一、大数据学习之路——探索性数据分析(EDA)

定义:对已有的数据(特别是调查或观察得来的原始数据)在尽量少的先验假定下进行探索,通过作图、制表、方程拟合、计算特征量等手段探索数据的结构和规律的一种数据分析方法。
数据类型:https://blog.csdn.net/Shingle_/article/details/80035405
数据类型是统计学中的重要概念,我们需要对它有正确的理解方能利用正确的数据类型来获得结论。这篇文章将介绍几种用于机器学习探索性数据分析的数据类型,以便正确的把握和利用数据。
对数据结构的良好理解对于机器学习中探索性分析十分重要,对于不同的数据类型我们需要不同的统计学度量手段来进行分析测试。同时也需要根据数据的类型选择合适的可视化方式来帮助我们更好的理解数据。最后数据类型也为变量的分类提供了一个有效的途径。
分类数据
分类数据代表着对象的属性特点。诸如人群的性别、语言、国籍大都属于分类数据。分类数据通常也可以用数值表示(例如1表示女性而0表示男性),但需要注意的是这一数值并没有数学上的意义仅仅是分类的标记而已。
定类数据
定类变量用于标记不同变量的特征,而并不需要定量的数值,它们仅仅是标签而已。需要注意定类数据是无序的,对于变量顺序的更改不会改变数据的本质特征。

上图中表示的便是一个样本典型的分类数据,分别描述了个体的性别和语言属性。特别的作图中是一个只有两个属性的二叉分枝。
定序数据
定序数据代表了离散但是有序的变量单位。它于定类数据十分类型但确实有序的数据组织。下面教育背景的数据很好地的描述了定序数据的特点。

上图中的四个选项依次表示了不同的受教育程度,但却无法量化初级教育与高中的差别和高中与大学差别间的不同。定序数据缺乏对于特征间差别的量化使得它更多的只能用于评价利于情绪和用户满意度等一系列非数值特征。
数值数据
离散数据
离散数据是指其取值是不连续的分离值,数据只能在一些特定点取值。这样的数据不能定量测量但可以进行统计计量,并可将其蕴含的信息通过分类的方式进行表示。掷硬币便是最著名的例子,我们无法预测出下一次硬币的正反但是可以通过统计历史数据来估测概率的分布。
当处理离散数据时我们需要对两个问题进行深入思考:数据是否可以计数统计,是否可以分割成较小的部分。如果结论于此相关数据可以被测量而不能够计数,那么意味着我们需要处理的便是连续的数据类型。
连续数据
连续数据类型代表着对象可测量的连续取值,虽然不能够计数但是可以用某种尺度进行连续的测量取值,例如人的身高和年龄便是连续的数值。通常情况下人们只用或者实数来进行表示。
定距数据
定距变量用于表示对象等差属性的描述方法。当我们使用定距变量时我们可以明确的知道数值间的顺序和差别,并计量这种差别。对于温度的描述就是一个定距数据典型的例子。

但定距变量存在的问题在于它没有一个绝对的基准零值,对于上图中的温度来说0度并不意味着没有温度。对于定距变量来说我们可以进行加减操作却无法进行乘除或者比例计算操作。由于不存在绝对零值使得描述性和推理性的统计方法都无法在定距数据上应用。
定比数据
定比数据和定距数据一样都是有序的数据排列,但定比数据存在一个绝对的零值,所描述的都是具有零值基准的变量,包括重量、高度和长度等。

为何数据类型如此重要?
由于不同的统计方法适用于不同的数据类型,所以数据的类型对于统计和机器学习分析十分重要。试想如果利用连续数据的分析方法来研究分类数据,那么十有八九会得出错误的结论。对于数据类型的理解将会有助于我们选择正确的方法和统计模型来探索和分析数据。那么不同的数据类型我们该选择何种统计模型来分析呢?
对于定类数据来说主要需要关注频率、比例/百分比和可视化方法三个要素。用频率度量某一事物在一定时间或者是在数据集中发生的次数。同时可以用频率将其从数据中的占比进行统计和分离。对于这列数据来说饼图和柱状图是最好的呈现方式。

对于定序数据来说除了百分比和频率等指标外,还可以利用百分位数、中位数等统计指标来描述数据。
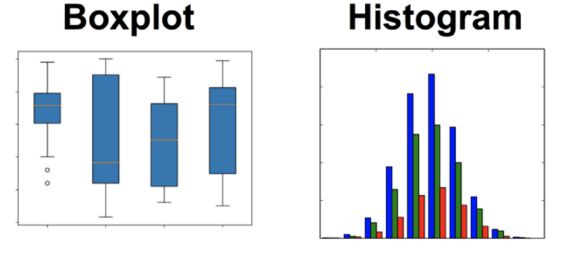
对于连续数据来说可以利用更为丰富的的手段进行处理,除了常见统计手段的均值和方差外还有峰峰值、范围等指标来进行表示。为了表示数据的误差和离散程度,带有误差棒的箱式图和直方图不失为一种直观的呈现方式。通过箱图可以看到数据的集中程度和误差程度,而直方图则可以提供数据的整体形态、中值、分布以及趋势。
在这篇文章中我们看到除了连续和离散的数值类型外,统计学中还包括了定序数据、定类数据、定距数据和定比数据等类别。对于不同的数据类型有着不同的分析和可视化方法,在着手处理数据时,理解数据是开始工作的首要条件,不仅有助于我们选择正确的工具和方法,更有助于我们用正确的思维去探索和分析数据,更容易地得出正确有效的结论。