YOLOv5简易使用笔记
YOLOv5简易使用笔记
前言:
这篇博客只是简单记录下YOLOv5的使用方式,并不会详细介绍代码含义之类的。
更多文章:博客地址
环境:
-
YOLOv5
-
Python 3.8.1
YOLOv5目录介绍
从Github上下载解压好最新的YOLOv5文件后的目录如下图
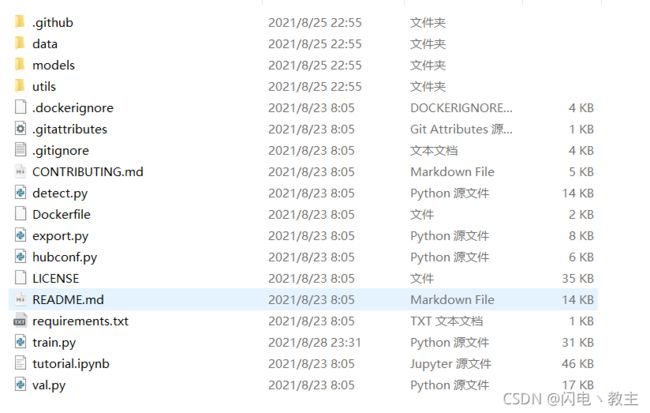
data文件夹里面放着yaml文件,就是数据集的一些配置,是比较重要的,在训练自己数据集的时候会用到这个文件夹。
model文件夹里面放着一些官方的参数模型,里面有4个yaml文件分别对应着不同的模型参数,在自己训练的时候会用到这4个文件。
detect.py这个是用来测试模型效果的。
train.py这个是用来训练自己模型的。
自己进行训练或检测模型后还会多一个run文件夹,这个里面会存放检测模型的效果和训练的模型。
train.py 介绍
首先介绍一下train.py。我们自己可以使用这个py文件来训练自己的模型。
其中需要了解的是parse_opt函数,这个是重点。
def parse_opt(known=False):
parser = argparse.ArgumentParser()
# 模型选择 不填表示从头开始训练 也可以指定模型进行训练
parser.add_argument('--weights', type=str, default='', help='initial weights path')
# 配置模型
parser.add_argument('--cfg', type=str, default='models/yolov5s.yaml', help='model.yaml path')
# 指定训练数据集
parser.add_argument('--data', type=str, default='data/mytrain.yaml', help='dataset.yaml path')
# 超参数
parser.add_argument('--hyp', type=str, default='data/hyps/hyp.scratch.yaml', help='hyperparameters path')
# 迭代次数 500到1000次
parser.add_argument('--epochs', type=int, default=300)
# 一次对多少数据进行训练 数值越大对显卡要求越高了。
parser.add_argument('--batch-size', type=int, default=16, help='total batch size for all GPUs')
# 图片缩放尺寸
parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='train, val image size (pixels)')
parser.add_argument('--rect', action='store_true', help='rectangular training')
# 可以修改这个参数来在以前的模型基础上训练 但是需要原来的路径和文件
parser.add_argument('--resume', nargs='?', const=True, default="runs/train/exp/weights/last.pt", help='resume most recent training')
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
parser.add_argument('--noval', action='store_true', help='only validate final epoch')
parser.add_argument('--noautoanchor', action='store_true', help='disable autoanchor check')
# 调优方式
parser.add_argument('--evolve', type=int, nargs='?', const=300, help='evolve hyperparameters for x generations')
parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
parser.add_argument('--cache', type=str, nargs='?', const='ram', help='--cache images in "ram" (default) or "disk"')
parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class')
parser.add_argument('--adam', action='store_true', help='use torch.optim.Adam() optimizer')
parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
parser.add_argument('--workers', type=int, default=8, help='maximum number of dataloader workers')
parser.add_argument('--project', default='runs/train', help='save to project/name')
parser.add_argument('--entity', default=None, help='W&B entity')
parser.add_argument('--name', default='exp', help='save to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--quad', action='store_true', help='quad dataloader')
# 学习速率
parser.add_argument('--linear-lr', action='store_true', help='linear LR')
parser.add_argument('--label-smoothing', type=float, default=0.0, help='Label smoothing epsilon')
parser.add_argument('--upload_dataset', action='store_true', help='Upload dataset as W&B artifact table')
parser.add_argument('--bbox_interval', type=int, default=-1, help='Set bounding-box image logging interval for W&B')
parser.add_argument('--save_period', type=int, default=-1, help='Log model after every "save_period" epoch')
parser.add_argument('--artifact_alias', type=str, default="latest", help='version of dataset artifact to be used')
parser.add_argument('--local_rank', type=int, default=-1, help='DDP parameter, do not modify')
parser.add_argument('--freeze', type=int, default=0, help='Number of layers to freeze. backbone=10, all=24')
opt = parser.parse_known_args()[0] if known else parser.parse_args()
return opt
--weights:这个参数是填写模型的。在default后面可以填写模型路径,下次训练就是在这个模型的基础上训练的。不过一般都是不填写,让它重新训练。
--cfg:这个参数是用来选择模型参数的。一般是使用官方的,就是选择models文件夹下那4个文件中的一个。这4个文件每个特点都不同,具体差异可以去Github上看详细介绍。一般都是使用yolov5s.yaml,因为这个又小又快很适合完成小项目。
--data:这个参数是用来指定数据集参数的。就是使用data文件夹里面的文件,但要使用的文件是自己定义的,这个地方需要注意。
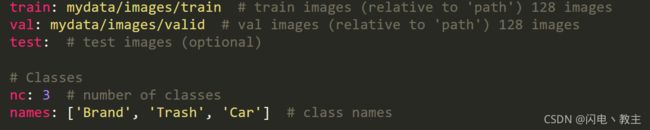
train后面填写训练集路径
val后面填写验证集路径
test后面填写测试集路径
nc后面填写种类数量
names后面填写对应的类型名称
--hyp:这个参数是超参数。默认就行,不用改。
--epochs:这个参数设置迭代次数。默认值为300,就是训练总次数。数值越高对显卡要求就越高。一般默认或者提高到500-1000.
--batch-size:每个轮次下图片训练的批次大小。同样对显卡的配置有要求。一般都是默认。
--imgsz:输入图像的分辨率大小,注意这里是训练和mAP测试的图像尺寸,而不是一个图像的宽高。一般默认。
--resume:这个参数是设置是否从上次一次没训练完的地方继续训练。但要求保留原文件。因为训练过程中会在run文件夹下生成对应的训练文件目录,这个参数要求这个训练文件目录还存在。
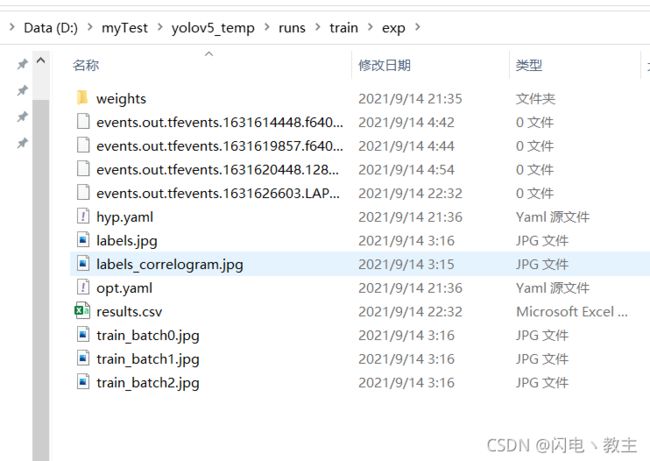
目录大概如上图。使用方式就是在default后面填写weights文件夹里面的last.pt路径。例如:default=“runs/train/exp/weights/last.pt”(也可以写绝对路径),不使用的话就填False。
后面还有很多参数,就不说了,我认为比较常用的就这些。
detect.py 介绍
这个文件是用来检测模型效果的。
其中需要了解的是parse_opt函数。
def parse_opt():
parser = argparse.ArgumentParser()
# 权重 在这里可以选择模型
parser.add_argument('--weights', nargs='+', type=str, default='mymodels/best.pt', help='model.pt path(s)')
# 给模型指定检测目录 可以是文件夹下的所有图片、单个图片、本地视频、youtube视频链接、传输协议(视频推流?)
# default='0' 开启摄像头
parser.add_argument('--source', type=str, default='D:\\myTest\\yolov5_temp\\mydata\\videos\\2.mp4', help='file/dir/URL/glob, 0 for webcam')
# 检测过程中的图片大小
parser.add_argument('--imgsz', '--img', '--img-size', nargs='+', type=int, default=[640], help='inference size h,w')
# 置信度 大于这个数值就认为目标检测成功
parser.add_argument('--conf-thres', type=float, default=0.25, help='confidence threshold')
# 交并比 交集面积/并集面积 大于设定阈值则选择其中一个 小于设定阈值则都选择
parser.add_argument('--iou-thres', type=float, default=0.45, help='NMS IoU threshold')
parser.add_argument('--max-det', type=int, default=1000, help='maximum detections per image')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
# 实时显示结果 在命令行运行的时候指定参数 python detect.py --view-img
parser.add_argument('--view-img', action='store_true', help='show results')
# 保存标注信息
parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
# 保存置信度
parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
parser.add_argument('--save-crop', action='store_true', help='save cropped prediction boxes')
parser.add_argument('--nosave', action='store_true', help='do not save images/videos')
# 过滤不要的类型 只保留需要的类别
parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --class 0, or --class 0 2 3')
# 增强检测
parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')
# 增强检测
parser.add_argument('--augment', action='store_true', help='augmented inference')
parser.add_argument('--visualize', action='store_true', help='visualize features')
parser.add_argument('--update', action='store_true', help='update all models')
# 保存结果
parser.add_argument('--project', default='runs/detect', help='save results to project/name')
# 保存名字
parser.add_argument('--name', default='exp', help='save results to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--line-thickness', default=3, type=int, help='bounding box thickness (pixels)')
parser.add_argument('--hide-labels', default=False, action='store_true', help='hide labels')
parser.add_argument('--hide-conf', default=False, action='store_true', help='hide confidences')
parser.add_argument('--half', action='store_true', help='use FP16 half-precision inference')
opt = parser.parse_args()
opt.imgsz *= 2 if len(opt.imgsz) == 1 else 1 # expand
return opt
--weights:这个参数是用来选择测试的模型。
--source:这个参数是用来选择测试文件目录。可以是单个图片、视频或者文件夹等。
--imgsz:测试中图片大小。默认就行。
--conf-thres:置信度。大于这个数值就认为目标检测成功。可以根据实际情况调整。
--iou-thres:交并比。根据实际情况调整。
--view-img:一边检测一边输出效果。
用法是
python detect.py --view-img
这些参数都可以使用这种方式来配置。
其他的参数不多说。
最后的输出结果在run文件夹下。
数据集制作—图片标注
一种是网页在线标注。网址是:Make Sense 这个怎么使用就不说了,因为我自己不用这个网站标注。
一种是使用labelimg标注。
使用下面的命令安装
pip install labelImg #直接命令行输入
之后在命令行直接输入labelimg就可以打开软件了。
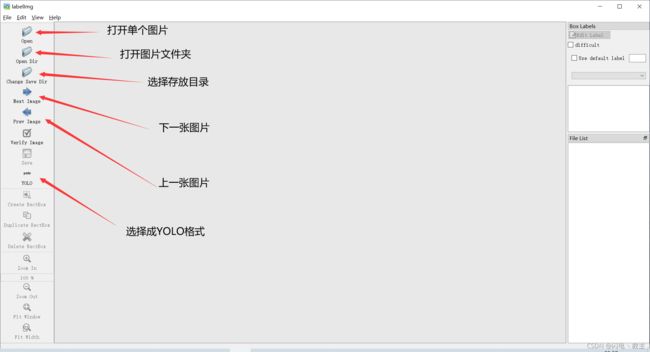
软件有关介绍如上图。
使用方式:
先选择图片目录,再选择输出的保存目录,最后选择保存格式为yolo。
在图片上按下w键开始框选矩形区域,用这个矩形选中要检测的目标,单击鼠标左键确定、首次使用会让你输入标签,你就输入你想填的标签,再点击OK,就行了。后面再框选的话可以选择之前已经有的标签就不用再打字了。
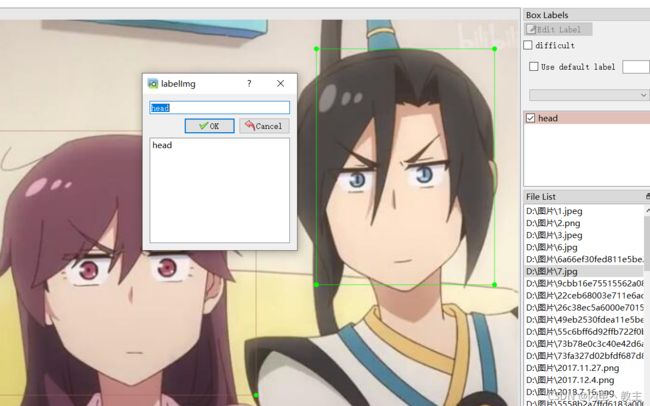
标注完一张图片后要记得保存,快捷键ctrl+s。之后再切换到下一张图片进行标注就行了。
标注一张图片就会生成一个txt文件,这个txt文件就是标注信息,后面自己训练的时候会用到。
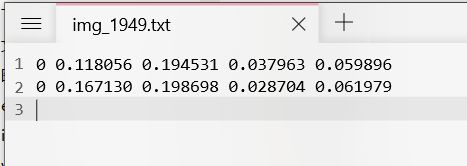
这个就是txt文件内容,最开头的0表示标签类型,也就是对应的标签序号。
还会有个classes文件,这个里面存放着标签类型和顺序。
标注是个技术活也是劳力活。因为一般情况下一个模型至少要100或者200多张图片才可以,每张图片都要标的准确不然最后训练的效果会受到影响。
自己训练模型—本地训练
首先要准备好自己要训练的数据集,至少要有个几百张吧,然后分成训练集和验证集,数量大概5:1就可以。如果图片数量少的话就不要加验证集了。(不仅仅图片要分,标签信息也要对应着分。)
-
在目录新建一个文件夹用于存放自己训练的数据集。

该文件夹下必须包含这两个目录。第一个存放图片,第二个存放标签。(这个标签就是标注后生成的txt文件)
-
在images下新建文件夹,表示训练集、验证集、测试集(没有验证集或者测试集可以不用建),然后把准备好的训练集、验证集或者测试集图片放入对应的文件夹里面就行。文件夹名字应该没有要求,一般都是训练集–train,验证集–val,测试集–test。
-
在labels下新建文件夹,表示训练集、验证集、测试集(没有验证集或者测试集可以不用建),这个地方要与images对应起来。然后把标签信息文件对应放入文件夹就行。
-
打开data文件夹,在这里新建一个自己的yaml文件。
例如:
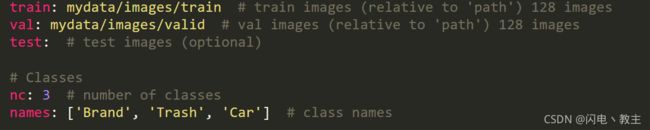
**train**后面填写训练集路径 val后面填写验证集路径
test后面填写测试集路径
nc后面填写种类数量
names后面填写对应的类型名称
按照这样填写然后保存就行。
-
打开train.py。根据自己需要调整一下参数。
重点注意:
--data参数要填写自己刚才配置的yaml文件 -
运行train.py就可以了。如果要GPU训练的话还需要配置cuda,这个方面就自行查找资料吧。
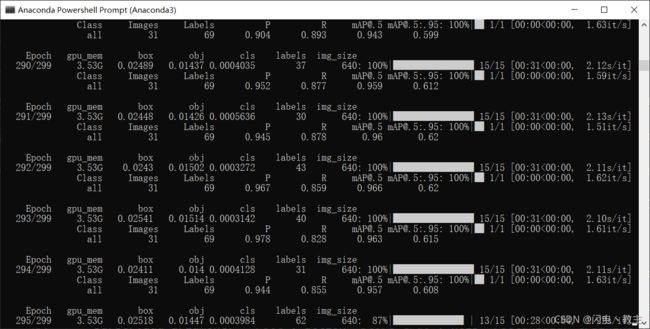
训练过程差不多就是这样。
训练过程中会在run文件夹下生成对应的文件。在对应的训练中,weights文件夹下的best.pt表示训练过程中最好的模型,last.pt表示最后一次训练的模型。
自己训练模型—谷歌免费GPU训练
以后有空再填坑。懂的都懂。
(其实这个也就那样,谷歌会给你限流,用一会就不能用了。懂的都懂。)
自己测试模型效果
这个比较简单。就按照之前介绍detect.py里面的参数填写最后运行就行。但要主要路径不要出现中文,不然可能会报错。
最后效果会生成在run文件夹下,如果测试的是视频那最终就是生成视频,如果是图片就会生成图片。
(gif太大了,传不上来,效果可以去我自己的博客网站看。)
这个是我自己随便搞得一个,视频效果就是这样。

图片大概就这样。
其他
# Write results
for *xyxy, conf, cls in reversed(det):
# 标出目标中心点坐标
# c1, c2 = (int(xyxy[0]), int(xyxy[1])), (int(xyxy[2]), int(xyxy[3]))
# w = c2[0] - c1[0]
# h = c1[1] - c2[1]
# cv2.circle(im0, (int(c1[0] + w / 2), int(c1[1] - h / 2)), 1, (0, 255, 0), 2)
# 根据cls判断目标类型 names[int(cls)] 这个类型与标注对应
# print("\n" + "class:" + str(int(cls)) + "\n")
if save_txt: # Write to file
xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # normalized xywh
line = (cls, *xywh, conf) if save_conf else (cls, *xywh) # label format
with open(txt_path + '.txt', 'a') as f:
f.write(('%g ' * len(line)).rstrip() % line + '\n')
if save_img or save_crop or view_img: # Add bbox to image
c = int(cls) # integer class
label = None if hide_labels else (names[c] if hide_conf else f'{names[c]} {conf:.2f}')
im0 = plot_one_box(xyxy, im0, label=label, color=colors(c, True), line_width=line_thickness)
if save_crop:
save_one_box(xyxy, imc, file=save_dir / 'crops' / names[c] / f'{p.stem}.jpg', BGR=True)