论文阅读笔记(1):Deep Animation Video Interpolation in the Wild——野外深度动画视频插值(2021CVPR)
论文名称:Deep Animation Video Interpolation in the Wild
会议:2021CVPR会议
基于深度网络动漫视频插帧
- 摘要
- 一、简介
- 二、相关工作
- 三、ADK-12K数据集
-
- 3.1数据集构建
- 3.2注解
- 四、使用方法
-
- 4.1分段引导匹配
- 4.2循环细流化网络
- 4.3帧整经和合成
- 4.4学习体会
- 五、实验
-
- 5.1对比结果
- 5.2消融研究
- 5.3进一步分析
- 六、总结
- 参考文献

图片1:动画视频插值的经典案例。我们的方法能够正确的估计大运动光流,并恢复内容,然而其他方法无法处理这类运动。
摘要
在动画产业中,动画视频通常是在低帧率的情况下制作的,手绘动画帧的成本高、耗时长。因此,需要开发能够自动插入动画帧之间的计算模型。然而,现有的视频插帧方法无法产生令人满意的动画数据结果。与自然视频相比,动画视频具有两个独特的特征使插帧变得困难:1)动画由线条和光滑的色彩块组成。光滑的区域缺少纹理,就难以估计动画视频的准确动作。2)漫画通过夸张来表现故事。有些动作是非线性的并且非常大。本文首次正式定义并研究了动画视频插帧问题。为了解决上述挑战,我们提出了一个有效的框架AnimeInterp,它通过从粗到细的方式包含两个专用模块。具体来说,1)分段引导匹配(Segment-Guided Matching)通过利用分段一致的色块之间的全局匹配来解决“缺乏纹理”的挑战。2)循环流优化(Recurrent Flow Refinement )通过使用类似变压器的架构进行循环预测,解决“非线性和极大运动”的挑战。为了便于全面训练和评估,我们构建了一个大型动画三元组数据集ATD-12K,其中包含12000个有丰富注释的三元组。大量实验表明,我们的方法优于现有的最优动画视频插帧方法。值得注意的是,AnimeInterp 在野外动画场景中展现出良好的感知质量和鲁棒性。建议的数据集和代码可在此获取:https://github.com/lisiyao21/AnimeInterp/。
一、简介
在动画行业中,动画视频是由专业动画师使用复杂的手绘图和精确的程序进行制作。手动绘制视频的每一帧都需要花费大量的时间,从而导致过高成本。在实际操作中,动画制作者通常会将一幅画复制两三遍,以此降低成本,这样会导致动画视频实际帧率偏低。因此,非常必要开发计算机算法来自动插入中间动画帧。
最近几年,视频插值在自然视频方面取得了较大的进展。然而,在动画中,现有的视频插值方法还不能产生满意的中间帧。如图1所示电影《追逐失落声音的孩子》中的一个例子,由于不正确的运动估计,当前最先进的方法无法生成一件完整的行李,如下图左下角所示。这里的挑战源于动画视频的两个独特特性:1)首先,卡通图像由清晰的草图和线条组成,将图像分割成平滑的色块。在一个片段中的像素是相似的,产生的纹理不足以匹配两帧之间的相应图像,因此增加了预测准确运动的难度。2)其次,卡通动画通过使用夸张的表达方式追求艺术效果,导致相邻两帧之间非线性和极大运动。图二(a)和(b)描绘了两个典型案例,分别说明了这些挑战。由于上述困难,动画中的视频插帧仍然是一项具有挑战性的任务。

图 2:动画视频插值的两个挑战。 (a) 分段平滑动画缺乏纹理。 (b) 非线性和极大的运动。
在这项工作中,我们开发了一种有效且有原则的动画视频插值方法。我们提出了一个有效框AnimeInterp来解决上述两个挑战。AnimeInterp由两个专用模块组成:Segment-Guided Matching (SGM) 模块和 Recurrent Flow Refinement (RFR) 模块,旨在以粗到细的方式预测动画的准确运动。更具体的说,提出的SGM模块使用按轮廓分割的颜色块之间的全局语义匹配来计算粗片光流。由于属于一个段的相似像素被看作一个整体,SGM模型能够避免在光滑区域不匹配导致的局部最小值,解决了“缺乏纹理”的问题。为了解决动画中”非线性和极大动作“的挑战,SGM估计的分段流通过名为Recurrent Flow Refinement的类似Transformer的网络进一步增强。如图1所示,我们的方法能够更好的估计大位移下行李箱的流动,并产生完整的中间帧。
构建大型动画三元组数据集ATD-12K,为了便于在卡通视频的插帧方法上面进行综合训练和评估。与其他只有单个图像组成的动画数据集不同的是,ATD-12K数据集包含从30部不同风格的动画电影中选出的12000帧三元组,总长度超过25小时。除了多样性之外,我们的测试集根据运动和遮挡的大小分为三个难度级别。我们还提供有关运动类别的注释以供进一步分析。
这项工作的贡献可以总结如下:1)我们首次正式定义并研究了动画视频插值问题。这个问题对学术界和工业界都具有重要意义。2)我们提出了一种有效的AnimeInterp动画插值框架,具有两个专用模块解决”缺少纹理“和”非线性和极大运动“的挑战。大量实验表明,AnimeInterp在数量和质量方面都优于现有的最先进方法。3)我们构建了一个名为ATD-12K的大型卡通三元组数据集,该数据集具有丰富的内容多样性,代表许多类型的动画,以测试动画视频插值方法。ATD-12K的数据规模和丰富的注释将会为未来动画研究铺平道路。
二、相关工作
视频插值:视频插值在最近几年被广泛研究。在[16]中Meyer等人提出了一种基于相位的视频插帧方案,该方案在具有小位移的视频上表现出色。在[19,20]中,Niklaus等人设计了一个基于内核的框架,通过相邻帧的相应面片进行卷积,对插帧像素进行采样。然而,由于内核大小的限制,基于内核的框架仍然不能处理大型移动。为了解决视频中的大运动,许多研究使用光流进行视频插帧。Liu等人在[15]中预测3D体素流,以对中间帧的输入进行采样。类似的,Jiang等人在[9]建议联合估计双向流和用于多帧插值的遮挡掩模。此外,一些研究致力于改善给定双向流的扭曲和合成[2.1.17.18],并使用高阶运动信息来近似真实视频[33.5]。除了在图像上使用像素外,在视频插帧中还探索了深度特征上的“特征流”[8]。虽然现有的方法在插帧真实世界的视频方面取得了巨大的成功,但他们无法处理动画的大型非线性运动。因此,动画视频插帧仍然没有解决,本文提出了一种基于色块匹配的分段引导匹配模块,提高了流量预测。
动画视觉:在视觉和图像领域,有很多关于处理和增强动画内容的工作,例如:漫画草图简介[24.23],卡通图像矢量化[35.34],动画视频立体化[14],黑白漫画彩色化[22.27.11]。近年来,随着深度学习的兴起,研究者们试图产生有利的动画内容。例如:生成性对抗网络用于生成生动的卡通人物[10.32],样式转换模式用于将真实世界的图像转换为卡通[4,29,3]。然而,由于难以估计帧之间的运动,因此生成动画视频内容仍然是一项具有挑战性的任务。
 图3:ATD-12K的三元样本和数据统计。顶部:训练和测试集中的典型三元组。(a)不同类别的难度级别和动作标签的百分比。(b)在每个图像中计算的评价运动值和标准偏差的直方图。
图3:ATD-12K的三元样本和数据统计。顶部:训练和测试集中的典型三元组。(a)不同类别的难度级别和动作标签的百分比。(b)在每个图像中计算的评价运动值和标准偏差的直方图。
三、ADK-12K数据集
为了便于训练和估计动画视频插值方法,我们构建了命名为ATD-12K的大规模数据集,由10000个动画帧三元组的训练集和2000个三元组的测试集组成,这些数据集是从不同种类的卡通电影中收集的。为了保证数据的客观性和公平性,测试集是从训练集专有的不同来源中采样的。除此之外,为了从多个方面评估视频插值的方法,我们为测试集提供了丰富的注释,包括困难等级、运动的兴趣区域(Rol)和运动类别的标签。ATD-12K的一些典型例子和注释信息如图3所示。
3.1数据集构建
构建ATD-12K数据集的第一步,我们从网上下载大量的动画视频。为了保证ATD-12K数据集的多样性和代表性,从Disney,Hayao, Makoto, Hosoda, Kyoto Animation, 和A1 pictures等多元化制片人制作的30部系列电影中,共收录101个卡通片段,总时长超过 25 小时。采集的视频具有1920×1080或1280×720的高视觉分辨率。其次,我们从收集的视频中提取足够的三元组。在这一步中,我们不仅提取相邻的连续帧到三元组中,还将以一帧或两帧为间隔的帧提取出来,以扩大帧间位移。由于动画帧的绘制可能会重复多次,因此通常会在从一个视频中提取的三元组中采样相似的内容。为了避免我们数据之间的高相似性,过滤掉包含结构相似性(SSIM)大于0.95的两个帧的三元组。同时,SSIM低于0.75的三元组也被删除,以消除我们数据集中的场景转换。然后,我们需要手动检查剩余的131606个三元组以进一步提高质量。被至少两个人标记为合格的三元组将被保留。包含不一致字幕、简单或相似场景或非典型动作的帧将被移除。经过严格的筛选,12000个有代表性的动画三元组将被用来构建我们最终的ATD-12K。
数据统计:为了探索自然视频和卡通视频之间的差距,我们比较了ATD-12K和真实世界数据集Adobe240[26]的运动统计数据,后者通常用作视频插值的评估集。我们估计两个数据集中每个输入对的帧之间的光流,并计算每个流位移的平均值和标准偏差。两个数据集的均值和标准差的归一化直方图如图3所示。他们表明,卡通数据集ATD-12K比真实世界的Adobe240数据集具有更高比例的大型和多样性运动。
3.2注解
难度等级:我们根据每个三元组的平均运动幅度和遮挡面积将ATD-12K测试集分为三个难度等级,即”简单“,”中等“,”困难“。每个等级定义的详细信息,请参考补充文件。不同级别的三元组样本如图3所示。
运动RoIs:动画视频由移动的前景物体和静止的背景场景组成。由于前景人物在视觉上更具有吸引力,这些区域的运动对观众的视觉体验影响更大。为了更好的展示插帧方法对运动区域的性能,我们为每个三元组的第二幅图像(如图3测试集所示)提供一个边界框来描绘运动RoIs;

图4:(a)AnimeInterp的整体流程。将输入I0和I1送入SGM模块,生成粗流,即f0→1和f1→0。然后RFR模块对f0→1和f1→0进行细化。最后的插补结果是借用SoftSplat 的翘曲合成网络产生的。(b)SGM模块内部结构。(c)RFR模块工作流程。
运动标签:我们也提供描述三元组主要运动的标签。我们的运动标签主要分为两类,即:1)一般的运动类型,包括平移、旋转、缩放和变形;2)人物行为包括说话、走路、吃饭、运动、取物等。每个类别中标记的百分比如图3所示。
四、使用方法
我们的框架概述如图4所示。给定输入图像I0和I1,我们首先通过4.1节中提出的SGM模块估计I0和I1之间两个方向上的粗流f0→1和f1→0。然后,我们将粗流设为递归神经网络的初始化,并逐步细化,得到4.2节中的细流f′0→1and f′1→0,并在4.3节中合成最终输出I’1/2。
4.1分段引导匹配
对于经典2D动画,物体通常是用明确的线条勾勒出来的,每个封闭区域都用单一的颜色填充。一帧中运动物体的颜色在大位移的情况下在下一帧中保持稳定,这可以作为寻找合适的颜色块语义匹配的有力线索。在本文中,我们利用这个线索来处理平滑的分段运动,产生粗光流。这个过程如图4(b)所示,我们将在下面详细说明它。
色块分割:借鉴Zhang[35]等人的工作,我们采用拉普拉斯滤波器提取动画帧的轮廓。然后,用trappedball算法[35]填充轮廓,生成色块。这一步之后,我们得到一个分割地图S∈NH×W,其中每个色块的像素都用一个身份标号进行标记。在本节的其余部分,我们将输入I0和I1的分割分别记为S0和S1。S0(i)表示I0的第i个彩色块中的像素点,S1(i)表示I1的像素点。
特征收集:我们将输入I0和I1输入到预先训练的VGG-19模型中,提取relu1_2, relu2_2,relu3_4和relu4_4层的特征。然后,我们通过提出的超像素池将属于某一段的特征集合起来。通过下采样分割图汇集较小尺度的特征,并将其拼接在一起。池化后,每个色块由一个N维特征向量表示,整个图像映射到一个K*N特征矩阵中,其中K为色块的数量,矩阵的每一行表示对应色块的特征。特征矩阵I0和I1分别表示为F0和F1。
色块匹配:现在,我们使用F0和F1估计I0和I1颜色块之间的一致映射。具体来说,我们预测一个正向地图M0→1和一个反向地图M1→0。对于第一帧第i个颜色块,正向映射M0→1(i)表示第二帧最大似然对应块,后向映射从I1到I0表示最大似然对决块。为了量化候选对(i∈S0,j∈S1)的可能性,我们使用F0和F1计算亲和性指标A为:
其中F0~(i,n)=F0(i,n)/∑nF0(i,n)为F0的归一化特征,F1~和F0~相似。这种亲和度测量了所有对的全局相似性。此外,为了避免潜在的异常值,我们还利用了两种约束惩罚,即距离惩罚和尺寸惩罚。首先,我们假设两个相应部分之间的位移不可能过大。距离惩罚定义为两个色块的质心与图像对角线长度的距离之比,公式如下:

其中P0(i)和P1(j)分别表示S0(i)和S0(j)的质心位置。注意这个惩罚只适用于位移大于图像对角线长度15%的匹配。其次,我们建议进行匹配色块的大小应该相似。尺寸惩罚被设计为:

式中| . |为集群像素数。
结合以上各项,得到匹配度矩阵C为:
![]()
其中,λdist和λsize分别设置为0.2和0.05.对于每对(i∈S0,j∈S1=1),C(i,j)表示可能性。因此,对于S0中的第i个色块,S1中最可能匹配的色块就是匹配度最大的色块,反之亦然。这种匹配的映射可以表示为如下所示:

流的产生:在SGM模块最后一步中,我们利用M0→1和M1→0预测密集的双向光流f0→1和f1→0。我们只描述计算f0→1的过程,因为f1→0可以通过反转映射顺序得到。对于匹配的每个色块(i,j),其中j=M0→1(i),我们首先计算质心的位移作为位移基fic=P1(j)-P0(i),然后通过变分优化计算局部变形fid:=(u,v),

在这里,I0i表示掩码I0,其中不属于第i个颜色块的像素被设置为0。I1j与I0i相似。第i块色素的光流为f0→1i=fdi+fci。由于颜色块是不相交的,整个图像的最终流是通过将所有逐片流简单的相加来进行计算的,如f0→1=∑i fi0→1;
为了进一步避免离群值,我们将第i块的流量掩码置为零,如果不满足一致性,即M1→0(M0→1(i))不等于i。此操作防止后续的流细化操作步骤被低置信度匹配所误导。
4.2循环细流化网络
在这节中,我们通过深度循环流细化(RFR)网络将粗糙的光流f0→1和f1→0细化为更精细的视图f’0→1和f’1→0。引入RFR模块有两个主要动机。首先,由于在色块匹配步骤中采用了严格的互一致性约束,非鲁棒对被屏蔽掉,在某些位置留下空流值。RFR能够为这些位置生成有效的流。其次,SGM模块有利于大位移,但对动画视频中非线性和夸张运动的精确变形预测效果较差。在这里,RFR通过细化粗的、分段的流补充了前面的步骤。
受最先进的光流网络RAFT的启发,我们设计了如图4(c)所示的变压器式架构,以不断的细化分段流f0→1。为了简洁而见,我们只说明计算f’0→1的过程。首先,为了进一步避免粗流f0→1中的潜在错误,一个像素级的置信映射g通过一个三层CNN来掩盖不可靠的值,该CNN采用串联的|I1(x+f0→1(x))-I0(x)|,I0和f0→1作为输入。然后,粗流f0→1乘以exp{-g2}作为初始值f(0)0→1,进行下一步细化。接下来,一系列留数{△f(t)0→1}通过卷积GUR学习:

其中corr(.,.)计算的是两个张量之间的相关性,F0和F1是CNN提取的帧特征,F(t)1→0是用光流f(t)0→1从F1进行双线性采样.学习的留数会不断积累,以更新初始化.经过T迭代后的光流细化计算为:
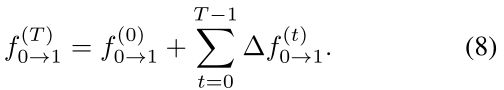
得到的细流f’0→1是最后一次迭代的输出.
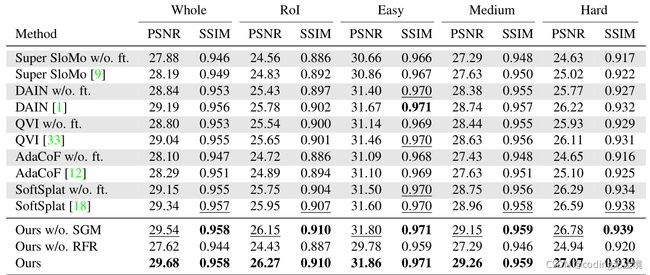
表1:ATD-12K测试集定量结果.最佳值和亚军值分别用粗体和下划线表示.
4.3帧整经和合成
使用f’0→1和f’1→0流产生中间帧,我们采取SoftSplat的飞溅和合成策略.简而言之,利用多尺度CNN从I0和I1中提取一组特征值,然后通过正向偏移到中心位置,将所有特征和输入帧进行散列.例如:I0被分割成I0→1/2公式如下:

最后,将所有扭曲的帧和特征输入到具有三个尺度级别的GridNet中,合成目标帧^I1/2.
4.4学习体会
为了监督所有网络,我们采用预测值I1/2与地面真实值I1/2之间L1和||^I1/2-I1/2||1d 的距离作为训练损失。
我们训练这个网络分为两个阶段:训练阶段和微调阶段。在训练阶段中,我们首先对循环细流(RFR)网络进行预训练,然后确定权值,用以训练在[33]中提出的真实数据集上训练网络的其余部分,训练时间为200纪元.在此阶段,我们不使用SGM模块预测的粗流.学习率初始化为10-4,并在第100和150纪元的时候降低0…1倍。在第二阶段,我们在ATD-12K的训练集上以10-6的学习率对整个系统进行另外50个周期的优化.在微调期间,图像被重新缩放到960540,并随机剪裁到380380,批大小为16.同时,随机翻转图像,并反转三元组数据进行数据增强
五、实验
方法对比:AnimeInterp与五种最先进的方法进行比较,包括Super SloMo[9], DAIN [1], QVI [33], AdaCoF [12] and SoftSplat [18].我们使用DAIN、QVI和AdaCoF的原始实现,和Super SloMo的实现方法。由于SoftSplat没有发布模型,所以我们按照[18]中的描述来实现这个方法,并使用我们提出的模型相同的策略来实现它。
数据集:我们在ATD-12K的训练集中使用4.4节中描述的超参数对这些基线模型进行微调。在我们提出的ATD-12K测试集上分别评估微调前后的模型。
评价指标:我们在每个测试的三元组中使用两个远处的图像作为输入帧,并使用中间的图像作为地面真值。采用预测中间结果与地面真实值之间的PSNR和SSIM[31]作为评价指标。利用3.2节中的注释,我们不仅对整个图像(记为Whole)进行插帧,而且对感兴趣的图区域(记为Rol)进行插帧。同时,我们展现了三个等级(容易、中等和困难)。
5.1对比结果
定量评价:定量结果如表1所示。通过比较,我们提出的模型在所有评价方面都优于现有的方法。与最优比较方法SoftSplat相比,本方法在整体图像评价上的PSNR评分提高了0.34dB。对于一个三元组中显著运动的Rol的评价,我们的方法同样可以达到0.32dB的提升。优于动漫视频包含很多帧都有静态背景,所以对Rol的评价更能准确反映大动作的效果。

图5:ATD-12K测试集的定性结果。每个例子的第一行是重叠的输入帧和相应方法的预测光流,第二行是地面真值和插帧的结果。
定性评价:为了进一步证明我们提出方法的有效性,我们在图5中展示了两个可视化比较案例。在每个例子中,我们展示插帧结果和不同方法的预测光流。在第一个例子中,Mowgli正用一只手伸向一只秃鹫,而他的另外一只手已经放在了秃鹫的翅膀上面。在这种情况下,插帧是非常具有挑战性的,因为男孩手臂的位移是不连续的,而且非常大。此外,男孩双手的局部模式非常相似,导致了光流预测的局部最小值。因此,现有的所有方法都无法准确预测男孩手上的流量值。在这些插帧方法的结果中,移动的手要么消失,要么分裂成两个变形的手。相比之下,我们的方法可以估计更精确的光流,并在中间位置产生一个相对完整的手臂。在第二种情况下,Peter Pan在空中快速滑行,背景移动很大。类似于第一个例子,比较方法估计错误的流动值的字符,因此不能合成一个完整的身体在准确的位置,而我们的方法可以产生整个字符,几乎相同的地面场景,看起来是正确的。
5.2消融研究
定量评价:为了解释AnimeInterp中SGM和RFR模块的有效性,我们评估了提出方法的两个变量,其中SGM模块和RFR模块分别被删除(定义为“Ours w/o. SGM” and “Ours w/o. RFR”)。“w/o.SGM”的变体使用递归细化网络直接预测光流,而不需要全局上下文感知的分段流的引导初始化,然而“w/o.RFR”模型利用SGM预测的分段流对插帧结果进行扭曲和综合。为了进行公平的比较,我们在删除相应模块后重新调整这两个分支。如表1和图6(a)所示,“w/o.SGM”变体的PSNR属性对整体图像的评价降低了0.14dB,而“w/o.RFR”模块的评分极具下降到2.06dB,因为逐片流较粗,而且在相互不一致的色块上包含零值。结果表明提出的SGM模块和RFR模块在我们方法中起着关键作用。为了在不同困难水平上有一个更精确的视图,SGM模块可以在标记为困难的三元组上面提高0.3dB,从26.78dB到27.07dB,但是对于简单等级的评估仅仅提高了0.06dB,表明提出的SGM模块在大动作的视频中更有效提高。

图6:(a)SGM模块的消融研究。展示了PSNR的定量结果。(b)SGM的有效性可视化。在第一行可视化图1中帧0和帧1的色彩分割,在S0和S1中匹配的色块用相同的随机颜色填充。在第二行,展示流量估计和最终插帧结果。(c)用户研究结果。我们的方法在很大程度上面优于其他方法。
定量评价:对于视觉结果的质量,如果去掉SGM模块,我们的方法预测流程就不正确,由于其陷入了局部最小值。例如,在图5的第一个样本中,第一张图片中男孩移动的右手与第二张图片中的左手进行了匹配,空间上更接近,但匹配错误。有趣的是,以分段流作为引导,我们的方法可以避免这种局部最小值,并利用全局上下文信息来估计正确的流量值。SGM影响的细节描述如图6(b)所示。在第一行,我们在图1展示了两个输入帧的色块分割。匹配的色块用相同的随机颜色填充,不符合一致性的色块用白色掩盖。从红色的箱子中可以看出,行李虽然被分割成几块,但是每一段都是正确匹配的。在图6(b)第二行中,我们直观地比较了有和没有SGM的光流和插帧结果。尽管分段的f1→0是粗光流,可以很好的指导求精网络准确预测值f’1→0,形成一个完整的行李箱。总之,所提出的SGM模块通过全局上下文匹配显著改善了局部不连续运动的性能。
5.3进一步分析
难度等级和运动RoIs的影响:从表1可以看出,难度等级对表现有很大影响。当难度增加一级时,各种方法的PSNR分数下降超过2dB。对于不是解决动画中“缺少纹理”和“非线性运动和极大运动”挑战的方法来说,下降更明显。例如:DAIN在“简单”等级获得了第三高分(31.67dB),与我们提出的方法(31.67dB)相差比不到0.2dB,但是在“中等”(28.74dB vs. 29.26dB)和“困难”(26.22dB vs. 27.07dB)水平上的表现相比下降更多。同时,各种方法对RoIs的性能远低于对整体图像的性能。由于RoI区域是动漫视频的重要组成部分,对视觉体验有很大的影响,因此鼓励恢复对RoI的未来研究。
用户研究:为了进一步评价我们方法的视觉性能,我们对Super SloMo、DAIN、SoftSplat和我们提出f方法的插帧结果进行了用户研究。我们分别对十个人进行主观实验。在每次测试中,我们随机选择150对,每对都包含我们方法的插帧结果和其中一种比较方法对应的帧,并要求投票选出最好的一种。我们将插帧框架和输入框架同时提供,使他们能在决策时间上面一致。图6展示了我们的方法与比较方法的平均票数百分比。对于每一种比较方法,超过83%的平均投票认为我们的方法在视觉质量上更好。实验结果表明,我们的方法在定量评价和视觉质量方面都取得了较好的效果。
六、总结
本文介绍了动漫视频插帧任务,是动画生成的重要一步。为了对动画视频插帧进行基准测试,构建了一个名为ATD-12K的大型动画三元组数据集,该数据集包含12000个带有丰富注释的三元组。我们还提出了一种有效的动画视频插帧框架AnimeInterp,该框架采用色块分割作为匹配指导,计算不同帧之间的逐片光流,并利用循环模块进一步细化光流的质量。综合实验证明了所提模块的有效性,以及AnimeInterp的泛化能力。
参考文献
详细请查阅论文相关资料;