机器学习及与智能数据处理Python使用朴素贝叶斯算法对垃圾短信数据集进行分类
文章目录
- 朴素贝叶斯算法
- 1.使用sklearn的朴素贝叶斯算法对垃圾短信数据集进行分类
-
- 要求:
- 代码:
- 结果:
- 2.自己写朴素贝叶斯算法对垃圾短信数据集进行分类
-
- 代码:
- 结果:
朴素贝叶斯算法
输入:样本集合D={(x_1,y_1),(x_2,y_2)~(x_m,y_m);
待预测样本x;
样本标记的所有可能取值{c_1,c_2,c_3~c_k};
样本输入变量X的每个属性变量X^i的所有可能取值{a_i1,a_i2,~,a_iAi};
输出:待预测样本x所属的类别
1.计算标记为c_k的样本出现概率。
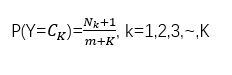
2.计算标记c_k的样本,其X^i分量的属性值为a_ip的概率。
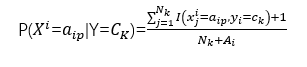
3.根据上面的估计值计算x属于y_k的概率值,并选择概率最大的作为输出。

1.使用sklearn的朴素贝叶斯算法对垃圾短信数据集进行分类
要求:
(1)划分训练集和测试集(测试集占20%)
(2)对测试集的预测类别标签和真实标签进行对比
(3)掌握特征提取方法
(4)输出分类的准确率
代码:
from sklearn.feature_extraction.text import CountVectorizer as CV
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import MultinomialNB as NB
import pandas as pd
# 加载SMS垃圾短息数据集
with open('SMSSpamCollection.txt', 'r', encoding='utf8') as f:
sms = [line.split('\t') for line in f]
y, x = zip(*sms)
# SMS垃圾短息数据集的特征提取
y = [label == 'spam' for label in y]
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=0)
counter = CV(token_pattern='[a-zA-Z]{2,}')
x_train = counter.fit_transform(x_train)
x_test = counter.transform(x_test)
# 朴素贝叶斯分类器的构造与训练
model = NB()
model.fit(x_train, y_train)
train_score = model.score(x_train, y_train)
test_score = model.score(x_test, y_test)
print('train score:', train_score)
print('test score:', test_score)
# 对测试集的预测类别标签和真实标签进行对比
y_predict = model.predict(x_test)
print('测试集的预测类别标签与真实标签的对比:\n', pd.concat([pd.DataFrame(x_test), pd.DataFrame(y_test), pd.DataFrame(y_predict)], axis=1))
结果:

2.自己写朴素贝叶斯算法对垃圾短信数据集进行分类
代码:
# coding = utf-8
import pandas as pd
import numpy as np
import random
import math
class bayesianClassifier(object):
def __init__(self, ratio=0.7):
self.trainset = []
self.testset = []
self.ratio = ratio
def loadData(self, filepath):
"""
:param filepath: csv
:return: list
"""
data_df = pd.read_csv(filepath)
data_list = np.array(data_df).tolist()
print("Loaded {0} samples secessfully.".format(len(data_list)))
self.trainset, self.testset = self.splitData(data_list)
return data_list
def splitData(self, data_list):
"""
:param data_list:all data with list type
:param ratio: train date's ratio
:return: list type of trainset and testset
"""
train_size = int(len(data_list) * self.ratio)
random.shuffle(data_list)
self.trainset = data_list[:train_size]
self.testset = data_list[train_size:]
return self.trainset, self.testset
def seprateByClass(self, dataset):
"""
:param dataset: train data with list type
:return: seprate_dict:separated data by class;
info_dict:Number of samples per class(category)
"""
seprate_dict = {}
info_dict = {}
for vector in dataset:
if vector[-1] not in seprate_dict:
seprate_dict[vector[-1]] = []
info_dict[vector[-1]] = 0
seprate_dict[vector[-1]].append(vector)
info_dict[vector[-1]] += 1
return seprate_dict, info_dict
def mean(self, number_list):
number_list = [float(x) for x in number_list] # str to number
return sum(number_list) / float(len(number_list))
def var(self, number_list):
number_list = [float(x) for x in number_list]
avg = self.mean(number_list)
var = sum([math.pow((x - avg), 2) for x in number_list]) / float(len(number_list) - 1)
return var
def summarizeAttribute(self, dataset):
"""
calculate mean and var of per attribution in one class
:param dataset: train data with list type
:return: len(attribution)'s tuple ,that's (mean,var) with per attribution
"""
dataset = np.delete(dataset, -1, axis=1) # delete label
summaries = [(self.mean(attr), self.var(attr)) for attr in zip(*dataset)]
return summaries
def summarizeByClass(self, dataset):
"""
calculate all class with per attribution
:param dataset: train data with list type
:return: num:len(class)*len(attribution)
{class1:[(mean1,var1),(),...],class2:[(),(),...]...}
"""
dataset_separated, dataset_info = self.seprateByClass(dataset)
summarize_by_class = {}
for classValue, vector in dataset_separated.items():
summarize_by_class[classValue] = self.summarizeAttribute(vector)
return summarize_by_class
def calulateClassPriorProb(self, dataset, dataset_info):
"""
calculate every class's prior probability
:param dataset: train data with list type
:param dataset_info: Number of samples per class(category)
:return: dict type with every class's prior probability
"""
dataset_prior_prob = {}
sample_sum = len(dataset)
for class_value, sample_nums in dataset_info.items():
dataset_prior_prob[class_value] = sample_nums / float(sample_sum)
return dataset_prior_prob
def calculateProb(self, x, mean, var):
"""
Continuous value using probability density function as class conditional probability
:param x: one sample's one attribution
:param mean: trainset's one attribution's mean
:param var: trainset's one attribution's var
:return: one sample's one attribution's class conditional probability
"""
exponent = math.exp(math.pow((x - mean), 2) / (-2 * var))
p = (1 / math.sqrt(2 * math.pi * var)) * exponent
return p
def calculateClassProb(self, input_data, train_Summary_by_class):
"""
calculate class conditional probability through multiply
every attribution's class conditional probability per class
:param input_data: one sample vectors
:param train_Summary_by_class: every class with every attribution's (mean,var)
:return: dict type , class conditional probability per class of this input data belongs to which class
"""
prob = {}
p = 1
for class_value, summary in train_Summary_by_class.items():
prob[class_value] = 1
for i in range(len(summary)):
mean, var = summary[i]
x = input_data[i]
p = self.calculateProb(x, mean, var)
prob[class_value] *= p
return prob
def bayesianPredictOneSample(self, input_data):
"""
:param input_data: one sample without label
:return: predicted class
"""
train_separated, train_info = self.seprateByClass(self.trainset)
prior_prob = self.calulateClassPriorProb(self.trainset, train_info)
train_Summary_by_class = self.summarizeByClass(self.trainset)
classprob_dict = self.calculateClassProb(input_data, train_Summary_by_class)
result = {}
for class_value, class_prob in classprob_dict.items():
p = class_prob * prior_prob[class_value]
result[class_value] = p
return max(result, key=result.get)
def calculateAccByBeyesian(self, ratio=0.7):
"""
:param dataset: list type,test data
:return: acc
"""
self.ratio = ratio
correct = 0
for vector in self.testset:
input_data = vector[:-1]
label = vector[-1]
result = self.bayesianPredictOneSample(input_data)
if result == label:
correct += 1
return correct / len(self.testset)
if __name__ == "__main__":
bys = bayesianClassifier()
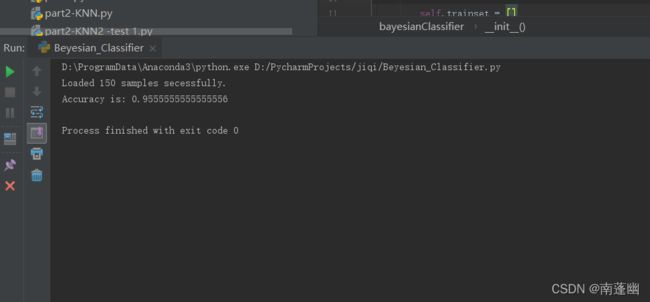
data_samples = bys.loadData('IrisData.csv')
print("Accuracy is:", bys.calculateAccByBeyesian(ratio=0.7))
结果: