Bellman Equation 贝尔曼方程
Bellman equation(贝尔曼方程),是以Richard E.Bellman命名,是数值最优化方法的一个必要条件,又称为动态规划。它以一些初始选择的收益以及根据这些初始选择的结果导致的之后的决策问题的“值”,来给出一个决策问题在某一个时间点的“值”。这样把一个动态规划问题离散成一系列的更简单的子问题,这就是bellman优化准则。
Bellman equation最早应用于工程控制理论和其他的应用数学领域,之后成为了经济学理论的重要工具。但是其基本概念是在John von Neumann和Oskar Morgenstern的《Theory of Games and Economic Behavior 游戏和经济行为理论》,以及Abraham Wald的《sequential analysis顺序分析》中提出的。
几乎任何可以通过最优化控制理论解决的问题都可以通过分析合适的Bellman方程来解决。但是,一般Bellman方程常用于离散时间优化问题中的动态规划问题。在连续时间优化问题上,通常使用一种类似的偏微分方程,Hamilton-Jacobi-Bellman方程。
目录
1. 动态规划中的解析概念
2. 起源
2.1 一种动态决策问题
2.2 贝尔曼最优化理论
2.3 贝尔曼方程
2.4 在随机问题中的应用
3. 解决方法
4. 在经济学中的应用
5. 例子
1. 动态规划中的解析概念
要理解贝尔曼方程,必须理解几个基本概念。
目标函数(objective functions):任何优化问题都有一些目标:最小化旅行时间、最小化成本、最大化利润、最大化效用等。描述这个目标的数学函数称为目标函数。最优化的最终目的都是调整参数使这些目标函数最大或最小。
状态(states):动态规划将多周期规划问题分解成不同时间点的简单步骤。因此,它需要跟踪决策情况是如何随时间演变的。关于做出正确决策所需的当前情况的信息被称为“状态”。例如,为了决定在每一个时间点消耗和花费多少,人们需要知道(除了其他的事情)他们最初的财富。因此,财富将是它们的状态变量之一,但可能还有其他变量。
控制变量(control variables):在任何给定时间点选择的变量通常被称为控制变量。例如,考虑到他们目前的财富,人们可能会决定现在消费多少。现在选择控制变量可能相当于选择下一个状态(财富是“状态”,消费是“控制变量”);更一般地说,除了当前的控制之外,下一个状态也受到其他因素的影响。例如,在最简单的情况下,今天的财富(状态)和消费(控制)可能准确地决定明天的财富(新的状态),尽管通常其他因素也会影响明天的财富。
策略函数(policy function):动态规划方法通过找到一个规则来描述最优计划,它给出了给定状态的任何可能值的控制应该是什么。例如,如果消费(C)仅依赖于财富(W),我们将寻求一个规则,它将消费(控制)作为财富(状态)的函数。这样的规则,将控制写成由状态作为变量的函数,称为策略函数。控制=F(状态)。
最优决策规则(the optimal decision rule):最后,根据定义,最优决策规则是达到目标的最佳可能值的规则。例如,如果有人根据财富,选择消费以使幸福最大化(假设幸福H可以由数学函数来表示,例如效用函数(utility function),并且是由财富定义的东西),那么每一个财富W水平将与一些最高可能的幸福水平H(W)相关联。这里幸福H是目标函数,消费是控制,财富是状态。
值函数(value function):目标的最佳可能值为值函数(大概是因为是估计出来的,所以有个最佳可能,后续理解了再改正)。目标是以状态为变量的函数。
贝尔曼方程(Bellman Equation):理查德·贝尔曼表明,离散时间的动态优化问题可以通过建立一个周期内的值函数与下一个周期的值函数之间的关系,结合向后归纳(一种递归的、分步的形式)的方式来表示。这两个值函数之间的关系称为“贝尔曼方程”。
在该方法中,在最后一个时间段中的最优策略预先指定为一个以当前状态变量的值(财富W)为变量的函数,并且由此得到的目标函数(H(W))的最佳值,以当前状态变量值(W)表示。
接下来,倒数第二个时间段的优化,包括最大化该周期的特定目标函数和未来(最后一个时间段)目标函数的最优值的总和,给出该周期的取决于状态变量的最优策略,作为倒数第二个时间段的决策。该逻辑在时间上递归地返回,直到第一周期决策规则作为初始状态变量值的函数而导出,该值通过优化第一周期特定目标函数和第二周期值函数的值的总和,包含了所有未来周期的值。因此,每个周期的决定是通过明确承认所有未来的决策将是最佳的。
2. 起源
2.1 一个动态规划问题
定义时刻  时的状态为
时的状态为  。
。
对于0时刻的决策,我们给定初始状态  .
.
在任意时刻,有一组基于当前状态可能的动作(控制变量);把它写作 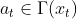 ,此处的
,此处的  表示一个或多个控制变量。这个式子的意思是当前状态采取的动作要在可能的范围内,比如你有100块钱,在不赊账的情况下你不可能花掉200块钱,你的可能消费只能在0到100元之间。
表示一个或多个控制变量。这个式子的意思是当前状态采取的动作要在可能的范围内,比如你有100块钱,在不赊账的情况下你不可能花掉200块钱,你的可能消费只能在0到100元之间。
我们同样假设:当执行动作  后,当前状态从
后,当前状态从  变为新的状态
变为新的状态 ![]() ,且当前的回报(通过在 状态,执行 动作得到的回报)为
,且当前的回报(通过在 状态,执行 动作得到的回报)为 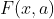 。
。
最后我们定义impatience, 即折扣因子(discount factor)为 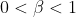 。
。
基于以上假设,无限时域决策问题可以写成如下形式:

其满足以下约束:
![]()
注意,我们定义了符号![]() 来表示最优值,这个最优值是通过最大化满足假设约束条件的目标函数值来获得的。这个函数就是“值函数”,它是一个与初始状态有关的函数,因为可以获得的最好的值取决于初始状态。
来表示最优值,这个最优值是通过最大化满足假设约束条件的目标函数值来获得的。这个函数就是“值函数”,它是一个与初始状态有关的函数,因为可以获得的最好的值取决于初始状态。
2.2 贝尔曼优化策略
动态规划方法把决策问题离散为更小的子问题。Richard Bellman的优化策略描述了这个过程:
优化策略:最优策略的性质是,无论初始状态和初始决策是什么,其余的决策必须构成关于第一决策所导致的状态的最优策略。(换成人话就是:无论你最初做了多么SB的决定,生活还是要继续,最优策略要保证你能在当初做的那个决定的影响下获得你能达到的最幸福美满的人生。)
在计算机科学中,一个可以像这样分解的问题被认为具有最佳的子结构。在动态博弈论的背景下,这一原理类似于子博弈完全均衡的概念,虽然在这种情况下构成最优策略的条件是由决策者的对手从他们的观点中选择相似的最优策略。
根据最优性原理的建议,我们将单独考虑第一个决定,抛开所有未来的决定(我们将从时刻 1 的新的状态  重新开始)。在右边括号中收集未来的决定,以前的问题相当于:
重新开始)。在右边括号中收集未来的决定,以前的问题相当于:
满足以下约束:
这里我们选择了 , 因此我们的选择会导致时刻 1 时状态变成 .
新的状态会对时刻1以后的决策有影响。整个未来决策问题出现在右边的方括号中。
2.3 贝尔曼方程
到目前为止,我们似乎只是把今天的决定与未来的决定分开了。但是我们可以注意到右边的方括号内的内容是时刻1的决策问题的值,从状态 开始,基于上述条件可以对式子进行简化。
因此,我们可以将问题重新定义为值函数递归:
上式满足以下约束:
上式就是贝尔曼方程。(天哪!终于写到这里了!)
去掉一些时间下标,代入下一时刻的值,它还可以被进一步简化为如下形式:
贝尔曼方程被归类为函数方程(functional equation),因为求解它意味着寻找未知函数V,即函数值。回想一下,价值函数描述了目标的最佳可能值,作为状态X的函数。通过计算值函数,我们还会发现函数 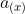 ,它描述了作为状态的函数的最优动作;这被称为策略函数。
,它描述了作为状态的函数的最优动作;这被称为策略函数。
2.4 一个随机问题的应用
在确定性设置中,除了动态规划之外,还可以使用其他技术来解决上述最优控制问题。然而,Belman方程往往是求解随机最优控制问题最方便的方法。
对于经济学的一个具体例子,考虑一个无限寿命消费者在时刻 时有财富 。
他有一个瞬时(utility function)效用函数 , 表示消费,并将下一个周期的效用以 的速率来打折。
假设周期 中没有发生消费,财富以进入下一周期,利率为 。
那么,这个消费者的效用最大化问题可以写成:选择一个消费计划 ,使下式中右边的方程最大:
上式满足约束 :
第一个约束是由问题指定的资本积累/运动规律,而第二个约束是一个横截(边界)条件,即消费者在他生命结束时不承担债务。贝尔曼方程
![]()
或者,也可以直接使用哈密顿方程来处理序列问题。
如果利率随着周期变化,那么消费者则面对的是一个随机优化问题。
假设利率是一个马尔可夫过程,其概率转移函数为 ,如果当前利率是 的话, 表示下一周期的利率分布的概率测量,模型的时刻是消费者在当前利率公布之后决定当前周期的消费。
消费者现在必须给每个可能的实现 选择一个序列,而不是简单地选择一个序列 ,以使他的在此生能获得的期望效用最大化。
由以 r 为参数的Q给出一个合适的概率测量值,并由此计算出期望值 .
由于 r 受马尔可夫过程控制,动态规划将这个问题显著简化了。贝尔曼方程
在合理的假设下,得到的最优策略函数 g(a,r) 是可测量的。
对于具有Markovian冲击的一般随机序贯优化问题,在代理人面临决策的情况下,贝尔曼方程具有非常相似的形式。
3. 解决方法
待定系数的方法,也称为“猜测和验证”,可以用来解决一些无限时域自治贝尔曼方程。
Bellman方程可以通过反向归纳来求解,无论是在特殊情况下还是在计算机上进行数值分析。数值向后归纳法适用于各种各样的问题,但由于维数灾难,当存在许多状态变量时可能是不可行的。D. P. Bertsekas和J. N. Tsitsiklis引入了近似动态规划,利用人工神经网络(多层感知器)来逼近贝尔曼函数。这是一种有效的缓解策略,通过替换完备函数映射的记忆来减少维数的影响。对于整个空间域具有记忆唯一的神经网络参数。
通过计算与Bellman方程相关的一阶条件,然后利用包络定理消除数值函数的导数,可以得到一个差分方程或微分方程组,称为“Euler方程”。求解差分或差分的标准技术。ILE方程可以用来计算状态变量的动态和优化问题的控制变量。
4. 例子
在马尔可夫过程中,贝尔曼方程是向后迭代的。例如,对于一个特定状态s,一个固定策略  ,其期望的奖励的贝尔曼方程为:
,其期望的奖励的贝尔曼方程为:
![]()
这个方程表示采取了策略 规定的动作后的期望奖励。
这个最优策略的方程称为Belman最优方程:
![]()
其中![]() 是优化策略,
是优化策略,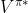 是最优策略的值函数。上面的等式描述了达到最高预期的行动对应的奖励。
是最优策略的值函数。上面的等式描述了达到最高预期的行动对应的奖励。
以上内容翻译自维基百科,只添加了部分自己的理解。
原文地址:https://en.wikipedia.org/wiki/Bellman_equation#Bellman's_Principle_of_Optimality