如何用MLflow做机器学习实验效果比对
背景介绍
最近看了很多MLflow相关的内容,做一个简单的分享。MLFlow是一款管理机器学习工作流程的工具,核心由以下4个模块组成:
-
MLflow Tracking:如何通过API的形式管理实验的参数、代码、结果,并且通过UI的形式做对比。
-
MLflow Projects:代码打包的一套方案
-
MLflow Models:一套模型部署的方案
-
MLflow Model Registry:一套管理模型和注册模型的方案
今天重点讲讲MLflow Tracking,也就是如何做机器学习不同模型下的实验的管理以及效果的比对。
详细流程
(1)安装环境
肯定要首先安装mlflow,可以通过pip install mlflow的方式进行安装。
(2)训练代码
可以使用mlflow的官方demo做模型的训练,具体代码如下:
重点看下最后几行:
mlflow.log_param("alpha", alpha)
mlflow.log_param("l1_ratio", l1_ratio)
mlflow.log_metric("rmse", rmse)
mlflow.log_metric("r2", r2)
mlflow.log_metric("mae", mae)
在这几行代码中,demo通过mlflow sdk注册了参与训练的参数,分别是alpha和l1_ratio,另外也注册了metric(参与评估的指标)为rmse、r2、mae
(3)执行训练任务
import os
import warnings
import sys
import pandas as pd
import numpy as np
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
from sklearn.model_selection import train_test_split
from sklearn.linear_model import ElasticNet
import mlflow
import mlflow.sklearn
import logging
logging.basicConfig(level=logging.WARN)
logger = logging.getLogger(__name__)
def eval_metrics(actual, pred):
rmse = np.sqrt(mean_squared_error(actual, pred))
mae = mean_absolute_error(actual, pred)
r2 = r2_score(actual, pred)
return rmse, mae, r2
if __name__ == "__main__":
warnings.filterwarnings("ignore")
np.random.seed(40)
# Read the wine-quality csv file from the URL
csv_url =\
'http://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-red.csv'
try:
data = pd.read_csv(csv_url, sep=';')
except Exception as e:
logger.exception(
"Unable to download training & test CSV, check your internet connection. Error: %s", e)
# Split the data into training and test sets. (0.75, 0.25) split.
train, test = train_test_split(data)
# The predicted column is "quality" which is a scalar from [3, 9]
train_x = train.drop(["quality"], axis=1)
test_x = test.drop(["quality"], axis=1)
train_y = train[["quality"]]
test_y = test[["quality"]]
alpha = float(sys.argv[1]) if len(sys.argv) > 1 else 0.5
l1_ratio = float(sys.argv[2]) if len(sys.argv) > 2 else 0.5
with mlflow.start_run():
lr = ElasticNet(alpha=alpha, l1_ratio=l1_ratio, random_state=42)
lr.fit(train_x, train_y)
predicted_qualities = lr.predict(test_x)
(rmse, mae, r2) = eval_metrics(test_y, predicted_qualities)
print("Elasticnet model (alpha=%f, l1_ratio=%f):" % (alpha, l1_ratio))
print(" RMSE: %s" % rmse)
print(" MAE: %s" % mae)
print(" R2: %s" % r2)
mlflow.log_param("alpha", alpha)
mlflow.log_param("l1_ratio", l1_ratio)
mlflow.log_metric("rmse", rmse)
mlflow.log_metric("r2", r2)
mlflow.log_metric("mae", mae)
mlflow.sklearn.log_model(lr, "model")
接下来就可以执行训练任务,每次执行需要传两个参数,分别对应代码里的alpha和l1_ratio这两个取值。
python train.py 0.4 0.4
python train.py 0.5 0.5
python train.py 0.6 0.6
训练完后数据会在本地做一个存储,以每次任务的实例名称为文件夹名

每个任务下面有四个内容,分别是params、metrics、artifacts、tags
-
Artifacts:存储输出的model
-
Metrics:存储了模型的评估指标,比如mae、r2、rmse
-
Params:存储的是一些参数
-
Tags:存储的是一些任务的meta,就是用户、日志等等
(4)可视化管理
在terminal中运行命令:mlflow run
然后在浏览器输入localhost:5000,可以打开mlflow的UI
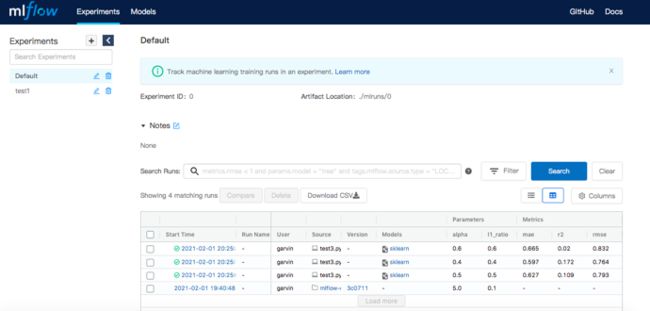
experiments是实验对照组,在选择对照组后可以选择不同的任务进行比较。

可以看到不同任务的效果比对:
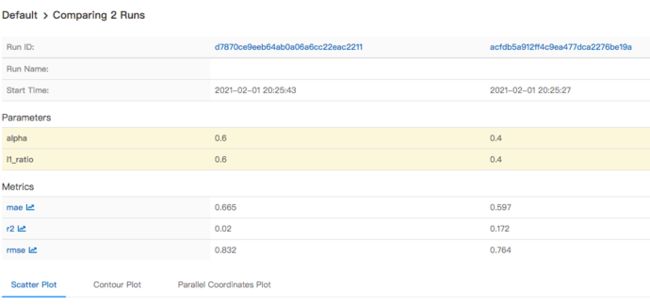
也可以图形化的展示:
