因子分析用Python怎么做?
大家好,我是小z
数据分析中,主成分分析(PCA)是被大家熟知的数据降维方法。而因子分析和主成分分析是非常相似的两种方法,他们都属于多元统计分析里的降维方法。但因子分析最大的优点就是:对新的因子能够进行命名和解释,使因子具有可解释性。因此,因子分析可以作为「需要满足可解释性数据建模」的前期数据降维的方法。下文会介绍因子分析的原理逻辑、用途以及Python代码的实现过程。
01
什么是因子分析?
因子分析的起源是这样的,1904年英国的一个心理学家发现学生的英语、法语和古典语成绩非常有相关性,他认为这三门课程背后有一个共同的因素驱动,最后将这个因素定义为“语言能力”。基于这个想法,发现很多相关性很高的因素背后有共同的因子驱动,从而定义了因子分析。
因子分析在经济学、心理学、语言学和社会学等领域经常被用到,一般会探索出背后的影响因素如:语言能力、智力、理解力等。这些因素都是无法直接计算,而是基于背后的调研数据所推算出的公共因子。
因此概括下,因子分析就是将存在某些相关性的变量提炼为较少的几个因子,用这几个因子去表示原本的变量,也可以根据因子对变量进行分类。
【举个例子】:学生有语文、英语、历史、数学、物理、化学六门成绩,通过因子分析会发现这六门课由两个公共因子驱动,前三门是由“文科”因子,后三门是“理科”因子;从而可以计算每个学生的文科得分和理科得分来评估他在两个方面的表现。
02
因子分析可以解决什么问题?
1、在多变量场景下,挖掘背后影响因子
比如在企业和品牌调研中,消费者会调查很多问题来评估企业品牌;对这些问题通过因子分析可以刻画出背后少量的潜在影响因素。比如:服务质量、商品质量等等。
2、用于数学建模前的降维
因子分析和主成分分析都可用于降维;但因子分析的优点是:因子作为新的解释变量去建模,有更好的解释性。
因此对于有些需要业务解释的数据建模,可以在建模前通过因子分析提取关键因子,再用因子得分为解释变量,通过回归或者决策树等分类模型去建模。
03
算法实现步骤
首先需要注意的是,和主成分分析一样,两种方法的目的都是降维,所以两种方法的前提假设都是:特征之间不是完全互相交互。
因子分析是寻找不线性相关的“变量”的线性组合来表示原始变量,这些“变量”称为因子,如下图中的F就是因子,X是原始变量,eps是原始变量不可被公共因子表示的部分。
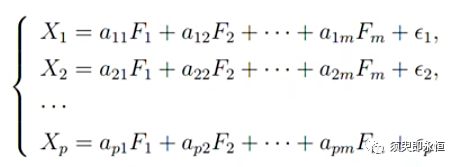
以上的公式还需要满足:
要求因子的数据小于原始变量的数量,即m≤p
因子F之间是相互独立且方差为1
因子F和eps之间的相关性为0,eps之间相关性为0
因此,因子分析的过程就是实现以下几个目的的过程:
1)求解方程中的因子F的系数
2)给予因子F实际的解释
3)展示原始特征和公共因子之间的关系,从而实现降维和特征分类等目的
求解方程的过程,就是分析变量的相关系数矩阵,从而找到少数几个随机变量去描述所有变量;又因为求解的不唯一性,最后通常会对因子的载荷矩阵做一次正交旋转,目的是为了:方便理解每个因子的意义。
汇总一下:对于因子分析的实操可以提炼为以下几个步骤:
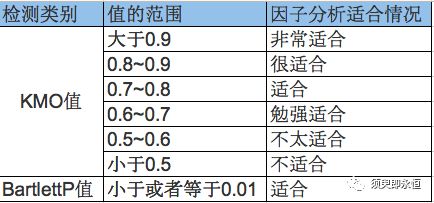
1)充分性检验
目的:检验变量之间是否存在相关性,从而判断是否适合做因子分析
方法:抽样适合性检验(KMO检验)或者 巴特利特检验(Bartlett’s Test)
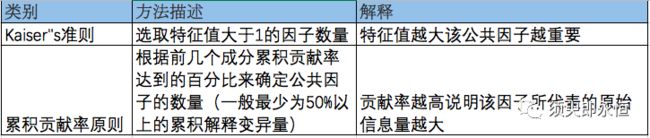
2)选择因子个数
目的:通过数据定义最合适的潜在公共因子个数,这个决定后面的因子分析效果
方法:Kaiser"s准则 或者 累积贡献率原则
3)提取公共因子并做因子旋转
提取公共因子就是上面提到的求解函数的过程,一般求解方法有:主成分法、最大似然法、残差最小法等等;
因子旋转的原因是提取公共因子的解有很多,而因子旋转后因子载荷矩阵将得到重新分配,可以使得旋转后的因子更容易解释。常用的方法是:方差最大法。
4)对因子做解释和命名
目的:解释和命名其实是对潜在因子理解的过程;这一步非常关键,需要非常了解业务才可。这也是我们使用因子分析的主要原因。
方法:根据因子载荷矩阵发现因子的特点
5)计算因子得分
对每一样本数据,得到它们在不同因子上的具体数据值,这些数值就是因子得分。
04
案例讲解
数据集介绍:
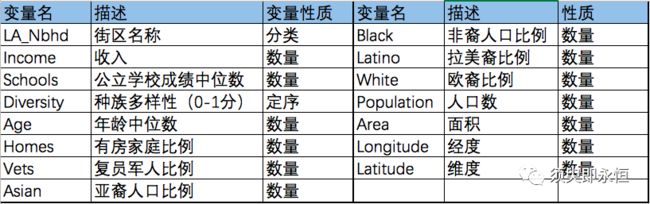
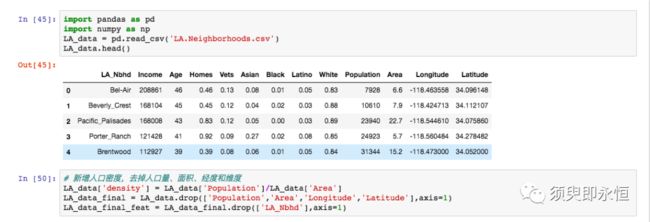
美国洛杉矶2000年街区普查数据,共有110个街区,15个变量,变量具体情况见下表;想分析影响不同街区下人口分布的潜在因子。
第一步:数据预处理和分析:
新增“人口密度”特征,删除特征人口量、面积、经度和维度。
import pandas as pd
import numpy as np
LA_data = pd.read_csv('LA.Neighborhoods.csv')
# 新增人口密度,去掉人口量、面积、经度和维度
LA_data['density'] = LA_data['Population']/LA_data['Area']
LA_data_final = LA_data.drop(['Population','Area','Longitude','Latitude'],axis=1)
LA_data_final_feat = LA_data_final.drop(['LA_Nbhd'],axis=1)
第二步:因子分析——充分性检验
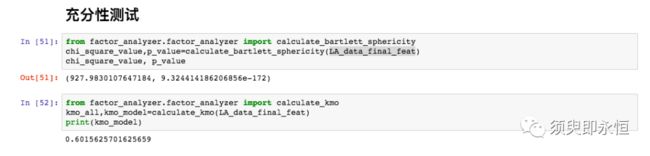
巴特利特P值小于0.01,KMO值大于0.6;说明此数据适合做因子分析。
# 计算巴特利特P值
from factor_analyzer.factor_analyzer import calculate_bartlett_sphericity
chi_square_value,p_value=calculate_bartlett_sphericity(LA_data_final_feat)
chi_square_value, p_value
# 计算KMO值
from factor_analyzer.factor_analyzer import calculate_kmo
kmo_all,kmo_model=calculate_kmo(LA_data_final_feat)
print(kmo_model)
第三步:因子个数确定
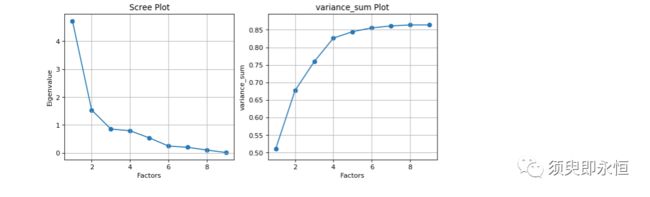
特征值大于1的因子数有2个,且两个因子的累计方差有68%;因此确定因子个数为2个。
# Create factor analysis object and perform factor analysis
from factor_analyzer import FactorAnalyzer
fa = FactorAnalyzer(LA_data_final_feat.shape[1]+1, rotation=None)
fa.fit(LA_data_final_feat)
ev, v = fa.get_eigenvalues() # 计算特征值和特征向量
var = fa.get_factor_variance()#给出方差贡献率
第四步:做因子分析
调用因子分析函数,并得到因子载荷矩阵;从载荷矩阵可以看到,第一个因子和收入、有房家庭比例、复员军人比例及欧裔比例成正相关;第二个因子和非裔比例成正相关,反而和收入及有房比例等成负相关。
fa = FactorAnalyzer(2, rotation="varimax")
fa.fit(LA_data_final_feat)
# 输出载荷矩阵
df_loading = pd.DataFrame(fa.loadings_,index=LA_data_final_feat.columns.tolist())
df_loading

第五步:计算因子得分
其中因子1得分越大表示:收入、有房家庭比例、复员军人比例及欧裔比例更高;因子2得分高表示:非裔人群比例更高。
#计算因子得分
LA_data_trans = pd.DataFrame(fa.transform(LA_data_final_feat),index=LA_data_final['LA_Nbhd'])
#以散点图的形式呈现
plt.figure(figsize=(10,4), dpi= 80)
plt.subplot(1,2,1)
plt.scatter(LA_data_trans.loc[:,0],LA_data_trans.loc[:,1])
plt.title('Scree Plot')
plt.xlabel('Factor1')
plt.ylabel('Factor2')
plt.grid()
综上,以上就是本文要介绍的全部内容;因子分析在互联网数据分析场景下用到的比较少,主要原因就是很多人不知道怎么用?不知道用到哪里?希望看完文章的你能初步了解因子分析,能知道下面几个问题的答案(不记得就回头看上面的介绍分享哦)。
什么是因子分析?
因子分析可以解决什么问题?
因子分析的算法逻辑和分析流程是什么?
Python代码如何实现?