按键精灵免字库本地识别OCR
按键精灵免字库识别—基于百度飞桨PaddleOCR的RapidOCR
-
- 前言
- 为什么
-
- 为什么有大漠了还要使用其它OCR
- 为什么要使用RapidOCR
- 开发
-
- PaddleOCR介绍
- PaddleOCR使用
-
- 衍生项目版——小白方案
- 按键精灵post调用
-
- 图片转base64方法
- 转json方法
- post调用
- JVM版
-
- 改为maven
- OcrEngine路径
- idea Run配置
- 网页版【推荐】
-
- 第一次优化-简化结果
- 第二次优化-免base64传输
- 最后
前言
目前网上仅有类大漠的字库识别和远程调用互联网识别。百度飞桨很早就开源了PaddleOCR,做一个小脚本还使用收费远程项目早应该过时。由于对py不熟悉,推理麻烦,直接使用了捷智开源的基于PaddleOCR的RapidOCR,简单快捷。
为什么
为什么有大漠了还要使用其它OCR
大漠OCR确实是经典永流传,它的优点就是非常的快,个位数毫秒级别,完美适用是实时高频率调用的脚本。当然快速也就意味着简单,它的识字是要做字库的,只适用于已知文库,我认为其实就是相当于特殊识图,伪OCR。人工智能快速发展,才有了真正的OCR,也就是免字库OCR。百度也是承担起国内人工智能发展的社会责任,开源了PaddleOCR,遵守Apache协议,可以商用。
为什么要使用RapidOCR
大漠 =》需要字库,个位数毫秒级
远程OCR =》免费受限制、网络传输耗时,百位数毫秒级
PaddleOCR =》 推导,需要一定的python开发经验,未知
RapidOCR =》成品,本地搭建调用即可,当然定制化优化性能更好,十位数毫秒级。
开发
有了这么优秀的产品,就可以尝试整合了。
PaddleOCR介绍
https://github.com/PaddlePaddle/PaddleOCR/

PaddleOCR使用
PaddleOCR如上,有各种语言的应用推导。记录一下我使用过的几种。
衍生项目版——小白方案
衍生项目使用易语言编写的,无需依赖环境,双击即可启动,小白也能用。
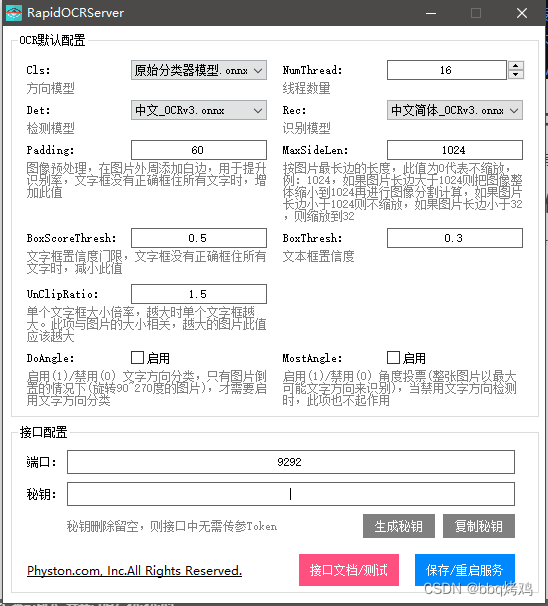
点开接口测试,都已经写好调用案例了。
按键精灵post调用
关于按键精灵http请求调用接口的代码,B站酷玩蚊仔已经封装好,我直接借鉴了,需要做些调整。
酷玩蚊仔
https://www.bilibili.com/video/av556250543/?vd_source=8a1fa4f94facedbbcdd82d30f1ef1a10
给出我做的调整的代码
图片转base64方法
注释掉替换加号,这应该是百度在线api需要的格式。
Function ImagesToBase64(FilePath)
Dim xml
Dim root
Dim fs
Dim objStream
Dim objXMLDoc
Dim Base64
Set objXMLDoc = CreateObject("Microsoft.XMLDOM") // 可以访问和操作XML文档
objXMLDoc.loadXML "" // 导入指定字符串的XML文档
Set fs = createObject("Scripting.FileSystemObject") // 可以操作磁盘、文件夹或文本文件
If fs.FileExists(FilePath) Then // 判断文件是否存在
'用 stream 来读取数据
Set objStream = CreateObject("ADODB.Stream") // 可以存取二进制数据或者文本流
objStream.Type = 1 // 表示二进制数据
objStream.Open // 打开objStream
objStream.LoadFromFile FilePath // 加载文件数据(下载图片用SaveToFile)
objXMLDoc.documentElement.dataType = "bin.base64" // 设置节点数据类型
objXMLDoc.documentElement.nodeTypedvalue = objStream.Read // 从objStream读取,再存储到根节点(objXMLDoc.documentElement代表XML文档的根节点)
'数据流读取结束.得到了值 objXMLDoc
'创建XML文件
Set xml = CreateObject("Microsoft.XMLDOM")
xml.load objXMLDoc // 导入指定位置的XML文档
If xml.ReadyState > 2 Then // 0:未初始化;1:载入;2:载入完成;3:交互;4:完成
Set root = xml.getElementsByTagName("data")// 返回指定名字的节点集合(可能会有多个重名节点)
Base64 = root(0).Text
Base64 = Replace(Base64, vbLf, "") // 去除换行(vbLf相当于chr(10))(可以不去除)
// Base64 = Replace(Base64,"+","%2B") // 替换加号(文档未说明,但需要此操作,而且不要进行urlencode)
Else
Base64 = ""
End If
Set xml = Nothing
Set objStream = Nothing
Else // 文件不存在
Base64 = ""
End If
Set fs = Nothing
Set objXMLDoc = Nothing
ImagesToBase64 = "data:image/png;base64,"&Base64
// //TracePrint ImagesToBase64
End Function
转json方法
Function jsonFormatter(str)
result = "{"
attrList = split(str, "&")
For i = 0 To UBound(attrList)
If i > 0 Then
result = result & ","
End If
attr = attrList(i)
key = split(attr, "=")(0)
value = split(attr, "=")(1)
result = result & chr(34) & key & chr(34) & ":" & chr(34) & value & chr(34)
Next
result = result & "}"
TracePrint result
jsonFormatter = result
End Function
post调用
imgBase64 = ImagesToBase64("E:\python\ocr\2.png")
Set xPost = CreateObject("Msxml2.ServerXMLHTTP.3.0")
xPost.Open "Post", "http://127.0.0.1:9003/ocr", False
xPost.setRequestHeader "CONTENT-TYPE", "application/json"
xPost.Send (jsonFormatter("file=" & imgBase64))
If xPost.readyState = 4 Then
TracePrint xPost.responsetext
// Set obj = json.Decode(xPost.responsetext)
// TracePrint obj("Msg")
// access_token = obj("access_token")
End If
JVM版
作为Java开发,反而在搞Java Demo时耗时最长。
改为maven
给出的案例是grade版,改为java开发熟悉的maven版,移植代码
maven应该只需要加这个以支持kotlin
<dependency>
<groupId>org.jetbrains.kotlingroupId>
<artifactId>kotlin-stdlibartifactId>
dependency>
OcrEngine路径
OcrEngine 全类名不能改动,否则会报错遇坑
Java调用jni的一个坑-java.lang.UnsatisfiedLinkError ()Ljava/lang/String
======= https://blog.csdn.net/qq_24054301/article/details/128653326
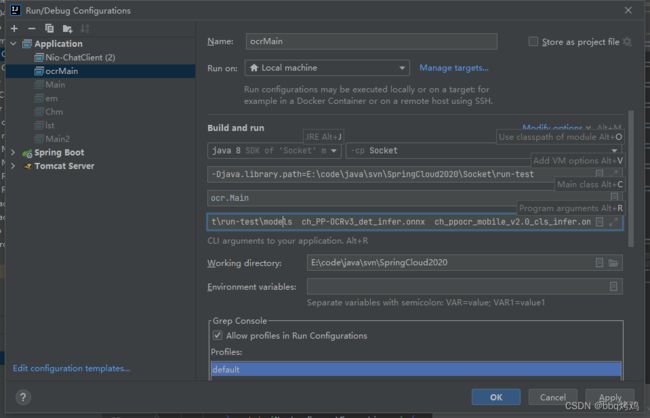
idea Run配置
需要配置参数,github有详细讲解
网页版【推荐】
Web版启动也非常简单,不过代码是用python写的,按文档走就行了,pip需要使用源外,没有其它坑,也是非常简单,而且速度比易语言版更快,更是可以修改代码,定制格式化。
注意:不要使用api版,好像有问题,直接用网页版,然后f12查看请求,更快。
第一次优化-简化结果
http请求返回值json简化
修改返回值,简化结果,免去两端格式化
return str(rec_res_data).split(',')[1]
第二次优化-免base64传输
原方案都是基于cs或bs架构,但是本地调用文件都在本地,没必要转码和文件传输。
所以直接在python里读取图片文件不要传输更快。
image = cv2.imread("E:\python\ocr\screen.bmp")
最后
抓图还是得使用大漠,效率比python的抓图性能好。如果能找到高效抓图的py库那自然是最好的,可以免去文件存储和读取的io耗时。