过拟合 欠拟合 多项式回归模型 酶活性预测实战task
过拟合 欠拟合
酶活性预测实战task:
基于T-R-train.csv数据,建立线性回归模型,计算其在T-R-test.csv数据上的r2分数,可视化模型预测结果 加入多项式特征(2次、5次),建立回归模型 计算多项式回归模型对测试数据进行预测的r2分数,判断哪个模型预测更准确 可视化多项式回归模型数据预测结果,判断哪个模型预测更准确
import pandas as pd
import numpy as np
data_train = pd.read_csv('T-R-train.csv')
data_train #数据预览

#define X_train and y_train
X_train = data_train.loc[:,'T']
y_train = data_train.loc[:,'rate']
#可视化数据
%matplotlib inline
from matplotlib import pyplot as plt
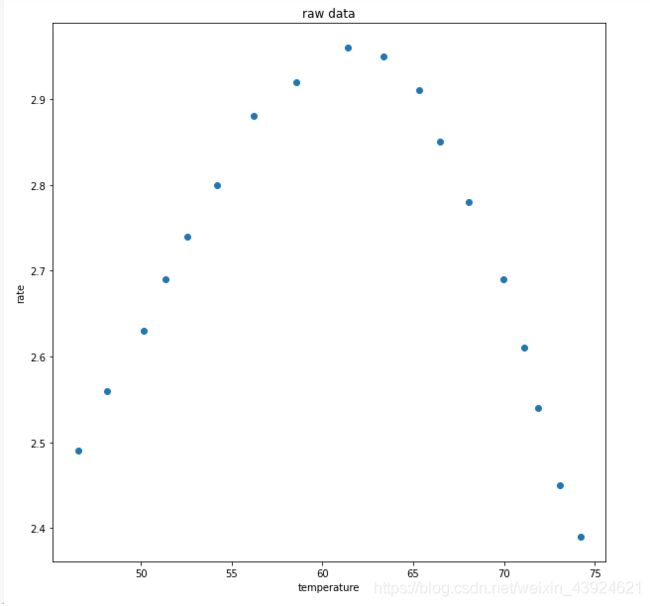
fig1 = plt.figure(figsize=(10,10))
plt.scatter(X_train,y_train)
plt.title('raw data')
plt.xlabel('temperature')
plt.ylabel('rate')
plt.show()
print(type(X_train))
#将X_train转换为一维数组(若不转换会因为维度问题而无法建立下面的线性回归模型)
X_train = np.array(X_train).reshape(-1,1)
print(type(X_train))
#建立线性回归模型并对该模型进行预测
from sklearn.linear_model import LinearRegression
lr1 = LinearRegression()
lr1.fit(X_train,y_train)
#加载测试数据
data_test = pd.read_csv('T-R-test.csv')
X_test = data_test.loc[:,'T']
y_test = data_test.loc[:,'rate']
data_test

#这里测试数据也要转换成一维numpy数组
X_test = np.array(X_test).reshape(-1,1)
#make prediction on the training and testing data
y_train_predict = lr1.predict(X_train)
y_test_predict = lr1.predict(X_test)
from sklearn.metrics import r2_score
r2_train = r2_score(y_train,y_train_predict)
r2_test = r2_score(y_test,y_test_predict)
print('training r2:',r2_train)
print('test r2:',r2_test)

#生成新数据
X_range = np.linspace(40,90,300).reshape(-1,1)#新数据X的范围是40-90,然后共有300个点
y_range_predict = lr1.predict(X_range)
#可视化数据
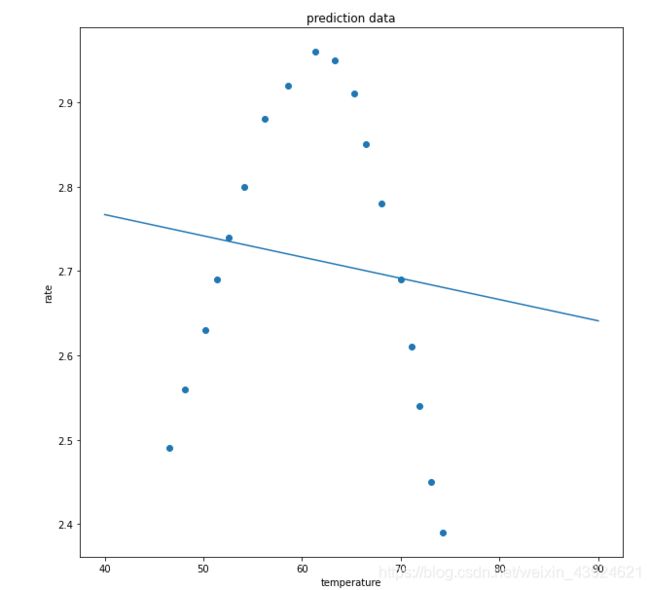
fig2 = plt.figure(figsize=(10,10))
plt.plot(X_range,y_range_predict)
plt.scatter(X_train,y_train)
plt.title('prediction data')
plt.xlabel('temperature')
plt.ylabel('rate')
plt.show()
多项式模型
#多项式模型
#加入多项式特征
from sklearn.preprocessing import PolynomialFeatures
poly2 = PolynomialFeatures(degree=2)#这里degree=2代表的是2次,相应的degree=3代表的就是3次,以此类推
X_2_train = poly2.fit_transform(X_train) #将原来的数据进行转换
X_2_test = poly2.fit_transform(X_test)
poly5 = PolynomialFeatures(degree=5)
X_5_train = poly5.fit_transform(X_train)
X_5_test = poly5.fit_transform(X_test)
print(X_2_train.shape)
print(X_5_train.shape)
#训练以及评估模型
lr2 = LinearRegression()
lr2.fit(X_2_train,y_train)
y_2_train_predict = lr2.predict(X_2_train)
y_2_test_predict = lr2.predict(X_2_test)
r2_2_train = r2_score(y_train,y_2_train_predict)
r2_2_test = r2_score(y_test,y_2_test_predict)
lr5 = LinearRegression()
lr5.fit(X_5_train,y_train)
y_5_train_predict = lr5.predict(X_5_train)
y_5_test_predict = lr5.predict(X_5_test)
r2_5_train = r2_score(y_test,y_5_test_predict)
r2_5_test = r2_score(y_test,y_5_test_predict)
print('training r2_2:',r2_2_train)
print('test r2_2:',r2_2_test)
print('training r2_5:',r2_5_train)
print('test r2_5:',r2_5_test)
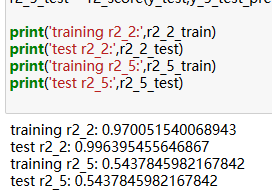
2次的有0.9 5次的却是0.5
#生成新数据
X_2_range = np.linspace(40,90,300).reshape(-1,1)
X_2_range = poly2.transform(X_2_range)
y_2_range_predict = lr2.predict(X_2_range)
X_5_range = np.linspace(40,90,300).reshape(-1,1)
X_5_range = poly5.transform(X_5_range)
y_5_range_predict = lr5.predict(X_5_range)
#可视化数据
fig3 = plt.figure(figsize=(10,10))
plt.plot(X_range,y_2_range_predict)#这里画图用X_range是因为X_2_range和X_5_range的维度过高,无法将图形展示出来。
plt.scatter(X_train,y_train)
plt.scatter(X_test,y_test)
plt.title('polynomial prediction result (2)')
plt.xlabel('temperature')
plt.ylabel('rate')
plt.show()

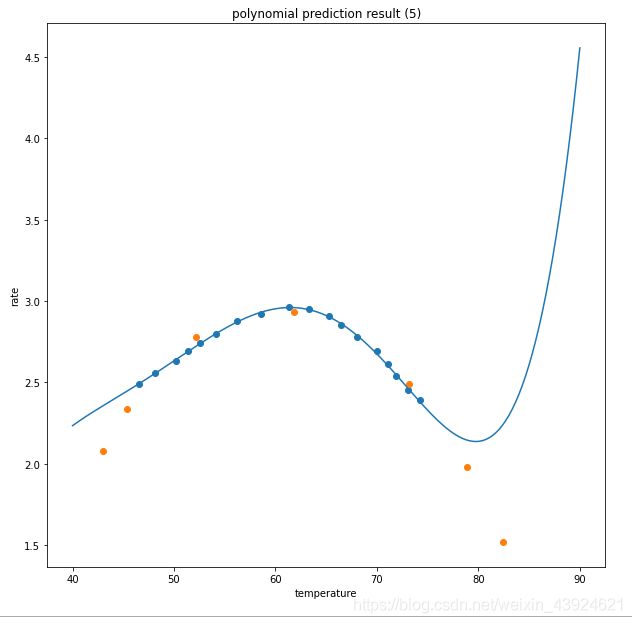
fig4 = plt.figure(figsize=(10,10))
plt.plot(X_range,y_5_range_predict)
plt.scatter(X_train,y_train)
plt.scatter(X_test,y_test)
plt.title('polynomial prediction result (5)')
plt.xlabel('temperature')
plt.ylabel('rate')
plt.show()
参考: 机器学习之——过拟合欠拟合(实战) https://blog.csdn.net/weixin_46344368/article/details/106739989