基于 Python 环境搭建 - YOLO 实现吸烟行为监测
作者|李秋键
出品|AI科技大本营(ID:rgznai100)
引言
目标检测是一种与计算机视觉和图像处理有关的计算机技术, 用于检测数字图像和视频中特定类别的语义对象 (例如人、建筑物或汽车等), 其在视频安防,自动驾驶, 交通监控, 无人机场景分析和机器人视觉等领域有广阔的应用前景。近年来, 由于卷积神经网络的发展和硬件算力提升, 基于深度学习的目标检测取得了突破性的进展。目前, 深度学习算法已在计算机视觉的整个领域得到广泛采用, 包括通用目标检测和特定领域目标检测. 大多数最先进的目标检测算法都将深度学习网络用作其骨干网和检测网络, 分别从输入图像 (或视频), 分类和定位中提取特征。
目标检测包括分类和定位两方面。目标检测应用领域广泛,包括人脸检测、行人检测、车辆检测等。由于检测物体形状各异,实际场景存在背景复杂、遮挡严重及光照影响等问题,设计高精度的检测模型具有很大挑战。传统的目标检测算法分为3个步骤,如下图所示。
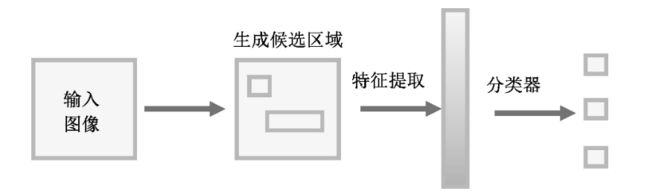
(1)候选区域选择:
通常使用滑动窗口算法,通过不同大小的滑窗在输入图像上划定目标可能存在的区域,对目标进行初步定位。
(2)特征提取:
使用局部二值模式、方向梯度直方图等算法对候选区域进行特征提取。
(3)分类:
通过支持向量机、Adaboost等算法对提取的图像特征进行分类。
传统目标检测算法没有针对性地使用滑动窗口去检测目标,不仅效率低,准确率也不高,而且人工选择的特征对于形状各异的不规则物体鲁棒性较差。随着深度学习技术的发展,利用卷积神经网络提取图像特征,从而实现目标检测,已成为机器视觉领域研究的热点之一。
目前,基于深度学习的目标检测方法主要有两大分支,分别是基于区域提取的两阶段目标检测模型和直接进行位置回归的一阶段目标检测模型。
故本项目通过采用深度学习方法实现对吸烟行为的目标检测,使用python语言搭建YOLO算法实现对吸烟行为的实时监测。其最终实现效果如下图可见:

1、基本介绍
1.1 环境要求
本次环境使用的是python3.6.5+windows平台。主要用的库有:
opencv模块。在计算机视觉项目的开发中,opencv作为较大众的开源库,拥有了丰富的常用图像处理函数库,采用C/C++语言编写,可以运行在Linux/Windows/Mac等操作系统上,能够快速的实现一些图像处理和识别的任务。
numpy模块。numpy系统是Python的一种开源的数值计算扩展。这种工具可用来存储和处理大型矩阵,比Python自身的嵌套列表结构要高效得多(该结构也可以用来表示矩阵。
pillow模块。PIL是理想的图像存档和批处理应用程序。您可以使用库创建缩略图,在文件格式、打印图像等之间进行转换。它提供了广泛的文件格式支持、高效的内部表示和相当强大的图像处理功能。核心图像库是为快速访问以几种基本像素格式存储的数据而设计的。为通用图像处理工具提供了坚实的基础。
keras模块。Keras是一个由Python编写的开源人工神经网络库,可以作为Tensorflow、Microsoft-CNTK和Theano的高阶应用程序接口,进行深度学习模型的设计、调试、评估、应用和可视化 。
1.2 目标检测算法介绍
深度学习目标检测算法大体上可以分为双阶段和单阶段两种,前者需要将整体分为两部分,然后生成识别框分别对两部分进行识别,后者是将整个流程放在一起直接进行检测。
双阶段目标检测算法需要先借助SelectiveSearch选出图像中的候选区域,之后还需要对候选区域进行再次检测,从而得出最后检测结果,比较常用的算法主要有OverFeat、R-CNN、MaskR-CNN等。
单阶段目标检测算法依据的是回归分析思想,所以也被称作回归分析目标检测算法。该算法之所以被称作单阶段目标检测算法是因为该算法不需要生成候选区域,而是直接对整个图像进行检测,从而获得目标位置类别和位置信息,比较常用的检测算法主要有YOLO和SSD。
其中YOLO目标检测算法是考虑到双阶段目标检测算法的检测效率比较低,所以一些学者提出了单阶段目标检测。JosephRedmon等人在2016年的时候提出了由卷积层和FC层构成的YOLO目标检测算法,先要在最顶层特征图中标出边界框,之后就可以对每个类别概率进行预测,最后再激活函数就可以得到最终信息。下图为YOLO的残差网络结构:

2、模型搭建
2.1 初始函数搭建
其中包括YOLO初始化基本参数,初始化类别、获取先验框、计算会话等。
def __init__(self, **kwargs):
self.__dict__.update(self._defaults)
self.class_names = self._get_class()
self.anchors = self._get_anchors()
self.sess = K.get_session()
self.boxes, self.scores, self.classes = self.generate()
def _get_class(self):
classes_path = os.path.expanduser(self.classes_path)
with open(classes_path) as f:
class_names = f.readlines()
class_names = [c.strip() for c in class_names]
return class_names
def _get_anchors(self):
anchors_path = os.path.expanduser(self.anchors_path)
with open(anchors_path) as f:
anchors = f.readline()
anchors = [float(x) for x in anchors.split(',')]
return np.array(anchors).reshape(-1, 2)
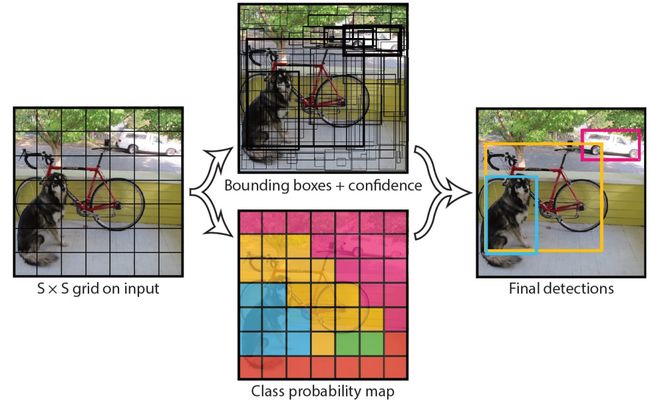
2.2 YOLO网络层搭建
YOLO算法将整幅图像分为了多个网格单元,对每个网格中心目标进行检测,该算法不用生成候选区域,在一个卷积网络中就可以完成特征提取、分类回归等任务,检测过程得到了简化,检测速度也变得更快,但该算法对于小尺度目标的检测不够准确,如果图像中存在重叠遮挡等现象就可能出现遗漏。整个网络模型搭建包括DarknetConv2D、 BatchNormalization和 LeakyReLU卷积块的设置以及卷积层特征提取。
def DarknetConv2D(*args, **kwargs):
darknet_conv_kwargs = {'kernel_regularizer': l2(5e-4)}
darknet_conv_kwargs['padding'] = 'valid' if kwargs.get('strides')==(2,2) else 'same'
darknet_conv_kwargs.update(kwargs)
return Conv2D(*args, **darknet_conv_kwargs)
def DarknetConv2D_BN_Leaky(*args, **kwargs):
no_bias_kwargs = {'use_bias': False}
no_bias_kwargs.update(kwargs)
return compose(
DarknetConv2D(*args, **no_bias_kwargs),
BatchNormalization(),
LeakyReLU(alpha=0.1))
03、模型调用
常见的目标检测算法常分为三个步骤进行:
第一步:分类,用事前确定好的类别或实例ID对化为信息的图像结构进行描述。
第二步:检测,上一步是对整张图片内容的描述,这一步则需要选定一个物体目标进行检测,获取物体所处位置以及类别信息。
第三步:分割,这一步需要对语义和实例进行分割,并得出像素属于哪个目标物体或哪个场景的结论。
流程为调整输入图像或视频流的尺寸以满足模型规范输入大小,通过模型预测出类别、框体大小和分数。
其中模型调用显示框图代码如下:
def detect_image(self, image):
boolen=False
start = timer()
new_image_size = self.model_image_size
boxed_image = letterbox_image(image, new_image_size)
image_data = np.array(boxed_image, dtype='float32')
image_data /= 255.
image_data = np.expand_dims(image_data, 0) # Add batch dimension.
out_boxes, out_scores, out_classes = self.sess.run(
[self.boxes, self.scores, self.classes],
feed_dict={
self.yolo_model.input: image_data,
self.input_image_shape: [image.size[1], image.size[0]],
K.learning_phase(): 0
})
print('Found {} boxes for {}'.format(len(out_boxes), 'img'))
font = ImageFont.truetype(font='font/simhei.ttf',
size=np.floor(3e-2 * image.size[1] + 0.5).astype('int32'))
thickness = (image.size[0] + image.size[1]) // 300
small_pic=[]
for i, c in list(enumerate(out_classes)):
predicted_class = self.class_names[c]
box = out_boxes[i]
score = out_scores[i]
top, left, bottom, right = box
top = top - 5
left = left - 5
bottom = bottom + 5
right = right + 5
top = max(0, np.floor(top + 0.5).astype('int32'))
left = max(0, np.floor(left + 0.5).astype('int32'))
bottom = min(image.size[1], np.floor(bottom + 0.5).astype('int32'))
right = min(image.size[0], np.floor(right + 0.5).astype('int32'))
# 画框框
label = '{} {:.2f}'.format(predicted_class, score)
draw = ImageDraw.Draw(image)
label_size = draw.textsize(label, font)
label = label.encode('utf-8')
if predicted_class=='smoke':
boolen=True
if top - label_size[1] >= 0:
text_origin = np.array([left, top - label_size[1]])
else:
text_origin = np.array([left, top + 1])
for i in range(thickness):
draw.rectangle(
[left + i, top + i, right - i, bottom - i],
outline=self.colors[c])
draw.rectangle(
[tuple(text_origin), tuple(text_origin + label_size)],
fill=self.colors[c])
draw.text(text_origin, str(label,'UTF-8'), fill=(0, 0, 0), font=font)
del draw
end = timer()
print(end - start)
return image,boolen


完整代码:
链接:
https://pan.baidu.com/s/1vmjV1HwhcMOdUqFhKwH4Mg
提取码:pqsv
作者简介:
李秋键,CSDN博客专家,CSDN达人课作者。硕士在读于中国矿业大学,开发有taptap竞赛获奖等。