使用tensorflow快速搭建 DQN环境
使用tensorflow快速搭建 DQN环境
- 使用tensorflow快速搭建 DQN环境
-
- 1建立网络
-
- 基本需要使用的参数
- 网络结构
- 2 网络的使用
- 3 训练网络
- 总结
使用tensorflow快速搭建 DQN环境
本文章主要是用来快速搭建DQN环境的,个人感觉写的还是比较清晰的,借鉴了莫烦python和其他友友们的网络搭建方法。我的代码是有两个agent的,两个玩家交替更新,代码在: https://github.com/nsszlh/tensorflow-DQN
1建立网络
基本需要使用的参数
class AgentNet():
def __init__(
self,
name,
n_action,
n_state,
learning_rate=0.001,
reward_decay=0.9,
e_greedy=0.9,
replace_target_iter=300,
memory_size=50000,
batch_size=32,
e_greedy_increment=None
):
self.n_action = n_action #action个数
self.n_state = n_state #state 个数
self.alpha = learning_rate #学习率
self.gamma = reward_decay # QLearning函数参数
self.epsilon_max = e_greedy #贪心
self.replace_target_iter = replace_target_iter # 每iter次复制一次eval网络参数给target网络
self.memory_size = memory_size #记忆库容量
self.batch_size = batch_size #每批学习的个数
self.epsilon_increment = e_greedy_increment #逐步增大贪心比例
self.epsilon = 0 if e_greedy_increment is not None else self.epsilon_max
self.name = name #给多个agent建立网络时
self.sess = sess
self.build()
self.learn_step_counter = 0
self.memory = []
self.losses = []
'''复制网络'''
t_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='target_net')
e_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='eval_net')
with tf.variable_scope('hard_replacement'):
self.target_replace_op = [tf.assign(t, e) for t, e in zip(t_params, e_params)]
网络结构
def build(self,hidden_dim=64):
with tf.variable_scope(self.name):
self.s = tf.placeholder(tf.float32, [None, self.n_state], name='s') # input State
self.s_ = tf.placeholder(tf.float32, [None, self.n_state], name='s_') # input Next State
self.r = tf.placeholder(tf.float32, [None, ], name='r') # input Reward
self.a = tf.placeholder(tf.int32, [None, ], name='a') # input Action
with tf.variable_scope("eval_net"):
hidden = tf.layers.dense(self.s,hidden_dim,activation=tf.nn.relu)
hidden = tf.layers.dense(hidden, hidden_dim, activation=tf.nn.relu)
self.q_eval = tf.layers.dense(hidden,self.n_action)
with tf.variable_scope("target_net"):
hidden = tf.layers.dense(self.s_, hidden_dim, activation=tf.nn.relu)
hidden = tf.layers.dense(hidden, hidden_dim, activation=tf.nn.relu)
self.q_next = tf.layers.dense(hidden, self.n_action)
with tf.variable_scope('q_target'):
q_target = self.r + self.gamma * tf.reduce_max(self.q_next, axis=1, name='Qmax_s_')
self.q_target = tf.stop_gradient(q_target)
with tf.variable_scope("q_eval"):
a_indices = tf.stack([tf.range(tf.shape(self.a)[0], dtype=tf.int32), self.a], axis=1)
self.q_eval_wrt_a = tf.gather_nd(params=self.q_eval, indices=a_indices)
with tf.variable_scope("loss"):
self.loss = tf.reduce_mean(tf.squared_difference(self.q_target, self.q_eval_wrt_a, name='TD_error'))
with tf.variable_scope('train'):
self._train_op = tf.train.RMSPropOptimizer(self.alpha).minimize(self.loss)
其含义是:
- 首先建立{s,q_eval}和{s_,q_next}的网络对应关系,
- 然后根据DQN的学习公式:
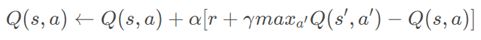
计算 q_target,由于此时q_target是一个张量,是由wx+b得到的,如果下一步更新的话同样也会更新它的参数,因此使用tf.stop_gradient(q_target)停掉该网络的更新
计算self. q_eval_wrt_a得到要更新的动作a的Q(s,a) - 计算loss并使用train根据loss更新网络的参数
2 网络的使用
在与环境互动时采用
action = net.choose_action(obs)
选择动作,其中net.choose_action(state)函数是这么定义的:
def choose_action(self,state):
if np.random.random() > self.epsilon:
action_chosen = np.random.randint(0, self.n_action)
else:
state = state[np.newaxis, :]
actions_value = self.sess.run(self.q_eval, feed_dict={self.s: np.array(state)})
action_chosen = np.argmax(actions_value)
return action_chosen
按照贪心策略执行动作,当贪心时根据当前状态s运算得到q_eval,取最大值的动作返回
3 训练网络
Transition = collections.namedtuple("Transition", ["state", "action", "reward", "next_state"])
'''执行eposide次环境'''
if len(net.memory) > net.memory_size:
net.memory.pop(0)
reward = reward if player=="agent_0" else -reward
net.memory.append(Transition(obs, action, reward, next_obs))
if len(net.memory) > net.batch_size * 4:
batch_transition = random.sample(net.memory, net.batch_size)
batch_state, batch_action, batch_reward, batch_next_state = map(np.array, zip(*batch_transition))
loss = net.train(state=batch_state,
reward=batch_reward,
action=batch_action,
state_next=batch_next_state,
)
update_iter += 1
net.losses.append(loss)
首先,在每次执行完成后将{s,a,r,s_} 存入memory中,当积累到一定量之后,按批次提取memory并训练网络,net.train函数定义如下
def train(self,state,reward,action,state_next):
if self.learn_step_counter % self.replace_target_iter == 0:
self.sess.run(self.target_replace_op)
# print('\ntarget_params_replaced\n')
_,loss = self.sess.run([self._train_op,self.loss],
feed_dict={
self.s:np.array(state),
self.s_:np.array(state_next),
self.a:np.array(action),
self.r:np.array(reward)
})
self.learn_step_counter += 1
# increasing epsilon
self.epsilon = self.epsilon + self.epsilon_increment if self.epsilon < self.epsilon_max else self.epsilon_max
self.learn_step_counter += 1
return loss
其中第一行是每隔多少步将eval_net的网络参数复制给target_net网络,其定义在类的init中.
self.sess.run()将收集到的(s,a,s_,r)传入tensorflow中,运行网络得到loss并更新了网络
。
总结
其实就是建立一个网络,然后在每次执行action时调用网络,收集数据后训练网络,没了。
等我会用github时将函数传上去