Sklearn(v3)——朴素贝叶斯(1)

真正的概率分类器
在许多分类算法应用中,特征和标签之间的关系并非是决定性的。比如说,我们想预测一个人究竟是否会在泰坦尼克号海难中生存下来,那我们可以建一棵决策树来学习我们的训练集。在训练中,其中一个人的特征为:30岁,男,普 通舱,他最后在泰坦尼克号海难中去世了。当我们测试的时候,我们发现有另一个人的特征也为:30岁,男,普通 舱。基于在训练集中的学习,我们的决策树必然会给这个人打上标签:去世。然而这个人的真实情况一定是去世了吗?并非如此。
也许这个人是心脏病患者,得到了上救生艇的优先权。又有可能,这个人就是挤上了救生艇,活了下来。对分类算法来说,基于训练的经验,这个人“很有可能”是没有活下来,但算法永远也无法确定”这个人一定没有活下来“。即便这个人最后真的没有活下来,算法也无法确定基于训练数据给出的判断,是否真的解释了这个人没有存活下来的真实情况。这就是说,算法得出的结论,永远不是100%确定的,更多的是判断出了一种“样本的标签更可能是某类的可能性”,而非一种“确定”。我们通过某些规定,比如说,在决策树的叶子节点上占比较多的标签,就是叶子节点上所有样本的标签,来强行让算法为我们返回一个固定结果。但许多时候,我们也希望能够理解算法判断出的可能性本身。
每种算法使用不同的指标来衡量这种可能性。比如说,决策树使用的就是叶子节点上占比较多的标签所占的比例(接口predict_proba调用),逻辑回归使用的是sigmoid函数压缩后的似然(接口predict_proba调用),而SVM使用的是样本点到决策边界的距离(接口decision_function调用)。但这些指标的本质,其实都是一种“类概率”的表示,我们可以通过归一化或sigmoid函数将这些指标压缩到0~1之间,让他们表示我们的模型对预测的结果究竟有多大的把握(置信度)。但无论如何,我们都希望使用真正的概率来衡量可能性,因此就有了真正的概率算法:朴素贝叶斯。
朴素贝叶斯是一种直接衡量标签和特征之间的概率关系的有监督学习算法,是一种专注分类的算法。朴素贝叶斯的算法根源就是基于概率论和数理统计的贝叶斯理论,因此它是根正苗红的概率模型。接下来,我们就来认识一下这个简单快速的概率算法。
朴素贝叶斯是如何工作的





概率大于0.5标签为1
概率小于0.5标签为0

温度和观察到的瓢虫数量不是独立的,但是当控制了冬眠个变量时,温度和观察到了瓢虫数量就不是独立的了
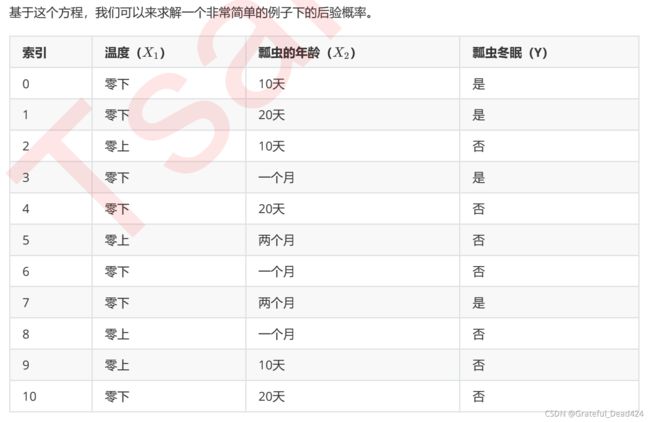







fit过程是在估计对应分布的参数,predict过程是在该参数下的分布中去进行概率预测
sklearn中的朴素贝叶斯
 高斯朴素贝叶斯
高斯朴素贝叶斯



import numpy as np
import matplotlib.pyplot as plt
from sklearn.naive_bayes import GaussianNB
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
#十分类问题
digits = load_digits()
X, y = digits.data,digits.target
Xtrain,Xtest,Ytrain,Ytest = train_test_split(X,y,test_size=0.3,random_state=420)
gnb = GaussianNB().fit(Xtrain,Ytrain)
#查看分数
acc_score = gnb.score(Xtest,Ytest)
acc_score结果:
0.8592592592592593#查看预测结果
Y_pred = gnb.predict(Xtest)
#查看预测的概率结果
prob = gnb.predict_proba(Xtest)
prob #每一行和为1结果:

from sklearn.metrics import confusion_matrix as CM
CM(Ytest,Y_pred)结果:


贝叶斯——要求变量是相互独立的,故通常而言不是第一选择
不同样本量是横坐标, 准确率是纵坐标
import numpy as np
import matplotlib.pyplot as plt
from sklearn.naive_bayes import GaussianNB
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier as RFC
from sklearn.tree import DecisionTreeClassifier as DTC
from sklearn.linear_model import LogisticRegression as LR
from sklearn.datasets import load_digits
from sklearn.model_selection import learning_curve
from sklearn.model_selection import ShuffleSplit
from time import time
import datetime
def plot_learning_curve(estimator,title, X, y,
ax, #选择子图
ylim=None, #设置纵坐标的取值范围
cv=None, #交叉验证
n_jobs=None #设定索要使用的线程
):
train_sizes,train_scores,test_scores = learning_curve(estimator,X,y,cv=cv,n_jobs=n_jobs)
ax.set_title(title) #设置标题
if ylim is not None:
ax.set_ylim(*ylim) #纵坐标在一致的量纲下
ax.set_xlabel("Training examples")
ax.set_ylabel("Score")
ax.grid() #显示网格作为背景,不是必须
ax.plot(train_sizes,np.mean(train_scores,axis=1),'o-', color="r",label="Training score")
ax.plot(train_sizes,np.mean(test_scores,axis=1),'o-', color="g",label="Test score")
ax.legend(loc="best")
return ax
digits = load_digits()
X, y = digits.data, digits.target
title = ["Naive Bayes" ,"DecisionTree" ,"SVM, RBF kernel" ,"RandomForest" ,"Logistic"]
model = [GaussianNB(),DTC(),SVC(gamma=0.001),RFC(n_estimators=50),LR(C=.1,solver="lbfgs")]
cv = ShuffleSplit(n_splits=50, test_size=0.2, random_state=0)
fig, axes = plt.subplots(1,5,figsize=(30,6))
for ind,title_,estimator in zip(range(len(title)),title,model):
times = time()
plot_learning_curve(estimator, title_, X, y,ax=axes[ind], ylim = [0.7, 1.05],n_jobs=4, cv=cv)
print("{}:{}".format(title_,datetime.datetime.fromtimestamp(time()-times).strftime("%M:%S:%f")))
plt.show()note:

结果:
Naive Bayes:00:00:417101
DecisionTree:00:00:604189
SVM, RBF kernel:00:08:924170
RandomForest:00:05:252286
Logistic:00:05:541503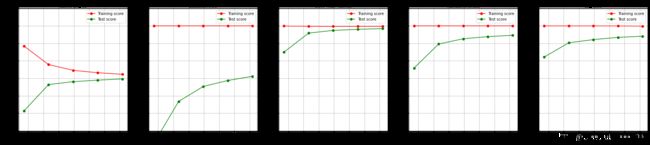
三个模型表现出的状态非常有意思。
我们首先返回的结果是各个算法的运行时间。可以看到,决策树和贝叶斯不相伯仲(如果你没有发现这个结果,那么可以多运行几次,你会发现贝叶斯和决策树的运行时间逐渐变得差不多)。决策树之所以能够运行非常快速是因为sklearn中的分类树在选择特征时有所“偷懒”,没有计算全部特征的信息熵而是随机选择了一部分特征来进行计算,因此速度快可以理解,但我们知道决策树的运算效率随着样本量逐渐增大会越来越慢,但朴素贝叶斯却可以在很少的样本上获得不错的结果,因此我们可以预料,随着样本量的逐渐增大贝叶斯会逐渐变得比决策树更快。朴素贝叶斯计算速度远远胜过SVM,随机森林这样复杂的模型,逻辑回归的运行受到最大迭代次数的强烈影响和输入数据的影响(逻辑回归一般在线性数据上运行都比较快,但在这里应该是受到了稀疏矩阵的影响)。因此在运算时间上,朴素贝叶斯还是十分有优势的。
紧接着,我们来看一下每个算法在训练集上的拟合。手写数字数据集是一个较为简单的数据集,决策树,森林,SVC和逻辑回归都成功拟合了100%的准确率,但贝叶斯的最高训练准确率都没有超过95%,这也应证了我们最开始说的,朴素贝叶斯的分类效果其实不如其他分类器,贝叶斯天生学习能力比较弱。并且我们注意到,随着训练样本量的逐渐增大,其他模型的训练拟合都保持在100%的水平,但贝叶斯的训练准确率却逐渐下降,这证明样本量越大,贝叶斯需要学习的东西越多,对训练集的拟合程度也越来越差。反而比较少量的样本可以让贝叶斯有较高的训练准确率。
再来看看过拟合问题。首先一眼看到,所有模型在样本量很少的时候都是出于过拟合状态的(训练集上表现好,测试集上表现糟糕),但随着样本的逐渐增多,过拟合问题都逐渐消失了,不过每个模型的处理手段不同。比较强大的分类器们,比如SVM,随机森林和逻辑回归,是依靠快速升高模型在测试集上的表现来减轻过拟合问题。相对的,决策树虽然也是通过提高模型在测试集上的表现来减轻过拟合,但随着训练样本的增加,模型在测试集上的表现善生却非常缓慢。朴素贝叶斯独树一帜,是依赖训练集上的准确率下降,测试集上的准确率上升来逐渐解决过拟合问题。
接下来,看看每个算法在测试集上的拟合结果,即泛化误差的大小。随着训练样本数量的上升,所有模型的测试表现都上升了,但贝叶斯和决策树在测试集上的表现远远不如SVM,随机森林和逻辑回归。 SVM在训练数据量增大到1500个样本左右的时候,测试集上的表现已经非常接近100%,而随机森林和逻辑回归的表现也在95%以上,而决策树和朴素贝叶斯还徘徊在85%左右。但这两个模型所面临的情况十分不同:决策树虽然测试结果不高,但是却依然具有潜力,因为它的过拟合现象非常严重,我们可以通过减枝来让决策树的测试结果逼近训练结果。然而贝叶斯的过拟合现象在训练样本达到1500左右的时候已经几乎不存在了,训练集上的分数和测试集上的分数非常接近,只有在非常少的时候测试集上的分数才能够比训练集上的结果更高,所以我们基本可以判断,85%左右就是贝叶斯在这个数据集上的极限了。可以预测到,如果我们进行调参,那决策树最后应该可以达到90%左右的预测准确率,但贝叶斯却几乎没有潜力了。
在这个对比之下,我们可以看出:贝叶斯是速度很快,但分类效果一般,并且初次训练之后的结果就很接近算法极限的算法,几乎没有调参的余地。也就是说,如果我们追求对概率的预测,并且希望越准确越好,那我们应该先选择逻辑回归。如果数据十分复杂,或者是稀疏矩阵,那我们坚定地使用贝叶斯。如果我们分类的目标不是要追求对概率的预测,那我们完全可以先试试看高斯朴素贝叶斯的效果(反正它运算很快速,还不需要太多的样本),如果效果很不错,我们就很幸运地得到了一个表现优秀又快速的模型。如果我们没有得到比较好的结果,那我们完全可以选择再更换成更加复杂的模型。