Horizontal Pyramid Matching for Person Re-ID
行人再识别问题
行人再识别是一项很具有挑战性的任务,主要因素包括环境因素和行人本身的因素:
(1)环境因素:复杂的背景、光照、获取的图像分辨率等;
(2)行人因素:衣着、姿势、步态等。
之前很难提取到robust的特征,深度学习的发展使特征提取成为可能。
论文方法
[主要思想]
使用多个尺度,将提取到的特征图进行水平划分成bins;将每个bin分别进行平均池化和最大池化,并将两个池化结果整合起来:每个尺度的不同bin池化结果可以连在一起,用作分类。参考下图:

[模型框架]
(1)backbone: 使用resnet50从输入图像提取特征图;使用ImageNet的预训练权重;与resnet50不同在于:conv4_1的步长由2改成1,并且去掉平均池化层和全连接层。
(2)horizontal pyramid pooling: 首先根据scale水平划分特征图:分别进行最大池化和平均池化,两者结果对应相加;通过1*1的卷积核进行降维。
(3)fc + softmax: 使用全连接层和softmax进行分类。
详情见下图:

[具体实施]
1、通过水平翻转增加图像数目,并对图像进行归一化;
2、输入图像大小:384*128,提取到的特征图尺寸是输入的1/16;
3、训练参数:epoch=60; 基准学习率是0.1,训练40个epoch后下降到0.01,预训练的resnet层的学习率是0.1*基准学习率;batch_size=64; SGD设置momentum=0.9;
4、Pytorch; 两块 NVIDIA TITAN X GPU。
为什么该模型优于其他模型?
同样基于深度学习、考虑图像存在部分身体缺失,充分利用局部信息来提取特征的其他方法分为3类:
1、基于先验模型:先验模型指的是先通过姿态/特殊标记(例如衣服的logo)来预测出行人在一张图片的位置,然后在利用该区域进行特征提取然后判别。
该方法的缺点:预测结果如果不对,严重影响重识别结果;用于姿态预测和行人重识别的数据集并不匹配。
2、基于深度特征图的高度激活部分进行判别:忽略图像语义。
3、基于深度特征图分割:使用预先定义的尺寸将特征图划分成一条条或者一块块。
面临问题是:如果图像中的行人并没有对齐,很容易受到异常值的影响。
作者的创新体现:
1、使用pyramid structure:
并不是单一尺度的分割,而是多尺度的分割,像是金字塔一样;
好处在于:使用单一尺度进行分割,如果分的太细,就很难提取到合适的判别信息,反之,划分太粗就不能抵制图像未对齐的影响。
pyramid的最大尺度是图像的高度的log2,并且尺度既不能太多也不能太少,太多计算成本太大,太少则提取不到充分的局部判别信息。
2、使用maxpooling和avgpooling相结合:
maxpooling有利于提取具有极高判别性的信息,而avgpooling有利于提取全局信息。
单maxpooling要比avgpooling表现好;
将两者整合起来,既能提取全局信息,又能提取局部信息。
一些实验结果
关于pyramid structure的影响:
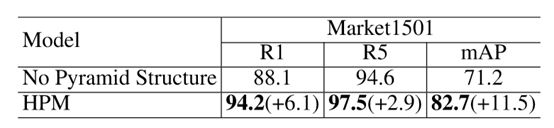
关于pyramid scale 和 pooling的影响:

相关工作
何凯明大神在2014年提出的Spatial Pyramid Pooling;
SPP和HPP的区别在于:SPP使用不同大小的2-D块来划分特征图,而HPP使用水平条分割。