深度学习方法中 3D目标检测 数据预处理综述
这一篇的内容主要要讲一点在深度学习的3D目标检测网络中,我们都采用了哪些数据预处理的方法,主要讲两个方面的知识,第一个是representation,第二个数据预处理内容是数据增广。
作为本篇博文的引言,我们先给一种博主制作的比较重要的3D检测方法图鉴,如下,就笔者的个人理解,今年的CVPR出现了很多的one-stage的方法,同时出现了很多融合的方法,这里的融合有信息融合,有representation融合,同时根据近两年的发展来看,voxel-based的方法占据了主导地位,这是得益于卷积结构优越性(point-based方法采用pointnet++结构,是MLP搭建的),但是今年的oral文章3D-SSD是一篇在point-based方法上很有建树的文章,所以在3D检测中了解主要的representation代表方法也是很重要的。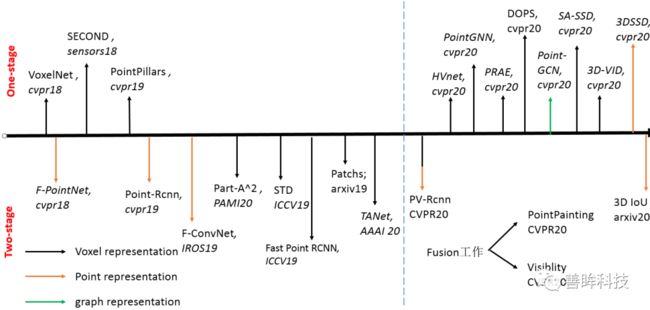
1 representation
做3D视觉的,尤其是基于点云做3D视觉任务的同学们都比较清楚的知道,点云因为其具有稀疏性和无规则性使得在二维上非常成熟的CNN结构不能直接的运用在点云中。我们先了解一下点云的这两个特性,如下图所示,下图中的(i)表示二维图像的排列方式,(ii),(ii),(iv)表示的是点云的数据,可以看出点云的排列稀疏性,对比(ii)和(iii)可以得知虽然点云数据的排列顺序假使是一样的,但是其对应的几何结构不同,而(iii)和(iv)则可以看出尽管几何结构表示同一个,但是排列顺序却是可以不一样的。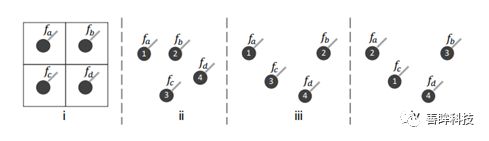
知道了上述的两个点云数据的两种特性,所以设计一种合适的点云表达形式是比寻找到一个高效的深度学习框架更加重要的内容,就3D检测方面而言,到CVPR20,至少有三种比较重要和值得探究的representation方式,分表示point representation,voxel representation和graph representation。
1.1 point representation
如题,就是采用最原始的点作为深度学习网络的输入,不采用任何的预处理工作,这类工作都是在pointnet++的基础上进行的。
这里首选插入一点采用point-based方法的基础backbone,如下所示,左图表示的是pointnet的特征提取结构,也就是point-based的基础模块,右图就是point-based方法的基础架构,由point-encoder层和point-decoder层组成,encoder层主要逐渐下采样采点特取语义信息,decoder过程是将encoder过程得到的特征信息传递给没有被采样到的点。使得全局的点都具有encoder的特征信息。最后再通过每个点作为anchor提出候选框。
最早的工作是CVPR18上的F-pointnet,该文章的作者也是pointnet/pointnet++的作者,具体做法如下可知,首先通过二维的检测框架得到二维目标检测结果,然后将二维检测结果通过视锥投影到三维,再采用三维破pointnet++延伸结构检测为三维目标框。算是三阶段的基于point输入的目标检测方法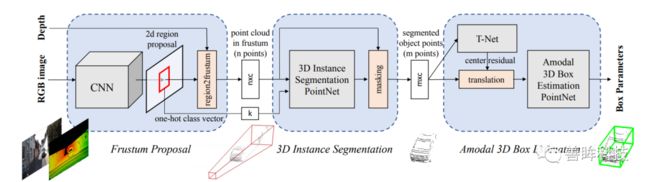
随后的CVPR19的比较经典的Point_based方法是point-rcnn,该工作不仅仅采用point作为representation,同时和上诉的F-pointnet比较没有采用二维信息,仅仅采用点云作为网络输入。如下图所示,该工作是一个两阶段的检测方法,第一阶段根据语义分割信息对每一个点都提出一个候选框,随后再采用多特征融合进一步优化proposals。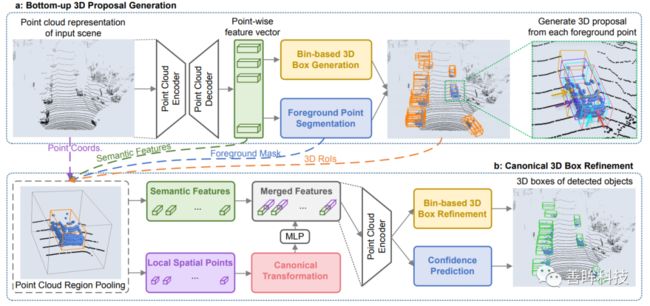 除了CVPR会议,在IROS和ICRA机器人相关的会议上也有很多这方面的研究,其中有一篇在F-pointnet上做出更细致的优化的文章F-ConvNet也是很优秀的工作,有兴趣的同学可以去了解下;这里直接介绍今年CVPR20上的基于Point representation的文章 3D-SSD,如下图所示,平平无奇的一阶段encoder过程,也就是把pointnet++的decoder部分给去除掉(这样做的目的是减少网络前馈时间,在KITTI上达到35FPS),本文的最主要的贡献点在于将Pointnet++的采样方法由欧式空间度量改为特征空间度量和欧式空间度量相结合的方法,同样的也采用了anchor-free的设计方法,使得显存占用更少。
除了CVPR会议,在IROS和ICRA机器人相关的会议上也有很多这方面的研究,其中有一篇在F-pointnet上做出更细致的优化的文章F-ConvNet也是很优秀的工作,有兴趣的同学可以去了解下;这里直接介绍今年CVPR20上的基于Point representation的文章 3D-SSD,如下图所示,平平无奇的一阶段encoder过程,也就是把pointnet++的decoder部分给去除掉(这样做的目的是减少网络前馈时间,在KITTI上达到35FPS),本文的最主要的贡献点在于将Pointnet++的采样方法由欧式空间度量改为特征空间度量和欧式空间度量相结合的方法,同样的也采用了anchor-free的设计方法,使得显存占用更少。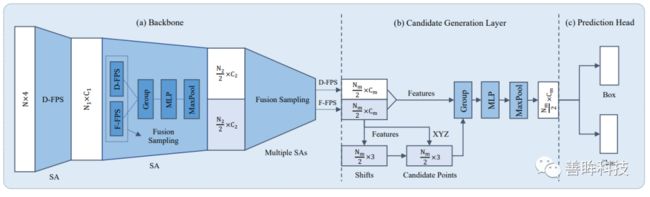
point representation方法小总结
就笔者个人对这方面的理解,该类方法的优点是作为最原始的点云数据,保留了最细致的几何结构信息,网络的输入信息损失几乎是所有representation方法中最小的。但是缺点也很明显,第一点,MLP的感知能力不如CNN,因此主流的effective的方法都是voxel-based的,第二点,pointnet++结构的采样是很耗时的,所以在实时性上也不及voxel-based的方法。所以今年的CVPR oral文章3D-SSD为了实时性,丢掉了FP层,同时设计了新的SA模块。
1. 2 voxel representation
1.2.1 Voxelization 步骤
在3D目标检测中,对整个场景的point2voxel的过程可以简单描述为如下:
设置Voxelization参数(每个voxel可以存放点的个数(max_points_number),voxel长宽高的大小(whl))
对依次每一个点,根据其对应的坐标(x,y,z)得到该点在voxel的索引。
根据索引判断该voxel种是否已经存在max_points_number个点,如果存在,则将该点直接丢弃,如果不满足,则将该点加入到该voxel中。
计算voxel特征
采用voxelnet的图表示为如下: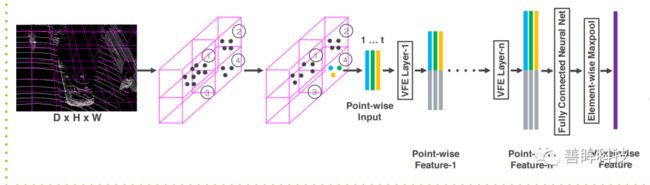
1.2.2 Voxelization 参数
上文中的体素化过程涉及到两个重要的内容,一个是体素参数,另外一个是voxel特征根据该voxel中的特征如何求取。
Voxelization 对参数的要求比较高,就发展历史来说,VoxelNet(CVPR18)是第一篇采用voxel-representation作为点云输入的网络结构,该文章中max_points_number设置的为35,voxel大小设置为0.5;采用的voxel特征提取方式为增加一个pointnet对每个voxel中的35个点特征提取得到相应的voxel特征(如下图中的feature learning network所示的内容),但是该参数很明显是会丢失比较多的几何结构信息,但是以这样的参数划分在当时还受到VoxelNet网络后续的3D卷积的显存占用的影响(3D卷积很占显存,因此网络预处理的参数受到影响)。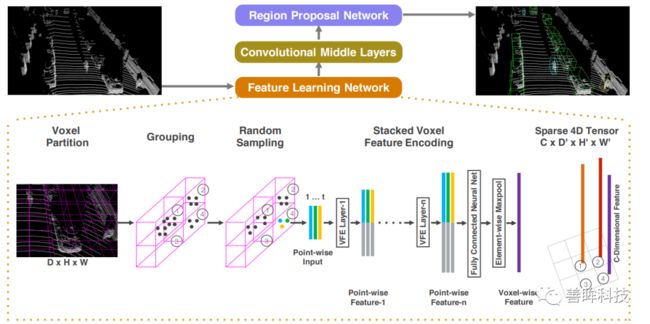
18年的SECOND提出的3D稀疏卷积大大减少了3D卷积的内存占用,(我们知道,3D卷积本身会对空间中每一个voxel都进行卷积,但是3D稀疏卷积只保留了空间中非空的voxel,采用map映射的方式得到卷积后的voxel空间索引);因此参数的设置自由了很多,就目前在KITTI和Nuscence上的sota的内容而言,我们一般采用的参数和特征提取方为:
max−points−number=5,(w,l)=(0.05,0.05),h=0.1
采用的voxel特征直接为mean特征,即对每一个voxel中的所有点的坐标求均值即可。
1.2.3 related paper
这里只介绍一些在voxel representation上做文章的研究内容,而不是采用voxel作为网络输入的研究工作,因此voxel-based的研究方法比较多,后续笔者会出一篇在这方面的研究综述,所以这里推荐的几篇文章都是在voxel-representation上的做出研究的工作。
voxel-based的先驱的两篇文章voxelnet和second的主要贡献分别是第一个提出采用voxel作为网络输入的方法和引入稀疏卷积替代3D卷积。这里补充一点voxel-based方法的backbone,目前几乎所有的voxel-based方法都采用如下的encoder的backone作为特征提取器。下图左图表示的是点的voxel表示,经过Voxelization 化后,经过逐步下采样的encoder过程降为二维 feature map,最后再根据二维的feature的每一个像素点作为anchor point提出候选框。
在voxel-representation上做文章的研究工作,如下图,这是一篇发表在sensors2020上的文章Voxel-FPN:multi-scale voxel feature aggregation in 3D object detection from point clouds,该研究工作的主要内容是通过不同scale的体素划分,最后将其整合成到RPN网络结构中的FPN网络中,需要注意的是,这里的scale的大小要和最初划分的scale对应起来。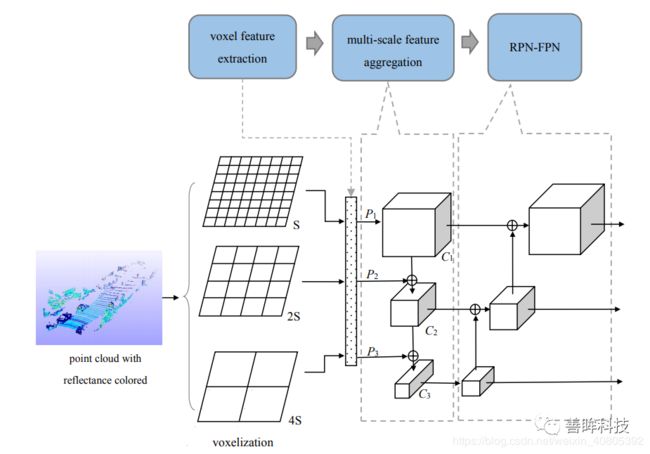
同样采用该思想的还有今年的CVPR20的文章HVNet,如下图所示,也是对场景中点云采用multi-scale的体素划分,最后也会形成一个FPN的结构,但是不同的细节和实现之处还是有很多的,HVNet采用了多线程同时并行处理每一个scale的体素划分,同时对于voxel的特征提取和Voxel-FPN也是不一样的。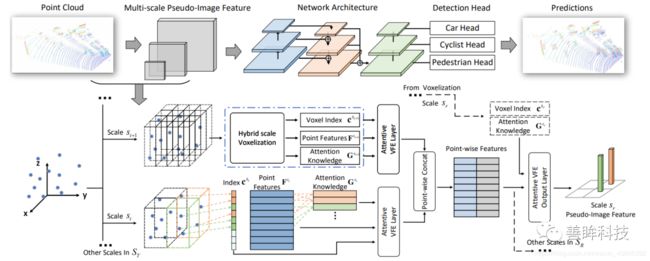
在voxel划分上做研究的工作还有
1.2.4 voxel representation方法小结
voxel-representation的方法的优点即是性能好又高效,不仅仅在精度上有着point-based的方法目前无法比拟的精度,在速度上也是很可观的,尤其是在稀疏卷积和3D流型卷积引入到3D目标检测后,发展更为迅速。但是缺点则是该类方法对参数比较敏感,预处理划分voxel的时候需要设置合适的参数,当然从信息论的方面理解,体素划分必然带来信息的丢失,尤其是局部细节信息的丢失,因此今年CVPR20上至少有三篇文章(SA-SSD,pointpainting,HVnet)在细节几何结构上做了一定的研究工作。
1.3 graph represention
这是一个比较新的representation,在3D检测中,今年CVPR20第一次出现了以graph作为representation的网络结构,如下图所示,graph representation的核心问题也在于构建一个graph网络,即下图中的图左所示的内容。这也是很多在语义分割中遇到的问题,在目前的建图中大多是采用的knn的方法构建图结构,后续再送入到图卷积进行特种提取,最后根据point rpn-head提出proposals。
就该类方法而言,目前的研究还不是很多,因为GCN非常耗时,可以理解为时pointnet++特征提取网络的升级版,不仅仅提取点之间的信息,同时根据‘点-边’信息提取到更加局部细节的信息,但是优点也可以理解到,3D shape实际上在增加边信息后,会更加容易感知(对比mesh结构可知),但是采用何种方式构建合适的graph都还是很需要研究的内容。
1.4 point-voxel fusion
既然我们知道point-based的方法具有保持了几何structure的能力,同时voxel-based的方法具有高效的感知能力,那么最新的研究就在考虑如何做这方面的fusion工作,PV-RCNN(CVPR20)采用的将voxel特征经过multi-scale的形式赋予到point上,最后再refine阶段将点的局部信息融合到pointnet中。SA-SSD采用voxel2point添加附加任务使得voxel backbone具有structure aware能力。实际上根据representation fusion的经验,应该还是大有可做的。
2 Augmentation
实际上3D目标检测的数据增广方式和二维目标检测的方式大多相同,我们总结为如下一些比较常见的数据增广方式,根据动态图很容易的看到的出来数据增广的方式,这里笔者着重介绍一下ground truth augmentor的方法,这应该是根据3D点云的稀疏空间特性所特有的数据增广方式。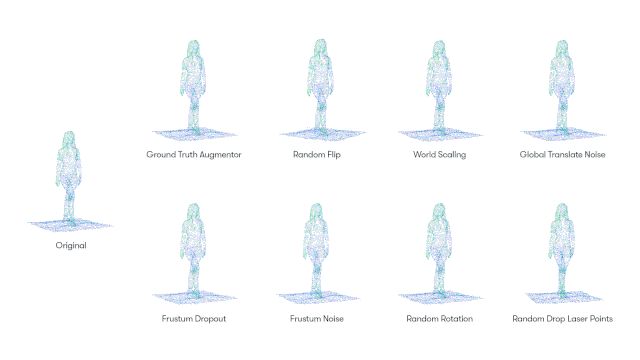
ground truth augmentor
就KITTI object 3D的数据而言,每一帧的object数量从无到二十多个不等,ground truth augmentor的想法则是先从所有训练集中根据类别把ground truth建立成一个data base,然后在训练的时候将data base中的gt按照类别丢一定数量的gt到当前训练的帧中,这里笔者给出一般在KITTI上数据增广的数量如下。即表示一般会选择在场景中丢进去15个car,丢进10个Pedestrians和Cyclists。
SAMPLE_GROUPS: ['Car:15','Pedestrian:10', 'Cyclist:10']因为该数据增广的工作在3D目标检测中比较重要,后续还延伸到一些涉及到该方面的研究工作,笔者做一点简单介绍.
这一篇文章(Class-balanced Grouping and Sampling for Point Cloud 3D Object Detection)的后续研究工作做成了一个detection zoo,在github上叫det3D,但是该文章的初始问题是想解决在nuscene数据中的数据不平衡问题,根据作者的采样得到如下图表,这里也就是目标检测的long tail问题,数据不平衡问题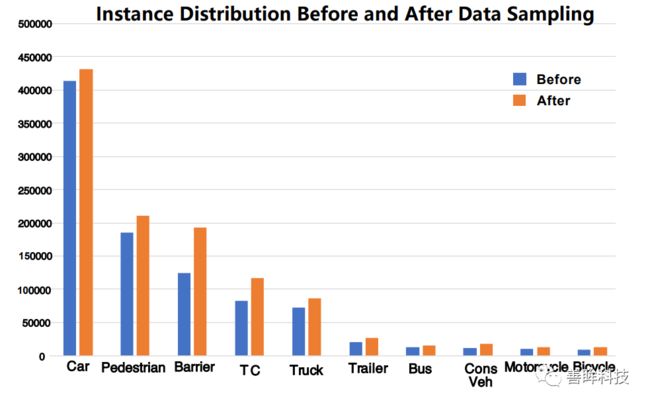
这里作者采用的gt数据增广方式采样如下个数的gt来平衡数据集本身存在的long tail问题,并最终在nuscence上取得了榜一的成绩。
在这里插入图片描述
笔者再介绍一篇今年CVPR20上涉及到gt augmentation的工作(oral)(What You See is What You Get: Exploiting Visibility for 3D Object Detection),,如下图,在本文gt数据增广后,俯视图下由(a)变成了(b),但是作者指出这里出现的问题在于有的增广的物体出现在墙后,这在Lidar扫描过程中是不符合规律的,因此作者采取的增广策略是把对应的墙体去掉,如(d)图所示的内容。这就比较符合lidar扫描的特性,即遇到object就会反弹。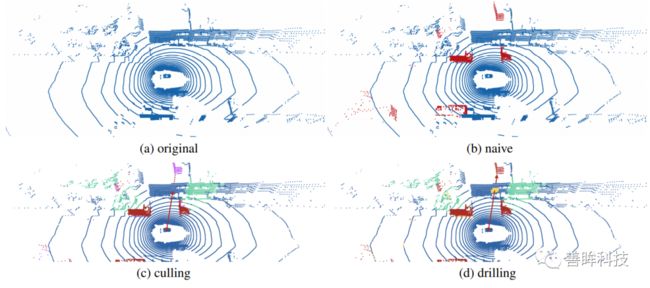
3 笔者的思考
实际上数据预处理在深度学习中也是比较重要的内容,就representation来说,voxel的方法高效但存在信息丢失,point-basde的方法感知能力不及cnn但输入为最原始的结构,Graph构建了更容易感知的结构,但也要承担GCN网络过长的前馈时间;就augmentation来说,gt augmentation尽管在涨点上成了众人皆知的trick,但是要能很好的用起来该方法还是有一些值得研究的trick在里面,就比如上述提到的两篇文章。最后写一个flag,后续尽快写一个voxel-based方法研究的发展概述,主要也是笔者的理解。
推荐文献
[1] VoxelNet: End-to-End Learning for Point Cloud Based 3D Object Detection
[2]Frustum PointNets for 3D Object Detection from RGB-D Data
[3]PointRCNN: 3D Object Proposal Generation and Detection from Point Cloud’
[4]3DSSD: Point-based 3D Single Stage Object Detector
[5]Point-GNN: Graph Neural Network for 3D Object Detection in a Point Cloud
作者为CSDN博主「Little_sky_jty」
原文链接:https://blog.csdn.net/weixin_40805392/article/details/106169269?utm_medium=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase