Transformer小结
文章目录
-
-
- Model Architecture
- Self-Attention
- Multi-Head Attention
- Positional Encoding
- Eecoder
- Decoder
- Summary
- Reference
-
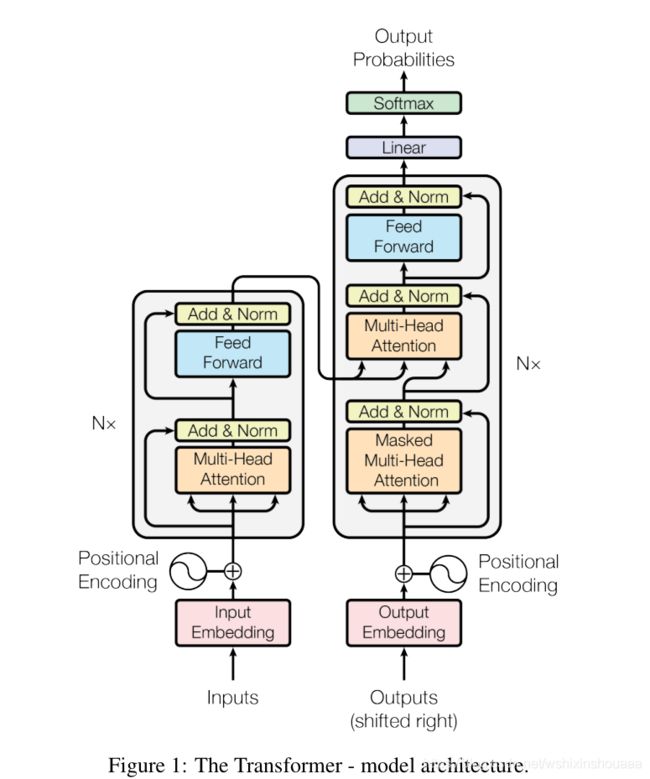
Model Architecture
一、Encoder
Encoder 由六个相同的层堆叠组成,每个层中又包含两个子层:Multi-Head Attention 和 Feed Forward。每个子层后由残差连接一个 Layer Normalization 。
二、Decoder
Decoder 也由六个相同的层堆叠组成,每个层中包含三个子层:Masked Multi-Head Attention、Multi-Head Attention 和 Feed Forward,比 Encoder 多了一个子层,其他结构不变。
三、Multi-Head Attention
Multi-Head Attention 是由多个 Self-Attention 拼接而成,本质还是 Self-Attention 运算。
Self-Attention
根据上文中 Attention 的介绍,Attention 的本质可以看作是根据 Query ,查找键值对
Attention 结构图如下所示,在 Transformer 的 Encoder 中是没有Mask操作的。

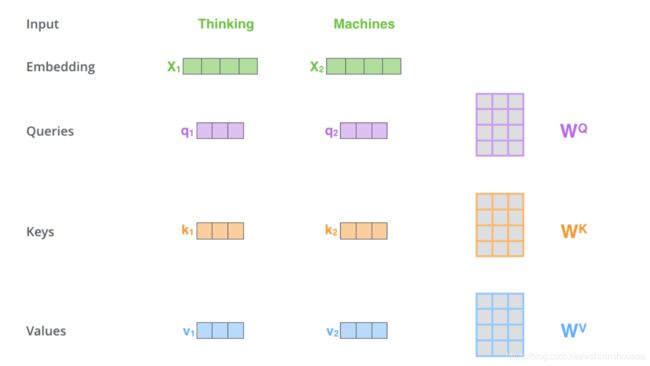
一、首先获取 Query,Key, Value:
Transformer 给定的 Embedding 的维度是 512,直接作为 Query,Key, Value 的话计算量比较大。为了减少维度,训练三个数组 W Q , W K , W V W^{Q},W^{K},W^{V} WQ,WK,WV ,使 Query,Key, Value 的维度降为 64。
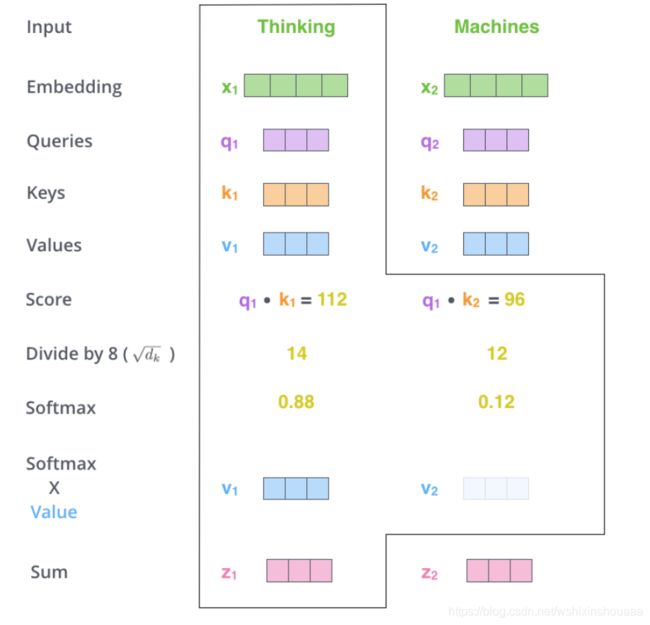
二、将输入句子中的每个词与所有的词都进行 Attention 计算,根据权重值累加 Query 得到每个词新的表示。
三、一些细节
先来说第一步中如何利用数组 W Q , W K , W V W^{Q},W^{K},W^{V} WQ,WK,WV 使 Query,Key, Value 的维度降为 64。
输入 X 的大小为 (句子长度 * Embedding_size) ,而 W Q , W K , W V W^{Q},W^{K},W^{V} WQ,WK,WV 的大小为 (Embedding_size * 64) ,数组相乘后得到大小为 (句子长度* 64) 的 Q , < K , V > Q, <K, V> Q,<K,V> 。

再来说一下经过数组计算一步就得到经过 Attention 计算后就可以得到所有的输出。
上面已经说到如何使用输入得到 Q , < K , V > Q, <K, V> Q,<K,V> ,这三个都是数组,利用数组乘法可以得到 X 经过 Attention 计算,得到新的考虑到所有词的输出 Z 。
Transformer 中还引入了一个缩放因子 d k \sqrt d_k dk , d k d_k dk 为降维后的维度 64。目的是为了避免点乘导致结果过大,进入 softmax 函数的饱和域,导致梯度消失。
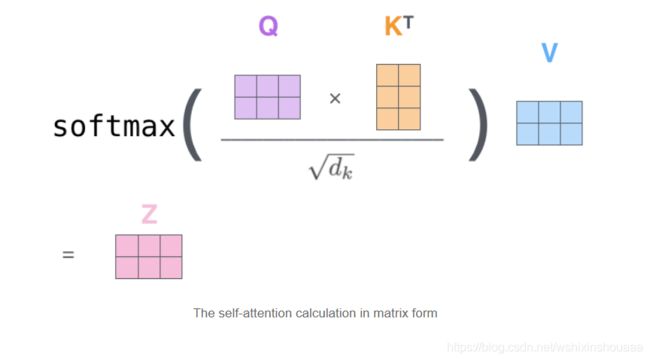
四、Self-Attention 总结
输入中的每一个词与所有的词都进行了相似度计算,得到一个相似概率,经过累加,相当于把所有词对于当前词的重要性都考虑在内。但是,最重要的一点是,没有像 RNN 一样考虑到句子的顺序,所以 Attention 只是相当于计算了词与词的相似度。不过,Transformer 为了解决这个问题,添加了 Position Embedding 。
Multi-Head Attention
一、Multi-Head Attention 结构图:

二、 Multi-Head Attention 计算公式:

三、分解结构图和计算公式
Multi-Head Attention 本质上还是 Self-Attention,只不过引入了多个初始化不同的 W i Q , W i K , W i V W_i^{Q},W_i^{K},W_i^{V} WiQ,WiK,WiV ,从而得到不同的 Q i Q_i Qi, K i K_i Ki, V i V_i Vi 。
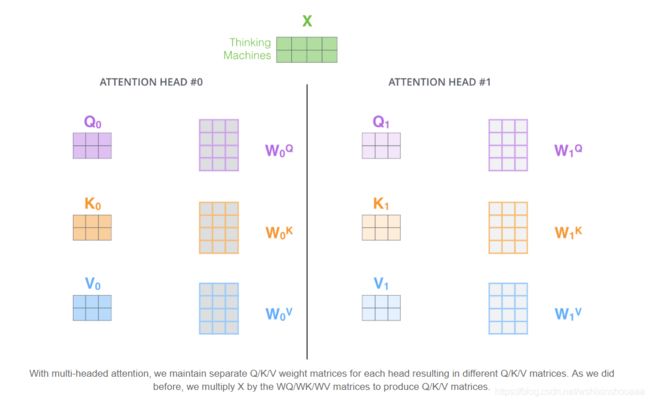
Transformer 中分别计算了八次,得到八个 Z i Z_i Zi 。
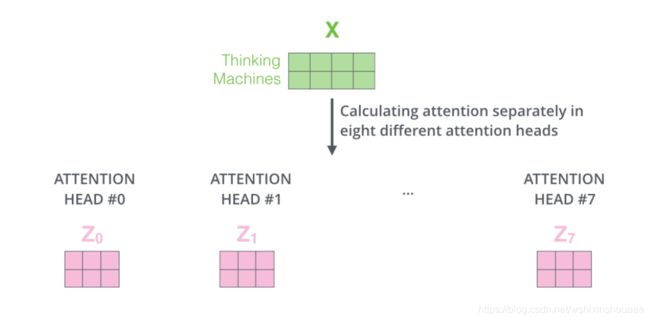
将所有经过 Self-Attention 计算后得到的 Z i Z_i Zi 拼接到一块,然后乘以权重数组 W O W^O WO ,作为下一个子层:前向神经网络 FFNN 的输入。

现在再看一下结构图就很好理解了。
Positional Encoding
Self Attention 机制虽然考虑到了整个句子中所有的词对每一个词的影响,但是忽略了词的位置信息,并没有像 RNN 一样按时序编码,这样就丢失了词与词之间的距离关系。比如 “我 爱 中国” 和 “中国 爱 我” 经过注意力建模出来的结果,每个词对应的表征是相同的。
所以 Transformer 模型添加了一种根据公式计算出来的位置编码,将词向量和位置向量相加作为考虑到了顺序的新 Embedding:
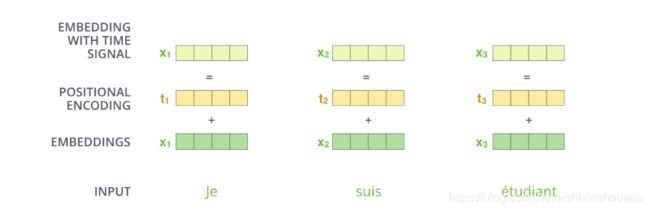
为什么要这么计算位置编码我也没看懂,先将参考的文章放在这里:

Eecoder
前面说到,Encoder 由六个相同的层堆叠组成。每个层中又包含两个子层:Multi-Head Attention 和 Feed Forward。每个子层后由残差连接一个 Layer Normalization 。假设输入只有两个,看一下 Encoder 第一层的结构:

第一个子层 Multi-Head Attention 已经说过,接下来看一下第二个子层 Feed-Forward Networks 和两个中间操作: residual connection 和 layer normalization。
Feed-Forward Networks:
全连接前馈神经网络,对输入进行两次线性变换,其中一次包括 ReLU 激活函数,计算公式如下所示,
F F N ( x ) = max ( 0 , x W 1 + b 1 ) W 2 + b 2 FFN(x)=\max (0, x W_{1}+b_{1}) W_{2}+b_{2} FFN(x)=max(0,xW1+b1)W2+b2
Residual Connection:
使用残差连接更好的避免梯度消失问题。
Layer Normalization:
对输出做归一化处理,加快模型收敛。
具体结构图如下:
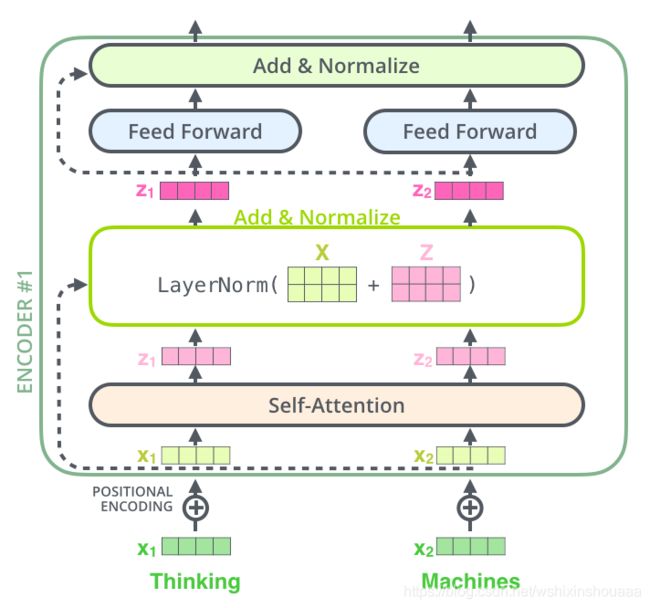
最后将剩下的五层重复第一层的操作,每次把上一层的输出作为下一层的输入。
Decoder
Decoder 和 Encoder 有两个不同点:
-
Decoder 的第二层:Multi-Head Attention 的组成单位不是 Self Attention,而是 Soft Attention。参与计算的 K K K, V V V 是 Encoder 部分最后一层的输出,而不是 Decoder 中前一层的输出。
-
Decoder 的第一层是 Masked Multi-Head Attention,这一层是由八个 Self Attention 堆叠组成。与 Encoder 的 Self Attention 层计算方法不同的是,它是按时间顺序计算的。比如训练到 target sentence 中的第二个词时,它会把后面所有的词设置成
-inf掩盖住确保预测第 i i i 个词时只参考了前面所有位置的词。
Summary
以 RNN 结构为主的 Encoder 模型是按照输入顺序进行建模,考虑到了时序性。但是随着句子的增长,会出现梯度的问题。虽然后来有了 LSTM、GRU 这种门控 RNN 的改善,但是还是会受限于句子长度。同时还有一个问题是 RNN 结构需要并行计算,花费时间长。

以 CNN 结构为主的 Encoder 模型也是按照顺序对输入进行建模,每次可以并行的建模感受野内词的信息,但是受限于长距离内的词若获取相互的信息,则需要更深层的 CNN 单元。
以 Self-Attention 结构为主的 Encoder 模型则综合了 RNN 和 CNN 的优点,既考虑到了输入中所有词之间的相互信息,同时还可以并行计算。不过却没有很好的考虑词的位置信息。

Reference
Attention is All You Need
The Illustrated Transformer
The Annotated Transformer
《Attention is All You Need》浅读
The Annotated Transformer
《Attention is All You Need》浅读
“变形金刚”为何强大:从模型到代码全面解析Google Tensor2Tensor系统