B站百大分析,如何成为百大(文末提供数据和源代码)
B站百大分析
2022年1月21日晚19点,B站举行了百大UP主(bilibili power up, BPU)颁奖典礼,此次评选采用了新标准,从专业性、影响力、创新性三个维度进行评选。
关键字:B站百大,网络爬虫,数据分析
B站百大包括了游戏、知识、音乐、美食、生活各大领域的up主,百大是B站各领域的精英,也是现实生活中的佼佼者,让我们从数据角度看百大。
1 数据来源
b站的百大有专门的页面展示:
https://www.bilibili.com/BPU2021#/poweruplist
F12开发者模式对这个网页简单分析就可以轻松拿到百大名单,包括up主的id、名字、百大简介、百大头像等,B站使用 mid 作为up主的唯一标识,百大名单爬虫代码如下:
def getBPU100(self, year=2021):
# 获取100个up主信息
url = r"https://api.bilibili.com/x/activity/up/list?csrf=59de2f8df79cf6afcc3e045f0f44e3c1&ps=100&sid=239549&type=ctime"
ups = []
try:
list = requests.get(url, headers=self.headers).json()['data']['list']
except:
print(url+"网页请求失败")
return []
for row in list:
up = dict()
up['id'] = row['object']['act']['mid']
up['name'] = row['object']['act']['name']
#up.update(self.getDetail(up['id']))
up['message'] = row['object']['cont']['message']
up['image'] = row['object']['cont']['image']
up['reply'] = row['object']['cont']['reply']
time.sleep(10)
ups += [up]
self.write(ups,str(year))
return ups
接下来就是对每个up主的主页进行数据采集。通过点个某一个up主的主页打开F12开发者模式就可以分析出含有关键信息的页面。
这里涉及到up主信息的网页较多,本文采集三个页面,主要涉及个人信息页、播放和阅读数页面,较私密信息(生日、学历)页面。还有一些别的页面包括up主的信息,这里不做爬取。
(1) 个人信息页
这个页面是主要的信息来源,将upId更换为优秀up主的mid即可请求。
https://api.bilibili.com/x/web-interface/card?mid=upId&jsonp=jsonp&article=true
个人信息页包含了up主的名字、ID、性别、排名、关注数、粉丝数、个人签名、等级、官方title、vip类型、视频数量、文章数量、点赞数等信息。话不多说,直接上代码。
def getDetail(self, upId):
# up 个人信息页
url = r"https://api.bilibili.com/x/web-interface/card?mid=" + str(upId) + "&jsonp=jsonp&article=true"
res = {}
try:
data = requests.get(url, headers=self.headers).json()['data']
except:
print(url+"网页请求失败")
return res
res['name'] = data['card']['name']
res['id'] = data['card']['mid']
res['sex'] = data['card']['sex']
#res.update(self.getOther(upId))
res['rank'] = data['card']['rank']
res['friend'] = data['card']['friend']
res['attention'] = data['card']['attention']
res['fans'] = data['card']['fans']
res['sign'] = data['card']['sign']
res['level'] = data['card']['level_info']['current_level']
res['Official_title'] = data['card']['Official']['title']
res['vip'] = data['card']['vip']['label']['text']
res['archive_count'] = data['archive_count']
res['article_count'] = data['article_count']
#if self.headers['cookie']!="":
# res.update(self.getView(upId))
res['follower'] = data['follower']
res['like_num'] = data['like_num']
res['getDate'] = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
return res
(2)播放和阅读数页面
在个人信息页是找不到播放数和阅读数的,仔细寻找发现有一个单独的页面存储这个数据,页面如下,将upId更换为优秀up主的mid即可请求:
https://api.bilibili.com/x/space/upstat?mid=upId&jsonp=jsonp
开始在编译器里怎么也获得不到数据,后来发现这个页面需要在headers中设置cookie参数,爬虫代码如下:
def getView(self, upId):
# up 的播放数和阅读数
url = r"https://api.bilibili.com/x/space/upstat?mid=" + str(upId) + "&jsonp=jsonp"
try:
upstat = requests.get(url, headers=self.headers).json()['data']
archive_view = upstat['archive']['view']
article_view = upstat['article']['view']
except:
print(url+"网页请求失败")
return {}
return {'archive_view': archive_view, 'article_view': article_view}
(3) 较私密信息页面
大部分up主这部分信息都是缺失的,这也给后面的分析带来了一些困难。页面如下,将upId更换为优秀up主的mid即可请求:
https://api.bilibili.com/x/space/acc/info?mid=upId&jsonp=jsonp
这个页面包括up主的生日、学历、直播信息和tags,代码如下:
def getOther(self, upId):
# up 的生日和学历
# 还有直播信息和tags
url = r"https://api.bilibili.com/x/space/acc/info?mid=" + str(upId) + "&jsonp=jsonp"
try:
data = requests.get(url, headers=self.headers).json()['data']
birthday = data['birthday']
if data['school']:
school = data['school']['name']
else:
school = ""
if data['profession']:
profession = data['profession']['name']
else:
profession = ""
except:
print(url+"网页请求失败")
return {}
return {'birthday': birthday, 'school': school, 'profession': profession}
2 数据展示
点击这个下载全部信息!爬取结果
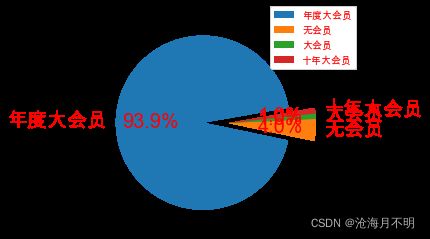
简简单单做个饼图,想当百大这边建议先开个年度大会员?或者十年大会员?!
特别提醒
各位同学不要频繁运行代码访问,可能会给自己带来麻烦~代码仅供参考,请勿商用。
有时间会再做一篇数据分析,2021百大只有99个哦。
代码链接
参考链接:
1.https://www.bilibili.com/read/cv2171515
2.https://www.zhihu.com/question/510926583/answer/2306528429
3.https://www.bilibili.com/read/cv9221533