《图机器学习》-Graph as Matrix:Page Rnak,
Graph as Matrix
- 一、Graph as Matrix
- 二、PageRank
- 三、PageRank:How to solve?
- 四、Random Walk with Restarts and Personalized PageRank
- 五、Matrix Factorization and Node Embedding
一、Graph as Matrix
本小节将从矩阵的角度研究图形分析和学习。
把一个图当作一个矩阵来处理,我们可以:
- 通过random walk确定节点的重要性(PageRank)
- 通过矩阵分解(matrix factorization ,MF)获得节点嵌入
- 将node embeddings (例如Node2Vec)视为MF
- random walk、MF和node embeddings是密切相关的!
二、PageRank
我们可以将网页看一个图:
- 节点:网页
- 边:超链接
我们将图看作是一个有有向图,超链接的指向构成边的方向:
其他类似的:
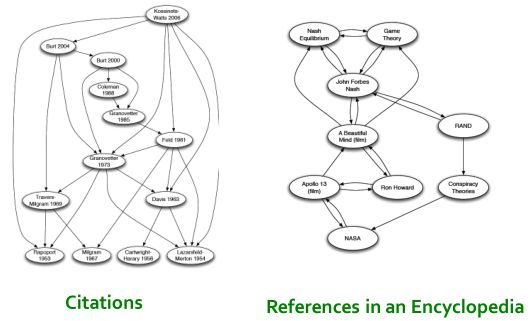
论文之间的应用、百科全书之间的引用关系也可以类似的组织成一张有向图:
在Web graph中,并非所有网页(节点)都是同样“重要”,所有想要对Web graph中的网页按照重要性进行排序;有以下三种方法可以实现:
- PageRank
- Personalized PageRank (PPR)
- Random Walk with Restarts
P a g e R a n k PageRank PageRank:
两个重要的思想:
-
如果页面有更多的链接,它就更重要
- 选择出链还是入链作为衡量呢?
因为出链可以自己去构建,所以很容易去造假;而入链不容易造假,所以选择入链会比较靠谱;
可以把入链想象成投票(vote),别人给你投的票越多你就会越重要。
- 选择出链还是入链作为衡量呢?
-
来自重要页面的链接更重要
- 大人物给你投的票会更重要些
- 因此:
- 每个链接的投票与其源页面的重要性成正比
- 如果重要性 r i r_i ri的页面 i i i有 d i d_i di个出链接,每个链接得到 r i / d i r_i / d_i ri/di票
- 页面 j j j本身的重要性 r j r_j rj是对其链接的投票总和
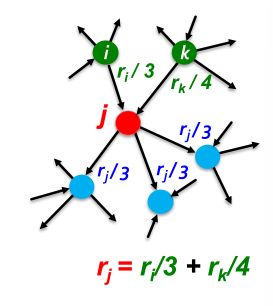
可以观察到,上面的问题是一个递归的问题。
对节点 j j j定义 r a n k rank rank:
r j = ∑ i → j r i d i (1) r_j=\sum_{i→j}\frac{r_i}{d_i}\tag1 rj=i→j∑diri(1)
- d i d_i di:节点 i i i的出链数
- 节点 i i i至少有一条出链指向节点 j j j
例子:
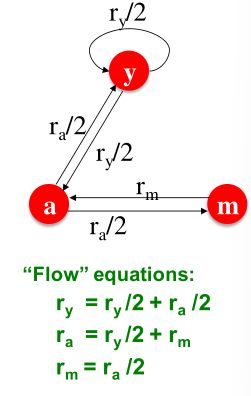
你可能会想:让我们用高斯消去法来解这个线性方程组。坏主意!因为这样的做法并具备可扩展性。
下面介绍该线性方程组的另一种解法。
首先我们引入随机邻接矩阵(Stochastic adjacency matrix) M M M:
- d i d_i di表示节点 i i i的出度
- 如果 i i i到 j j j有一条边,那么 M j i = 1 d i M_{ji}=\frac{1}{d_i} Mji=di1;否则为0。
- M M M中每列的和都是1
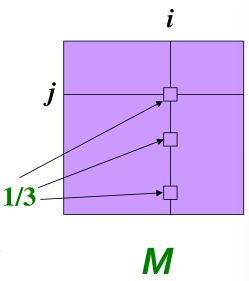
这个 M M M其实就是一个概率转移矩阵, M j i M_{ji} Mji表示从 i i i节点出发有 M j i M_{ji} Mji的几率去到 j j j节点。
引入Rank vector r r r:
- 一个列向量,第i个元素表示第i个网页的rank值,即第i个网页的重要性。
- ∑ i r i = 1 \sum_ir_i=1 ∑iri=1
对rank的定义公式 ( 1 ) (1) (1),其向量化可写成:
r j = ∑ i → j r i d i ⇒ r = M ⋅ r r_j=\sum_{i→j}\frac{r_i}{d_i} \Rightarrow r=M\cdot r rj=i→j∑diri⇒r=M⋅r
例子:

让我们将Page Rank与Random Walk联系起来:
想象一个随机的网上冲浪者:
- 在某个时间 t t t,冲浪者在网页 i i i上
- 在时间 t + 1 t+1 t+1,冲浪者会均匀随机地点击 i i i的出链接,去到下一个网页。即从网页 i i i中的某个链接去到某个页面 j j j
- 过程无限重复,即这个冲浪者一直在浏览网页。
引入 p ( t ) p(t) p(t):
- 一个列向量,表示在 t t t时间,第 i i i个元素表示冲浪者处于第 i i i个网页的概率。
- 所以, p ( t ) p(t) p(t)是网页的概率分布
如何计算 t + 1 t+1 t+1时刻的网页概率分布呢?
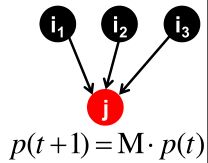
以上图为例子,下一时刻处于网页j的概率=处于网页 i 1 i_1 i1的概率 × \times ×从网页 i 1 i_1 i1跳到网页j的概率+处于网页 i 2 i_2 i2的概率 × \times ×从网页 i 2 i_2 i2跳到网页j的概率+处于网页 i 3 i_3 i3的概率 × \times ×从网页 i 3 i_3 i3跳到网页j的概率。
可以得到下一时刻网页概率分布的向量化公式:
p ( t + 1 ) = M ⋅ p ( t ) p(t+1)=M\cdot p(t) p(t+1)=M⋅p(t)
若经过一段时间后,有:
p ( t + 1 ) = M ⋅ p ( t ) = p ( t ) p(t+1)=M\cdot p(t)=p(t) p(t+1)=M⋅p(t)=p(t)
则 p ( t ) p(t) p(t)是random walk的平稳分布(stationary distribution)。
该公式与之间的 r = M ⋅ r r=M\cdot r r=M⋅r类似,所以可以称 r r r是random walk的平稳分布(stationary distribution)。
让我们将Page Rank与特征向量联系起来:
让我们回忆之前学过的Engienvector centrality

而式 ( 1 ) (1) (1)可以写成:
1 ⋅ r = M ⋅ r 1\cdot r=M\cdot r 1⋅r=M⋅r
- 所以rank向量 r r r是随机邻接矩阵 M M M特征值为 1 1 1的特征向量
- 从任意节点 u u u开始, M ( M ( ⋯ M ( M u ) ) ) M(M(\cdots M(M\ u))) M(M(⋯M(M u)))是网页的长期概率分布,即无论从哪个点开始开始冲浪, r r r都会收敛到同一个相同的结果。
- PageRank =极限分布= M的特征向量
因此我们能找到求解 r r r的方法: P o w e r i t e r a t i o n Power\ iteration Power iteration
之前写的关于Page Rank的一个博客
三、PageRank:How to solve?
P o w e r i t e r a t i o n Power\ iteration Power iteration流程:
- 初始化: r ( 0 ) = [ 1 / N , ⋯ , 1 / N ] T r^{(0)}=[1/N,\cdots,1/N]^T r(0)=[1/N,⋯,1/N]T
一开始,各网页的重要性都是一样的。 - 迭代: r ( t + 1 ) = M ⋅ r ( t ) r^{(t+1)}=M\cdot r^{(t)} r(t+1)=M⋅r(t)
- 当 ∣ r ( t + 1 ) − r ( t ) ∣ 1 < ε |r^{(t+1)}-r^{(t)}|_1<\varepsilon ∣r(t+1)−r(t)∣1<ε时停止迭代
这里 ∣ x ∣ 1 = ∑ 1 N ∣ x i ∣ |x|_1=\sum^N_1|x_i| ∣x∣1=∑1N∣xi∣表示第一范式,也可以使用其他的范式
大概迭代50次就可以得到一个收敛的 r r r。
PageRnak存在的三个问题:
- 能否收敛?
- 它会收敛到我们想要的吗?
- 结果合理吗?
下面介绍 d e a d e n d s dead\ ends dead ends和 S p i d e r t r a p s Spider\ traps Spider traps来探讨上面的三个问句。
d e a d e n d s dead\ ends dead ends:
即页面中存在没有出链的节点,这样的页面会导致重要性“leak out”(泄漏)。
S p i d e r t r a p s Spider\ traps Spider traps:
即所有出链都在一个组内,最后这个组会“吸收”所有的重要性。
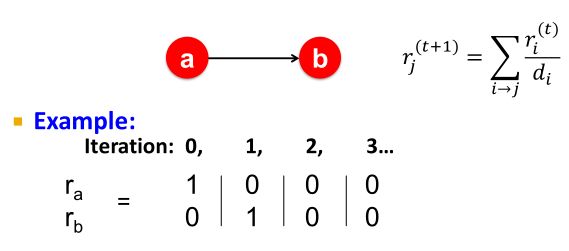
例子1:能否收敛?
The “Spider trap” problem:
入下图,b节点的出链指向了自己;根据迭代公式,a节点会向b节点投票,而b节点也会向自己投票,而a没有节点向它投票。在多次迭代后,票都会向b节点汇聚,最后 r = [ 0 , 1 ] T r=[0,1]^T r=[0,1]T,从而a节点重要性为0,b节点重要性为1.
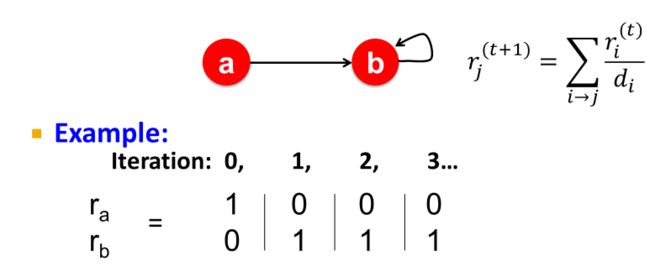 会发现无论迭代多少次,重要性都会在这个圈子里打转,导致random surfer会在圈子里打转,出不去。
会发现无论迭代多少次,重要性都会在这个圈子里打转,导致random surfer会在圈子里打转,出不去。
例子2:它会收敛到我们想要的吗?
The “Dead end” problem:
b节点不存在出链。相当于a把票投给了b,而b不把票投给任何人,票就像投入了一个黑洞,最后导致所有节点的重要性都归为了0。
然而这个收敛的结果并不是我们想要的。
解决Spider trap方案:
思想:
random surfer会在圈打转,那么打破这个圈就行了
所以在每个时间步,random surfer有两个选项:
- 以概率 β \beta β,沿着出链浏览网站
- 以概率 1 − β 1-\beta 1−β,跳到一个随机的网站
一般 β \beta β会被设置为0.8-0.9的一个数。
所以,冲浪者将在几个时间步骤内传送出Spider trap。
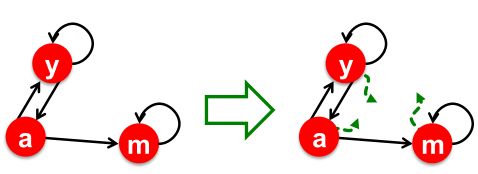
解决Dead end的方案:Teleports
思想:
Dead end即死胡同,那我们把死胡同做活就行了。
所以Dead end节点以总概率1.0随机传送到其他节点。
例子:
如下图,m节点是一个死胡同,那么将其做活:
m会等1/N的概率跳转到其他的节点,即走出了死胡同。

为什么Dead end和Spider trap是一个问题,为什么Teleports可以解决这个问题?
-
Spider trap不是问题,但对于PageRank分数不是我们想要的
- 解决方案:
千万不要被困在Spider trap里,在有限的步骤内瞬间移动出来
- 解决方案:
-
Dead-ends是个问题,因为矩阵不是列随机的(列和不为1),所以我们最初的假设不满足。
- 解决方案:
当无处可去时,总是传送,使矩阵列随机
- 解决方案:
综上,PageRank等式更新为:
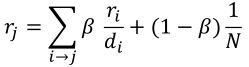
公式解释:
r j r_j rj表示浏览网页 j j j的概率。
其概率等于:
- 从 r i r_i ri以概率 1 / d i 1/d_i 1/di跳转过来,但有 β \beta β的概率会按出链走
- 还有可能是某个节点以 1 − β 1-\beta 1−β的概率随机跳转到其他节点,并以 1 / N 1/N 1/N的概率跳转到网页 j j j
向量化表示:
G = β M + ( 1 − β [ 1 N ] N × N ) G=β\ M+(1-β\left[\frac{1}{N}\right]_{N\times N}) G=β M+(1−β[N1]N×N)
变成递归的问题: r = G ⋅ r r=G\cdot r r=G⋅r,然后使用Power iteration的方法去求解 r r r。
PageRank案例:
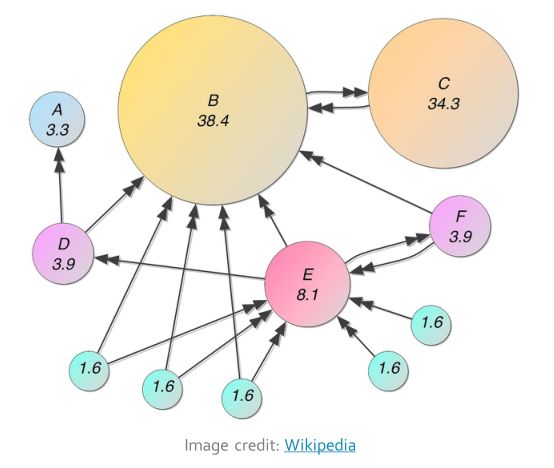
看上图,不存在重要性为0的节点,不重要的节点会赋值为较小的值,入1.6.
B B B和 E E E的入链数相同,但是 E E E的入链来自于一些不重要的节点,所以rank值低一些,而 B B B的入链来自于一些较重要的节点,所以rank值较大。
四、Random Walk with Restarts and Personalized PageRank
以一个推荐问题为例:
下图表示用户和物品交互(如购买)的bipartite graph:
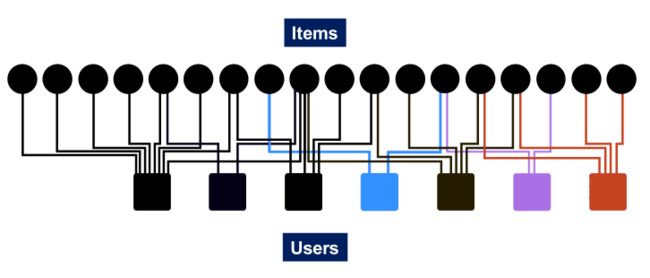
- 我们应该向与物品Q交互的用户推荐什么物品?
- 直觉:如果物品Q和P有相似的用户交互,当用户与Q交互时,推荐P。
因此,我们的目标是在图中找到与 Q Q Q有相似交互的节点 P P P。
如何评估相似性呢?
如下图,A '和A、B,B '哪个更相近呢?
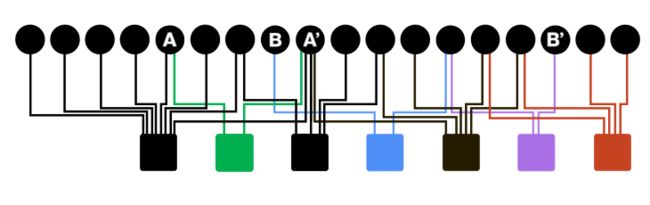
可以使用最短路径来评估节点的相似性,如下图;可以判断A和A’是更相似的。
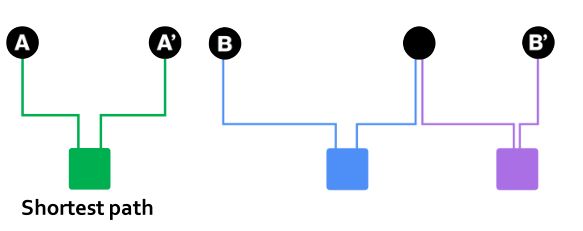
但对于下图,A,A’与C,C’都有着相同的最短路径,因此很难评估哪个更相似了。
但直觉上,C和C’是更相似,因为C和C’有更多的共同邻居。
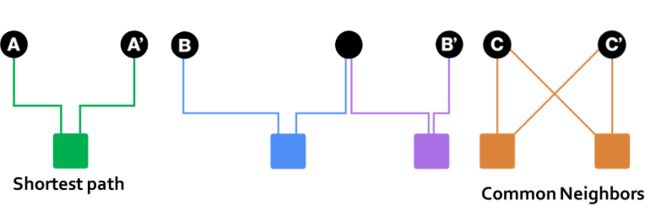
所以能否使用共同邻接的数量作为相似性的评估呢?
看下图;D,D’之间有着和C,C’一样数量的共同邻居,但D,D’之间的共同用户之间的相似性却很低。
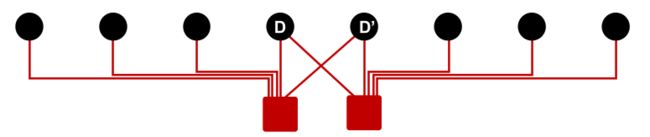
那该如何衡量两个节点之间的相似性呢?
可以使用Random Walks with Restarts
先介绍三个概念:
- PageRank:
- 根据“重要性”对节点进行排名
- 以均匀概率传送到网络中的任何节点
- Personalized PageRank:
- 根据顶点与转移顶点(teleport nodes)集S中节点的相似性进行排序
- Random Walks with Restarts:
- 根据顶点与给定节点Q的相似性进行排序
- 可以看作是Personalized PageRank的特例,转移顶点集S中只包含一个顶点。
什么是转移顶点集?
-
在标准的RandWalk中,每个节点会以(1-β)的概率转移到图中的任何一个节点,这里的转移顶点集是图中的所有顶点。
-
在Personalized PageRank中,每个节点会以(1-β)的概率转移到给定的转移顶点集S,这里的转移顶点集是图的一个子集。
-
在Random Walks with Restarts,转移顶点集缩小为一个给定的节点Q,每个节点会以(1-β)的概率转移到节点Q。只有一个顶点,所有每次随机游走都会有一定的概率回到原点,这也是名字中restars的含义。
-
在Personalized PageRank和Random Walks with Restarts中,转移节点是一个查询顶点集,即希望找出与转移节点集相似的顶点。
具体步骤:
- 给定一组QUERY_NODES,我们模拟随机游走;
- 随机向一个邻居迈出一步并记录访问次数(visit count)
- 在概率为ALPHA的情况下,会转移到QUERY_NODES中的其中一个节点,重新启动游走
- 访问计数最高的节点与QUERY_NODES的接近度最高
大概意思就是,先从QUERY_NODES中的一个节点开始随机游走,每游走到一个节点,就给这个节点的计数器+1。游走的过程中会有一定概率回到QUERY_NODES,重新开始游走。
最后,与QUERY_NODES相似的节点游走过程中经过的次数是最多的,即计数器的值较大。
算法流程图:
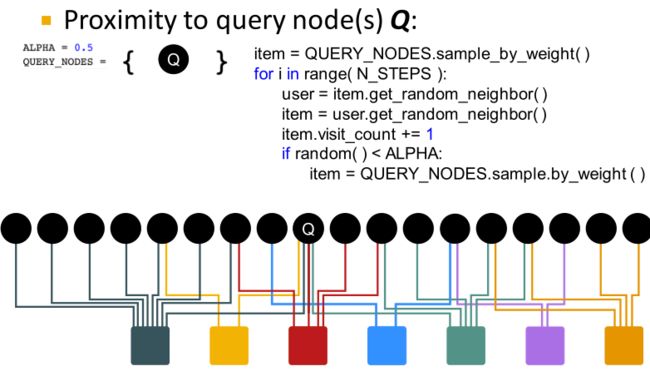
假设访问结果如下;可以评估绿色节点与Q节点相似度较大,而红色节点与Q相似性较小。

为什么这是个好的解决方案呢?
因为“相似性”考虑到了:
- Multiple connections
- Multiple paths
- Direct and indirect connections
- Degree of the node
五、Matrix Factorization and Node Embedding
在Node Embedding中,我们将节点的embedding组织成一个 d × N d\times N d×N的矩阵 Z Z Z,如下图:
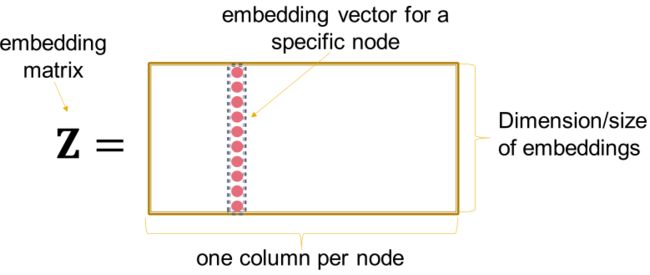
优化 Z Z Z的方式:
对于相似的节点对(u,v)最大化 z v T z u z^T_vz_u zvTzu。
接下来将上述内容与矩阵分解联系起来。
我们先定义一个最简单的相似度指标:
- 如果节点u和v由一条边连接,则它们是相似的。
- 即 z v T z u = A u , v z^T_vz_u=A_{u,v} zvTzu=Au,v; A u , v A_{u,v} Au,v是图邻接矩阵 A A A的第u行,第v列元素
- 向量化表示: Z T Z = A Z^TZ=A ZTZ=A

因此 Z Z Z可以看作是 A A A矩阵分解的结果。
- 嵌入维d (Z中的行数)比节点数n小得多。
- 所以,精确的因式分解 A = Z T Z A=Z^TZ A=ZTZ通常是不可能的。【肯定要丢失一些信息】
- 但是,我们可以近似地学习Z
- 目标: min Z ∣ ∣ A − Z T Z ∣ ∣ 2 \min\limits_Z||A-Z^TZ||_2 Zmin∣∣A−ZTZ∣∣2
- 优化Z的过程即优化上面的第二范式
- 在之前的的课程,使用的是softmax函数来代替L2范式,都是学习Z去近似A
- 结论:
由边连通性定义节点相似度的内积译码器,等价于A的矩阵分解
将上述结论进行扩展,DeepWalk和node2vec是基于random walk衡量节点相似度的更复杂的方式,因此Z可以表示为更复杂的矩阵的分解。
-
DeepWalk相当于将以下复矩阵表达式进行矩阵分解:

-
Node2vec也可以表述为矩阵分解(尽管是一个更复杂的矩阵)
- 感兴趣的看论文:
Network Embedding as Matrix Factorization: Unifying DeepWalk, LINE, PTE, and node2vec, WSDM 18
- 感兴趣的看论文:
基于矩阵分解和随机游走的节点嵌入的局限性:
-
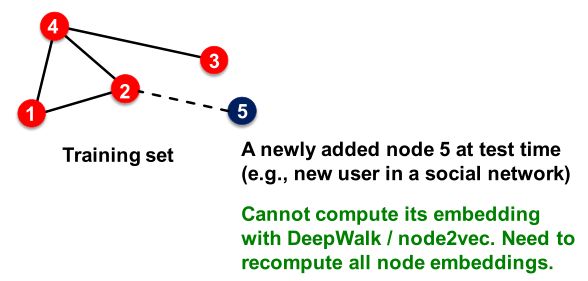
限制一:不适用于动态的使用场景,若添加了训练集以外的节点,就要从头开始。
-
限制二:无法捕捉结构相似性:
如下图,{1、2、3}和{11、12、13}在结构上很相似,但deepWalk和Node2vec会赋予1和11很不一样的embedding,因为它们的邻居很不同。
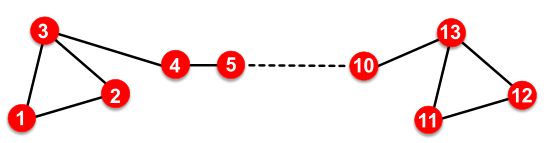
当然,可以通过匿名路径来忽略节点的身份,从而学习到结构相似性。
所以DeepWalk和node2vec不能捕获结构相似性。匿名路径可以学习到结构相似性 -
限制三:不能利用节点、边和图特征。
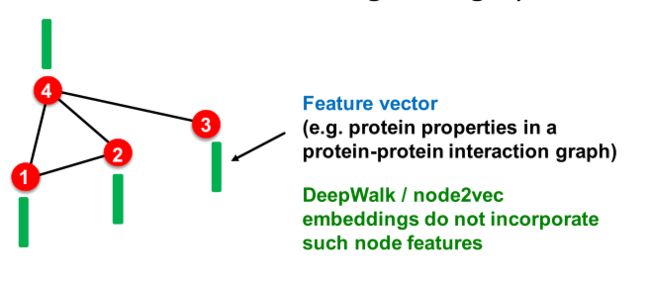
解决这些限制的方法:深度表示学习和图神经网络。
将在下一章进行讲解