CoAlign:基于Agent-Object Pose Graph的鲁棒协同感知(3D Object Detection)
标签:Pose Error;Intermediate Fusion;3D Object Detection;V2X; Hybrid Collaboration;Intermediate & Late collaboration;
论文标题:Robust Collaborative 3D Object Detection in Presence of Pose Errors
发表会议/期刊:
开源代码:CoAlign
数据集:OPV2V、V2X-Sim 2.0、DAIR-V2X
问题:在V2X协同感知中,为了相互分享有效的信息,每个agent的精确定位是多agent协作的基础,因为不准确的pose会造成协作中的空间信息错位,导致感知性能比单agent的感知更差。但是,
1. 每个agent的定位模块所估计的6 DoF pose 在实践中并不精确,严重的定位误差将引起很大的relative pose noises,造成空间信息错位,从而大大降低了协同3D目标检测的性能。
2. 许多现有的方法在训练阶段需要pose的ground-truth来监督训练,尽管训练数据中的pose噪声可以离线纠正,但这种pose标记过程可能是昂贵并且不准确的。
6 DoF:
- 平移运动 刚体可以在3个自由度中平移:X轴平移(向前/后),Y轴平移(向上/下),Z轴平移(向左/右)。
- 旋转运动 刚体在3个自由度中旋转:X轴旋转-纵摇(Pitch)、Y轴旋转-横摇(Roll)、Z轴旋转-垂摇(Yaw)。
本文方法
为了减轻 pose errors的不利影响,提出了一个混合协同框架CoAlign,它使多个agent共享中间特征和单agent检测结果。其核心思想是:
- 利用所提出的agent-object pose graph 优化来调整场景中的agents和检测到的objects之间的relative pose relations,以促进pose一致性:一个object的pose从多个agent的角度来看应该是一致的。
- 为了有效缓解pose errors的影响,还进一步考虑了多尺度的中间融合策略,以全面地聚合多个空间尺度的协作信息。
1 Problem Formulation
基于中间协作的3D目标检测
假设一个场景中有N个合作的agents,每个agent都有感知、通信和检测的能力,协同目标检测目的是通过分布式的相互协作达到每个agent的更好的3D检测能力。对于第i个agent, O i O_i Oi表示第i个agent的感知观测值, B i B_i Bi表示检测输出, ξ i = ( x i , y i , z i , θ i , φ i , ψ i ) ξ_i = (x_i , y_i , z_i , θ_i , φ_i , ψ_i) ξi=(xi,yi,zi,θi,φi,ψi)表示其6 DoF pose( θ i , φ i , ψ i θ_i , φ_i , ψ_i θi,φi,ψi 分别为偏航、俯仰和滚动角度),则基于中间协作策略的3D目标检测:
- 特征提取: F i = f e n c o d e r ( O i ) F_i=f_{\rm{encoder}}(O_i) Fi=fencoder(Oi);
- 合作车辆(第 j j j个agent)将其信息(包括特征 F j F_j Fj 和 pose ξ j ξ_j ξj)传送到第 i i i个agent之后,通过pose变换将 F j F_j Fj 与 F i F_i Fi 坐标空间对齐: M j → i = f t r a n s f o r m ( ξ i , ( F j , ξ j ) ) M_{j→i}=f_{\rm{transform}}(ξ_i,(F_j, ξ_j)) Mj→i=ftransform(ξi,(Fj,ξj));
- 特征融合: F i ′ = f f u s i o n ( F i , { M j → i } j = 1 , 2 , . . . , N ) F'_i=f_{\rm{fusion}}(F_i,\{M_{j→i}\}_{j=1,2,...,N}) Fi′=ffusion(Fi,{Mj→i}j=1,2,...,N);
- 目标检测: B i = f d e c o d e r ( F i ′ ) B_i=f_{\rm{decoder}}(F'_i) Bi=fdecoder(Fi′)。
在实践中,每个6DoF pose ξ i ξ_i ξi是由定位模块实时估计的,其往往具有噪声。因此,从不同agents接收到的特征在经过pose变换之后会有不同的坐标系,无法实现空间对其,导致特征融合错位,进一步使得目标检测不准确。
2 Pose-robust 协同3D目标检测
本文在pose变换之前引入了一个pose校正模块,将pose errors 的影响降到最低。提出了一个混合协作框架CoAlign,其结合了中间和后期协作方式,可同时传输中间特征和目标检测输出。这种混合协作方式与中间协作相比,可以利用检测输出(边界框)作为场景landmarks去纠正agents之间的相对位置。
CoAlign整体架构:
其中Bi和B0 i分别是协作前和协作后的检测输出,ξ0 j→i是第i个代理的视角对第j个代理的校正相对姿势(ξ0 i→i是身份)。
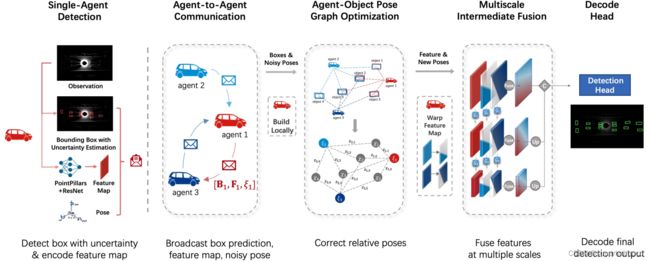
1)单agent检测,特征提取并进一步输出检测到的目标边界框 : F i , B i = f d e t e c t i o n ( O i ) F_i,B_i=f_{\rm{detection}}(O_i) Fi,Bi=fdetection(Oi);
2)V2V通信:向附近合作agent广播单车检测结果、特征图和noisy pose;
3)Agent-object pose graph优化模块,根据 noisy pose 和从其他 agent 获得的检测到的边界框来修正相对pose: { ξ j → i ′ } j = f c o r r e c t i o n ( { B j , ξ j } j = 1 , 2 , . . . , N ) \{ξ'_{j→i}\}_j=f_{\rm{correction}}(\{B_j,ξ_j\}_{j=1,2,...,N}) {ξj→i′}j=fcorrection({Bj,ξj}j=1,2,...,N);
4)根据校正后的相对pose,将其他agent的特征同步到自车坐标系下: M j → i = f t r a n s f o r m ( F j , ξ j → i ′ ) M_{j→i}=f_{\rm{transform}}(F_j, ξ'_{j→i}) Mj→i=ftransform(Fj,ξj→i′);
5)为了进一步确保对pose噪声的鲁棒性,使用多尺度中间融合来更新特征: F i ′ = f f u s i o n ( { M j → i } j = 1 , 2 , . . . , N ) F'_i=f_{\rm{fusion}}(\{M_{j→i}\}_{j=1,2,...,N}) Fi′=ffusion({Mj→i}j=1,2,...,N),其中 M i → i = F i M_{i→i} = F_i Mi→i=Fi;
6)检测头,使用融合后的特征来获得最终的检测结果: B i ′ = f d e c o d e r ( F i ′ ) B'_i=f_{\rm{decoder}}(F'_i) Bi′=fdecoder(Fi′)。
2.1 具有不确定性估计的单agent检测
在单agent检测阶段,每个agent采用PointPillars模型生成中间特征和预测边界框。
预测边界框的估计不确定性
由于后续需要依靠预测边界框来纠正pose,messy检测可能导致误差更大的相对pose,而每个边界框的估计不确定性可以提供有益的置信度信息来排除不理想的检测。因此,对于每个预测边界框,也估计其不确定性。将每个边界框的不确定性参数化为 b = ( x ^ , y ^ , z ^ , l ^ , w ^ , h ^ , θ ^ , σ x 2 , σ y 2 , σ θ 2 ) b = (\hat{x}, \hat{y}, \hat{z},\hat{l}, \hat{w}, \hat{h}, \hat{θ}, σ^2_x, σ^2_y , σ^2_θ ) b=(x^,y^,z^,l^,w^,h^,θ^,σx2,σy2,σθ2),包括估计边界框的3D中心位置、长度、宽度、高度、偏航角、中心位置方差和角度方差。
- 边界框中心位置建模
为了将中心位置 x x x(或 y y y)建模为一个随机变量,考虑一个均值为 x ^ \hat{x} x^、方差为 σ x 2 σ^2_x σx2的高斯分布。 通过最小化 估计的高斯分布 N ( x ^ , σ x 2 ) \mathcal{N}(\hat{x},σ^2_x) N(x^,σx2)与ground-truth delta 分布 P ( x ) = δ ( x − x 0 ) \mathbb{P}(x)= δ(x - x_0) P(x)=δ(x−x0)之间的 KL divergence 来监督训练,获得预测边界框的不确定性。
根据推导,由此产生的关于 x x x的损失为: L x = ( x ^ − x 0 ) 2 / ( 2 σ x 2 ) + l o g ( σ x 2 ) / 2 L_x = (\hat{x} - x_0) ^2 /(2σ^2_x)+ \rm{log}({σ^2_x}) /2 Lx=(x^−x0)2/(2σx2)+log(σx2)/2 - 偏航角建模
基于偏航角的周期性,考虑一个均值为 θ ^ \hat{θ} θ^ 方差为 1 / σ θ 2 1/σ^2_θ 1/σθ2的冯-米塞斯 von-Mises分布。通过最小化冯-米塞斯分布 M ( θ ^ , 1 / σ θ 2 ) \mathcal{M}(\hat{θ}, 1/σ^2_θ) M(θ^,1/σθ2)和ground-truth delta 分布 P ( θ ) = δ ( θ − θ 0 ) \mathbb{P}(θ)= δ(θ - θ_0) P(θ)=δ(θ−θ0)之间的KL divergence 来监督训练。
将所有损失组合起来,与不确定性估计共同训练单agent检测。总损失为:
L t o t a l = L c l s + α r e g L r e g + α c e n t e r ( L x + L y ) + α θ L θ L_{total} = L_{cls} + α_{reg}L_{reg} + α_{center}(L_x + L_y) + α_θL_θ Ltotal=Lcls+αregLreg+αcenter(Lx+Ly)+αθLθ,
其中 L c l s L_{cls} Lcls是目标分类的交叉熵损失, L r e g L_{reg} Lreg是边界框回归参数的平滑L1损失, α r e g , α c e n t e r , α θ α_{reg}, α_{center}, α_θ αreg,αcenter,αθ为损失平衡的超参数。(在本文实验中, 设置 α r e g = 2 , α c e n t e r = 0.25 , α θ = 0.125 α_{reg}=2, α_{center}=0.25, α_θ=0.125 αreg=2,αcenter=0.25,αθ=0.125 )
2.2 Agent-Object Pose Graph优化
在单Agent检测之后,每个Agent将与其他合作Agent共享三种信息,包括:
i)由其自身定位模块估计的pose信息 ξ i ξ_i ξi;
ii)自车检测的边界框;
iii)自身提取到的特征图 F i F_i Fi。
其中,pose信息和边界框将用于纠正相对pose,特征图将用于特征融合;另外,由于边界框检测的旋转分量只有偏航角,将每个pose简化到二维空间 ξ i = ( x i , y i , θ i ) ξ_i=(x_i , y_i , θ_i) ξi=(xi,yi,θi)。
为了校正相对位置,需要对齐多个agent对于同一物体的相应边界框。首先,车辆接收来自所有其他agent的信息后,将建立其内部的Agent-Object Pose Graph 以模拟Agent和检测物体之间的关系,Graph由agent节点、Object节点和edge组成。
1)agent节点集:由所有的agent组成;
2)Object节点集:Object是通过对所有从agent接收收到的相似边界框进行空间聚类而得到的;
3)edge集:反映了Agent和Object之间的检测关系,当一个agent检测到一个Object的边界框时,就设置一条边来连接它们。

另外,每个节点都有一个相应的pose,每条edge也反映了一个agent和一个object之间的相对pose。每个Agent的pose ξ j ξ_j ξj由其定位模块估计获得,而每个object的pose χ k χ_k χk从该object的多个预测边界框中采样得到。
优化
理想情况下,同一个object的pose是唯一的,即从多个agent的视角来看object的pose应该是一致的。所以,pose一致性误差 e j k = z j k − 1 ◦ ( ξ j − 1 ◦ χ k ) ∈ R 3 e_{jk} = z^{-1}_{jk} ◦(ξ^{-1}_j ◦ χ_k)∈\mathbb{R}^3 ejk=zjk−1◦(ξj−1◦χk)∈R3应该为0,为了促进pose一致性,考虑以下优化问题 :
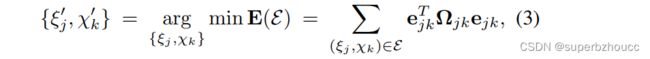
其中, Ω j k = d i a g ( [ 1 / σ x 2 , 1 / σ y 2 , 1 / σ θ 2 ] ) ∈ R 3 × 3 Ω_{jk} = diag([1/σ^2_x , 1/σ^2_y , 1/σ^2_θ ]) ∈\mathbb{R}^{3×3} Ωjk=diag([1/σx2,1/σy2,1/σθ2])∈R3×3类似于 graph-based SLAM中的信息矩阵,其对角线元素为边界框的不确定性估计,用于衡量对pose估计的置信度。
该优化问题与 graph-based SLAM优化类似,但语义不同:Graph-based SLAM在多个时间戳中对齐同一object,而Agent-Object Pose Graph优化在同一时间戳中对齐由多个agent检测到的同一object。
在训练迭代时,将自车的pose固定下来,并更新所有其他agent和object的pose,最后计算出相对pose ξ j → i ′ = ξ i ′ − 1 ◦ ξ j ′ ξ'_{j→i} = ξ'^{-1}_i ◦ ξ'_j ξj→i′=ξi′−1◦ξj′。有了校正后的相对pose ξ j → i ′ ξ'_{j→i} ξj→i′,自车就可以将接收到的特征 F j Fj Fj 转换到自车坐标系下,使其与自车捕获的特征 F i F_i Fi具有相同的坐标系。
2.3 多尺度特征融合
在空间对齐后,每个agent需要将自身获得的信息与其他agent的协作信息聚合以获得一个具有更多信息量的融合特征。由于较小尺度的特征可以提供更详细的几何和语义信息,而较大尺度的特征对pose误差的敏感性较低。因此,为了进一步减轻pose噪声的影响,这里采用了多尺度融合方法来融合多个空间尺度的特征,以产生信息量大且具有鲁棒性的特征。
假设 F j → i ( ℓ ) F^{(\ell)}_{j→i} Fj→i(ℓ) 为第 ℓ \ell ℓ 个空间尺度的协作特征,多尺度融合的工作原理为
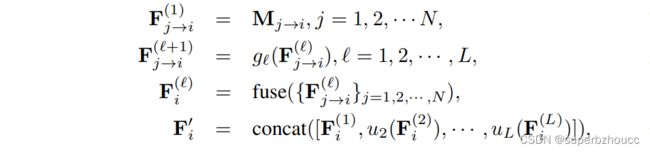
其中 g ℓ g_{\ell} gℓ是下采样为2的第 ℓ {\ell} ℓ个 residual layer,fuse(-)是沿 agent 维度的attention 加权, u ℓ u_{\ell} uℓ 是第 ℓ {\ell} ℓ个尺度的反卷积上采样,concat(-)是沿特征通道维度的拼接。融合的特征 F i ′ F'_i Fi′将被解码为最终的检测结果输出 B i ′ B'_i Bi′。
3 实验
3.1 执行细节
- 在训练阶段,为了模拟定位误差,在pose信息的二维中心 x 、 y x、y x、y和偏航角 θ θ θ上添加高斯噪声。采用通用图优化算法(g2o)来优化Agent-Object Pose Graph,选择密集求解器用于增量方程,Levenberg-Marquartdt算法用于迭代优化,最大迭代次数为1000。对于多尺度中间融合,采用通道数分别为(128, 256) 的2个residual layer。
- 为了验证在存在pose errors的情况下的3D目标检测性能,将CoAlign与现有的有/无pose errors设计的方法在在具有不同噪声水平的OPV2V、V2X-Sim 2.0和DAIR-V2X数据集上,比较它们在IoU阈值为0.5和0.7时的平均精度(AP)。实验表明,CoAlign在这三个数据集的各种噪声水平下都明显优于之前的方法,当噪声水平较高时,领先的差距更大。
4 总结
提出了一个对未知 pose errors 具有鲁棒性的混合协同3D检测框架CoAlign。采用中期和后期协作的混合策略,在agent-object pose graph modeling使用单车检测输出的边界框,来促进合作agent之间的 pose consistency来校正relative pose。采用多尺度的数据融合策略,在多个空间分辨率上聚合中间特征。与现有的其他方法相比,CoAlign在训练中不需要pose的ground-truth来监督学习,但是,在实验验证时仍然对pose 噪声做了假设,即在pose信息的二维中心和偏航角上添加了高斯噪声。