Machine Learning - Advice for Applying ML: Evaluating a hypothesis
- Computer
- Vision
- Machine
- Learning
- algorithm
- Bin博的机器视觉工作间
- Algorithm
- Machine
- Learning
- Evaluation
- test
- set
- training
- set
This series of articles are the study notes of " Machine Learning ", by Prof. Andrew Ng., Stanford University. This article is the notes of week 6, Advice for Applying Machine Learning. This article contains some topic about how to evaluating a hypothesis
Advice for Applying Machine Learning
By now we have seen a lot of different learning algorithms. And if you've been following along these videos you should consider yourself an expert on many state-of-the-art machine learning techniques. But even among people that know a certain learning algorithm. There's often a huge difference between someone that really knows how to powerfully and effectively apply that algorithm, versus someone that's less familiar with some of the material that I'm about to teach and who doesn't really understand how to apply these algorithms and can end up wasting a lot of their time trying things out that don't really make sense. What I would like to do is make sure that if you are developing machine learning systems, that you know how to choose one of the most promising avenues to spend your time pursuing.
1. Deciding What to Try Next
Debugging a learning algorithm

Now suppose that after you take your learn parameters,if you test your hypothesis on the new set of houses, suppose you find that this is making huge errors in this prediction of the housing prices.
What should you then try next in order to improve the learning algorithm?
There are many things that one can think of that could improve the performance of the learning algorithm.
- Get more training examples
- Try smaller sets of features
- Try getting additional features
- Try adding polynomial features (x1, x2, x1x2, etc)
- Try decreasing λ
- Try increasing λ
(2) Other things you might try are to well maybe try a smaller set of features. So if you have some set of features such as x1, x2, x3 and so on, maybe a large number of features. Maybe you want to spend time carefully selecting some small subset of them to prevent overfitting.
(3) Or maybe you need to get additional features. Maybe the current set of features aren't informative enough and you want to collect more data in the sense of getting more features. And once again this is the sort of project that can scale up the huge projects can you imagine getting phone surveys to find out more houses, or extra land surveys to find out more about the pieces of land and so on, so a huge project. And once again it would be nice to know in advance if this is going to help before we spend a lot of time doing something like this. We can also try adding polynomial features things like x2 square x2 square and product features x1, x2.
(4) We can still spend quite a lot of time thinking about that and we can also try other things like decreasing lambda, the regularization parameter or increasing lambda.
Given a menu of options like these, some of which can easily scale up to six month or longer projects. Unfortunately, the most common method that people use to pick one of these is to go by god feeling. In which what many people will do is sort of randomly pick one of these options and maybe say, "Oh, lets go and get more training data." And easily spend six months collecting more training data or maybe someone else would rather be saying, "Well, let's go collect a lot more features on these houses in our data set." And I have a lot of times, sadly seen people spend, you know, literally 6 months doing one of these avenues that they have sort of at random only to discover six months later that that really wasn't a promising avenue to pursue.
Machine learning diagnostic
2. Evaluating a hypothesis
Evaluating your hypothesis
Hypothesis can overfit
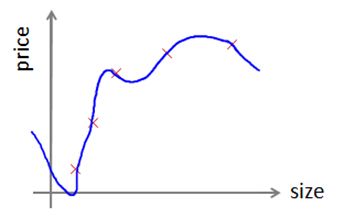
How do you tell if the hypothesis might be overfitting

70%, 30% split of the data set

And so now, if we have some data set, we run 70% of the data to be our training set where here "m" is as usual our number of training examples and the remainder of our data might then be assigned to become our test set. And here, I'm going to use the notation m test to denote the number of test examples.
Randomly sort the data set
Training/testing procedure for linear regression
Here then is a fairly typical procedure for how you would train and test the learning algorithm and the learning regression.
Learn parameter θ from training data
Learn parameter θ from training data (minimizing training errorJ(θ) )
First, you learn the parameters theta from the training set so you minimize the usual training error objective j of theta, where j of theta here was defined using that 70% ofall the data you have. There is only the training data. And then you would compute the test error.
Compute test set error of Linear Regression

So this is basically the average squared error as measured on your test set. This is the definition of the test set error if we are using linear regression and using the squared error metric.
Training/testing procedure for logistic regression
Learn parameter θ from training data
Learnparameter θ from training data(minimizing training errorJ(θ) )
First, you learn the parameters theta from the training set so you minimize the usual training error objective j of theta, where j of theta here was defined using that 70% of all the data you have. There is only the training data. And then you would compute the test error.
Compute test set error of logistic regression
How about if we were doing a classification problem and say using logistic regression instead.In that case, the procedure for training and testing say logistic regression is pretty similar first we will do the parameters from the training data, that first 70% of the data. And it will compute the test error as follows.
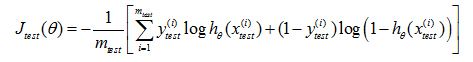
Misclassification error (0/1 misclassification error):