万字超详细python基础解析
文章目录
-
- 1 Python简介
- 2 Python编码
- 3 python模块安装之pip
- 4 python的缩进规则
- 5 标识符
-
- 5.1 关键字
- 6 转义字符
- 7 注释
-
- 7.1 单行注释
- 7.2 多行注释
- 8 输出函数
-
- 8.1 格式化输出
- 8.2 精度和宽度控制
- 8.3 转换标志
- 8.4 格式字符归纳
- 控制输出字体样色
- 9 输入函数
- 10 变量与常量
- 11 数据类型
-
- 11.1 数据类型转换
- 12 python运算符
-
- 12.1 算术运算符的优先级
- 12.2 对象的布尔值
- 13 选择结构
-
- 13.1 条件表达式
- 13.2 pass语句
- 14 循环结构
-
- 14.1 range函数
- 14.2 while循环
- 14.3 for-in循环
- 14.4 流程控制语句
- 14.5 循环总结
- 15 列表
-
- 15.1 列表的基本操作
- 16 字典
-
- 16.1 字典的基本操作
- 16.2 字典总结
- 17 元组
-
- 17.1 元组的基本操作
- 18 集合
-
- 18.1 集合的基本操作
- 18.2 元组与集合总结
- 19 序列总结
- 20 字符串
-
- 20.1 字符串的驻留机制
- 20.2 字符串的操作
- 21 函数
-
- 21.1 递归函数
- 22 异常处理机制
-
- 22.1 BUG总结
- 23 python类
-
- 23.1 类总结
- 24 面向对象的三大特征
- 24.1 封装
-
- 24.2 继承
- 24.3 object类
- 24,4 多态
- 24.5 面向对象总结
- 25 类的浅拷贝与深拷贝
- 26 模块化编程
-
- 26.1 主程序运行
- 26.2 python常用模块
- 26.3 模块总结
- 27 python文件操作
-
- 27.1 os 模块
- 28 python文件打包
- 29 正则表达式
-
- 29.1 re模块
- 30 闭包
- 31 装饰器
- 32 迭代器
- 33 生成器
1 Python简介
Python是一个高层次的结合了解释性、编译性、互动性和面向对象的脚本语言。
- 解释性:这意味python在运行过程中没有编译这个过程
- 交互式:意味着可以直接运行代码而不用像c语言一样在main函数中执行代码
- 面向对象的语言:意味着python支持面向对象或代码封装的编程技术
2 Python编码
- 如果 python 源码文件 没有声明编码格式,python 解释器会默认使用 ASCII 编码
- 可以在文件头写#encoding=gbk等修改python默认的编码格式或者# -- coding: UTF-8 --修改
- 若文件中出现与编码格式不一致的字符时python解释器就会报错

3 python模块安装之pip
- pip是Python的包安装程序。其实pip就是python标准库中的一个包,可以用来管理python标准库中的包,也可以用来安装非python标准库的包
- 一般python安装包已经自带pip
- pip使用
- 可以在cmd界面中用pip help install查看安装使用说明
- 可以直接pip install+包名来安装包
- 安装时还可以指定版本安装包,例下:
pip install SomePackage # 最新版本 pip install SomePackage==1.0.4 # 指定版本 pip install 'SomePackage>=1.0.4' # 最小版本
- 查看安装包信息
- pip freeze 查看已经安装的包及版本信息
- 还可以导出包信息到指定文件。如:pip freeze > requirements.txt,文件名称随意;也可以使用 pip install -r requirements.txt,两者等效。
- 包卸载
- 卸载包命令:pip uninstall <包名>
- 批量卸载,把包信息导入到文件 pip uninstall -r requirements.txt
- 包升级
- pip install -U <包名> 或:pip install <包名> --upgrade
- 列出安装包
- pip list 查看已经安装的包及版本信息
- pip list -o 查看可更新的包信息
- 显示包所在目录及信息
- pip show <包名>
- pip show -f <包名> 查看包的详细信息
- 搜索包
- pip search <关键字>
4 python的缩进规则
- python一般用新行作为语句的结束标识
- python中用缩进来区分代码块
- Python PEP8 编码规范,指导使用4个空格作为缩进。
- 但是在复杂代码中会选择用2个空格作为缩进,使代码更容易读懂
- 物理行与逻辑行区别
- 物理行:代码编辑器中显示的代码,每一行内容是一个物理行
- 逻辑行:Python解释器对待吗进行介绍,一个语句是一个逻辑行
- 相同的逻辑行要保持相同的缩进
- ":"标记一个新的逻辑层
增加缩进表示进入下一个代码层
减少缩进表示返回上一个代码层 - 使用;可以把多个逻辑行合成一个物理行
- 使用\可以把逻辑行分成多行
5 标识符
- 标识符是编程时使用的名字,用于给变量、函数、语句块等命名,Python 中标识符由字母、数字、下划线组成,不能以数字开头,区分大小写。
- 以下划线开头的标识符有特殊含义
- _xxx ,表示不能直接访问的类属性,需通过类提供的接口进行访问,不能用 from xxx import * 导入
- 双下划线开头的标识符,如:__xx,表示私有成员
- 双下划线开头和结尾的标识符,如:xx,表示 Python 中内置标识,如:init() 表示类的构造函数
5.1 关键字
| and | exec | not | assert | finally | or |
|---|---|---|---|---|---|
| break | for | pass | class | from | |
| continue | global | raise | def | if | return |
| del | import | try | elif | in | while |
| else | is | with | except | lambda | yield |
- 自定义标识符时不能使用关键字
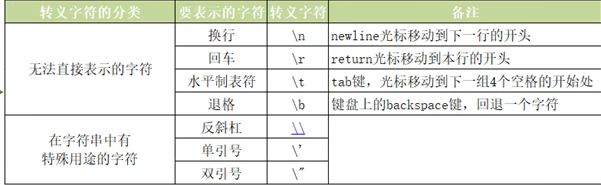
6 转义字符
- 需要在字符中使用特殊字符时,就需要用到转义字符,在python里用反斜杠‘\’转义字符。
- 当字符串中包含反斜杠、单引号和双引号等有特殊用途的字符时,必须使用反斜杠对这些字符进行转义(转换一个含义)
- ·当字符串中包含换行、回车,水平制表符或退格等无法直接表示的特殊字符时,也可以使用转义字符当字符串中包含换行、回车,水平制表符或退格等无法直接表示的特殊字符时,也可以使用转义字符
7 注释
- Python 解释器在执行代码时会忽略注释,不做任何处理。
- 注释最大的作用就是提高代码的可读性

7.1 单行注释
# 注释内容
7.2 多行注释
Python 使用三个连续的单引号'''或者三个连续的双引号"""注释多行内容,如:
'''
注释内容
'''
"""
注释内容
"""
8 输出函数
- python输出函数为print,无论什么类型的数据都可以直接输出,使用如下:
print(*objects, sep=' ', end='\n', file=sys.stdout)
- objects参数:表示输出对象。输出多个对象时,需要用逗号分隔
- sep参数:用来间隔多个对象
- end参数:用来设定以什么结尾
- file参数:要写入的文件对象
#如果直接输出字符串,而不是用对象表示的话,可以不使用逗号
print("Duan""Yixuan")
print("Duan","Yixuan")
运行结果如下:
DuanYixuan
Duan Yixuan
可知,不添加逗号分隔符,字符串之间没有间隔
- 在输出前加r表示原样输出
print(r'\hello word')
# \hello word
8.1 格式化输出

8.2 精度和宽度控制

- 在“:”后分别加^,<,>分别表示输出居中,左对齐,右对齐
- 第二三种不可控,其他格式控制方式与C语言一样
8.3 转换标志
- 转换标志:-表示左对齐;+表示在数值前要加上正负号;" "(空白字符)表示正数之前保留空格();0表示转换值若位数不够则用0填充。
p=3.141592653
print('%+3.1f'%p)
# +3.1
p=3.141592653
print('%010.1f'%p)
# 00000003.1
p=3.141592653
print('%-3.1f'%p)
#3.1
8.4 格式字符归纳
| 格式符 | 格式符输出 | 格式符 | 格式符输出 |
|---|---|---|---|
| %s | 字符串输出 | %r | 字符串输出 |
| %c | 单个字符输出 | %b | 二进制整数输出 |
| %d | 十进制整数输出 | %i | 十进制整数 |
| %o | 八进制整数输出 | %x | 十六进制整数输出 |
| %e | 指数输出(e为基底) | %E | 上同(E为基底) |
| %f | 浮点数 | %F | 浮点数 |
| %g | 指数(e)或浮点数(根据显示长度) | %G | 指数(E)或浮点数(根据显示长度) |
控制输出字体样色

9 输入函数
- python使用input()控制键盘录入
input('请输入:')
# 请输入:
- 一次性输入多个变量
a,b,c=input('请输入:').split(',')
# 录入多个数且用逗号隔开
- 以上一种方式的类型转换
a,b,c=map(int,input('请输入:').split(','))
# 这样就可以把所有数转换为int类型
10 变量与常量
- 变量:一般值改变后内存地址随着改变

- 局部变量和全局变量

- 常量:python没有常规意义上的常量,约定用全大写标识符表示常量,但其值还是可以改变
- 所以后来用户可以自定义类来实现常量
# -*- coding: utf-8 -*-
# python 3.x
# Filename:const.py
# 定义一个常量类实现常量的功能
#
# 该类定义了一个方法__setattr()__,和一个异常ConstError, ConstError类继承
# 自类TypeError. 通过调用类自带的字典__dict__, 判断定义的常量是否包含在字典
# 中。如果字典中包含此变量,将抛出异常,否则,给新创建的常量赋值。
# 最后两行代码的作用是把const类注册到sys.modules这个全局字典中。
class _const:
class ConstError(TypeError):pass
def __setattr__(self,name,value):
if name in self.__dict__:
raise self.ConstError("Can't rebind const (%s)" %name)
self.__dict__[name]=value
import sys
sys.modules[__name__]=_const()
# test.py
import const
const.PI=3.14
print(const.PI)
11 数据类型
- python常用数据类型:
| 类型 | 类型名 | 实例 |
|---|---|---|
| 整数类型 | int | 88 |
| 浮点类型 | float | 3.123 |
| 布尔类型 | bool | True,False |
| 字符串类型 | str | ‘人生苦短,我用python’ |
| 空值 | None | None |
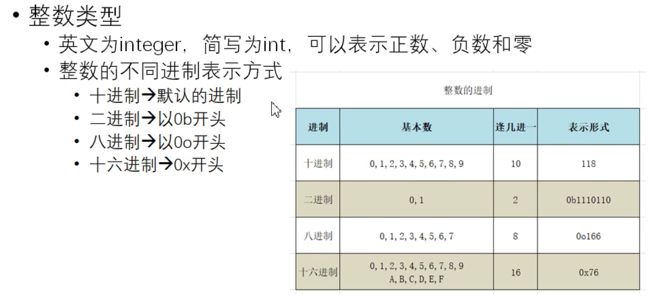
- 整数类型:
- 浮点类型:

- 布尔类型:

- 字符串类型:

11.1 数据类型转换
- 数据类型转化事项:

- 特别注意int()函数有两个参数,如果只有一个参数则转换为整数,如果有第二个参数,则为指定转换的进制
c='123' print(int(c,16)) #291
12 python运算符
| 算术运算符 | 赋值运算符 | 比较运算符 |
|---|---|---|
| 布尔运算符 | 位运算符 |
- 算术运算符:

- 整除一正一负向下取整
- 赋值运算符:
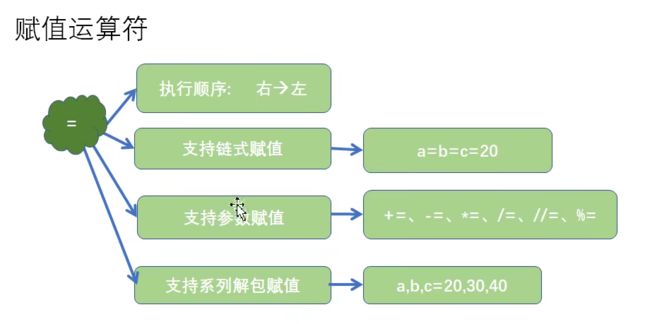
- python没有自增自减运算符,自增自减用+=、-+实现
- 比较运算符:

- 布尔运算符:

- 位运算符:

12.1 算术运算符的优先级
- 算术运算符优先级:

12.2 对象的布尔值
- python一切皆对象,所有对象都有一个布尔值
- 可以使用内置函数bool()获取对象的布尔值
- 布尔值为False的对象:
| False | 数值0 | None | 空字符串 |
|---|---|---|---|
| 空列表 | 空元组 | 空字典 | 空字典 |
- 其他对象布尔值为True
13 选择结构
- 语法结构:

- python的选择条件可以使用数学方式表达:
# 与c不一样,c不能连续比较 if 90<=score<=100- else后面不能接条件,只能接:
if 100>90: print('小于') else: print('大于')- 嵌套if

13.1 条件表达式
- 基本语法:
print(100 if 100>90 else 90)
# 输出100
# if判断条件为True输出前面,否则输出后面
13.2 pass语句
- pass简介

14 循环结构
14.1 range函数
- 用于生成一个整数序列,默认从0开始
- 基础语法:

14.2 while循环
- 基础语法:
i=0
while i<5:
print(i)
i+=1
# 0 1 2 3 4
14.3 for-in循环
- 基础语法:
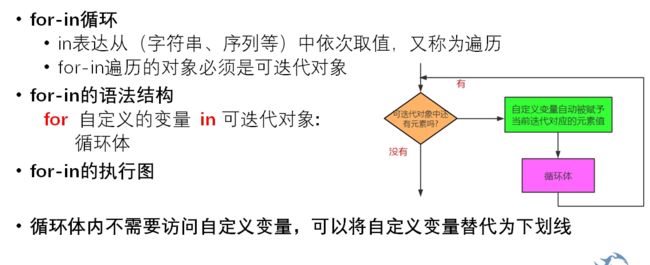
for i in range(3):
print(i)
# 0 1 2
- 不需要变量时:
for _ in range(3):
print('人生苦短,我用python')
14.4 流程控制语句
- break语句
- 基础语法:

- 基础语法:
- continue语句:
- 基础语法:

- 基础语法:
- else语句:
- 基础语法:
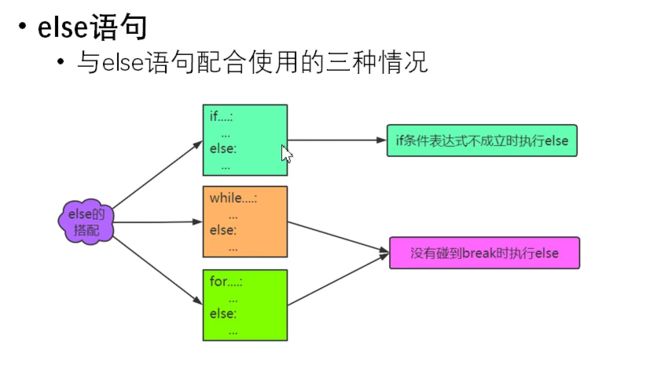
- 基础语法:
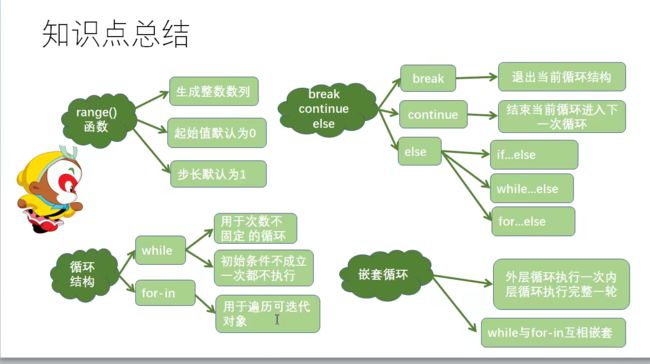
14.5 循环总结
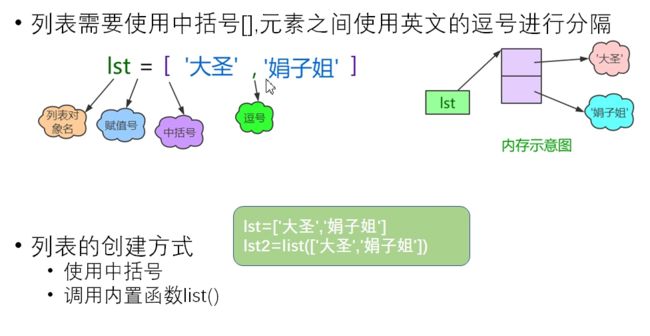
15 列表
- 列表可存储不同类型的值
15.1 列表的基本操作
- 创建列表:
r=[12,"i"]
print(r)
# [12, 'i']
r=list('1234')
print(r)
# ['1', '2', '3', '4']
- 列表的特点:

- 获取列表指定元素的索引(index()函数)
l=[1,2,3]
print(l.index(1))
# 0

- 获取列表的多个元素(切片)
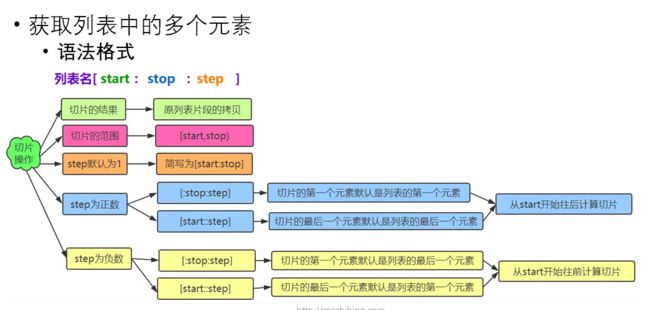
- 切片会产生新的列表
l=[1,2,3]
print(l[1:])
# [2, 3]
-
列表查询与遍历

l=[1,2,3] print(1 in l) # True -
列表的增加操作
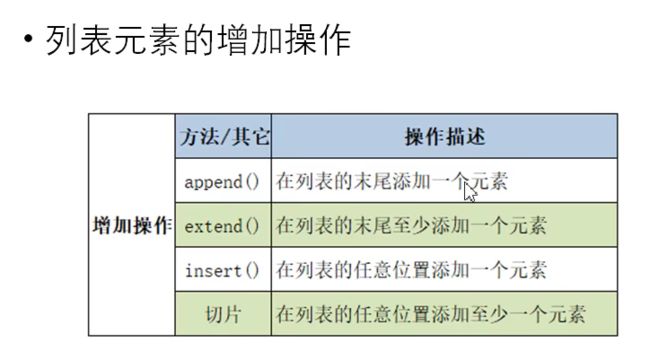
l=[1,2,3] # 在末尾加一个元素 l.append(4) print(l) # 在末尾加任意多元素,参数为列表 l.extend([5,6]) print(l) # 在第6个位置加上一个7元素 l.insert(6,7) print(l) # 切片,把切出去的部分用新列表替换 l[1:]=[8] print(l) -
列表的删除

l=[1,1,2,3] # 删除1元素 l.remove(1) print(l) # 删除第0个元素,若不指定则删除最后一个元素 l.pop(0) print(l) # 切片出第0个到第1个元素 print(l[0:1]) # 清除全部元素 l.clear() print(l) # 删除列表 del(l) print(l) 23 # [1, 2, 3] # [2, 3] # [2] # [] # 报错,没有l变量 -
列表的排序

- sort()不会产生新列表对象
- sorted()会产生新的列表对象
l=[3,2,1] # 不会产生新对象 l.sort() print(l) # 会产生新对象 r=sorted(l) print(l) -
列表生成式
- 基本语法:
- i for i in 迭代器
# 生成一个1-9元素的列表 lst=[i for i in range(1,10)] - 基本语法:
16 字典
- 以键值对的方式无序存储数据

- 把key进过哈希函数计算得出位置
- key要求为不可变序列
- key不可重复
16.1 字典的基本操作
- 创建字典:

- 字典元素的获取

s={"张三":100} t=s["张三"] print(t) # 设置默认查找值,当查字典没有的元素时返回默认值 t=s.get("lisi",99) print(t) #100 #99 - key的判断、元素删除、元素新增


- 获取字典视图

s={"张三":100} # 获取所有key print(s.keys()) # 获取所有值 print(s.values()) # 获取所有键值对 print(s.items()) #dict_keys(['张三']) # dict_values([100]) # dict_items([('张三', 100)]) - 字典遍历
s={"张三":100} # item 获取的是key # s[item]获取值 for item in s: print(item) print(s[item]) - 字典生成式

- 基本语法
- for({列表:列表 for 列表,列表 in zip(列表, 列表)})
s=[1,2,3] t=[4,5] print({s: t for s, t in zip(s, t)})- 若zip打包的两个列表元素数目不一样,则按元素数目少的列表打包
- 基本语法
16.2 字典总结

17 元组
- 是一个不可变序列
17.1 元组的基本操作
- 元组的创建
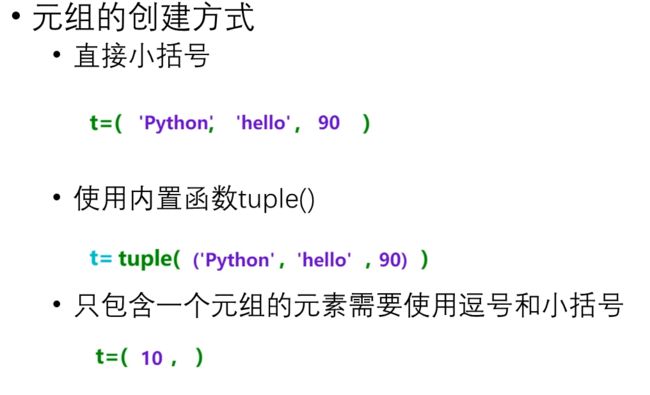
- 第一种方式可以省略小括号
- 第三种方式如果省略逗号,会被认为是元素原来的类型
- 为什么要把元组设计成不可变序列?

- 遍历元组:
t=1,2,3,4 for i in t: print(i) - 元组生成式
- 元组没有生成式
18 集合
- 集合是没有value的字典

18.1 集合的基本操作
- 集合的创建

- 集合的元素不能重复
- 空集合创建只能用内置函数进行设置
- 集合的判断,新增,删除

s={1,2,3} # 末尾增加一个元素 s.add(4) print(s) # 末尾至少增加一个元素 s.update([5]) print(s) # 删除一个指定元素 s.remove(2) print(s) # 删除一个指定元素 s.discard(1) print(s) # 一次删除头部一个元素 s.pop() print(s) # 清空元素 s.clear() - 集合间的关系

s={1,2,3,4} t={3,4} # 判断集合是否相等 print(s==t) # 判断集合t是否是集合s的子集 print(t.issubset(s)) # 判断集合s的父集是否是t print(s.issuperset(t)) # 判断两个集合是否是没有交集 print(s.isdisjoint(t)) #False #True #True #False - 集合的数学操作

s={1,2,3,4} t={3,4,5,6} # 集合的交集 print(s.intersection(t)) print(s&t) # 集合的并集 print(s.union(t)) print(s|t) # 集合的差集 print(s.difference(t)) print(s-t) # 集合的对称差集 print(s.symmetric_difference(t)) print(s^t) - 集合生成式

print({i for i in range(1,10)})
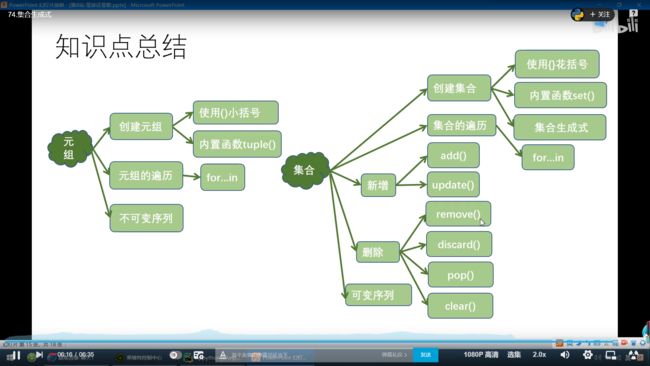
18.2 元组与集合总结
19 序列总结
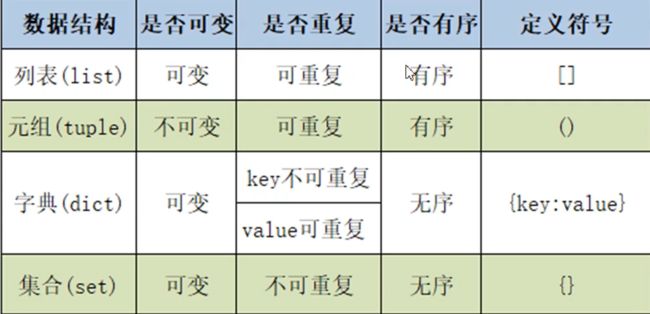
- 不可变序列还有字符串
20 字符串
- python基本数据类型,是一个不可变序列
20.1 字符串的驻留机制
- 基本概述


- pycharm中对字符串的驻留机制进行了优化,只要是字符串都可以驻留
- 驻留机制优缺点
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SKvBkivX-1645512642755)(https://note.youdao.com/yws/public/resource/92933d878935240680c00793fc3e404c/xmlnote/WEBRESOURCE0dafb644fe2f97462c17e1e63d4b2c26/169)]
20.2 字符串的操作
- 字符串的查询

s='python人生苦短,我用python' # 查找子串第一次出现的位置,无子串报错 print(s.index('python')) # 查找子串最后一次出现的位置,无子串报错 print(s.rindex('python')) # 查找子串第一次出现的位置,无子串返回-1 print(s.find('python')) # 查找子串最后一次出现的位置,无子串返回-1 print(s.rfind('python')) #0 #13 #0 #13 - 字符串的大小写转换

s='人生苦短python,我用Python' # 全部字符转换为大写 print(s.upper()) # 全部字符转换为小写 print(s.lower()) # 大写转小写,小写转大写 print(s.swapcase()) # 第一个字符转换为大写,其他字符转换为小写 print(s.capitalize()) # 把每个单词第一个字母大写,其他为小写 print(s.title()) # 人生苦短PYTHON,我用PYTHON # 人生苦短python,我用python # 人生苦短PYTHON,我用pYTHON # 人生苦短python,我用python # 人生苦短Python,我用Python - 字符串对齐

s='人生苦短python,我用Python' # 居中 print(s.center(48)) # 右对齐 print(s.rjust(48)) # 左对齐 print(s.ljust(48)) # 右对齐 print(s.zfill(48))
- 字符串的劈分
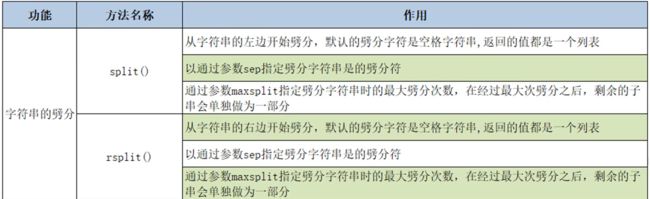
s='hello,world ' print(s.split(sep=',',maxsplit=1)) # ['hello', 'world '] - 字符串的判断
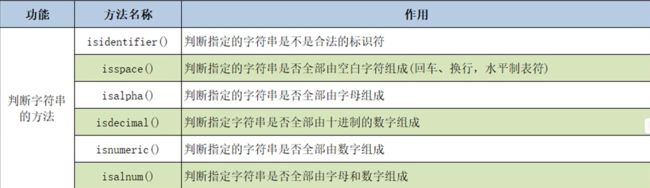
s='hello2022' # 判断是否为合法的标识符 print(s.isidentifier()) # 判断是否全由空白字符组成 print(s.isspace()) # 判断是否全为字母 print(s.isalpha()) # 判断是否全为十进制数字 print(s.isdecimal()) # 判断是否全为数字 print(s.isnumeric()) # 判断是否全为字母和数字 print(s.isalnum()) #True #False #False #False #False #True - 字符串的替换与合并

s='hello2022' lst=["1,2,3",'木头人'] # 将指定子串替换 print(s.replace('2','1')) # 在每两个列表元素中间加一个字符串 print(s.join(lst)) # hello1011 # 1,2,3hello2022木头人 - 字符串的比较

s='hello2022' r='H' print(s>r) print(s>=r) print(s - 字符串的切片
- 由于字符串是不可变序列,字符串的增删改切片等操作都会产生新的对象
- 字符串的编码转换
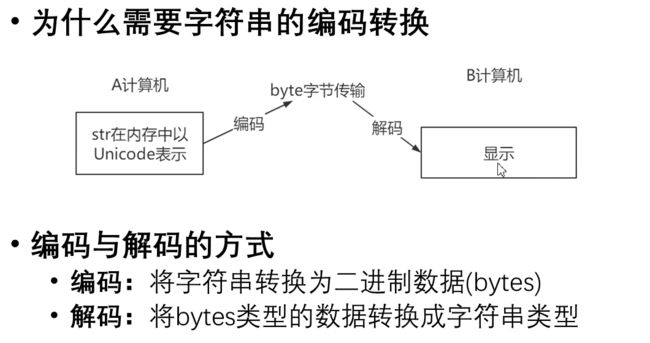
- 字符串的编码
- 使用str类的encode方法
- 字符串的解码
- 使用decode方法
s='天涯共此时' # 编码 print(s.encode(encoding='GBK')) print(s.encode(encoding='UTF-8')) # 解码 r=s.encode(encoding='GBK') print(r.decode(encoding='GBK')) # b'\xcc\xec\xd1\xc4\xb9\xb2\xb4\xcb\xca\xb1' # b'\xe5\xa4\xa9\xe6\xb6\xaf\xe5\x85\xb1\xe6\xad\xa4\xe6\x97\xb6' # 天涯共此时- 编码和解码所使用的的字符编码必须一致否则会报错
- 字符串的编码
21 函数
- 函数就是执行特定任务和完成特定功能的一段代码
- 函数的好处
- 复用代码
- 隐藏实现细节
- 提高可维护性
- 提高可读性便于调试
- 函数的创建
def 函数名(输入参数): 函数体 [return xxx] - 函数参数传递

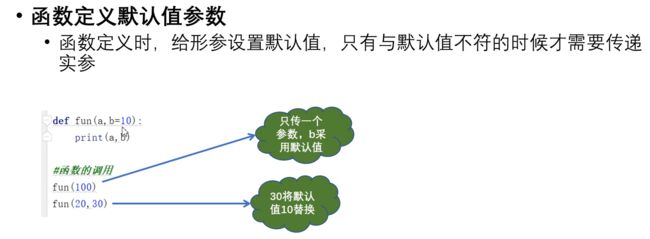
- 默认值参数
- 其他类型参数

- 如果两个参数都有,则可边的位置参数要在可变的关键字参数前面
- 当*args,**kwargs接受参数后,*args意思为把args元组里的数据打散为位置参数,**kwargs为把kwargs字典里的数据打散为关键字参数
- 默认值参数
- 参数总结

- 函数内存分析
- 如果不可变对象,那么在函数体内的修改不会影响实参的值,如果是可变对象,在函数体的修改会影响到实参
- 函数的返回值
- python支持多返回值
- 如果函数没有返回值,return可以省略不写
- 函数的返回值如果是一个直接返回类型
- 函数的返回值如果是多个,返回的结果是一个元组
- python支持多返回值
21.1 递归函数
- 如果一个函数的函数体调用了函数本身,这个函数就被称为递归函数

22 异常处理机制
- 被动掉坑类型(try-expect)
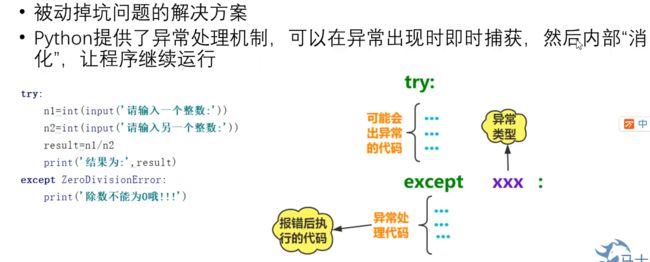
- 当存在多个expect结构时应该按照先子类再父类的顺序捕获异常,为避免遗漏可能出现的异常,可以在最后加BaseException
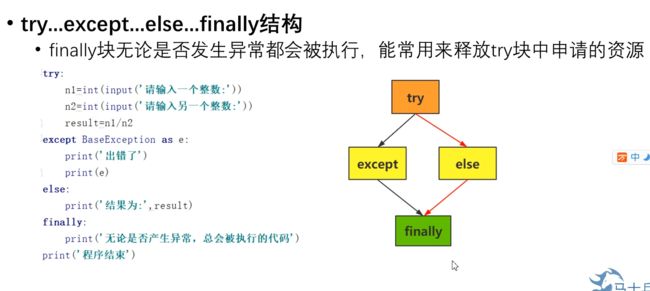
- try-except-else:

- try-except-else-finally:
- python常见的BUG类型

- traceback模块

- 可以把异常打印在日记文件中
- 手动抛出异常
if 0<=score<=100: print('分数为:',score) else: raise Exception('分数不正确')- 当没有try语句时,异常由python捕获
22.1 BUG总结

23 python类
- 创建python类

- 类之外的叫函数,类里面的叫方法
- 类属性,类方法,静态方法都可以直接类名.属性名调用,不需要创建对象
- 对象的创建
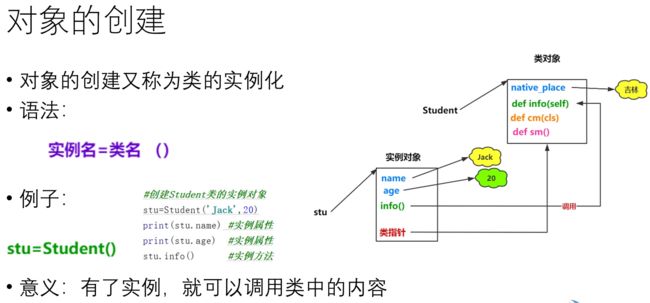
- 动态绑定属性和方法


class Student: def __init__(self,name,age): self.name=name self.age=age def show(self): print('我是{},今年{}'.format(self.name,self.age)) def show(): print('我是函数') stu=Student('李磊',20) stu.show() stu.show=show stu.show() #我是李磊,今年20 #我是函数
23.1 类总结

24 面向对象的三大特征

24.1 封装
- python没有专门的封装关键字,所以在属性名前用__表示私有
class A:
__place="吉林"
# 列出A中所有属性
print(dir(A))
print(A._A__place)
# ['_A__place']
# 吉林
24.2 继承
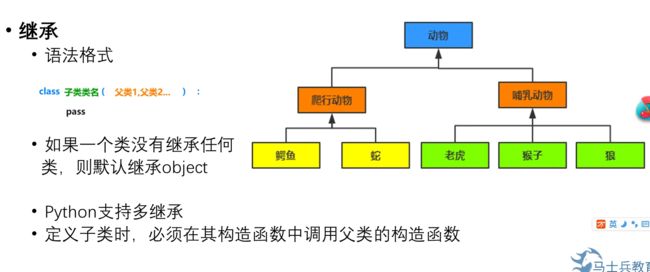
class A:
pass
class B:
pass
# 继承A,B类
class C(A,B):
pass
- 方法重写

24.3 object类

- object类特殊的方法和属性
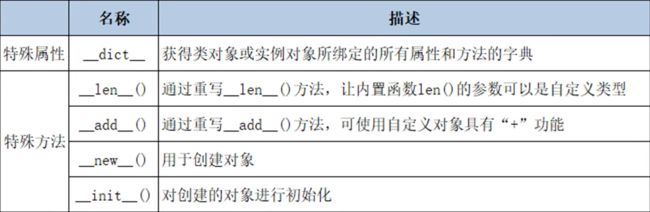
class C:
pass
class B(C):
pass
class A(B,C):
pass
a=A()
print(a.__class__)# 输出对象所属类
print(A.__base__)# 输出类的基类
print(A.__bases__)# (, ) 输出所有父类
print(A.__mro__)#(, , , ) 输出基础层次
print(C.__subclasses__())# [, ] 输出所有子类的列表
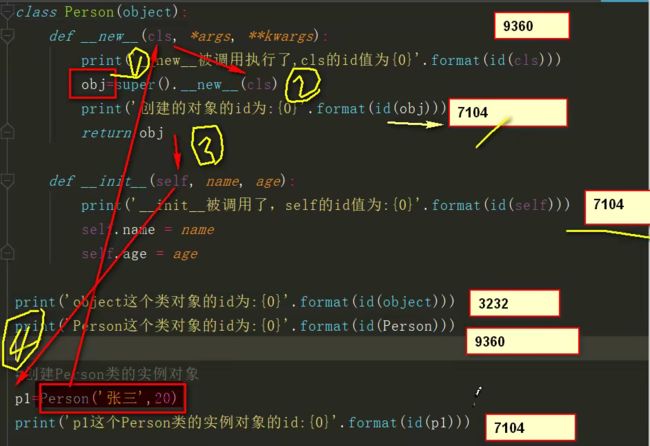
- new__与__init(new在前)
24,4 多态

- 静态语言和动态语言关于多态的区别

24.5 面向对象总结

25 类的浅拷贝与深拷贝
- 基础介绍

- 浅拷贝
import copy class CPU: pass class Disk: pass class Computer: def __init__(self,Disk,CPU): self.Disk=Disk self.CPU=CPU disk=Disk() cpu=CPU() a=Computer(disk,cpu) b=copy.copy(a) print(a,a.Disk,a.CPU) print(b,b.Disk,b.CPU) # <__main__.Computer object at 0x016B0A18> <__main__.Disk object at 0x00ACE580> <__main__.CPU object at 0x00A9AF40> # <__main__.Computer object at 0x016F4310> <__main__.Disk object at 0x00ACE580> <__main__.CPU object at 0x00A9AF40>
- 深拷贝
- 在浅拷贝基础上拷贝子对象
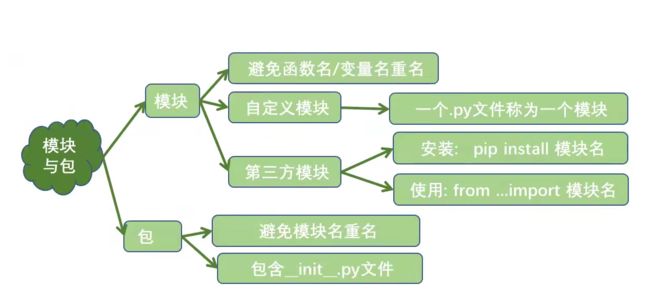
26 模块化编程
- 模块基础

- 创建与导入模块

- 使用import时只能接包名和模块名,from…import可以导入包,模块,变量
- 同一目录下直接导入

- from post_packaging.method import *
- 不同目录下导入
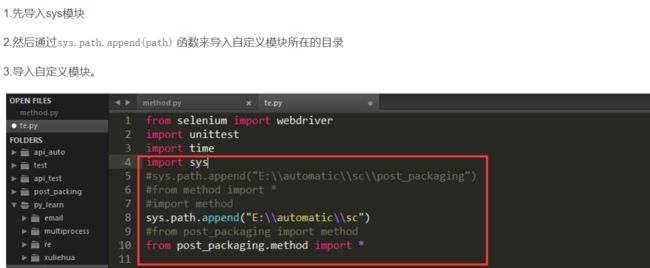
- python包

26.1 主程序运行

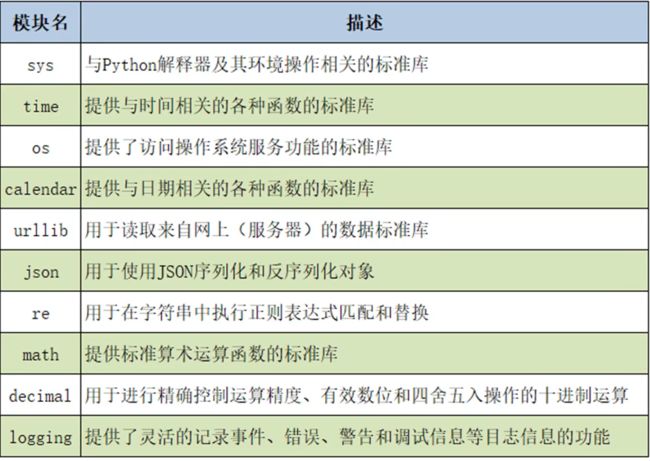
26.2 python常用模块
26.3 模块总结
27 python文件操作
- 文件的读写

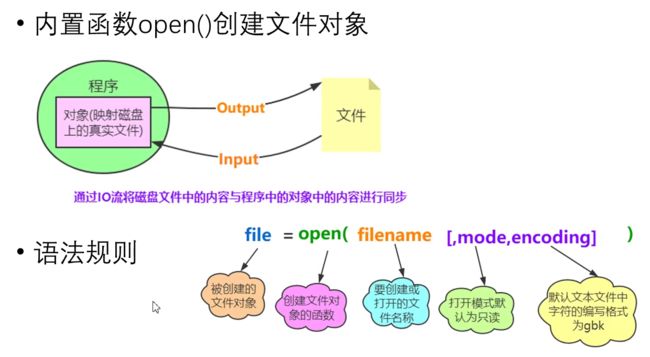
file=open(file,mode='r',encoding='gbk') - 常用文件处理方式

- 文件常用方法
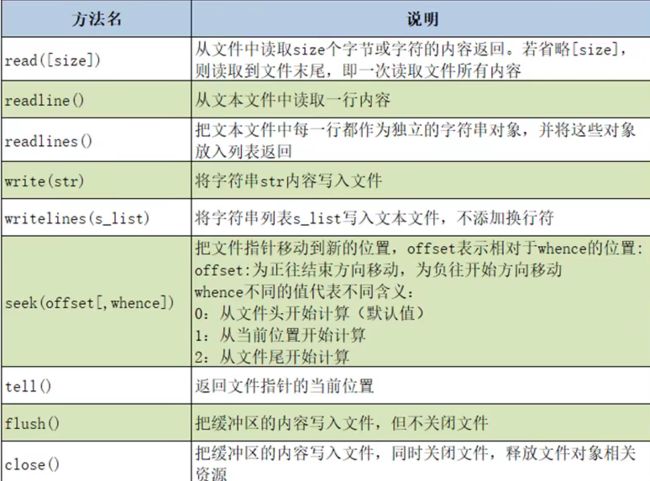
- 文件对象调用完一定要关闭
- with语句

with open('a.txt','r) as file:
print(file.read())
27.1 os 模块

- 操作目录的方法

- os.walk()会把所有子目录和文件遍历出来
- os.path操作目录常用函数

28 python文件打包
- Pyinstaller -F py_word.py 打包exe
- Pyinstaller -F -w py_word.py 不带控制台的打包
- Pyinstaller -F -w -i chengzi.ico py_word.py 打包指定exe图标打包
29 正则表达式

- 正则支持普通字符
- 元字符:
- \d:匹配一个数字的数字
- \w:匹配一个数字、字母、下划线
- \W,\D:匹配与上面取反(\D就是取数字以外的内容)
- []:取范围
- .:匹配换行符之外的东西
- 量词:
- 控制前面元字符出现的频次
- +:前面元字符出现1次或多次
- *:前面元字符出现0次或多次,尽可能多的匹配结果
- ?:前面元字符出现0次或多次
- 惰性匹配
- 1.*2:以1开头2结尾的尽可能长的字符
- 1.*?2:以1开头以2结尾尽可能短的字符(惰性匹配)
29.1 re模块
| 函数 | 作用 |
|---|---|
| re。findall(“正则表达式”,“字符串”) | 拿到列表 |
| re.search | 拿到第一个结果就返回,返回一个match对象,要输出match对象的话要用到group方法 |
| re.finditer | 把拿到的对象全放到迭代器里,也是match对象,结果比较大就用这个 |
- 预加载
- obj=re.conpile(r"正则表达式")
- 先创建一个正则表达对象
- obj.findall(“字符串”)
- 提取惰性匹配的值

- 也可以用groupdict方法,输出为字典
30 闭包
- 本层函数对外层函数的局部变量的使用,此时内层函数被称为闭包函数
- nonlocal关键字
- 用来在函数或者其他作用域中使用改变外层(非全局)变量
- global关键字
- 使局部变量改变全局变量
- 闭包作用
- 让一个变量常驻于内存
- 可以在外部使用改变局部变量
- 可以避免全局变量被修改
def func(fn):
def inner():
print('fn进来了')
fn()
print('fn出去了')
return 'f'
return inner
31 装饰器
- 装饰器本质就是闭包,对外部参数的引用

- 作用:再不改变原有函数调用下,给函数增加新功能

- 被装饰函数的参数问题
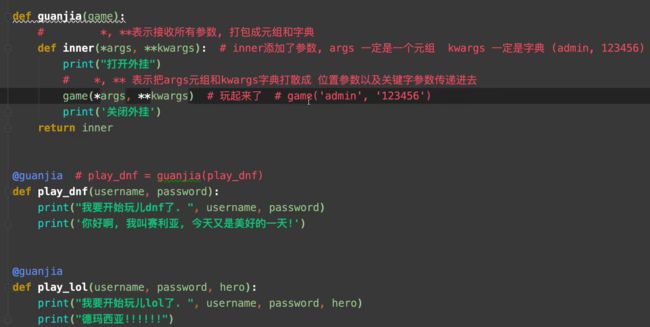
- 被装饰函数有参数的话,返回函数和目标函数都要加参数
- 一个函数可被多个装饰器装饰

- 通用装饰器写法

32 迭代器
- 迭代器基本概念


- 迭代器的特点
- 只能向前不能反复
- 特别节省内存
- 惰性机制
- 迭代器的特点
33 生成器
- 本质就是迭代器
- 生成器函数

def order(): lst=[] for i in range(100): lst.append(f"衣服{i}") if len(lst)==3: yield lst lst=[] gen=order() print(gen.__next__()) print(gen.__next__()) # ['衣服0', '衣服1', '衣服2'] # ['衣服3', '衣服4', '衣服5'] - 推导式

- 生成器表达式
- 优点:用好了特别节省内存
- 生成器表达式是一次性的
- 语法:
- (数据 for循环 if)