一些可以参考的文档集合5
之前的文章集合:
一些可以参考文章集合1_xuejianxinokok的博客-CSDN博客
一些可以参考文章集合2_xuejianxinokok的博客-CSDN博客
一些可以参考的文档集合3_xuejianxinokok的博客-CSDN博客
一些可以参考的文档集合4_xuejianxinokok的博客-CSDN博客
20220628
MQTT 最初由 Andy Stanford-Clark 博士和 Arlen Nipper 博士于 1999 年创建,用于通过卫星连接石油管道遥测系统。
两位发明者为未来的协议指定了几个要求:
简单的实现
服务质量数据交付
轻量级和带宽效率
数据不可知
持续的会话
物联网协议的王者:MQTT_mqtt_wljslmz_InfoQ写作社区你好,这里是网络技术联盟站。今天跟大家聊一下物联网协议中比较著名的协议:MQTT。让我们直接开始!什么是MQTT?英文全称:Message Quueuing Telemetry Transport中文 https://xie.infoq.cn/article/490b2d34332f44f5e53e9b371
https://xie.infoq.cn/article/490b2d34332f44f5e53e9b371
20220624
在用户离开页面时可靠地发送 HTTP 请求



Reliably Send an HTTP Request as a User Leaves a Page | CSS-Tricks - CSS-TricksOn several occasions, I’ve needed to send off an HTTP request with some data to log when a user does something like navigate to a different page or submit ahttps://css-tricks.com/send-an-http-request-on-page-exit/
服务静态网站的最小 Docker 镜像
The smallest Docker image to serve static websites | Florin Lipan https://lipanski.com/posts/smallest-docker-image-static-website
https://lipanski.com/posts/smallest-docker-image-static-website
20220623

Elasticsearch 在地理信息空间索引的探索和演进-51CTO.COM本文梳理了Elasticsearch对于数值索引实现方案的升级和优化思考,从2015年至今数值索引的方案经历了多个版本的迭代,实现思路从最初的字符串模拟到KD-Tree,技术越来越复杂,能力越来越强大,应用场景也越来越丰富。从地理位置信息建模到多维坐标,数据检索到数据分析洞察都可以看到Elasticsearch的身影。https://developer.51cto.com/article/712221.html
20220622

JEP咖啡屋11[熟肉]-虚拟线程这是 Oracle Java developer advocate 之一 José Paumard 主持的一系列节目,主要介绍 JEP(JDK Enhancement Proposal),这是节目的第11期,主要介绍了Java 19 中的预览特性虚拟线程,包括虚拟线程是什么,如何替代传统线程模型,以及如何使用虚拟线程和使用注意事项等等 https://mp.weixin.qq.com/s/r_uwOMgwygaJwnfA2F85qA
https://mp.weixin.qq.com/s/r_uwOMgwygaJwnfA2F85qA
2022062
Loki是 Grafana Labs 团队最新的开源项目,是一个水平可扩展,高可用性,多租户的日志聚合系统。它的设计非常经济高效且易于操作,因为它不会为日志内容编制索引,而是为每个日志流编制一组标签。
与其他日志聚合系统相比,Loki具有下面的一些特性:
- 不对日志进行全文索引。
Loki中存储的是压缩后的非结构化日志,并且只对元数据建立索引,因此Loki具有操作简单、低成本的优势。 - 使用与 Prometheus 相同的标签。
Loki通过标签对日志进行索引和分组,这使得日志的扩展和操作效率更高。 - 特别适合储存 Kubernetes Pod 日志。诸如 Pod 标签之类的元数据会被自动删除和编入索引。
- Grafana 原生支持
Loki日志系统由以下3个部分组成:- loki是主服务器,负责存储日志和处理查询。
- promtail是专为loki定制的代理,负责收集日志并将其发送给 loki 。
- Grafana用于 UI展示。

Loki 包含Distributor、Ingester、Querier和可选的Query frontend五个组件。每个组件都会起一个用于处理内部请求的 gRPC 服务器和一个用于处理外部 API 请求的 HTTP/1服务器。
Loki 日志系统(一) - 知乎Loki是 Grafana Labs 团队最新的开源项目,是一个水平可扩展,高可用性,多租户的日志聚合系统。它的设计非常经济高效且易于操作,因为它不会为日志内容编制索引,而是为每个日志流编制一组标签。项目受 Prometheu… https://zhuanlan.zhihu.com/p/153415749
https://zhuanlan.zhihu.com/p/153415749
Loki日志系统(五) - 知乎本文是系列文章的最后一篇,着重介绍各个组件的部署和配置,最终配合grafana一起查看日志,示例中日志来源为k8s集群。 5. 集群部署完整的日志系统包含以下几个部分: Loki 集群Promtail 日志收集代理Etcd/Consul …https://zhuanlan.zhihu.com/p/165985207
Loki - 知乎轻量级日志系统https://www.zhihu.com/column/c_1262077765433348096
一套轻量级日志收集方案:
Promtail:日志收集工具
Loki:日志聚合系统
Grafana:可视化工具
日志检索服务分为以下几个模块:
• GD-Search
查询调度器, 负责接受查询请求, 对查询命令做解析和优化, 并从 Chunk Index 中获取查询范围内日志块的地址, 最终生成分布式的查询计划
GD-Search 本身是无状态的, 可以部署多个实例,通过负载均衡对外提供统一的接入地址。
• Local-Search
本地存储查询器, 负责处理 GD-Search 分配过来的本地日志块的查询请求。
• Remote-Search
远程存储查询器, 负责处理 GD-Search 分配过来的远程日志块的查询请求。
Remote-Search 会将需要的日志块从远程存储拉取到本地并解压, 之后同 Local-Search 一样在本地存储上进行查询。同时 Remote-Search 会将日志块的本地存储地址更新到 Chunk Index 中,以便将后续同样日志块的查询请求路由到本地存储上。
• Log-Manager
本地存储管理器,负责维护本地存储上日志块的生命周期。
Log-Manager 会定期扫描本地存储上的日志块, 如果日志块超过本地保存期限或者磁盘使用率到达瓶颈,则会按照策略将部分日志块淘汰(压缩后上传到远程存储, 压缩算法采用了 ZSTD), 并更新日志块在 Chunk Index 中的存储信息。
• Log-Ingester
日志摄取器模块, 负责从日志 kafka 订阅日志数据, 然后将日志数据按时间维度和元数据维度拆分, 写入到对应的日志块中。在生成新的日志块同时, Log-Ingester 会将日志块的元数据写入 Chunk Index 中, 从而保证最新的日志块能够被实时检索到。
• Chunk Index
日志块元数据存储, 负责保存日志块的元数据和存储信息。当前我们选择了 Redis 作为存储介质, 在元数据索引并不复杂的情况下, redis 已经能够满足我们索引日志块的需求, 并且基于内存的查询速度也能够满足我们快速锁定日志块的需求。

作业帮PB级低成本日志检索服务_架构_吕亚霖_InfoQ精选文章作业帮PB级低成本日志检索服务日志是服务观察的主要方式,我们依赖日志去感知服务的运行状态、历史状况;当发生错误时,我们又依赖日志去 https://www.infoq.cn/article/xyDSrOGbg6tVDVEb261O
https://www.infoq.cn/article/xyDSrOGbg6tVDVEb261O
微服务的前提条件首要还是该先解决非技术方面的问题,准确地说是人的问题。分布式不是一项纯粹的技术性工作,如果不能满足以下条件,就应该尽量避免采用微服务。
微服务化的第一个前提条件是决策者与执行者都能意识到康威定律在软件设计中的关键作用。
康威定律尝试使用社会学的方法去解释软件研发中的问题,其核心观点是“沟通决定设计”(Communication Dictates Design),如果技术层面紧密联系在一起的特性,在组织层面上强行分离开来,那结果会是沟通成本的上升,因为会产生大量的跨组织的沟通;如果技术层面本身没什么联系的特性,在组织层面上强行安放在一块,那结果会是管理成本的上升,因为成员越多越不利于一致决策的形成。这些社会学、管理学的规律决定了假如产品和组织能够经受住市场竞争,长期发展的话,最终都会自发地调整成组织与产品互相匹配的状态。哪些特性在团队内部沟通,哪些特性需要跨团队的协作,将最终都会在产品中分别映射成与组织结构一致的应用内、外部的调用与依赖关系。
康威定律现在依然在指导我们进行软件开发团队组织结构建设--让团队结构与系统结构相匹配(如:与微服务匹配的 two-pizza team)。
微服务最大的挑战却并不在技术上,用采访专家的话说“微服务最大的挑战是大家没有意识到微服务的挑战有多大”。除了技术,企业和程序员正确使用微服务架构,本身就是微服务最大的挑战。第一,你需要正确使用场景,真正了解微服务带来的复杂性,了解服务划分会带来的问题;第二,微服务对于组织结构也有一定的要求,它要求自治的团队,如果你是强耦合的组织结构,那么首先就不符合康威定律,组织结构和系统架构就有着巨大的冲突。所以正确理解微服务的理念,正确使用微服务,是企业目前最大的挑战。
软件架构如何“以不变应万变”_架构_marsxxl_InfoQ精选文章软件架构如何“以不变应万变”采访嘉宾:蔡超、成国柱、谭待编辑|marsxxl在InfoQ成立15周年之际,InfoQ编辑部发起了https://www.infoq.cn/article/COjE2Mad57Vd8vQe1qKS
20220619
- Openresty最佳案例 | 第1篇:Nginx介绍
- Openresty最佳案例 | 第2篇:Lua入门
- Openresty最佳案例 | 第3篇:Openresty安装
- Openresty最佳案例 | 第4篇:OpenResty常见的api
- Openresty最佳案例 | 第5篇:http和c_json模块
- Openresty最佳案例 | 第6篇:OpenResty连接Mysql
- Openresty最佳案例 | 第7篇:模块开发、OpenResty连接Redis
- Openresty最佳案例 | 第8篇:RBAC介绍、sql和redis模块工具类
- Openresty最佳案例 | 第9篇:Openresty实现的网关权限控制
Openresty最佳案例 | 汇总 - 方志朋的专栏 - 博客园转载请标明出处:http://blog.csdn.net/forezp/article/details/78616856本文出自方志朋的博客目录Openresty最佳案例 | 第1篇:Nginx介绍Ohttps://www.cnblogs.com/forezp/p/9852065.html
https://wiki.jikexueyuan.com/project/openresty/https://wiki.jikexueyuan.com/project/openresty/
20220615

spring的BeanFactory和ApplicationContext_Java_程序员欣宸_InfoQ写作社区欢迎访问我的GitHub这里分类和汇总了欣宸的全部原创(含配套源码):https://github.com/zq2599/blog_demos文中涉及的spring版本号为4.1.8.RELEASE;https://xie.infoq.cn/article/b920a8c0f0eab3ca252e5d122
20220615
一款轻量级、开源、免费的PDF阅读器,SumatraPDFSumatra PDF 是一款开源、免费、体积小巧、启动极为迅速的 Windows 平台上经典的电子书阅读器软件。它不仅支持阅读 PDF 格式文档,同时还能支持 ePub、Mobi、CHM、XPS、DjVu 文档,CBZ、CBR 漫画等。https://mp.weixin.qq.com/s/dZv5lRYcSoRtX9FB8uwYfQ

聊聊八种架构模式-51CTO.COM作为一个工作10年以上的老码农,经历的系统架构设计也算不少,接下来,我会把工作中用到的一些架构方面的设计模式分享给大家,望大家少走弯路。https://developer.51cto.com/article/711543.html
系统本身的复杂性: 分层分模块
系统要解决跨主题域,跨层的所有问题,包括解决需求多元化的问题,快速响应和平台化之间矛盾,不同供应商标准不统一的问题(如不同手机有不同的充电接口)。
组织的复杂性:分模块 微服务
包括组织各层次各系统对应不同的职能,兼并重组带来的职能重叠,技术债等。基于康威定律,这必然影响 IT 系统设计,带来复杂性。
人的复杂性:不断的学习
系统是人设计的,由于设计者缺乏必要的知识,缺乏通盘考虑,以及受制于屁股决定脑袋,个人偏好等影响,每一次迭代和重构都有可能增加系统的复杂性。
企业架构正是为了解决 IT 系统的复杂性而诞生的。它通过战略和 IT 的对齐,通过解决不同利益相关者的关注点帮助我们在整个架构景观中形成一条穿过复杂性的路径。
企业架构的第一性原理_企业架构_涛哥_InfoQ写作社区很多人会问,为什么要学习Archiamte。回答为什么要学习Archimate和回答为什么要学习企业架构一样,都涉及一个第一性原理的问题,也就是企业架构的基本假设是什么。在回答这个问题之前,先让我们了https://xie.infoq.cn/article/434994bdef8ab384771a2ced0
20220614
非阻塞的 read,指的是在数据到达前,即数据还未到达网卡,或者到达网卡但还没有拷贝到内核缓冲区之前,这个阶段是非阻塞的。
当数据已到达内核缓冲区,此时调用 read 函数仍然是阻塞的,需要等待数据从内核缓冲区拷贝到用户缓冲区,才能返回。
可以看出几个细节:
1. select 调用需要传入 fd 数组,需要拷贝一份到内核,高并发场景下这样的拷贝消耗的资源是惊人的。(可优化为不复制)
2. select 在内核层仍然是通过遍历的方式检查文件描述符的就绪状态,是个同步过程,只不过无系统调用切换上下文的开销。(内核层可优化为异步事件通知)
3. select 仅仅返回可读文件描述符的个数,具体哪个可读还是要用户自己遍历。(可优化为只返回给用户就绪的文件描述符,无需用户做无效的遍历)
epoll 是最终的大 boss,它解决了 select 和 poll 的一些问题。
还记得上面说的 select 的三个细节么?
- select 调用需要传入 fd 数组,需要拷贝一份到内核,高并发场景下这样的拷贝消耗的资源是惊人的。(可优化为不复制)
- select 在内核层仍然是通过遍历的方式检查文件描述符的就绪状态,是个同步过程,只不过无系统调用切换上下文的开销。(内核层可优化为异步事件通知)
- select 仅仅返回可读文件描述符的个数,具体哪个可读还是要用户自己遍历。(可优化为只返回给用户就绪的文件描述符,无需用户做无效的遍历)
所以 epoll 主要就是针对这三点进行了改进。
- 内核中保存一份文件描述符集合,无需用户每次都重新传入,只需告诉内核修改的部分即可。
- 内核不再通过轮询的方式找到就绪的文件描述符,而是通过异步 IO 事件唤醒。
- 内核仅会将有 IO 事件的文件描述符返回给用户,用户也无需遍历整个文件描述符集合。
具体,操作系统提供了这三个函数。
第一步,创建一个 epoll 句柄
int epoll_create(int size);第二步,向内核添加、修改或删除要监控的文件描述符。
int epoll_ctl(
int epfd, int op, int fd, struct epoll_event *event);第三步,类似发起了 select() 调用
int epoll_wait(
int epfd, struct epoll_event *events, int max events, int timeout);动图说明IO多路复用的优势(转) - 知乎1. IO多路复用与IO模型我一直认为IO多路复用与IO模型是不同类的东西,IO模型主要讲的是假如调用 read()读取文件,当前进程从发起调用到真正返回结果可用的一个状态。而IO多路复用 则侧重于多个从事相同工作的线程…https://zhuanlan.zhihu.com/p/477835108IO多路复用,几个动图我悟了!深入浅出https://mp.weixin.qq.com/s/_FlMydLpS9BR-jBu_0PurA
最近在逛 Github 发现了一个宝藏 CLI 工具:qnm,它可以帮助我们快速梳理前端依赖信息,并且同时支持 npm 和 yarn。
Node_modules 是该好好治一治了-51CTO.COM作为前端开发者,大家有没有被 node_modules 困扰过呢?反正我是有。。。因为 npm 特殊的包管理机制,往往一个很小的项目就会携带一个很大的 node_modules 。https://developer.51cto.com/article/711528.html
20220613

Java News Roundup: JDK 19 in Rampdown, JDK 20 Expert Group, Eclipse Mojarra 4.0 https://www.infoq.com/news/2022/06/java-news-roundup-jun06-2022/
https://www.infoq.com/news/2022/06/java-news-roundup-jun06-2022/
20220610
如果redo log 是纯physical log 的话, 那么就可以省去double write buffer 的开销, 保证每一次修改都是在4kb以内(由操作系统保证4kb以内的原子操作), 那么就不存在应用redo 到不新不旧的page 上的问题, 就不需要double write buffer.
Double Write Buffer,但它与传统的buffer又不同,它分为内存和磁盘的两层架构。
传统的buffer,大部分是内存存储;而DWB里的数据,是需要落地的。

如上图所示,当有页数据要刷盘时:
第一步:页数据先memcopy到DWB的内存里;
第二步:DWB的内存里,会先刷到DWB的磁盘上,这可以把离散写变成顺序写,效率高
第三步:DWB的内存里,再刷到数据磁盘存储上;这里是离散写,效率低
DWB由128个页构成,容量只有2M。
步骤2和步骤3要写2次磁盘,这就是“Double Write”的由来。
DWB为什么能解决“页数据损坏”问题呢?
假设步骤2掉电,磁盘里依然是1+2+3+4的完整数据。
只要有页数据完整,这时可以用redo还原数据。
physical to a page, logical within a page
假如步骤3掉电,DWB里存储着完整的数据。
所以,一定不会出现“页数据损坏”问题。
⚠️ Tip: Use Local Records to model intermediate transformations
Complex data transformations require us to model intermediate values. Before Java 16, a typical solution was to rely on Pair or similar holder classes from a library, or to define your own (maybe inner static) class to hold this data.
The problem with this is that the former one quite often proves to be inflexible, and the latter one pollutes the namespace by introducing classes only used in context of a single method. It’s also possible to define classes inside a method body, but due to their verbose nature it was rarely a good fit.
Java 16 improves on this, as now it’s also possible to define Local Records in a method body:
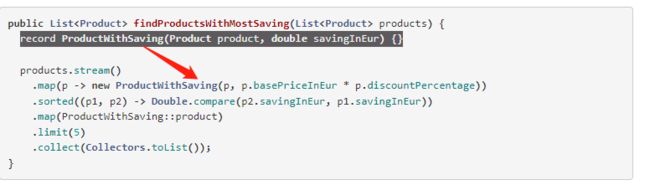
In addition to Records, this change also enables the use Local Enums and even Interfaces.
New language features since Java 8 to 18 - Advanced Web Machineryhttps://advancedweb.hu/new-language-features-since-java-8-to-18/
20220609
ARMS基于eBPF技术打造了Kubernetes监控,提供多语言无侵入的应用性能,系统性能,网络性能观测能力,验证了eBPF技术的有效性。
eBPF是一个能够在内核运行沙箱程序的技术,提供了一种在内核事件和用户程序事件发生时安全注入代码的机制,使得非内核开发人员也可以对内核进行控制。随着内核的发展,eBPF 逐步从最初的数据包过滤扩展到了网络、内核、安全、跟踪等,而且它的功能特性还在快速发展中,早期的 BPF 被称为经典 BPF,简称cBPF,正是这种功能扩展,使得现在的BPF被称为扩展BPF,简称eBPF。
eBPF的应用场景是什么?
网络优化 故障诊断 安全控制 性能监控
eBPF的出现本质上是为了解决内核迭代速度慢和系统需求快速变化的矛盾,在eBPF领域常用的一个例子是eBPF相对于Linux Kernel类似于Javascript相对于HTML,突出的是可编程性。一般来说可编程性的支持通常会带来一些新的问题,比如内核模块其实也是为了解决这个问题,但是他没有提供很好的边界,导致内核模块会影响内核本身的稳定性,在不同的内核版本需要做适配等。
深入浅出eBPF|你要了解的七个核心问题-51CTO.COMeBPF是一个能够在内核运行沙箱程序的技术,提供了一种在内核事件和用户程序事件发生时安全注入代码的机制,使得非内核开发人员也可以对内核进行控制。https://network.51cto.com/article/711018.html
20220608
决定“不要什么”比“要什么”更难
也许是由于人性的贪婪,对于软件系统我们同样想要更多:更多功能、更好的性能、更好的伸缩性、扩展性等等。作为软件架构师要明白软件架构设计就是一种取舍或平衡。当大家都在往里面加东西的时候,架构师更应该来做这个说“不”的人。
软件设计和定义过程中存在很多取舍,例如:
-
完善功能和尽早发布的取舍。
-
伸缩性和性能的取舍。
著名的 CAP 原则,就是一个很好的取舍指导策略。为了更好的取舍,保持架构风格的一致性,在一开始架构师就应该根据系统的实际需求来定义一些取舍的原则,如:
-
数据一致性拥有最高优先级。
-
提前发布核心功能优于完整发布等。
-
非功能性需求决定架构
-
因为软件是为了满足客户的功能性需求的,所以很多设计人员可能会认为架构是由要实现的功能性需求决定的。但实际上真正决定软件架构的其实是非功能性需求。
架构师要更加关注非功能性需求,常见的非功能性包括:性能,伸缩性,扩展性和可维护性等,甚至还包括团队技术水平和发布时间要求。能实现功能的设计总是有很多,考虑了非功能性需求后才能筛选出最合适的设计。
-
简单”并不“容易”
很多架构师都会常常提到保持简单,但是有时候我们会混淆简单和容易。简单和容易在英语里也是两个词“simple”和“easy”。
“Simple can be harder than complex:You have to work hard to get your thinking clean to make it simple. But it’s worth it in the end because once you get there, you can move mountains.To be truly simple, you have to go really deep.”
--SteveJobs
真正的一些简单的方法其实来自于对问题和技术更深入的理解。这些方案往往不是容易获得的、表面上的方法。简单可以说蕴含着一种深入的技巧在其中。
一位架构师的感悟:过度忙碌使你落后我踩过的坑,希望大家不用再踩。https://mp.weixin.qq.com/s/uwA5JryExOpUtQ_5AF7bBQ
数据库理论
博客 | PingCAPhttps://pingcap.com/zh/blog/?tag=TiKV%20%E6%BA%90%E7%A0%81%E8%A7%A3%E6%9E%90
mmap的api
作者给出了内存映射文件io的POSIX系统调用。
mmap:介绍了MAP_SHARED和MAP_PRIVATE在可见性上的区别
madvise:介绍了MADV_NORMAL,MADV_RANDOM和MADV_SEQUENTIAL在预读上的区别
mlock:可以尝试性的锁住内存中的页面,一定程度上防止被写回存储。(然而并不是确定性的锁住)
msync:将页面从内存写回存储的接口
mmap
主要讲述了MAP_SHARED和MAP_PRIVATE的区别。
此调用导致文件映射到DBMS的虚拟地址空间,然后DBMS可以使用普通的内存操作读取或写入文件内容。
MAP_SHARED:将修改后的文件 重写 回底层文件
MAP_PRIVATE:创建一个只有调用者可以访问的写时复制映射,不会重写回 底层文件。
madvise
介绍了MADV_NORMAL和MADV_RANDOM,MADV_SEQUENTIAL三种标志的区别
MADV_NORMAL:告诉linux系统执行默认操作,系统将会返回接下来前15个页面和后16个页面。
即使只需要一个页面,系统也会返回32个页面,带来了极大的系统开销
MADV_RANDOM:告诉系统,访问页面是随机的。
MADV_SEQUENTIAL:告诉系统,我们将要顺序执行。
mlock
该调用允许dbms将页面固定在内存中,并保证操作系统永远不会驱逐他
但是根据POSIX标准和linux实现,即使被固定了,操作系统随时会将脏页重写回磁盘中。因此,mlock只能保证页面不会被驱逐,不能够保证脏页不会被重写回磁盘中,这对于事务安全有很大的影响。
msync
将内存范围更改显示刷新到 外部存储中 ,如果没有这个方法,DBMS就没有其他方法将 更新 刷新到 外部存储中
两者的对比
表面上来看,两种io操作带来的开销
buffer pool:2次上下文切换,2次拷贝
mmap:2次上下文切换,1次拷贝
是否要在数据库系统中使用mmap?_seez的博客-CSDN博客andy在cmu15-445中提出了不要在数据库系统中使用mmap因为这个,在网络上找了许多关于 mmap 的文章,无一例外都是对 mmap 的褒奖, 对于mmap可能带来的负面影响少之又少,因此整理了一下andy的论文。andy的论文大佬的整理Ravendb‘s ceo的回应问题引出通常情况下,数据库系统对于文件IO管理有两种选择:开发者自己实现buffer pool来管理文件io读入内存的数据使用linux实现的mmap系统调用将文件直接映射到用户地址空间, 并且利用对开发者透明的pahttps://blog.csdn.net/qq12323qweeqwe/article/details/124323566
20220607
Parquet是Hadoop生态里面一个比较流行的列存储格式。它存在的意义就是最大化利用压缩的列存储表示。
当然支持各种压缩和编码模式:
- 可以细化到列级别,即每一列用不同算法压缩;
- 甚至支持未来的,尚未发明的压缩技术。
注意,总的来说,Parquet是一个非常底层的文件存储技术,它和任何数据处理技术、软件都是正交的,这些技术也都可以用Parquet来存文件。
Apache Parquet设计解读 - 简书官网地址:https://parquet.apache.org/docs[https://parquet.apache.org/docs]编码:https://www.wai...https://www.jianshu.com/p/07f789521564
Apache Beam 是一种用于处理数据、支持批处理和流式处理的编程模型。
使用为 Java、Python 和 Go 提供的 SDK,您可以开发管道,然后选择将运行管道的后端。
Introduction to Apache Beam Using JavaApache Beam is a stream processor, helping developers migrate work between different processes to offload work onto runners that leverage external resources.https://www.infoq.com/articles/apache-beam-intro/
JEP 428:简化 Java 多线程编程的结构化并发
JEP 428: Structured Concurrency (Incubator)https://openjdk.java.net/jeps/428
JEP 428: Structured Concurrency to Simplify Java Multithreaded Programminghttps://www.infoq.com/news/2022/06/java-structured-concurrency/
20220606
CMU数据库管理系统课程[熟肉]4.数据库存储结构2(下)这是 CMU 数据库管理系统课程的公开视频,我个人做了字幕附在底部,这是第四课的下半部分,第四节课是继续第三节课将数据库的存储设计,之后的课程我也会不断翻译发出来的~https://mp.weixin.qq.com/s/JcI0pwNMm7Wh6DTEBKs9JA
CMU数据库课程[熟肉]4.数据库存储结构2(上).mp4这是 CMU 数据库管理系统课程的公开视频,我个人做了字幕附在底部,这是第四课的上半部分,第四节课是继续第三节课将数据库的存储设计,之后的课程我也会不断翻译发出来的~https://mp.weixin.qq.com/s/1Ls0R3hVwJWPTII-iTCtKg
CMU 15-445 数据库课程第四课文字版 - 存储2熟肉视频地址:CMU数据库管理系统课程[熟肉]4.数据库存储结构2(上)CMU数据库管理系统课程[熟肉]4.https://mp.weixin.qq.com/s/xh9vj-sog1UVd0LnmGxlZA
页需要是自包含的,即关于如何解释和理解页内容,所需要的所有信息都必须存储在页本身中。这样,即使丢失任何一页,也不会影响其他任何一页的解析和使用。如果你把元数据存储与元组数据分开存储在不同的页,如果元数据页丢失或者损坏了,那么元组数据页也就无法解析了。这种自包含的设计,对于容灾更好。
每个页都有唯一的标识符即页 ID(Page ID)。我们使用这个唯一标识符形成一个中间层,在这个中间层维护 Page ID 与实际存储的文件的位置的映射,通过 Page ID 就能定位到对应的文件位置并读取这个页。同时如果我们移动了页(例如我们想扩展存储,压缩存储使用等等),Page ID 不会变,只是修改了文件位置,这比直接使用文件位置存储要方便很多。这样 DBMS 的其它层就不用关心这个,只记录 Page ID 就可以,我们在修改页位置的时候不用告知其他层同时修改。
通过页目录(Page)这种方式设计堆文件中的结构,但是首先我们先来通过链表(Linked List)设计下文件结构来看下为何这种方式是愚蠢的。

这是使用更多的设计方式,即页目录。我们维护一个专门存储目录的页,在这个目录中维护页 ID 到具体文件位置的偏移量的映射,可以简单把它理解成一个 key 为页 ID value 为文件位置偏移的哈希表。并且在这里还会维护页的空闲空间信息,这样在插入的时候,我们可以直接通过页目录直接定位到要插入的页。但是这样也带来了原子更新的问题,即页的空闲空间信息与插入数据是否在一个原子操作内。但是由于这个两个页的操作,硬件层面上我是很难保证两页更新是原子性的,所以我们需要额外的机制在数据库重启的时候检查是否有这些未完成的写入,这在后面讲恢复与日志的章节的时候会说到。
一般采用槽页(Slotted Pages)这种设计:
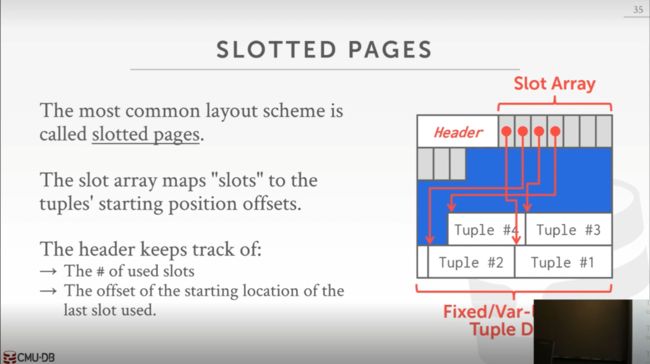
这种设计被大部分数据库所采用,虽然在细节上有些不同,但是大致是这么个结构。在开头还是前面提到的页头,之后跟着两种存储结构
-
槽数组(slot array):从前向后写,在这个数组中的元素记录所有元组在文件中的起始位置偏移。槽数组可以解耦元组位置与外部访问,相当于前面提到的间接层。我们可能在页内部移动元组(比如更新元组导致元组长度改变会标记删除原始元组在最后追加新的元组数据),通过这个槽数组外部就可以不关心这个位置变化了。
-
实际元组数据:从后向前写
CMU 15-445 数据库课程第三课文字版 - 存储1熟肉视频地址:CMU数据库管理系统课程[熟肉]3.数据库存储结构1(上)CMU数据库管理系统课程[熟肉]3.https://mp.weixin.qq.com/s/6q4nG6JTVvjP28BHYkOHtQ

深入理解 ELK 中 Logstash 的底层原理 + 填坑指南_架构_悟空聊架构_InfoQ写作社区你好,我是悟空呀~本文目录如下:前言一、部署架构图二、Logstash 用来做什么?三、Logstash 的原理3.1 从 Logstash 自带的配置说起3.2 Input 插件3.3 Filterhttps://xie.infoq.cn/article/19876ab127e12c0a7d5517125
20220603
度量linux 上下文切换代价
Measuring context switching and memory overheads for Linux threads - Eli Bendersky's websitehttps://eli.thegreenplace.net/2018/measuring-context-switching-and-memory-overheads-for-linux-threads/
20220601
Oracle 写数据库日志采用的是物理日志方式,记录的是内部数据块的变化;MySQL 在 Server 层的 binlog 是逻辑日志,记录的是逻辑行数据的变化。所以对 Oracle 的日志解析不仅需要理解日志本身 filespace、redo record,change vector 的变化,还需要理解 Oracle 内部数据存储的格式。
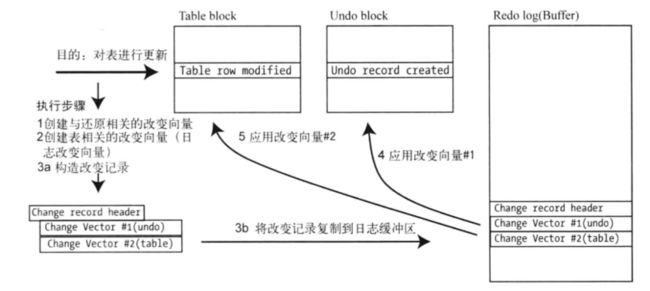
从 Oracle 日志解析学习数据库内核原理_ITPUB博客由浅入深,介绍了数据库中常见而又关键的概念,了解数据库思路以及工程实现中需要注意的事项。ITPUB博客每天千篇余篇博文新资讯,40多万活跃博主,为IT技术人提供全面的IT资讯和交流互动的IT博客平台-中国专业的IT技术ITPUB博客。http://blog.itpub.net/28218939/viewspace-2897865/
20220531
反应式宣言 The Reactive Manifesto
Published on September 16 2014. (v2.0)
Organisations working in disparate domains are independently discovering patterns for building software that look the same. These systems are more robust, more resilient, more flexible and better positioned to meet modern demands.
These changes are happening because application requirements have changed dramatically in recent years. Only a few years ago a large application had tens of servers, seconds of response time, hours of offline maintenance and gigabytes of data. Today applications are deployed on everything from mobile devices to cloud-based clusters running thousands of multi-core processors. Users expect millisecond response times and 100% uptime. Data is measured in Petabytes. Today's demands are simply not met by yesterday’s software architectures.
We believe that a coherent approach to systems architecture is needed, and we believe that all necessary aspects are already recognised individually: we want systems that are Responsive, Resilient, Elastic and Message Driven. We call these Reactive Systems.
Systems built as Reactive Systems are more flexible, loosely-coupled and scalable. This makes them easier to develop and amenable to change. They are significantly more tolerant of failure and when failure does occur they meet it with elegance rather than disaster. Reactive Systems are highly responsive, giving users effective interactive feedback.
Reactive Systems are:
Responsive: The system responds in a timely manner if at all possible. Responsiveness is the cornerstone of usability and utility, but more than that, responsiveness means that problems may be detected quickly and dealt with effectively. Responsive systems focus on providing rapid and consistent response times, establishing reliable upper bounds so they deliver a consistent quality of service. This consistent behaviour in turn simplifies error handling, builds end user confidence, and encourages further interaction.
Resilient: The system stays responsive in the face of failure. This applies not only to highly-available, mission-critical systems — any system that is not resilient will be unresponsive after a failure. Resilience is achieved by replication, containment, isolation and delegation. Failures are contained within each component, isolating components from each other and thereby ensuring that parts of the system can fail and recover without compromising the system as a whole. Recovery of each component is delegated to another (external) component and high-availability is ensured by replication where necessary. The client of a component is not burdened with handling its failures.
Elastic: The system stays responsive under varying workload. Reactive Systems can react to changes in the input rate by increasing or decreasing the resources allocated to service these inputs. This implies designs that have no contention points or central bottlenecks, resulting in the ability to shard or replicate components and distribute inputs among them. Reactive Systems support predictive, as well as Reactive, scaling algorithms by providing relevant live performance measures. They achieve elasticity in a cost-effective way on commodity hardware and software platforms.
Message Driven: Reactive Systems rely on asynchronous message-passing to establish a boundary between components that ensures loose coupling, isolation and location transparency. This boundary also provides the means to delegate failures as messages. Employing explicit message-passing enables load management, elasticity, and flow control by shaping and monitoring the message queues in the system and applying back-pressure when necessary. Location transparent messaging as a means of communication makes it possible for the management of failure to work with the same constructs and semantics across a cluster or within a single host. Non-blocking communication allows recipients to only consume resources while active, leading to less system overhead.
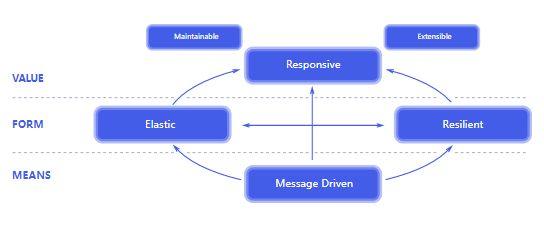
Large systems are composed of smaller ones and therefore depend on the Reactive properties of their constituents. This means that Reactive Systems apply design principles so these properties apply at all levels of scale, making them composable. The largest systems in the world rely upon architectures based on these properties and serve the needs of billions of people daily. It is time to apply these design principles consciously from the start instead of rediscovering them each time.
The Reactive Manifestohttps://www.reactivemanifesto.org/
Kafka到底有多高可靠?(RNG NB)-51CTO.COMKafka通过ACK应答机制保证了不同组件之间的通信效率,通过副本同步机制、数据截断和数据清理机制实现了对于数据的管理策略,保证整个系统运行效率。https://developer.51cto.com/article/710230.html
可以将可观测问题大致分为四类:
-
分布式链路追踪技术:可观测的基石
-
APM:Application Performance Monitoring ,应用性能监控
-
NPM:Network Performance Monitoring ,网络性能监控
-
RUM:Real User Monitoring,真实用户监控
其中,分布式链路追踪技术的核心思想是:在用户一次请求服务的调⽤过程中,无论请求被分发到多少个子系统,子系统又调用了多少其他子系统,我们都要把系统信息和系统间调用关系都追踪记录下来,最终把数据集中起来做可视化展示。(引用自《怎么理解分布式链路追踪技术》,作者:蒋志伟,该文章会在专题的后续更新中放出)
APM 主要是为了对企业核心业务系统进行性能的故障定位和处理,帮助优化性能,提高业务系统的可靠性和用户体验,更多偏向产品维度,其底层虽依赖分布式链路追踪技术,但不能直接用来解决分布式链路追踪的问题 —— 这是此前很多工程师容易混淆的问题。(《在生产环境如何选择靠谱的 APM 系统》,作者:蒋志伟,该文章会在专题的后续更新中放出)
NPM ,顾名思义,其关键在于实现全网流量的可视化,对数据包、网络接口、流数据进行监控和分析。
RUM 的关键在于端到端反应用户的真实体验,捕捉用户和页面的每一个交互并分析其性能,是种高度实用主义的监控设计。
可观测存在三个主要的数据源:
-
指标(metrics)
-
链路(trace)
-
日志(log)
其中指标告诉我们是否有故障,链路告诉我们故障在哪里,日志则告诉我们故障的原因。
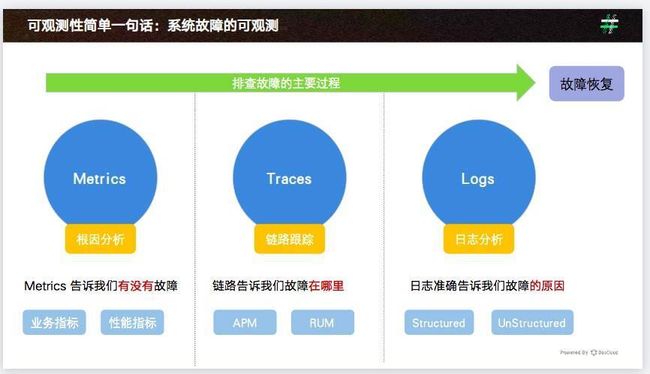
2022,我们该如何理解可观测技术_云原生_王一鹏_InfoQ精选文章2022,我们该如何理解可观测技术 本文受访嘉宾:蒋志伟,爱好技术的架构师,先后就职于阿里、Qunar、美团,前pmcaffCTO,目https://www.infoq.cn/article/j1qeF8L1MoGzFWXCcmbF
-
《Docker下RabbitMQ四部曲之一:极速体验(单机和集群)》;
-
《Docker下RabbitMQ四部曲之二:细说RabbitMQ镜像制作》;
-
《Docker下RabbitMQ四部曲之三:细说java开发》;
Docker下RabbitMQ四部曲之四:高可用实战_Java_程序员欣宸_InfoQ写作社区欢迎访问我的GitHub这里分类和汇总了欣宸的全部原创(含配套源码):https://github.com/zq2599/blog_demos本章是《Docker下RabbitMQ四部曲》系列的终篇,https://xie.infoq.cn/article/cc0948b2ff71c024d0142a2ed
1)XtraBackup
Percona公司开源的备份工具,适用于MySQL、MariaDB、Percona Server。
https://www.percona.com/software/mysql-database/percona-xtrabackup
XtraBackup目前维护的大版本有两个:
- XtraBackup 2.4,适用于MySQL 5.6和5.7。
- XtraBackup 8.0。适用于 MySQL 8.0。
之所以要维护两个版本,是因为MySQL 8.0中的redo log和数据字典的格式发生了变化。
2)mysqlbackup
MySQL企业级备份工具( MySQL Enterprise Backup ),适用于MySQL企业版。
https://dev.mysql.com/doc/mysql-enterprise-backup/4.1/en/mysqlbackup.html
3)Clone Plugin
MySQL 8.0.17引入的克隆插件。初衷是为了方便Group Replication添加新的节点。有了Clone Plugin,我们也能很方便的搭建一个从库,无需借助其它备份工具。
三者的实现原理基本相同,都是在备份的过程中,拷贝物理文件和redo log ,最后,再利用InnoDB Crash Recovery,将物理文件恢复到备份结束时的一致性状态。
针对数据量较大的实例,如果一定要使用逻辑备份,大家一般倾向于使用mydumper,而不是mysqldump。
MySQL如何选择合适的备份策略和备份工具-51CTO.COM在确定备份策略和选择备份工具时,应从业务的RTO和RPO出发,结合存储成本综合考虑。https://www.51cto.com/article/710267.html
20220530
SaltTiger | 每天一本编程书,每天进步一点点https://salttiger.com/
电子系统的集成主要分为三个层次(Level):芯片上的集成,封装内的集成,PCB板级集成.

科普集成电路:一文看懂电路三个层次的集成!额导 读集成,integration,是指将不同的功能单元汇聚到一起,并能实现其特定功能的过程,集成多指人类https://mp.weixin.qq.com/s/LbAvQKGtrCdJgGIZRlpQSw
20220527
PostgreSQL 14 版本特性浅析-阿里云开发者社区## 性能增强### 大量连接高并发优化- 场景: SaaS场景,微服务架构下的中心库场景- 业务特点:客户端多,在线用户多,数据库并发连接非常多- 价值: 比连接池网络少1跳, 性能更好, 支持绑定变量等连接池会话模式不支持的全部功能### 索引增强1. 缓解高频更新负载下的btree索引膨胀- 场景: 数据频繁更新,如游戏、交易、共享出行、IoT等行业- 价值: 减少膨胀https://developer.aliyun.com/article/849253
pgbench造2千万行数据:
pgbench -i -s 200
PostgreSQL技术之家: PostgreSQL14新特性:海量连接性能基本不下降PostgreSQL技术之家http://www.pgsql.tech/article_101_10000104

25 张图,一万字,拆解 Linux 网络包发送过程今天我们来聊另一个深度的话题,那就是 Linux 内核是怎么样将一个网络包发送出去的呢?https://mp.weixin.qq.com/s/wThfD9th9e_-YGHJJ3HXNQ

手工模拟实现 Docker 容器网络! - 知乎大家好,我是飞哥! 如今服务器虚拟化技术已经发展到了深水区。现在业界已经有很多公司都迁移到容器上了。我们的开发写出来的代码大概率是要运行在容器上的。因此深刻理解容器网络的工作原理非常的重要。这有这样…https://zhuanlan.zhihu.com/p/433060892
自定义对话框

Replace JavaScript Dialogs With New HTML Dialog | CSS-Tricks - CSS-TricksHere's how to replace JavaScript dialogs with the HTML dialog element with the same functionality as the alert(), confirm(), and prompt() methods.https://css-tricks.com/replace-javascript-dialogs-html-dialog-element/
20220526

在单进程模型中,不管有多少的连接,是几万还是几十万,服务器都是通过 epoll 来监控这些连接 socket 上的可读和可写事件。当某个 socket 上有数据发生的时候,再以非阻塞的方式对 socket 进行读写操作。
相对于同步阻塞的编程模型,这极大程度地减少了进程因为等待 socket 上的 网络 IO 而被阻塞掉的情况,进程可以一直进行数据的计算和收发。因为砍掉了上下文切换的系统开销,所以大幅度地提升了应用程序的性能。
单进程的问题也是显而易见的,没有办法充分发挥多核的优势。所以目前业界绝大部分的后端服务还都是需要基于多进程的方式来进行开发的。到了多进程的时候,更复杂的问题多进程之间的配合和协作问题就产生了。
万字多图,搞懂 Nginx 高性能网络原理! - 知乎https://zhuanlan.zhihu.com/p/496818263

漫画 | 看进程小 P 讲述它的网络性能故事! - 知乎大家好,我是飞哥! 今天给大家带来的是一个漫画故事!01大家好,我是一个进程,我的名字的小 P。 我和很多其它小伙伴一样,都由老大操作系统创建和管理。要问我是怎么来的,嘘小点声,不能让那帮应用开发们听见。…https://zhuanlan.zhihu.com/p/371575169
在传统的同步阻塞网络编程模型里(没有协程以前),性能上不来的根本原因在于进程线程都是笨重的家伙。让一个进(线)程只处理一个用户请求确确实实是有点浪费了。

先抛开高内存开销不说,在海量的网络请求到来的时候,光是频繁的进程线程上下文就让 CPU 疲于奔命了。

如果把进程比作牧羊人,一个进(线)程同时只能处理一个用户请求,相当于一个人只能看一只羊,放完这一只才能放下一只。如果同时来了 1000 只羊,那就得 1000 个人去放,这人力成本是非常高的。

性能提升思路很简单,就是让很多的用户连接来复用同一个进(线)程,这就是多路复用。多路指的是许许多多个用户的网络连接。复用指的是对进(线)程的复用。换到牧羊人的例子里,就是一群羊只要一个牧羊人来处理就行了。
不过复用实现起来是需要特殊的 socket 事件管理机制的,最典型和高效的方案就是 epoll。放到牧羊人的例子来,epoll 就相当于一只牧羊犬。
在 epoll 的系列函数里, epoll_create 用于创建一个 epoll 对象,epoll_ctl 用来给 epoll 对象添加或者删除一个 socket。 epoll_wait 就是查看它当前管理的这些 socket 上有没有可读可写事件发生。
当网卡上收到数据包后,Linux 内核进行一系列的处理后把数据放到 socket 的接收队列。然后会检查是否有 epoll 在管理它,如果是则在 epoll 的就绪队列中插入一个元素。epoll_wait 的操作就非常的简单了,就是到 epoll 的就绪队列上来查询有没有事件发生就行了。关于 epoll 这只“牧羊犬”的工作原理参见深入揭秘 epoll 是如何实现 IO 多路复用的 (Javaer 习惯把基于 epoll 的网络开发模型叫做 NIO)
在基于 epoll 的编程中,和传统的函数调用思路不同的是,我们并不能主动调用某个 API 来处理。因为无法知道我们想要处理的事件啥时候发生。所以只好提前把想要处理的事件的处理函数注册到一个事件分发器上去。当事件发生的时候,由这个事件分发器调用回调函数进行处理。这类基于实现注册事件分发器的开发模式也叫 Reactor 模型。

深度解析单线程的 Redis 如何做到每秒数万 QPS 的超高处理能力! - 知乎大家好,我是飞哥! 在网络编程中,只要提到高性能,很多人脑子里瞬间就会相当多线程。事实上,服务器端只需要单线程可以达到非常高的处理能力,Redis 就是一个非常好的例子。仅仅靠单线程就可以支撑起每秒数万 QP…https://zhuanlan.zhihu.com/p/512502929
可观察性可以定义为:根据内部系统产生的数据来评估其状态的能力。这个能力使用过程需要在不干预或不与系统互动的情况下审查系统的健康状况,只是在分析了来自系统的输出数据后得出结论。

DevOps和IT团队使用日志、度量和追踪(称为可观察性的三大支柱)等输出来衡量系统的可观察性,例如通过评估其属性和模式,我们可以确定各种系统组件的性能如何,然后决定下一步系统是否扩容、是否需要调优。当日志、度量和跟踪等方面的工具检测到异常情况时,它会通知团队,并提供团队所需的数据,以快速排除故障和解决问题。可观察性的三大支柱:
-
日志。有时间戳的、不可改变的离散事件记录,可以识别系统中不可预测的行为,并提供对出错时系统行为变化的洞察力。一般以结构化的方式读取日志,如JSON格式,以便日志可视化系统可以自动索引并使日志易于查询。
-
度量。作为监控的基础,会在一段时间内汇总度量指标的结果,这样度量指标会告诉我们一个方法使用了多少内存总量,或者一个服务每秒处理多少个请求,等等。
-
追踪。在分布式系统中,当一个单独的事务或请求从一个节点移动到另一个节点时,我们通过跟踪能了如指掌。追踪允许我们深入了解特定请求的细节,以确定哪些组件会导致系统错误,如监测通过模块的流量,并找到性能瓶颈。
-
可观察性起源于控制理论,从一个系统的外部输出了解其内部状态的程度。可观察性使用工具来提升系统监控的洞察力。换句话说,监控是在系统可观察后所做的事情。如果没有某种程度的可观察性,监控是不可能的。
-
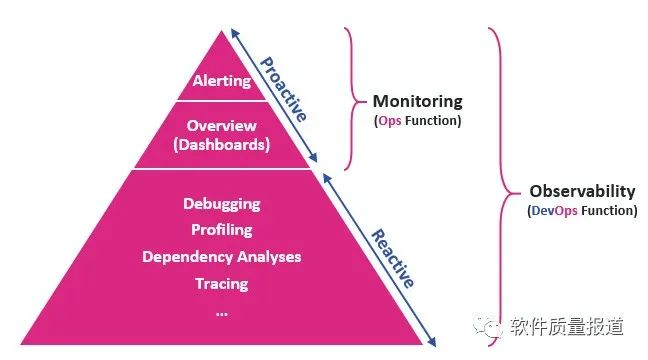
可观察性与监控的主要区别在于从I系统中提取的数据是否是预先确定的:
-
监控是一种收集和分析从单个系统中提取的预定数据的解决方案;
-
可观察性是一个聚合所有系统产生的所有数据的解决方案。
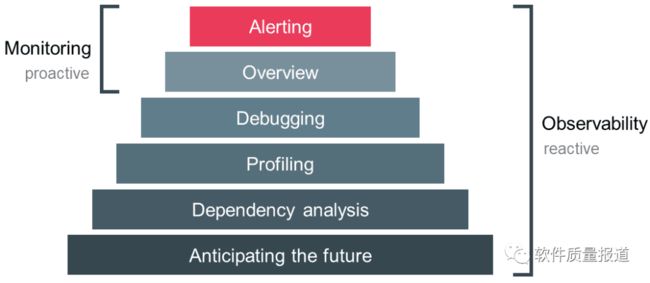
一文读懂:最近流行的可观察性本文讨论了这些主题:什么是可观察性?可观察性和监控有什么不同?可观察性的应用场景、带来的收益和\x0d\x0a常见的工具https://mp.weixin.qq.com/s/D2Y9PR2PERgUPi71c8KaOQ十年磨一剑:蚂蚁集团可观测性平台 AntMonitor 揭秘https://mp.weixin.qq.com/s/EHwsRuGPPMXwNf3DlmdNGQ
由于 @DataScope 注解是加在 service 层的方法上,所以这里使用前置通知,为方法的执行补充 SQL 参数,具体思路是这样:加了数据权限注解的 service 层方法的参数必须是对象,并且这个对象必须继承自 BaseEntity,BaseEntity 中则有一个 Map 类型的 params 属性,我们如果需要为 service 层方法的执行补充一句 SQL,那么就把补充的内容放到这个 params 变量中,补充内容的 key 就是前面声明的 dataScope,value 则是一句 SQL。在 doBefore 方法中先执行 clearDataScope 去清除 params 变量中已有的内容,防止 SQL 注入(因为这个 params 的内容也可以从前端传来);然后执行 handleDataScope 方法进行数据权限的过滤。

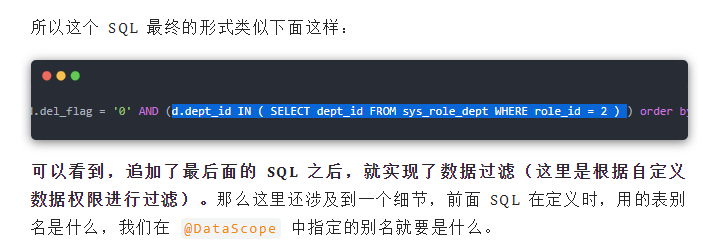
数据权限,一个注解搞定!。https://mp.weixin.qq.com/s/_dsdL5hDjd3CMxuWfWJ8Fg
rest 成熟度模型:
- 级别 1 通过使用分而治之,将大型服务端点分解为多个资源来解决处理复杂性的问题。
- Level 2 引入了一组标准的动词,以便我们以相同的方式处理类似的情况,消除不必要的变化。
- 第 3 级引入了可发现性,提供了一种使协议更加自文档化的方法。一个明显好处是它允许服务器在不破坏客户端的情况下更改其 URI 方案。

Richardson Maturity Modelhttps://martinfowler.com/articles/richardsonMaturityModel.html
20220525

DDD 整体作用总结如下:
-
消除信息不对称;
-
常规MVC三层架构中自底向上的设计方式做一个反转,以业务为主导,自顶向下的进行业务领域划分;
-
将大的业务需求进行拆分,分而治之。
肝了一个月的 DDD,一文带你掌握!去年倒腾了一个半月,写过一篇 DDD 的文章,当时没有推广,完全自嗨,为了不让这篇好文被埋没,现重新整理,突出重点,可读性更强!https://mp.weixin.qq.com/s/jU0awhez7QzN_nKrm4BNwg
一个微服务架构的概览

Infrastructure as a Service (IaaS)—The vendor provides the infrastructure that lets
you access computing resources such as servers, storage, and networks. In this
model, the user is responsible for everything related to the maintenance of the
infrastructure and the scalability of the application.
IaaS platforms include AWS (EC2), Azure Virtual Machines, Google Compute Engine, and Kubernetes.
Container as a Service (CaaS)—An intermediate model between the IaaS and the
PaaS, it refers to a form of container-based virtualization. Unlike an IaaS model,
where a developer manages the virtual machine to which the service is
deployed, with CaaS, you deploy your microservices in a lightweight, portable
virtual container (such as Docker) to a cloud provider. The cloud provider runs
the virtual server the container is running on, as well as the provider’s comprehensive tools for building, deploying, monitoring, and scaling containers.
CaaS platforms include Google Container Engine (GKE) and Amazon’s Elastic Container Service (ECS). In chapter 11, we’ll see how to deploy the microservices you’ve built to Amazon ECS.
Platform as a Service (PaaS)—This model provides a platform and an environment that allow users to focus on the development, execution, and maintenance of the application. The applications can be created with tools that are
provided by the vendor (for example, operating system, database management
systems, technical support, storage, hosting, network, and more). Users do not
need to invest in a physical infrastructure, nor spend time managing it, allowing
them to concentrate exclusively on the development of applications.
PaaS platforms include Google App Engine, Cloud Foundry, Heroku, and
AWS Elastic Beanstalk.
Function as a Service (FaaS)—Also known as serverless architecture, despite the
name, this architecture doesn’t mean running specific code without a server.
What it means is a way of executing functionalities in the cloud in which the
vendor provides all the required servers. Serverless architecture allows us to
focus only on the development of services without having to worry about scaling,Cloud and microservice-based applications 17
provisioning, and server administration. Instead, we can solely concentrate on
uploading our functions without handling any administration infrastructure.
FaaS platforms include AWS (Lambda), Google Cloud Function, and Azure
functions.
Software as a Service (SaaS)—Also known as software on demand, this model allows
users to use a specific application without having to deploy or to maintain it. In
most cases, the access is through a web browser. Everything is managed by the service provider: application, data, operating system, virtualization, servers, storage,
and network. The user just hires the service and uses the software.
SaaS platforms include Salesforce, SAP, and Google Business.

为什么需要轻量级线程: JEP 425: Virtual Threads (Preview)
虽然现代服务器可以支持的打开套接字的数量可能约为一百万甚至更多,但您不能拥有一百万个线程。因此,如果您可以说 2,000 个线程或 4,000 或 5,000 个线程,这就是您可以同时处理的最大请求数,即使您的服务器可以假设同时支持一百万个请求,因为您最多可以有一百万个请求打开socket。
Java 线程只是操作系统线程的薄包装,而操作系统线程是非常宝贵的资源。由于各种原因,现代操作系统一次不能支持超过几千个活动线程。因此,如果这是您想要编写的编程风格,那么您会受到线程数量的限制。
我们不会在同一个线程上从头到尾处理整个请求,而是我们要做一些处理,将线程返回到池中以供其他事务使用。然后假设我们向微服务发送一个传出请求。当response回来时,我们可能会在另一个线程中继续它。这种编程风格称为异步编程。
这解决了吞吐量问题。因此,通过反应式编程,您可以获得硬件支持的最大吞吐量,但是您编写程序的方式与平台的设计并不协调,因为 Java 平台的一切都是围绕线程构建的。如果您有异常,您获得的故障排除上下文是线程堆栈。一旦你使用了那些响应式框架,你得到的线程堆栈实际上并没有任何有价值的信息,任何有用的信息,因为同一个任务真的从一个线程移动到另一个线程。您无法在调试器中单步执行这些请求或那些事务,因为调试器单步执行单个线程上的操作。但是,如果您使用异步编程,您的操作实际上会从一个线程移动到另一个线程,并且您可以 t 使用 JFL 等分析器获取可操作的配置文件,因为它们按线程对操作进行分组。他们不知道这些异步事务。
从 Java 程序员的角度或从 Java 程序员的角度来看,当他们坐下来编写代码并运行它时,虚拟线程就是线程。它们是 Java 线程。语义在所有方面都完全相同,但在幕后,与我们已经开始调用平台线程的今天的线程不同,它们不会一对一地映射到 OS 线程。因此,虚拟线程不是操作系统线程的包装器。相反,它是操作系统不知道的 Java 运行时构造。
在幕后,运行时,库和 VM 将大量虚拟线程(甚至数百万)映射到非常小的 OS 线程集。所以从操作系统的角度来看,你的程序可能正在运行,我不知道,8 个或 32 个线程,但从你的角度来看,你将运行一百万个线程,这些线程将是虚拟的。virtual 这个名字应该唤起与虚拟内存相同的内涵和关联,在那里你有一些抽象的、廉价的、无限的资源,如虚拟内存或虚拟线程,然后自动巧妙地映射到一些更有限的物理资源,如 RAM 或操作系统线程。
线程局部变量。一旦你在一个池中共享线程,你必须非常非常小心,如果你使用线程局部变量,你可能会这样做,因为你使用的库,比如如果你使用一些日志库,它们使用线程局部变量。本地线程不与任务相关联,而是与线程相关联。因此,如果线程在许多任务之间共享并且您不小心,您的线程本地可能会从一个线程泄漏到另一个线程。事实上,这可能是一个安全问题。您可以将秘密从一个用户泄露给另一个用户。
- 调试仍然具有挑战性,Loom 项目团队正在与各种 IDE 供应商合作研究如何呈现大量线程。
- Loom 支持可插拔的调度器,允许开发人员试验不同的调度算法;默认调度程序使用基于工作窃取算法的 fork/join。在未来(发布第一个 GA 版本),团队可能会考虑添加显式的尾调用优化。
Java’s Project Loom, Virtual Threads and Structured Concurrency with Ron Presslerhttps://www.infoq.com/podcasts/java-project-loom/
Spring Integration 是一个支持企业应用程序集成 (EAI) 的框架。Gregor Hohpe 和 Bobby Woolf 的开创性著作《企业集成模式》为世界提供了集成模式的通用语。Spring Integration 为它提供了实现这些模式的抽象。
Go Native with Spring Boot and GraalVMhttps://www.infoq.com/articles/native-java-spring-boot/
record类规则
与普通类相比,record类的声明有许多限制:
- record类声明没有extends子句。record类的超类总是java.lang.Record,类似于枚举类的超类总是java.lang.Enum。即使普通类可以显式扩展其隐式超类Object,record也不能显式扩展任何类,即使是其隐式超类Record。
- record类是隐式的final,不能是abstract。这些限制强调了一个record类的 API 仅由其状态描述定义,并且不能在以后由另一个类增强。
- 从record组件派生的字段是final. 此限制体现了广泛适用于数据载体类的默认不可变策略。
- record类不能显式声明实例字段,也不能包含实例初始值设定项。这些限制确保record头单独定义record值的状态。
- 自动派生的成员的任何显式声明必须与自动派生成员的类型完全匹配,而不管显式声明上的任何注解。任何访问器或equals或者hashCode方法的显式实现都应该小心保留record类的语义不变量。
- record类不能声明native方法。如果record类可以声明一个native方法,那么record类的行为根据定义将取决于外部状态而不是record类的显式状态。没有具有本地方法的类可能是迁移到record的良好候选者。
除了上述限制之外,record类的行为类似于普通类:
- record类的实例是使用new表达式创建的。
- record类可以声明为顶级或嵌套的,并且可以是泛型的。
- record类可以声明static方法、字段和初始值设定项。
- record类可以声明实例方法。
JAVA record_sayWhat_sayHello的博客-CSDN博客_java recordJava17发布的新特性record,基于谷歌翻译再大致改下不通畅的地方。https://blog.csdn.net/sayWhat_sayHello/article/details/121902216
SpringMVC 源码
-
先来看下入口类 DispatcherServlet 的源码,在应用初始化的时候会调用 initMultipartResolver 方法:
this.multipartResolver = context.getBean(MULTIPART_RESOLVER_BEAN_NAME, MultipartResolver.class);...
复制代码
-
所以,如果配置了名为 multipartResolver 的 bean,就会 DispatcherServlet 的 multipartResolver 保存下来;
-
再来看一下处理 POST 请求时候的调用链:
FrameworkServlet.doPost->FrameworkServlet.processRequest->DispatcherServlet.doService->DispatcherServlet.doDispatch->DispatcherServlet.checkMultipart->multipartResolver.resolveMultipart(request)
复制代码
-
因此,应用收到上传文件的请求时,最终会调用 multipartResolver.resolveMultipart;
SpringMVC源码分析:POST请求中的文件处理_Java_程序员欣宸_InfoQ写作社区欢迎访问我的GitHub这里分类和汇总了欣宸的全部原创(含配套源码):https://github.com/zq2599/blog_demos本篇概览本章我们来一起阅读和分析SpringMVC的部分源https://xie.infoq.cn/article/c5c8eb0c6a6c3ae3139a25cab
20220524
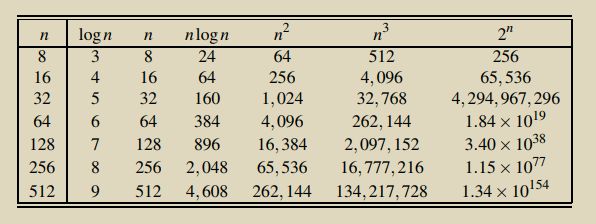
常见的增长数量级分类
以下为常见的算法分析方程形式,与微积分中求极限常见的方程相同。
一行语句 a+b = c为常熟级别(1)
二分查找为对数级别(logN)
遍历数组为线性级别(N)
分治法,归并排序就是线性对数级别(nlogn)
双层循环是平方级别,selection sort, insertion sort(n2)
三层循环是立方级别(n3)
最差的是指数级别,比如穷举查找(2 to the n)



本文主要描述了kafka3的安装配置包含不使用zookeeper的情况。还讨论了raft 协议
定义 Server 端代码实现:
public class Server1 {
public static void main(String[] args) {
// parse args
// peers, format is "host:port:serverId,host2:port2:serverId2"
//localhost:16010:1,localhost:16020:2,localhost:16030:3 localhost:16010:1
String servers = "localhost:16010:1,localhost:16020:2,localhost:16030:3";
// local server
RaftMessage.Server localServer = parseServer("localhost:16010:1");
String[] splitArray = servers.split(",");
List serverList = new ArrayList<>();
for (String serverString : splitArray) {
RaftMessage.Server server = parseServer(serverString);
serverList.add(server);
}
// 初始化RPCServer
RPCServer server = new RPCServer(localServer.getEndPoint().getPort());
// 设置Raft选项,比如:
// just for test snapshot
RaftOptions raftOptions = new RaftOptions();
/* raftOptions.setSnapshotMinLogSize(10 * 1024);
raftOptions.setSnapshotPeriodSeconds(30);
raftOptions.setMaxSegmentFileSize(1024 * 1024);*/
// 应用状态机
ExampleStateMachine stateMachine = new ExampleStateMachine(raftOptions.getDataDir());
// 初始化RaftNode
RaftNode raftNode = new RaftNode(raftOptions, serverList, localServer, stateMachine);
raftNode.getLeaderId();
// 注册Raft节点之间相互调用的服务
RaftConsensusService raftConsensusService = new RaftConsensusServiceImpl(raftNode);
server.registerService(raftConsensusService);
// 注册给Client调用的Raft服务
RaftClientService raftClientService = new RaftClientServiceImpl(raftNode);
server.registerService(raftClientService);
// 注册应用自己提供的服务
ExampleService exampleService = new ExampleServiceImpl(raftNode, stateMachine);
server.registerService(exampleService);
// 启动RPCServer,初始化Raft节点
server.start();
raftNode.init();
}
private static RaftMessage.Server parseServer(String serverString) {
String[] splitServer = serverString.split(":");
String host = splitServer[0];
Integer port = Integer.parseInt(splitServer[1]);
Integer serverId = Integer.parseInt(splitServer[2]);
RaftMessage.EndPoint endPoint = RaftMessage.EndPoint.newBuilder()
.setHost(host).setPort(port).build();
RaftMessage.Server.Builder serverBuilder = RaftMessage.Server.newBuilder();
RaftMessage.Server server = serverBuilder.setServerId(serverId).setEndPoint(endPoint).build();
return server;
}
}
定义客户端代码实现如下:
public class ClientMain {
public static void main(String[] args) {
// parse args
String ipPorts = args[0];
String key = args[1];
String value = null;
if (args.length > 2) {
value = args[2];
}
// init rpc client
RPCClient rpcClient = new RPCClient(ipPorts);
ExampleService exampleService = RPCProxy.getProxy(rpcClient, ExampleService.class);
final JsonFormat.Printer printer = JsonFormat.printer().omittingInsignificantWhitespace();
// set
if (value != null) {
ExampleMessage.SetRequest setRequest = ExampleMessage.SetRequest.newBuilder()
.setKey(key).setValue(value).build();
ExampleMessage.SetResponse setResponse = exampleService.set(setRequest);
try {
System.out.printf("set request, key=%s value=%s response=%s\n",
key, value, printer.print(setResponse));
} catch (Exception ex) {
ex.printStackTrace();
}
} else {
// get
ExampleMessage.GetRequest getRequest = ExampleMessage.GetRequest.newBuilder().setKey(key).build();
ExampleMessage.GetResponse getResponse = exampleService.get(getRequest);
try {
String value1 = getResponse.getValue();
System.out.println(value1);
System.out.printf("get request, key=%s, response=%s\n",
key, printer.print(getResponse));
} catch (Exception ex) {
ex.printStackTrace();
}
}
rpcClient.stop();
}
}
先启动服务端,然后启动客户端,就可以将实现客户端向服务端发送消息,并且服务端会向三台机器进行保存消息了。
Kafka 3 新特性,终于有人讲明白了https://mp.weixin.qq.com/s/w_HhaFieR6GPjB5m0ldIGQ

Raft 协议原理详解,10 分钟带你掌握!https://mp.weixin.qq.com/s/DiPN4fY6uqQ9pJaV4ftyrg分布式一致性协议 Raft 论文原理一篇读透 - 知乎参考文章 In Search Of Understandble Consensus Algorithm前言 笔者在校期间, 学习过的分布式一致性协议是 Paxos, 当时导师声称 Paxos 是分布式系统一致性协议的统治者, 其他一致性协议都可以看作是 Paxos 的变…https://zhuanlan.zhihu.com/p/344781101
不可知论的意思不应该是我们真的一无所知,而是假设Default我们一无所知,然后再重新梳理自己思想的真伪。它是一种对基点真伪的追问。因为世界是动态的,五官是不可靠的,固有的知识是有漏洞的,但是我们又喜欢用经验来衡量和决策。所以,如果能彻底怀疑过往的一切,假设我们的思想都是错的,那么对真理的追求会更近一步。
计算机的本质是哲学。https://mp.weixin.qq.com/s/NZysNyFdzoSyqqqbD0xhzQ
在传统的IO模型中,每个连接创建成功之后都需要由一个线程来维护,每个线程都包含一个while死循环,那么1万个连接对应1万个线程,继而有1万个while死循环,这就带来如下几个问题。
-
线程资源受限:线程是操作系统中非常宝贵的资源,同一时刻有大量的线程处于阻塞状态,是非常严重的资源浪费,操作系统耗不起。
-
线程切换效率低下:单机CPU核数固定,线程爆炸之后操作系统频繁进行线程切换,应用性能急剧下降。
-
除了以上两个问题,在IO编程中,我们看到数据读写是以字节流为单位的。
在NIO编程模型中,新来一个连接不再创建一个新线程,而是可以把这个连接直接绑定到某个固定的线程,然后这个连接所有的读写都由这个线程来负责,那么它是怎么做到的?我们用下图来对比一下IO与NIO。
实际开发过程中,我们会开多个线程,每个线程都管理着一批连接,相对于IO模型中一个线程管理一个连接,消耗的线程资源大幅减少。

NIO核心思路。
-
NIO模型中通常会有两个线程,每个线程都绑定一个轮询器Selector。在这个例子中,serverSelector负责轮询是否有新连接,clientSelector负责轮询连接是否有数据可读。
-
服务端监测到新连接之后,不再创建一个新线程,而是直接将新连接绑定到clientSelector上,这样就不用IO模型中的1万个while循环死等,参见(1)。
-
clientSelector被一个while死循环包裹着,如果在某一时刻有多个连接有数据可读,那么通过clientSelector.select(1)方法可以轮询出来,进而批量处理。
-
数据的读写面向Buffer。
让Netty“榨干”你的CPU使用Netty之后整个世界都变美好了https://mp.weixin.qq.com/s/Q27R1weSBeC5j9vNar7O4w
超过系统负载就是超载或过载(Overload),这看起来是个简单的问题,但实际上却并不简单,比如:
-
• CPU是否超过100%就是过载?不对,因为一般服务器会有多个CPU,也就是8个CPU的服务器,实际上能达到800%。
-
• 那CPU是否不超过总CPU使用率,比如8CPU的服务器不超过800%就不会过载?不对,因为流媒体服务器不一定能用多核,比如SRS就是单核,也就是它最多跑100%。
-
• 那是否SRS不超过100%使用率,就不会过载?不对,因为其他的进程可能也在消耗,不能只看SRS的CPU消耗。
因此,对于CPU来说,知道流媒体服务器能消耗多少CPU,获取流媒体服务器的CPU消耗,才能准确定义过载:
-
• 系统总CPU,超过80%认为过载,比如8CPU的服务器,总CPU超过640%就认为过载,一般系统的load值也升很高,代表系统很繁忙。
-
• SRS每个进程的CPU,超过80%认为过载,比如8CPU的服务器总CPU只有120%,但SRS的进程占用80%,其他占用40%,那么此时也是过载。
网络带宽,一般是根据以下几个指标判断是否过载,流媒体一般和流的码率Kbps或Mpbs有关,代表这个流每秒是多少数据传输:
-
• 是否超过服务器出口带宽,比如云服务器公网出口是10Mbps,那么如果平均码率是1Mbps的直播流,超过10个客户端就过载了。如果100个客户端都来推拉流,那么每个客户端只能传输100Kbps的数据,当然会造成严重卡顿。
-
• 是否超过内核的队列,在UDP中,一般系统默认的队列大小只有256KB,而流媒体中的包数目和字节,在流较多时远远超过了队列长度,会导致没有超过服务器带宽但是出现丢包情况,具体参考《SRS性能(CPU)、内存优化工具用法》(https://www.jianshu.com/p/6d4a89359352)这部分内容。
-
• 是否超过客户端的网络限制,有时候某些客户端的网络很差,出现客户端的网络过载。特别是直播推流时,需要重点关注主播上行的网络,没经验的主播会出现弱网等,导致所有人卡顿。
磁盘,主要涉及的是流的录制、日志切割以及慢磁盘导致的STW问题:
-
• 若需要录制的流较多,磁盘作为最慢的设备,会明显成为瓶颈。一般在系统设计时,就需要避免这种情况,比如64GB内存的服务器,可以分32GB的内存盘,给流媒体服务器写临时文件。或者使用较小的内存盘,用外部的程序比如node.js,开启多线程后,将文件拷贝到存储或发送到云存储,可以参考srs-cloud(https://github.com/ossrs/srs-cloud)的最佳实践。
-
• 服务器的日志,在一些异常情况下,可能会造成大量写入,另外如果持续累计不切割和清理,会导致日志文件越来越大,最终写满磁盘。SRS支持logrotate,另外docker一般也可以配置logrotate,通常会将日志做提取后(日志少可以直接采集原始日志),传输到云的日志服务做分析,本地只需要存储短时间比如15天日志。
-
• STW问题,写磁盘是阻塞操作,特别是挂载的网络磁盘(比如NAS),挂载到本地文件系统,而服务器在调用write写入数据时,实际上可能有非常多的网络操作,那么这种其实会更消耗时间。SRS目前应该完全避免挂载网络磁盘,因为每次阻塞都会导致整个服务器STW(世界暂停)不能处理其他请求。
内存主要是涉及泄露和缓存问题,主要的策略是监控系统整体的内存,相对比较简单。
SRS:流媒体服务器如何实现负载均衡当业务超过单台流服务器的承受能力,就需要负载均衡,它包括复杂的策略、工具和结构,和集群有一定关系但还不是完全等价。https://mp.weixin.qq.com/s/rzw0Inifap-nBX44NRMUlw