商务统计分析(第3章 数据描述)
文章目录
- 一、描述数值的度量
-
- 1.1 集中趋势
-
- 1.平均数
- 2.中位数
- 3.众数
- 1.2 离散程度
-
- 1.全距/极差
- 2.方差、标准差
- 3.变异系数
- 4.Z值
- 5.分布形状
- 1.3 总体数据的数值型描述度量
-
- 1.经验法则(适用于数据对称)
- 2.切比雪夫法则(适用于不对称的数据)
- 1.4 描述两个变量之间的关系的度量
-
- 1. 协方差(covariance)
- 2.相关系数(coefficient of correlation)
一、描述数值的度量
在统计应用中,对数值变量进行总结和描述的时候,通常从三个维度进行分析
1. 集中趋势:所有数据观测值是否在一个典型或中心值周位的范围内
2. 离散程度:观测值与一个中心值散布或分散的量
3. 分布形状:观测值从最低值到最高值分布的模式
1.1 集中趋势
1.平均数
作用: 平均数是用于反映总体数据的一般水平,或分布的集中趋势。
缺点:
a. 平均数容易受到极端值的影响,如果数据中有极大极小值,此时平均数的代表性很差
b. 当一组数据有明显的偏态分布时,平均数的代表性差
2.中位数
作用: 用来代表一组数据的中等水平,是一组数据中间位置上的代表值,不受极端值和偏态分布的影响
缺点: 因为只利用了部分数据来代表一组数据的集中趋势,可靠性较差,不代表整体。
计算公式: (n+1)/2
3.众数
作用: 集中了数据集中发生频数最高的数据值,不易受极端值影响,在一个数据集中,众数可能不存在或存在多个众数。当一组数据中有不少数据多次重复出现时,众数也往往是我们关心的一种集中趋势。它反映了一种最普遍的倾向
缺点: 没有平均数准确
1.2 离散程度
1.全距/极差
全距= 最大值 - 最小值
作用: 全距简单的度量了数据集的总体离散程度
2.方差、标准差
标准差的作用:
描述数据集的波动大小或者说离散程度。
标准差跟平均值有着相同的量纲(单位),所以便于衡量一个数据集的波动程度,
例如:一个球员,每场平均得分22.3分,标准差为3.1,那么可以说他每场得分聚集在22.3分上下浮动3.1分的范围内
公式:

注意: 总体的方差是除以总体样本个数N的,而样本方差是除以样本个数减1的,即(n-1)
3.变异系数
coefficient of variation , 用符号CV表示。
作用: 当需要比较两组数据离散程度大小的时候,如果两组数据的测量尺度相差太大,或者数据量纲/单位的不同,直接使用标准差来进行比较不合适,此时就应当消除测量尺度和量纲的影响,而变异系数可以做到这一点,它是原始数据标准差与原始数据平均数的比。
公式: CV = 标准差 / 平均数 * 100%
例子: 物流公司打算买新车,要考虑车的容量:体积和载重。从平常的货物中随机取样200个,发现平均重量26磅,标准差3.9磅,平均体积8.8立方英尺,标准差为2.2立方英尺。计算体积的CV为25%,重量的CV为15%。因而,相对于平均数,包裹体积比包裹重量变动更大。
4.Z值
作用: 识别异常值
Z= X - μ / σ
Z值等于:(观测样本值 - 样本平均值) /样本标准差
Z值如果小于-3或大于3,认为该样本是异常值。
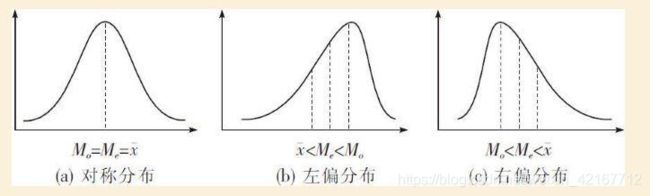
5.分布形状
均值<中位数:负偏,或左偏(左边长尾,左边的极小值拉低了平均数)
均值=中位数:对称分布,零偏度
均值>中位数:正偏,或右偏(右边长尾,右边的极大值拉高了平均数)
1.3 总体数据的数值型描述度量
1.1,1.2章节介绍的描述数据主要是针对样本数据的,要注意的是对总体数据的描述,标准差和方差是除以N
1.经验法则(适用于数据对称)
当一组数据是对称分布的时候,可以用经验法则来检验这些分布的特性:
- 约有68%的数据在平均数±1个标准差的范围内
- 约有95%的数据在平均数±2个标准差的范围内
- 约有99%的数据在平均数±3个标准差的范围内
当出现在平均数三个标准差之外的数据,可以当做outlier。
2.切比雪夫法则(适用于不对称的数据)

例题:一种新的心脏手术正在一家医院推广,对于已完成的20例这种手术,平均住院期为14.3天,标准差为2.84天,因为手术复杂,住院期天数的总体不服从正态分布,而是有些正偏,总体标准差未知,求总体均值的90%近似置信区间。

1.4 描述两个变量之间的关系的度量
用来描述两个变量之间的关系,比如说,年龄跟身高这两个变量间有没关系
1. 协方差(covariance)
作用: 度量两个数值变量X和Y之间的线性关系强度。如果协方差大于0,则两个变量正相关,反之同理,等于0则不相关。
缺点: 协方差只是个值,不能够确定两个变量之间关系的相对强度。因此需要计算相关系数来判定。换句话说,协方差只是为了计算相关系数,的中间产物。
样本协方差计算公式:
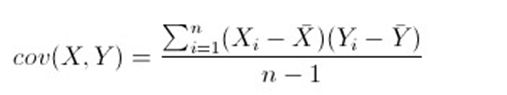
2.相关系数(coefficient of correlation)
作用: 衡量两个数值变量间的线性关系的相对强度。
取值范围: 【-1,1】
计算公式:

化简

相关性:
当 |r| >=0.8时,有强相关性
当0.5<|r|<0.8时,有较强相关性
当0.3<|r|<0.5时,有弱相关性
当 |r| <0.3时,无相关性
注意点: 存在较强的相关性并不意味着因果关系!!!仅仅意味着数据有如此倾向。