黑马Java视频全套,Java中高级核心知识全面解析(6)
if (expire) setExpire(c,c->db,key,mstime()+milliseconds);
notifyKeyspaceEvent(NOTIFY_STRING,"set",key,c->db->id);
if (expire) notifyKeyspaceEvent(NOTIFY_GENERIC,
"expire",key,c->db->id);
addReply(c, ok_reply ? ok_reply : shared.ok);
}
就像上面介绍的那样,其实在之前版本的 Redis 中,由于`SETNX`和`EXPIRE`并不是**原子指令**,所以在一起执行会出现问题。
也许你会想到使用 Redis 事务来解决,但在这里不行,因为`EXPIRE`命令依赖于`SETNX`的执行结果,而事务中没有`if-else`的分支逻辑,如果 `SETNX` 没有抢到锁,`EXPIRE`就不应该执行。
为了解决这个疑难问题,Redis 开源社区涌现了许多分布式锁的 library,为了治理这个乱象,后来在Redis 2.8 的版本中,加入了 `SET` 指令的扩展参数,使得 `SETNX` 可以和 `EXPIRE` 指令一起执行了:
```java
> SET lock:test true ex 5 nx
OK
... do something critical ...
> del lock:test
你只需要符合 SET key value [EX seconds | PX milliseconds] [NX | XX] [KEEPTTL] 这样的格式就好了。
另外,官方文档也在 SETNX 文档中提到了这样一种思路:把 SETNX 对应 key 的 value 设置为
1)代码实现
下面用 Jedis 来模拟实现以下,关键代码如下:
private static final String LOCK_SUCCESS = "OK";
private static final Long RELEASE_SUCCESS = 1L;
private static final String SET_IF_NOT_EXIST = "NX";
private static final String SET_WITH_EXPIRE_TIME = "PX";
@Override
public String acquire() {
try {
// 获取锁的超时时间,超过这个时间则放弃获取锁
long end = System.currentTimeMillis() + acquireTimeout;
// 随机生成一个 value
String requireToken = UUID.randomUUID().toString();
while (System.currentTimeMillis() < end) {
String result = jedis
.set(lockKey, requireToken, SET_IF_NOT_EXIST,
SET_WITH_EXPIRE_TIME, expireTime);
if (LOCK_SUCCESS.equals(result)) {
return requireToken;
}
try {
Thread.sleep(100);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
} catch (Exception e) {
log.error("acquire lock due to error", e);
}
return null;
}
@Override
public boolean release(String identify) {
if (identify == null) {
return false;
}
String script = "if redis.call('get', KEYS[1]) == ARGV[1] then return
redis.call('del', KEYS[1]) else return 0 end";
Object result = new Object();
try {
result = jedis.eval(script, Collections.singletonList(lockKey), Collections.singletonList(identify));
if (RELEASE_SUCCESS.equals(result)) {
log.info("release lock success, requestToken:{}", identify);
return true;
}
} catch (Exception e) {
log.error("release lock due to error", e);
} finally {
if (jedis != null) {
jedis.close();
}
}
log.info("release lock failed, requestToken:{}, result:{}", identify, result);
return false;
}
二、Redlock分布式锁
1.什么是 RedLock
Redis 官方站这篇文章提出了一种权威的基于 Redis 实现分布式锁的方式名叫 Redlock,此种方式比原先的单节点的方法更安全。它可以保证以下特性:
- 安全特性:互斥访问,即永远只有一个 client 能拿到锁
- 避免死锁:最终 client 都可能拿到锁,不会出现死锁的情况,即使原本锁住某资源的 client crash了或者出现了网络分区
- 容错性:只要大部分 Redis 节点存活就可以正常提供服务
2.怎么在单节点上实现分布式锁
SET resource_name my_random_value NX PX 30000
主要依靠上述命令,该命令仅当 Key 不存在时(NX保证)set 值,并且设置过期时间 3000ms (PX保证),值 my_random_value 必须是所有 client 和所有锁请求发生期间唯一的,释放锁的逻辑是:
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end
上述实现可以避免释放另一个client创建的锁,如果只有 del 命令的话,那么如果 client1 拿到 lock1 之后因为某些操作阻塞了很长时间,此时 Redis 端 lock1 已经过期了并且已经被重新分配给了 client2,那么 client1 此时再去释放这把锁就会造成 client2 原本获取到的锁被 client1 无故释放了,但现在为每个 client 分配一个 unique 的 string 值可以避免这个问题。至于如何去生成这个 unique string,方法很多随意选择一种就行了。
3.Redlock 算法
算法很易懂,起 5 个 master 节点,分布在不同的机房尽量保证可用性。为了获得锁,client 会进行如下操作:
- 得到当前的时间,微秒单位
- 尝试顺序地在 5 个实例上申请锁,当然需要使用相同的 key 和 random value,这里一个 client 需要合理设置与 master 节点沟通的 timeout 大小,避免长时间和一个 fail 了的节点浪费时间
- 当 client 在大于等于 3 个 master 上成功申请到锁的时候,且它会计算申请锁消耗了多少时间,这部分消耗的时间采用获得锁的当下时间减去第一步获得的时间戳得到,如果锁的持续时长(lockvalidity time)比流逝的时间多的话,那么锁就真正获取到了。
- 如果锁申请到了,那么锁真正的 lock validity time 应该是 origin(lock validity time) - 申请锁期间流逝的时间
- 如果 client 申请锁失败了,那么它就会在少部分申请成功锁的 master 节点上执行释放锁的操作,重置状态
4.失败重试
如果一个 client 申请锁失败了,那么它需要稍等一会在重试避免多个 client 同时申请锁的情况,最好的情况是一个 client 需要几乎同时向 5 个 master 发起锁申请。另外就是如果 client 申请锁失败了它需要尽快在它曾经申请到锁的 master 上执行 unlock 操作,便于其他 client 获得这把锁,避免这些锁过期造成的时间浪费,当然如果这时候网络分区使得 client 无法联系上这些 master,那么这种浪费就是不得不付出的代价了。
5.放锁
放锁操作很简单,就是依次释放所有节点上的锁就行了
6.性能、崩溃恢复和 fsync
如果我们的节点没有持久化机制,client 从 5 个 master 中的 3 个处获得了锁,然后其中一个重启了,这是注意 整个环境中又出现了 3 个 master 可供另一个 client 申请同一把锁! 违反了互斥性。如果我们开启了 AOF 持久化那么情况会稍微好转一些,因为 Redis 的过期机制是语义层面实现的,所以在server 挂了的时候时间依旧在流逝,重启之后锁状态不会受到污染。但是考虑断电之后呢,AOF部分命令没来得及刷回磁盘直接丢失了,除非我们配置刷回策略为 fsnyc = always,但这会损伤性能。解决这个问题的方法是,当一个节点重启之后,我们规定在 max TTL 期间它是不可用的,这样它就不会干扰原本已经申请到的锁,等到它 crash 前的那部分锁都过期了,环境不存在历史锁了,那么再把这个节点加进来正常工作。
三、如何做可靠的分布式锁,Redlock真的可行么
如果你只是为了性能,那没必要用 Redlock,它成本高且复杂,你只用一个 Redis 实例也够了,最多加个从防止主挂了。当然,你使用单节点的 Redis 那么断电或者一些情况下,你会丢失锁,但是你的目的只是加速性能且断电这种事情不会经常发生,这并不是什么大问题。并且如果你使用了单节点 Redis,那么很显然你这个应用需要的锁粒度是很模糊粗糙的,也不会是什么重要的服务。
那么是否 Redlock 对于要求正确性的场景就合适呢?Martin 列举了若干场景证明 Redlock 这种算法是不可靠的。
1.用锁保护资源
这节里 Martin 先将 Redlock 放在了一边而是仅讨论总体上一个分布式锁是怎么工作的。在分布式环境下,锁比 mutex 这类复杂,因为涉及到不同节点、网络通信并且他们随时可能无征兆的 fail 。Martin假设了一个场景,一个 client 要修改一个文件,它先申请得到锁,然后修改文件写回,放锁。另一个 client 再申请锁 … 代码流程如下:
// THIS CODE IS BROKEN
function writeData(filename, data) {
var lock = lockService.acquireLock(filename);
if (!lock) {
throw 'Failed to acquire lock';
}
try {
var file = storage.readFile(filename);
var updated = updateContents(file, data);
storage.writeFile(filename, updated);
} finally {
lock.release();
}
}
可惜即使你的锁服务非常完美,上述代码还是可能跪,下面的流程图会告诉你为什么:
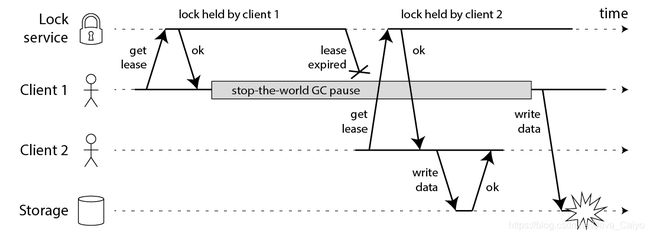
2.使用Fencing(栅栏)使得锁变安全
修复问题的方法也很简单:你需要在每次写操作时加入一个 fencing token。这个场景下,fencing token 可以是一个递增的数字(lock service 可以做到),每次有 client 申请锁就递增一次:
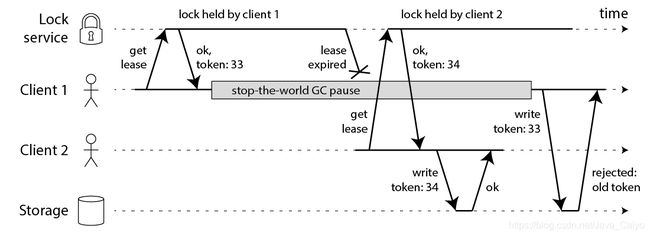
client1 申请锁同时拿到 token33,然后它进入长时间的停顿锁也过期了。client2 得到锁和 token34 写入数据,紧接着 client1 活过来之后尝试写入数据,自身 token33 比 34 小因此写入操作被拒绝。注意这需要存储层来检查 token,但这并不难实现。如果你使用 Zookeeper 作为 lock service 的话那么你可以使用 zxid 作为递增数字。
但是对于 Redlock 你要知道,没什么生成 fencing token 的方式,并且怎么修改 Redlock 算法使其能产生 fencing token 呢?好像并不那么显而易见。因为产生 token 需要单调递增,除非在单节点 Redis 上完成但是这又没有高可靠性,你好像需要引进一致性协议来让 Redlock 产生可靠的 fencing token。
3.使用时间来解决一致性
Redlock 无法产生 fencing token 早该成为在需求正确性的场景下弃用它的理由,但还有一些值得讨论的地方。
学术界有个说法,算法对时间不做假设:因为进程可能pause一段时间、数据包可能因为网络延迟延后到达、时钟可能根本就是错的。而可靠的算法依旧要在上述假设下做正确的事情。
对于 failure detector 来说,timeout 只能作为猜测某个节点 fail 的依据,因为网络延迟、本地时钟不正确等其他原因的限制。考虑到 Redis 使用 gettimeofday,而不是单调的时钟,会受到系统时间的影响,可能会突然前进或者后退一段时间,这会导致一个 key 更快或更慢地过期。
可见,Redlock 依赖于许多时间假设,它假设所有 Redis 节点都能对同一个 Key 在其过期前持有差不多的时间、跟过期时间相比网络延迟很小、跟过期时间相比进程 pause 很短。
4.用不可靠的时间打破 Redlock
这节 Martin 举了个因为时间问题,Redlock 不可靠的例子。
- client1 从 ABC 三个节点处申请到锁,DE由于网络原因请求没有到达
- C节点的时钟往前推了,导致 lock 过期’
- client2 在CDE处获得了锁,AB由于网络原因请求未到达
- 此时 client1 和 client2 都获得了锁
在 Redlock 官方文档中也提到了这个情况,不过是C崩溃的时候,Redlock 官方本身也是知道Redlock算法不是完全可靠的,官方为了解决这种问题建议使用延时启动。但是 Martin 这里分析得更加全面,指出延时启动不也是依赖于时钟的正确性的么?
接下来 Martin 又列举了进程 Pause 时而不是时钟不可靠时会发生的问题:
- client1从 ABCDE 处获得了锁
- 当获得锁的 response 还没到达 client1 时 client1 进入 GC 停顿
- 停顿期间锁已经过期了
- client2 在 ABCDE 处获得了锁
- client1 GC 完成收到了获得锁的 response,此时两个 client 又拿到了同一把锁
同时长时间的网络延迟也有可能导致同样的问题。
5.Redlock 的同步性假设
这些例子说明了,仅有在你假设了一个同步性系统模型的基础上,Redlock 才能正常工作,也就是系统能满足以下属性:
- 网络延时边界,即假设数据包一定能在某个最大延时之内到达
- 进程停顿边界,即进程停顿一定在某个最大时间之内
- 时钟错误边界,即不会从一个坏的 NTP 服务器处取得时间
6.结论
Martin 认为 Redlock 实在不是一个好的选择,对于需求性能的分布式锁应用它太重了且成本高;对于需求正确性的应用来说它不够安全。因为它对高危的时钟或者说其他上述列举的情况进行了不可靠的假设,如果你的应用只需要高性能的分布式锁不要求多高的正确性,那么单节点 Redis 够了;如果你的应用想要保住正确性,那么不建议 Redlock,建议使用一个合适的一致性协调系统,例如 Zookeeper,且保证存在 fencing token。
四、神奇的HyperLoglog解决统计问题
1.HyperLogLog 简介
HyperLogLog 是最早由Flajolet及其同事在 2007 年提出的一种 估算基数的近似最优算法。但跟原版论文不同的是,好像很多书包括 Redis 作者都把它称为一种 新的数据结构(new datastruct) (算法实现确 实需要一种特定的数据结构来实现)。
1)关于基数统计
基数统计(Cardinality Counting) 通常是用来统计一个集合中不重复的元素个数。
思考这样的一个场景: 如果你负责开发维护一个大型的网站,有一天老板找产品经理要网站上每个网页的 UV(独立访客,每个用户每天只记录一次),然后让你来开发这个统计模块,你会如何实现?
如果统计 PV(浏览量,用户没点一次记录一次),那非常好办,给每个页面配置一个独立的 Redis 计数器就可以了,把这个计数器的 key 后缀加上当天的日期。这样每来一个请求,就执行 INCRBY 指令一次,最终就可以统计出所有的 PV 数据了。
但是 UV 不同,它要去重,同一个用户一天之内的多次访问请求只能计数一次。这就要求了每一个网页请求都需要带上用户的 ID,无论是登录用户还是未登录的用户,都需要一个唯一 ID 来标识。
你也许马上就想到了一个 简单的解决方案:那就是 为每一个页面设置一个独立的 set 集合 来存储所有当天访问过此页面的用户 ID。但这样的 问题 就是:
- 存储空间巨大: 如果网站访问量一大,你需要用来存储的 set 集合就会非常大,如果页面再一多…为了一个去重功能耗费的资源就可以直接让你 老板打死你;
- 统计复杂: 这么多 set 集合如果要聚合统计一下,又是一个复杂的事情;
2)基数统计的常用方法
对于上述这样需要 基数统计 的事情,通常来说有两种比 set 集合更好的解决方案:
①、第一种:B 树
B 树最大的优势就是插入和查找效率很高,如果用 B 树存储要统计的数据,可以快速判断新来的数据是否存在,并快速将元素插入 B 树。要计算基础值,只需要计算 B 树的节点个数就行了。
不过将 B 树结构维护到内存中,能够解决统计和计算的问题,但是 并没有节省内存。
②、第二种:bitmap
bitmap 可以理解为通过一个 bit 数组来存储特定数据的一种数据结构,每一个 bit 位都能独立包含信息,bit 是数据的最小存储单位,因此能大量节省空间,也可以将整个 bit 数据一次性 load 到内存计算。如果定义一个很大的 bit 数组,基础统计中 每一个元素对应到 bit 数组中的一位,例如:

bitmap 还有一个明显的优势是 可以轻松合并多个统计结果,只需要对多个结果求异或就可以了,也可以大大减少存储内存。可以简单做一个计算,如果要统计 1 亿 个数据的基数值,大约需要的内存: 100_000_000/ 8/ 1024/ 1024 ≈ 12 M ,如果用 32 bit 的 int 代表 每一个 统计的数据,大约需要内存: 32 * 100_000_000/ 8/ 1024/ 1024 ≈ 381 M
可以看到 bitmap 对于内存的节省显而易见,但仍然不够。统计一个对象的基数值就需要 12 M ,如果统计 1 万个对象,就需要接近 120 G ,对于大数据的场景仍然不适用。
3)概率算法
实际上目前还没有发现更好的在 大数据场景 中 准确计算 基数的高效算法,因此在不追求绝对精确的情况下,使用概率算法算是一个不错的解决方案。
概率算法 不直接存储 数据集合本身,通过一定的 概率统计方法预估基数值,这种方法可以大大节省内存,同时保证误差控制在一定范围内。目前用于基数计数的概率算法包括:
- Linear Counting(LC):早期的基数估计算法,LC 在空间复杂度方面并不算优秀,实际上 LC 的空间复杂度与上文中简单 bitmap 方法是一样的(但是有个常数项级别的降低),都是 O(Nmax)
- LogLog Counting(LLC):LogLog Counting 相比于 LC 更加节省内存,空间复杂度只有O(log2(log2(Nmax)))
- HyperLogLog Counting(HLL):HyperLogLog Counting 是基于 LLC 的优化和改进,在同样空间复杂度情况下,能够比 LLC 的基数估计误差更小
其中,HyperLogLog 的表现是惊人的,上面我们简单计算过用 bitmap 存储 1 个亿 统计数据大概需要12 M 内存,而在 HyperLoglog 中,只需要不到 1 K 内存就能够做到!在 Redis 中实现的HyperLoglog也只需要 12 K 内存,在 标准误差 0.81% 的前提下,能够统计 264 个数据!
这是怎么做到的?! 下面赶紧来了解一下!
2.HyperLogLog 原理
我们来思考一个抛硬币的游戏:你连续掷 n 次硬币,然后说出其中连续掷为正面的最大次数,我来猜你一共抛了多少次。
这很容易理解吧,例如:你说你这一次 最多连续出现了 2 次 正面,那么我就可以知道你这一次投掷的次数并不多,所以 我可能会猜是 5 或者是其他小一些的数字,但如果你说你这一次 最多连续出现了 20次 正面,虽然我觉得不可能,但我仍然知道你花了特别多的时间,所以 我说 GUN…。
这期间我可能会要求你重复实验,然后我得到了更多的数据之后就会估计得更准。我们来把刚才的游戏换一种说法:

这张图的意思是,我们给定一系列的随机整数,记录下低位连续零位的最大长度 K,即为图中的maxbit,通过这个 K 值我们就可以估算出随机数的数量 N。
1)代码实验
我们可以简单编写代码做一个实验,来探究一下 K 和 N 之间的关系:
public class PfTest {
static class BitKeeper {
private int maxbit;
public void random() {
long value = ThreadLocalRandom.current().nextLong(2L << 32);
int bit = lowZeros(value);
if (bit > this.maxbit) {
this.maxbit = bit;
}
}
private int lowZeros(long value) {
int i = 0;
for (; i < 32; i++) {
if (value >> i << i != value) {
break;
}
}
return i - 1;
}
}
static class Experiment {
private int n;
private BitKeeper keeper;
public Experiment(int n) {
this.n = n;
this.keeper = new BitKeeper();
}
public void work() {
for (int i = 0; i < n; i++) {
this.keeper.random();
}
}
public void debug() {
System.out
.printf("%d %.2f %d\n", this.n, Math.log(this.n) / Math.log(2), this.keeper.maxbit);
}
}
public static void main(String[] args) {
for (int i = 1000; i < 100000; i += 100) {
Experiment exp = new Experiment(i);
exp.work();
exp.debug();
}
}
}
跟上图中的过程是一致的,话说为啥叫 PfTest 呢,包括 Redis 中的命令也一样带有一个 PF 前缀,还记得嘛,因为 HyperLogLog 的提出者上文提到过的,叫 Philippe Flajolet 。
截取部分输出查看:
//n n/log2 maxbit
34000 15.05 13
35000 15.10 13
36000 15.14 16
37000 15.18 17
38000 15.21 14
39000 15.25 16
40000 15.29 14
41000 15.32 16
42000 15.36 18
会发现 K和 N 的对数之间存在显著的线性相关性:N 约等于 2的k次方
2)更近一步:分桶平均
![]()
public class PfTest {
static class BitKeeper {
// 无变化, 代码省略
}
static class Experiment {
private int n;
private int k;
private BitKeeper[] keepers;
public Experiment(int n) {
this(n, 1024);
}
public Experiment(int n, int k) {
this.n = n;
this.k = k;
this.keepers = new BitKeeper[k];
for (int i = 0; i < k; i++) {
this.keepers[i] = new BitKeeper();
}
}
public void work() {
for (int i = 0; i < this.n; i++) {
long m = ThreadLocalRandom.current().nextLong(1L << 32);
BitKeeper keeper = keepers[(int) (((m & 0xfff0000) >> 16) % keepers.length)];
keeper.random();
}
}
public double estimate() {
double sumbitsInverse = 0.0;
for (BitKeeper keeper : keepers) {
sumbitsInverse += 1.0 / (float) keeper.maxbit;
}
double avgBits = (float) keepers.length / sumbitsInverse;
return Math.pow(2, avgBits) * this.k;
}
}
public static void main(String[] args) {
for (int i = 100000; i < 1000000; i += 100000) {
Experiment exp = new Experiment(i);
exp.work();
double est = exp.estimate();
System.out.printf("%d %.2f %.2f\n", i, est, Math.abs(est - i) / i);
}
}
}
这个过程有点 类似于选秀节目里面的打分,一堆专业评委打分,但是有一些评委因为自己特别喜欢所以给高了,一些评委又打低了,所以一般都要 屏蔽最高分和最低分,然后 再计算平均值,这样的出来的分数就差不多是公平公正的了。
上述代码就有 1024 个 “评委”,并且在计算平均值的时候,采用了 调和平均数,也就是倒数的平均值,它能有效地平滑离群值的影响:
avg = (3 + 4 + 5 + 104) / 4 = 29
avg = 4 / (1/3 + 1/4 + 1/5 + 1/104) = 5.044
观察脚本的输出,误差率百分比控制在个位数:
# 最后总结我的面试经验
2021年的金三银四一眨眼就到了,对于很多人来说是跳槽的好机会,大厂面试远没有我们想的那么困难,摆好心态,做好准备,你也可以的。
另外,面试中遇到不会的问题不妨尝试讲讲自己的思路,因为有些问题不是考察我们的编程能力,而是逻辑思维表达能力;最后平时要进行自我分析与评价,做好职业规划,不断摸索,提高自己的编程能力和抽象思维能力。
**资料领取方式:[点击这里免费获取](https://gitee.com/vip204888/java-p7)**

BAT面试经验
**实战系列:Spring全家桶+Redis等**

**其他相关的电子书:源码+调优**

**面试真题:**

辑思维表达能力;最后平时要进行自我分析与评价,做好职业规划,不断摸索,提高自己的编程能力和抽象思维能力。
**资料领取方式:[点击这里免费获取](https://gitee.com/vip204888/java-p7)**
[外链图片转存中...(img-YeVsceT1-1628238405564)]
BAT面试经验
**实战系列:Spring全家桶+Redis等**
[外链图片转存中...(img-wGZmGKLB-1628238405564)]
**其他相关的电子书:源码+调优**
[外链图片转存中...(img-NDhi2qMO-1628238405565)]
**面试真题:**
[外链图片转存中...(img-CkCxjObz-1628238405566)]
[外链图片转存中...(img-9Cc1WKEN-1628238405567)]