【图像分类】基于yolov5的钢板表面缺陷分类(附代码和数据集)
写在前面:
首先感谢兄弟们的订阅,让我有创作的动力,在创作过程我会尽最大能力,保证作品的质量,如果有问题,可以私信我,让我们携手共进,共创辉煌。
Hello,大家好,我是augustqi。
今天给大家分享一个图像分类项目:基于yolov5的钢板表面缺陷分类(附代码和数据集),在之前的文章中,我们使用yolov7算法对钢板表面缺陷进行检测,属于目标检测范畴,鉴于yolov5-6.2和yolov5-7.0版本中增加了图像分类功能,我们尝试使用yolov5做一个图像分类任务,使用的是钢板表面缺陷数据集。
钢板表面缺陷检测文章回顾:
【表面缺陷检测】基于yolov7的钢板表面缺陷检测(Ubuntu系统)
【表面缺陷检测】基于yolov7的钢板表面缺陷检测(附代码)
本项目也是从零开始制作自己的数据集,学会如何使用yolov5训练图像分类模型的保姆级教程,多的不说,少的不唠,下面我们一起来学习一下吧。
以下内容,完全是我根据参考资料和个人理解撰写出来的,不存在滥用原创的问题。

1. 引言
从事深度学习行业的都知道,yolov5是一个很优秀的目标检测框架,代码已开源至github,截止到2023年1月14日,获得了34.5k Star,12.5k Fork,妥妥的人类高质量项目。项目也在持续更新,并不断完善和增加了新的功能,例如在yolov5-6.2和yolov5-7.0版本中增加了图像分类功能,yolov5-7.0版本中增加了图像分割功能。
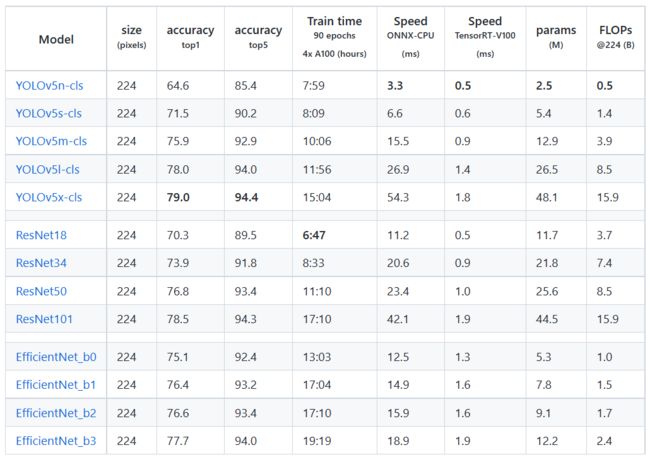
资料显示,官方使用4张A100显卡,在ImageNet数据集上训练了90个epoch,得到了YOLOv5-cls分类模型,同时训练了ResNet和EfficientNet模型进行比较,YOLOv5-cls分类模型取得了不错的结果。
2. 背景
图像分类任务是计算机视觉领域的核心任务之一,其目标就是根据图像信息中所反映的不同特征,将不同类别的图像区分开来。钢厂在生产钢板的时候,由于工艺或者现场因素原因,有的钢板表面会产生缺陷,通过对钢板表面缺陷类别进行分类和统计,从而分析缺陷产生的原因,对进一步改善工艺,降低次品率有很大的帮助。
使用人工对每天生产的钢板进行缺陷检测和分类,不仅费时费力,而且很容易漏检和错检。基于计算机视觉的方法对图像进行分类现在已经很成熟了,目前比较主流的图像分类网络有ResNet、DenseNet、EfficientNet等。YOLOv5是目标检测方向的一个主流框架,但yolov5-6.2版本增加了图像分类功能,从官方公布的实验结果来看,取得了不错的效果,本项目首次基于yolov5训练钢板表面缺陷分类模型。
3. 数据
国内外的工业界和学术界目前开源了几个钢板表面缺陷数据集,说实话,部分数据集的中图片的数量和质量还是有待提高的,但是想一想整理并开源一个数据集耗费大量的人力和物力,成本是巨大的,而且这些数据都是商业数据,也是保密的,能够免费使用目前开源的数据已经很幸运了,且用且珍惜吧。其实本人也参与过钢板表面缺陷检测项目,深入钢厂在钢板生产现场收集了某个钢种的一些钢板表面缺陷图片,也和现场业务员进行沟通,对缺陷图片进行了标注,整理了一份包含1600张缺陷图片的数据集,总共4类缺陷,每类缺陷400张图片,但是这是商业数据,也是保密数据,无法公开。其实,我很想继续把这个数据集进行扩充,收集更多的缺陷图片,增加更多的缺陷类别,当有一天这个数据成果公开后,可以给工业界和学术界带来更多的图像分类、目标检测和图像分割研究成果,希望这一天早日到来吧。
本项目中使用的图像分类数据集,是东北大学带钢表面缺陷检测数据集,这个数据集在之前的“【表面缺陷检测】表面缺陷检测数据集汇总”介绍过,数据集中包含夹杂、划痕、压入氧化皮、裂纹、麻点和斑块6种缺陷,每种缺陷300张,图像尺寸为200×200。
| 英文名称 | 中文名称 | 图片数 | 图片尺寸 |
|---|---|---|---|
| crazing | 裂纹 | 300 | 200×200 |
| inclusion | 夹杂 | 300 | 200×200 |
| patches | 斑块 | 300 | 200×200 |
| pitted_surface | 麻点 | 300 | 200×200 |
| rolled-in_scale | 压入氧化皮 | 300 | 200×200 |
| scratches | 划痕 | 300 | 200×200 |

4. 代码
4.1 项目搭建
下载代码,将代码上传到服务器,也可以是使用本地的Windows系统进行训练:
我们只要用到的是classify文件夹下的train.py、val.py和predict.py脚本代码:
train.py:训练脚本
val.py:评估脚本
predict.py:推理脚本
4.2 核心代码
主干网络使用yolov5s、yolov5x、yolov5m、yolov5n、yolov5l:
class ClassificationModel(BaseModel):
# YOLOv5 classification model
def __init__(self, cfg=None, model=None, nc=1000, cutoff=10): # yaml, model, number of classes, cutoff index
super().__init__()
self._from_detection_model(model, nc, cutoff) if model is not None else self._from_yaml(cfg)
def _from_detection_model(self, model, nc=1000, cutoff=10):
# Create a YOLOv5 classification model from a YOLOv5 detection model
if isinstance(model, DetectMultiBackend):
model = model.model # unwrap DetectMultiBackend
model.model = model.model[:cutoff] # backbone
m = model.model[-1] # last layer
ch = m.conv.in_channels if hasattr(m, 'conv') else m.cv1.conv.in_channels # ch into module
c = Classify(ch, nc) # Classify()
c.i, c.f, c.type = m.i, m.f, 'models.common.Classify' # index, from, type
model.model[-1] = c # replace
self.model = model.model
self.stride = model.stride
self.save = []
self.nc = nc
def _from_yaml(self, cfg):
# Create a YOLOv5 classification model from a *.yaml file
self.model = None
class Classify(nn.Module):
# YOLOv5 classification head, i.e. x(b,c1,20,20) to x(b,c2)
def __init__(self, c1, c2, k=1, s=1, p=None, g=1): # ch_in, ch_out, kernel, stride, padding, groups
super().__init__()
c_ = 1280 # efficientnet_b0 size
self.conv = Conv(c1, c_, k, s, autopad(k, p), g)
self.pool = nn.AdaptiveAvgPool2d(1) # to x(b,c_,1,1)
self.drop = nn.Dropout(p=0.0, inplace=True)
self.linear = nn.Linear(c_, c2) # to x(b,c2)
def forward(self, x):
if isinstance(x, list):
x = torch.cat(x, 1)
return self.linear(self.drop(self.pool(self.conv(x)).flatten(1)))
损失函数:
def smartCrossEntropyLoss(label_smoothing=0.0):
# Returns nn.CrossEntropyLoss with label smoothing enabled for torch>=1.10.0
if check_version(torch.__version__, '1.10.0'):
return nn.CrossEntropyLoss(label_smoothing=label_smoothing)
if label_smoothing > 0:
LOGGER.warning(f'WARNING ⚠️ label smoothing {label_smoothing} requires torch>=1.10.0')
return nn.CrossEntropyLoss()
优化器:
def smart_optimizer(model, name='Adam', lr=0.001, momentum=0.9, decay=1e-5):
# YOLOv5 3-param group optimizer: 0) weights with decay, 1) weights no decay, 2) biases no decay
g = [], [], [] # optimizer parameter groups
bn = tuple(v for k, v in nn.__dict__.items() if 'Norm' in k) # normalization layers, i.e. BatchNorm2d()
for v in model.modules():
for p_name, p in v.named_parameters(recurse=0):
if p_name == 'bias': # bias (no decay)
g[2].append(p)
elif p_name == 'weight' and isinstance(v, bn): # weight (no decay)
g[1].append(p)
else:
g[0].append(p) # weight (with decay)
if name == 'Adam':
optimizer = torch.optim.Adam(g[2], lr=lr, betas=(momentum, 0.999)) # adjust beta1 to momentum
elif name == 'AdamW':
optimizer = torch.optim.AdamW(g[2], lr=lr, betas=(momentum, 0.999), weight_decay=0.0)
elif name == 'RMSProp':
optimizer = torch.optim.RMSprop(g[2], lr=lr, momentum=momentum)
elif name == 'SGD':
optimizer = torch.optim.SGD(g[2], lr=lr, momentum=momentum, nesterov=True)
else:
raise NotImplementedError(f'Optimizer {name} not implemented.')
optimizer.add_param_group({'params': g[0], 'weight_decay': decay}) # add g0 with weight_decay
optimizer.add_param_group({'params': g[1], 'weight_decay': 0.0}) # add g1 (BatchNorm2d weights)
LOGGER.info(f"{colorstr('optimizer:')} {type(optimizer).__name__}(lr={lr}) with parameter groups "
f"{len(g[1])} weight(decay=0.0), {len(g[0])} weight(decay={decay}), {len(g[2])} bias")
return optimizer
5. 训练
训练命令:
python classify/train.py --model weights/yolov5s-cls.pt --data data_custom --epochs 100 --batch-size 32 --imgsz 224
开始训练:
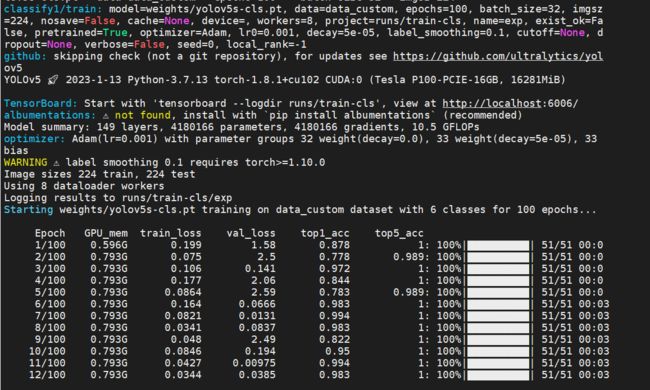
结束训练:
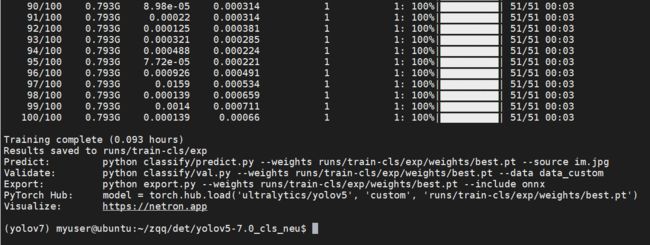
生成的文件:
我使用了一张Tesla P100显卡,训练了100 epoch,仅用了不到6分钟的时间,真的是相当的快,而且top1和top5精度都达到了100%。
6. 评估和推理
6.1 评估
评估代码:
python classify/val.py --weights runs/train-cls/exp/weights/best.pt --data data_custom
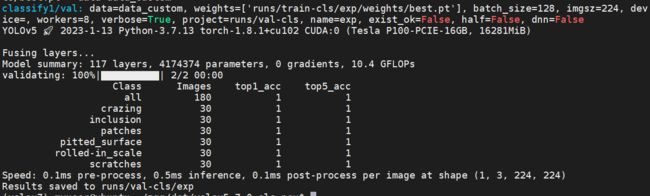
评估结果:
6.2 推理
推理代码:
# 测试im1.jpg
python classify/predict.py --weights runs/train-cls/exp/weights/best.pt --source im1.jpg
# 测试im2.jpg
python classify/predict.py --weights runs/train-cls/exp/weights/best.pt --source im2.jpg
推理结果:


7. 导出
7.1 ONNX
执行命令导出onnx:
python export.py --weights runs/train-cls/exp/weights/best.pt --include onnx
输出:
Detect: python classify/predict.py --weights runs/train-cls/exp/weights/best.onnx
Validate: python classify/val.py --weights runs/train-cls/exp/weights/best.onnx
PyTorch Hub: model = torch.hub.load('ultralytics/yolov5', 'custom', 'runs/train-cls/exp/weights/best.onnx') # WARNING ⚠️ ClassificationModel not yet supported for PyTorch Hub AutoShape inference
Visualize: https://netron.app
我们使用onnx进行模型部署,也可以把它当作中间件进行模型转换,根据项目需求进行选择。
7.2 TensorRT
执行命令导出engine:
python export.py --weights runs/train-cls/exp/weights/best.pt --include engine --device 0
输出:
Detect: python classify/predict.py --weights runs/train-cls/exp/weights/best.engine
Validate: python classify/val.py --weights runs/train-cls/exp/weights/best.engine
PyTorch Hub: model = torch.hub.load('ultralytics/yolov5', 'custom', 'runs/train-cls/exp/weights/best.engine') # WARNING ⚠️ ClassificationModel not yet supported for PyTorch Hub AutoShape inference
Visualize: https://netron.app
我们导出的engine模型,可以使用英伟达的TensorRT框架进行部署,加速模型推理速度。
8. 结论
本次项目基于yolov5对钢板表面缺陷进行分类,从评估指标来看,验证集上准确率很高,取得了很好的结果。模型训练速度也很快,模型导出也很方便和友好。目前,还可以做的工作是使用多GPU对模型进行训练,对导出的模型进行部署。但是,虽然分类精度很高,但是我们不知道缺陷的具体位置,没办法对缺陷进行定位,目前的想法是使用卷积热力图,用于突出图像的类的特定区域,不知道是否可行,还需进一步验证。总后絮叨,yolov5你真强!截止发文前,ultralytics公司目前已将yolov8开源了,yolov8将在江湖上引起腥风血雨。
如果您觉得这篇文章对您有一点点的帮助和启发,希望您关注公众号,并点赞、转发。您可以联系我获取项目中的数据集和代码,数据整理和代码调试不易,公众号运营困难,为了公众号的正常运营,提供有偿指导,感谢您的理解和支持,祝好。
联系方式:公众号底部菜单栏–关于我–与我联系【订阅CSDN专栏的朋友,请加我v,发您数据和代码,不贴出代码和数据集的链接是为了防止爬虫,望理解】
参考资料
[1]https://github.com/ultralytics/yolov5
[2]https://blog.csdn.net/AugustMe/article/details/128111977