聚类树图(dendrogram)绘制(matplotlib与scipy)
聚类树图是层次聚类的图形表示方法,可以直观地体现各组数据或变量之间的关系聚类图在诸多领域具有广泛应用。聚类树图也称为聚类树状图、聚类图、聚类树。在生物学中称其为系统树图。
一:基本原理
层次聚类法是多元统计中聚类分析的重要方法之一。过程为:每次计算各样本之间距离(距离度量方法详见兔兔的《相似性度量(距离度量)方法》系列文章),将距离近的样本合并为一个新的样本(计算合并的新样本的数值有不同的方法)。之后再重复上述操作,直至所有样本合并为1个样本。整个过程是从叶节点到根节点的递归。
对样本进行聚类,称为Q型聚类(样本聚类);对指标进行聚类,称为R型聚类(指标聚类)。
在层次聚类图中,横坐标表示各个样本(或变量),纵坐标表示距离。
如果从基本原理出发,是可以设计程序进行层次聚类:将数据以嵌套字典等可以表示树形结构的形式储存起来,再用plt.plot()绘制相应的线段,便可以形成树形聚类图。但是这个过程过于繁琐,使用scipy可以很容易地实现该过程。
二:绘制方法
(1)数据处理
进行聚类的数据可以为pd.DataFrame、numpy中的矩阵、二维数组等。它是以矩阵中每行作为一个样本进行层次聚类,所以若进行Q型聚类,需要保证每行代表一个样本,每列为一个指标。标签表示Q型聚类中每个样本名、序号,或R型聚类中的指标名,形式为列表、一维数组,列表中的标签顺序需与矩阵中每行顺序一致。
(2)基础绘制
兔兔采用随机生成的10×5维的矩阵进行层次聚类,各样本标签为[0,1,2,3,4,5,6,7,8,9]。
from scipy.cluster import hierarchy
import matplotlib.pyplot as plt
import numpy as np
data1=np.random.normal(size=(10,5)) #随机生成10个样本,5个指标的数据,进行Q型层次聚类
labels=np.arange(10) #样本标签
plt.figure(figsize=(5,5)) #画布大小
Z=hierarchy.linkage(y=data1,method='weighted',metric='euclidean') #生成聚类树
hierarchy.dendrogram(Z,labels=labels) #画聚类树
plt.show()聚类树如下所示。
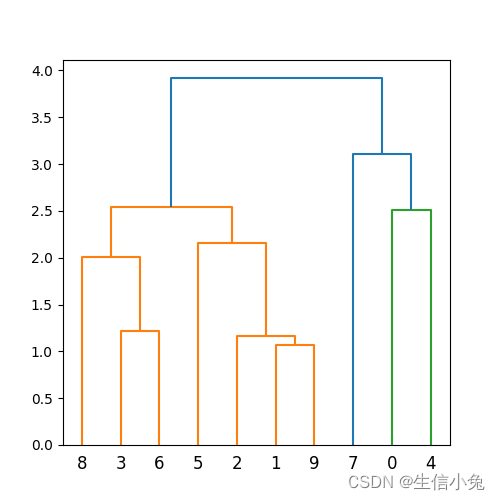
仅通过简单的基础绘制,我们便可以直观地看出各样本之间的距离关系。
(3)聚类树的生成
对于层次聚类,影响聚类结果主要分为两个方面:距离度量方法不同与层次聚类方法的不同。在scipy.cluster.hierarchy生成聚类树函数linkage中,参数metric表示距离度量方法,上面采用的是'euclidean'欧式距离,对于其它距离与相应字符串详见附录;参数method表示聚类方法,即每次将样本合成新样本时新样本的取值确定的方法,上面采用的是'weighted',其它的层次聚类方法与相应字符串详见附录。
linkage输出Z是包含聚类树信息的(n-1)×4矩阵(n表示样本数),矩阵Z第1、2列表示被两两连接生成一个新类的对象索引;第3列表示两两对象的连接距离;第4列表示当前类中原始对象的个数。
(4)细节补充
hierarchy.dendrogram(Z=,labels=,orientation=,color_threshold=,leaf_rotation=,leaf_font_size=,truncate_mode=,p=)
Z:linkage或fcluster计算生成聚类树数据。
labels:数据标签。
orientation:'top','bottom','left','right',聚类图方向。
color_threshold:根据距离,采用不同颜色划分聚类图,值在0~最大距离之间。
leaf_rotation:标签逆时针旋转角度。
leaf_font_size:标签大小。
truncate_mode与p:两个参数配合使用,截断压缩树状图。truncate_mode:'none','lastp','level','mtica'。'none'表示不截断,此时设置p无意义;'lastp'表示只显示p级后的树状图,'level'与'mtica'作用相同,表示显示p级前的树状图。p为整数。
(5)举例
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy.cluster import hierarchy
data=pd.DataFrame(pd.read_csv('Dry_Bean_Dataset.csv')).loc[0:99,'Area':'ShapeFactor4']
labels=np.arange(100)
plt.figure(figsize=(20,5)) #画布大小
plt.title('Dendrogram of dry bean dataset',fontdict={'size':20})
Z=hierarchy.linkage(y=data,method='weighted',metric='euclidean')
hierarchy.dendrogram(Z=Z,labels=labels,orientation='top',leaf_rotation=90,leaf_font_size=7,
color_threshold=1300,truncate_mode='none',p=3) #画聚类树
plt.xticks(color='black',rotation=90,verticalalignment='top',horizontalalignment='left') #进一步更改x轴标签
plt.tick_params(axis='x',direction='out',length=4,width=2,pad=4,labelsize=9)
plt.show()
附录
1.metric 距离度量种类
'euclidean'欧式距离;'minkowski'闵氏距离;'cityblock'绝对值距离(曼哈顿距离);'chebychev':切比雪夫距离;'mahalanobis'马氏距离;'hamming'汉明距离;'braycurtis' 布雷-斯蒂克相异度;'canberra'堪培拉距离;'correlation'皮尔逊相关系数;'cosine'余弦相似性;'dice'骰子系数;'jaccard'杰卡德系数;'jensenshannon';'kulsinski'库尔辛斯基差异;'matching';'rogerstanimoto'田本罗杰斯差异;'russellrao'拉塞尔差异;'seuclidean';'sokalmichener':索卡尔米切纳差异;'sokalsneath'索卡尔雪差异;'sqeuclidean';'Y=yule'......
2.method 层次聚类方法
'single'最短距离;'complete'最大距离;'average':无权平均距离;'centroid'重心距离;'ward'离差平方和方法......