【Linux操作系统】计算机体系结构和操作系统与进程概念深入理解

文章目录
- 一.现代计算机体系结构
-
- 1.和冯诺依曼体系结构的异同
- 2.计算机的五大核心部件
- 3.举例子:“我爱你”
- 4.CPU,内存,磁盘的联系
-
-
- a.三者读写速度对比
- b.规定:CPU不直接和外设打交道
-
- 二.操作系统
-
- 1.操作系统三段论
- 2.系统调用接口
- 3.用户操作接口
- 三.进程
-
- 1.什么是进程?
- 2.PCB
- 3.查看进程
- 4.见见与系统相关的系统调用
-
- 招式1:getpid查看当前进程的ID
- 招式2:另一种查看进程的方式(了解)
- 招式3:gettpid查看父进程的ID
- 5.fork创建子进程
一.现代计算机体系结构
1.和冯诺依曼体系结构的异同
现代计算机体系结构是以冯诺依曼体系结构(又叫普林斯顿结构)为基础发展起来的!
- 异:,冯诺依曼体系结构是以运算器为核心部件,而现代计算机体系结构做出优化, 以存储器为核心部件.
- 同: 二者都描述计算机硬件之间的关系和硬件层面的数据流向.

2.计算机的五大核心部件
- 运算器:用来做算术(加减乘除)计算和逻辑(与、或、非)计算;
- 存储器:用来存放程序和数据;
- 控制器:控制程序的运行;
- 输入设备:输入信息,比如磁盘、键盘、鼠标等;
- 输出设备:输出信息,比如磁盘、打印机、显示器等;
特别:
- 输入设备和输出设备合称外设,CPU和存储器合称主机
- 磁盘和网卡即是输入设备,也是输出设备(可读可写的外设)
- 中央处理器(CPU): 主要包含运算器和控制器等
- 现代计算机体系结构中的存储器指的是内存,掉电易失;磁盘属于外存,永久性存储.
3.举例子:“我爱你”
当你通过QQ发送一条“我爱你”给你女朋友(如果有的话),到你女朋友接收到“我爱你”这整个过程:让我们看看数据在硬件层上的流向:

这里网卡即是输出设备也是输入设备
4.CPU,内存,磁盘的联系
a.三者读写速度对比
速度从大到小排序:CPU>内存>磁盘
假如没有内存, 我们知道磁盘是永久性保存代码和数据的地方,由于CPU处理代码和数据的速度非常快,但是从磁盘中读取代码和数据的速度非常慢,导致磁盘的供应根本来不及,由于磁盘一个硬件,拖垮了整个计算机!
但是,因为存在内存且从内存读写代码和数据的速度远大于磁盘,所以我们可以把CPU接下来可能要读取到的代码和数据从磁盘提前加载到内存,作为一个临时的“仓库”,所以CPU在读取数据的时候就可以直接从内存中读取,这样就提升了整个计算机的效率!
如果把CPU比作一个加工车间,硬盘比作一个存储原料和产品的大仓库,那么内存就是一个临时的小仓库,通过这种方式,整个车间的生产效率才能提高!

b.规定:CPU不直接和外设打交道
由于上面的论述, 冯诺依曼体系结构规定, CPU 永远不和外设直接打交道,他们之间的交互都必须通过中间站-内存来实现!
到这里我们也能理解我们常说的一句话:一个程序要想运行起来,必须要先被加载到内存.
那是因为程序没有被运行起来的时候,它是静静地躺在硬盘上的,而只有把程序加载到内存中,CPU才能分析并执行到程序中的指令,实现对应的功能.
二.操作系统

1.操作系统三段论
- 是什么
- 为什么
- 怎么做
- 操作系统是什么?
一个负责软硬件资源管理的软件
操作系统的定位:一个纯“搞管理”的软件
- 为什么要有操作系统?
操作系统只有对下合理的管理好软硬件资源,才能给上层用户提供稳定,高效,安全的运行环境!
- 操作系统怎么做管理?
a. 管理者和被管理者一般都是不相互见面,而是通过分析被管理者的数据了解被管理者的情况,比如校长管学生,是通过分析导员给校长的成绩数据;
b. 管理分为决策和执行,校长是决策,导员是执行;
管理的本质:是对数据的管理
管理的方法: 先描述,再组织
描述起来: 抽取对象属性,使用struct 结构体–面向对象的思想
组织起来: 用链表等数据结构去分析数据(增删查改,比较大小)—数据结构的方法
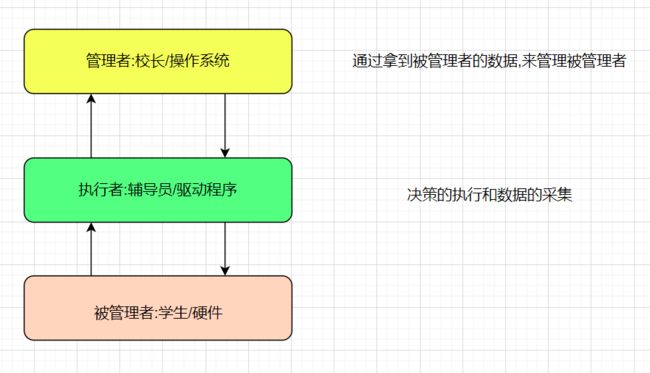
驱动:驱赶你动起来,执行者角色
2.系统调用接口
正如大家熟知:
- 银行里存有很多钱,树大招风
- 银行不相信任何人
- 银行要给我们提供各种存取服务
所以银行构建了一个厚实玻璃,并开有小窗口,保证自身安全的同时达到提供存取服务的目的.
银行系统如此, 其实操作系统也是如此
- 操作系统管理这很多硬件资源
- 操作系统不相信任何用户
- 操作系统要给用户提供各种服务
所以操作系统提供了很多系统调用接口,保证用户行为处于监管的同时达到提供服务的目的.
ps:操作系统都是C语言写的,所以推测系统调用肯定也是C语言写的!
结论:用户要访问硬件,必须通过OS提供的系统调用接口,用户提供参数,操作系统帮你完成后,用户接收返回值.
系统调用接口举例: fork,getpid

3.用户操作接口
使用系统调用的人应该具备:
- 熟悉操作系统
- 熟悉各种选项
但是别说普通用户,乃至一些科班学生都无法正确按需使用系统调用接口!
所以我们还需要再提供一层封装:(用户可能使用下列的一种或多种方式)
- 用户通过指令操作,在shell上执行命令行操作
- 用户通过编程操作,调用C/C++库
- 用户通过点击鼠标,完成窗口操作
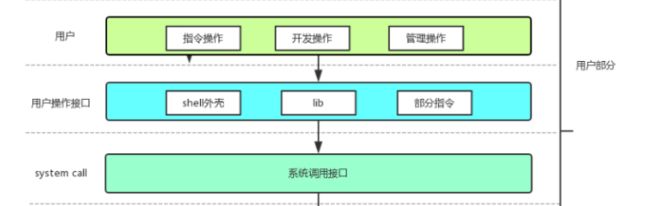
再次理解我们printf(“hello world\n”);
- 错误认知:我们调用函数直接访问硬件,向显示器打印结果
- 正确认知:我们提供数据,调用接口,操作系统帮我们访问硬件完成打印

所以我们学C/C++本质是在学习用户操作接口的C/C++库函数的层次.
ps:
- 库函数: 用户操作接口是系统调用接口的封装,库函数是用户操作接口的一种!
- 第一方库:系统的
第二方库:自己的
第三方库:别人的
三.进程
1.什么是进程?
- 课本概念:一个运行起来(加载到内存)的程序叫进程./在内存中的程序叫进程./进程和程序相比,进程具有动态属性.
- 逻辑链:程序是我们写好的二进制代码,存放在磁盘上,由冯诺依曼体系结构规定,要运行起来必须要加载到内存,当加载到内存中的程序增多,操作系统就必须得管理起来,管理的方式=先描述,再组织,描述就是用一个task_struct结构体,再组织就是运用相关的数据结构,只需构建并管理好结构体对象pcb(比如增删查改等)就能管理好对应的进程。
- 进程概念:进程=内核数据结构(task_struct) + 进程对应的磁盘代码
其中进程对应的磁盘代码是PCB需要的,内核数据结构是操作系统管理进程需要的,当CPU说我需要QQ进程的代码和数据,操作系统只需遍历一遍链表就可以找到QQ进程对应的PCB,进而找到QQ进程的代码和数据,从而交给CPU处理。
磁盘上的代码和数据被加载到内存,操作系统为了管理还得多做一步,为对应的进程创建PCB。

因为进程是位于操作系统内部,所以对进程相应的操作,比如getpid(),getppid()都必须使用系统调用接口。
2.PCB
对多个从硬盘被加载到内存的程序,操作系统必须要管理这个内存,那如何管理?
管理的方式:先描述在组织!

用task_struct结构体描述:
标示符: 描述本进程的唯一标示符,用来区别其他进程。
状态: 任务状态,退出代码,退出信号等。
优先级: 相对于其他进程的优先级。
程序计数器: 程序中即将被执行的下一条指令的地址。 内存指针: 包括程序代码和进程相关数据的指针,还有和其他进程共享的内存块的指针
上下文数据: 进程执行时处理器的寄存器中的数据[休学例子,要加图CPU,寄存器]。
I/O状态信息: 包括显示的I/O请求,分配给进程的I/O设备和被进程使用的文件列表。
记账信息: 可能包括处理器时间总和,使用的时钟数总和,时间限制,记账号等。

所谓对进程的管理,变成了对进程对应的PCB进行管理,对进程对应的链表进行增删查改。
3.查看进程
a. mypro.c:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CyPiNnGF-1673587725694)(C:\Users\21677\AppData\Roaming\Typora\typora-user-images\image-20230112161752867.png)]
b. makefile:

c. make编译后,./mypro运行
显示系统中所有的进程:
ps axj
显示的标题:
ps axj | head -1
显示名为myproc的进程信息:
ps axj | grep 'mypro'
查看mypro进程状态并附上标题:
ps axj | head -1 && ps axj | grep 'mypro'

d. 杀掉mypro进程:
kill -9 mypro的PID(2358)

或者直接ctrl+c杀掉进程(kill -9可以杀掉更顽固的进程)
4.见见与系统相关的系统调用
招式1:getpid查看当前进程的ID
a. man手册查看主角getpid
man getpid

b. 在原来mypro.c的基础上稍作修改:
printf("I am a process!pid:%d\n",getpid());
c. make后运行:

特点:每一次./mypro运行,都会重新分配pid:

招式2:另一种查看进程的方式(了解)
a. 根目录下有一目录proc:

b. 查看内存级目录/proc/下的文件:
ll /proc/
数字开头的文件是进程的文件,数字就是进程ID,说明一个进程也可被当作文件看待:

c. 查看进程的存在

d. 杀掉进程=>文件不存在

招式3:gettpid查看父进程的ID
a. 在原来mypro.c的基础上稍作修改:
printf("I am a process!pid:%d,getppid:%d\n",getpid(),getppid());
b.make后两次运行:

分析: 为什么PID变化,PPID并没有变化?
PID变化:
我们知道进程=内核数据结构+进程所对应的磁盘代码
代码虽然是同一份代码和数据,但是两次加载到内存,其内核数据结构肯定会有一定的变化,所以PID肯定会有所变化.
PPID不变:
我们登入,操作系统就给我们指派了一个shell/bash,就好比我们出生的时候,村里就有一个王婆为我们服务。
命令行上启动的进程,父进程如果没有特殊情况的话,都是bash,所以PPID不变。
父进程bash派子进程去执行各种命令行上启动的进程,从而完成用户给予的任务。当子进程运行失败的时候,并不会影响父进程,而是提供一个报错信息给用户,让用户再改一改。

5.fork创建子进程
ps: 我们用的是C语言的编码方式,但是接口没有用库,而是直接用的系统调用接口。
mypro.c:

make后运行:

fork函数返回值详解:
RETURN VALUE
On success, the PID of the child process is returned in the parent, and 0 is returned in the child. On failure,
-1 is returned in the parent, no child process is created, and errno is set appropriately.
返回值
fork调用成功,子进程的ID将返回给父进程,0将返回给子进程
fork调用失败,-1将返回给父进程,没有子进程被创建,错误码将被设置
也就是fork如果调用成功,将有两个返回值,子进程的ID将返回给父进程,0将返回给子进程.


我的博客即将同步至腾讯云开发者社区,邀请大家一同入驻:https://cloud.tencent.com/developer/support-plan?invite_code=3geefxzl9uo0s