Mybatis轻量化框架学习(完整文档)
写在前面: Mybatis是一个优秀的框架,今天我给大家介绍一下mybatis的用法,本文特别长,可以和官方文档一起食用。并且我这里整理了一份PDF格式的笔记,需要可以找我,全文8W字符,写得很累,希望能给个赞。
公众号:小白编码。Mybatis官方文档: 官方文档
框架学习网址: 框架学习地址
动态代理技术: 动态代理技术
本文目录
-
- Mybatis介绍:
- 第一章:什么是框架
-
- 1.1.1框架概述
- 1.1.2框架要解决的问题
- 第二章:JDBC回顾
-
- 2.1.1JDBC编程的分析
- 2.1.2JDBC程序编写步骤
- 2.1.3获取数据库连接
- 2.1.4使用PreparedStatement实现CRUD操作
- 2.1.5 JDBC总结
-
-
- JDBC缺点:
-
- 第三章:Mybatis使用
-
- 3.1.1环境搭建与测试
- 3.1.2★小结问题:
- 第四章:★Mybatis全局配置文件
-
- 4.1.1 properties标签
- 4.1.2 ★settings标签
- 4.1.3 ★驼峰命名开启
- 4.1.4 typeAliases别名处理器
- 4.1.5 ★environments标签
- 4.1.6 databaseIdProvide标签
- 4.1.7 ★mappers标签映射注册
- 4.1.8同一个包的概念:
- 第五章:★Mybatis关系映射文件
-
- 5.1.1 ★sql关系映射文件的CRUD
- 5.1.2 MySQL获取主键:
- 5.2.1 Mybatis参数处理★
-
- 5.2.2 单个参数:
- 5.2.3 多个参数:
- 5.2.4 使用命名参数:
- 5.2.5 参数处理推荐使用方法:
- 5.2.6 ★参数处理总结:
- 5.3.1 ★#{}与${}的区别:
- 5.4.1 ★select标签
-
- 5.4.2 返回值类型为List集合
- 5.4.3 返回值类型为Map集合
- 5.4.4 自定义映射规则:
- 5.5.1 多表查询
-
- 5.5.2:mysql复习:
- 5.5.3:关联查询:
- 5.5.4:分步查询:
- 5.5.5:★关联集合封装
- 5.5.6:★一对多查询(关联集合分步查询封装):
- 5.5.7:延迟加载
- 5.6.1 鉴别器
- 第六章:★动态SQL
-
- 6.1.1 if判断标签与where标签
- 6.1.2 trim标签
- 6.1.3 choose标签
- 6.1.4 set标签
- 6.1.5 foreach标签与批量插入
- 6.1.6 抽取可重复sql的值
- 6.1.7 内置参数:
- 6.1.8 bink标签
- 第七章:★Mybatis缓存
-
- 7.1.1 一级缓存:
- 7.1.2 二级缓存
- 7.1.3 自定义缓存
- 第八章:★Mybatis插件开发
-
- 8.1.1 generator插件
- 8.1.2 page插件
- 8.1.3 批量插入插件
- 8.1.4 插件开发
- 第九章: 拓展功能
-
- 9.1.1 Mybatis调用存储过程
- 9.1.2 自定义类型处理器
- 写在后边:
Mybatis介绍:
mybatis是一个优秀的基于java的持久层框架,它内部封装了jdbc,使开发者只需要关注sql语句本身,而不需要花费精力去处理加载驱动、创建连接、创建statement等繁杂的过程。 mybatis通过xml或注解的方式将要执行的各种statement配置起来,并通过java对象和statement中sql的动态参数进行映射生成最终执行的sql语句,最后由mybatis框架执行sql并将结果映射为java对象并返回。 采用ORM思想解决了实体和数据库映射的问题,对jdbc进行了封装,屏蔽了jdbc api底层访问细节,使我们不用与jdbc api打交道,就可以完成对数据库的持久化操作。 为了我们能够更好掌握框架运行的内部过程,并且有更好的体验,下面我们将从自定义Mybatis框架开始来学习框架。此时我们将会体验框架从无到有的过程体验,也能够很好的综合前面阶段所学的基础。
而且:Mybatis中sql和java编码分开,功能边界清晰,一个专注业务、一个专注数据。


第一章:什么是框架
1.1.1框架概述
框架(Framework)是整个或部分系统的可重用设计,表现为一组抽象构件及构件实例间交互的方法;另一种定义认为,框架是可被应用开发者定制的应用骨架。前者是从应用方面而后者是从目的方面给出的定义。 简而言之,框架其实就是某种应用的半成品,就是一组组件,供你选用完成你自己的系统。简单说就是使用别人搭好的舞台,你来做表演。而且,框架一般是成熟的,不断升级的软件。
1.1.2框架要解决的问题
框架要解决的最重要的一个问题是技术整合的问题,在J2EE的 框架中,有着各种各样的技术,不同的软件企业需要从J2EE中选择不同的技术,这就使得软件企业最终的应用依赖于这些技术,技术自身的复杂性和技术的风险性将会直接对应用造成冲击。而应用是软件企业的核心,是竞争力的关键所在,因此应该将应用自身的设计和具体的实现技术解耦。这样,软件企业的研发将集中在应用的设计上,而不是具体的技术实现,技术实现是应用的底层支撑,它不应该直接对应用产生影响。 框架一般处在低层应用平台(如J2EE)和高层业务逻辑之间的中间层。
第二章:JDBC回顾
2.1.1JDBC编程的分析

2.1.2JDBC程序编写步骤

补充:ODBC(Open Database Connectivity,开放式数据库连接),是微软在Windows平台下推出的。使用者在程序中只需要调用ODBC API,由 ODBC 驱动程序将调用转换成为对特定的数据库的调用请求。
2.1.3获取数据库连接
首先导入Maven数据库驱动:
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>5.1.6version>
dependency>
public static void main(String[] args) {
Connection conn = null;
try {
//加载配置文件
InputStream is = JDBCTest.class.getClassLoader().getResourceAsStream("jdbc.properties");
Properties properties = new Properties();
properties.load(is);
//2.读取配置信息
String username = properties.getProperty("username");
String password = properties.getProperty("password");
String url = properties.getProperty("url");
String driverClass = properties.getProperty("driverClass");
//3.加载驱动
Class.forName(driverClass);
//获取连接
conn = DriverManager.getConnection(url, username, password);
System.out.println(conn);
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
assert conn != null;
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
其中,配置文件声明在工程的src目录下:【jdbc.properties】
user=root
password=abc
url=jdbc:mysql://localhost:3306/test
driverClass=com.mysql.jdbc.Driver
2.1.4使用PreparedStatement实现CRUD操作
使用PreparedStatement实现增、删、改操作
//通用的增、删、改操作(体现一:增、删、改 ; 体现二:针对于不同的表)
public void update(String sql,Object ... args){
Connection conn = null;
PreparedStatement ps = null;
try {
//1.获取数据库的连接
conn = JDBCUtils.getConnection();
//2.获取PreparedStatement的实例 (或:预编译sql语句)
ps = conn.prepareStatement(sql);
//3.填充占位符
for(int i = 0;i < args.length;i++){
ps.setObject(i + 1, args[i]);
}
//4.执行sql语句
ps.execute();
} catch (Exception e) {
e.printStackTrace();
}finally{
//5.关闭资源
JDBCUtils.closeResource(conn, ps);
}
}
使用PreparedStatement实现查询操作
public <T> T getInstance(Class<T> clazz, String sql, Object... args) {
Connection conn = null;
PreparedStatement ps = null;
ResultSet rs = null;
try {
// 1.获取数据库连接
conn = JDBCUtils.getConnection();
// 2.预编译sql语句,得到PreparedStatement对象
ps = conn.prepareStatement(sql);
// 3.填充占位符
for (int i = 0; i < args.length; i++) {
ps.setObject(i + 1, args[i]);
}
// 4.执行executeQuery(),得到结果集:ResultSet
rs = ps.executeQuery();
// 5.得到结果集的元数据:ResultSetMetaData
ResultSetMetaData rsmd = rs.getMetaData();
// 6.1通过ResultSetMetaData得到columnCount,columnLabel;通过ResultSet得到列值
int columnCount = rsmd.getColumnCount();
if (rs.next()) {
T t = clazz.newInstance();
for (int i = 0; i < columnCount; i++) {// 遍历每一个列
// 获取列值
Object columnVal = rs.getObject(i + 1);
// 获取列的别名:列的别名,使用类的属性名充当
String columnLabel = rsmd.getColumnLabel(i + 1);
// 6.2使用反射,给对象的相应属性赋值
Field field = clazz.getDeclaredField(columnLabel);
field.setAccessible(true);
field.set(t, columnVal);
}
return t;
}
} catch (Exception e) {
e.printStackTrace();
} finally {
// 7.关闭资源
JDBCUtils.closeResource(conn, ps, rs);
}
return null;
}
2.1.5 JDBC总结
总结
@Test
public void testUpdateWithTx() {
Connection conn = null;
try {
//1.获取连接的操作(
//① 手写的连接:JDBCUtils.getConnection();
//② 使用数据库连接池:C3P0;DBCP;Druid
//2.对数据表进行一系列CRUD操作
//① 使用PreparedStatement实现通用的增删改、查询操作(version 1.0 \ version 2.0)
//version2.0的增删改public void update(Connection conn,String sql,Object ... args){}
//version2.0的查询 public T getInstance(Connection conn,Class clazz,String sql,Object ... args){}
//② 使用dbutils提供的jar包中提供的QueryRunner类
//提交数据
conn.commit();
} catch (Exception e) {
e.printStackTrace();
try {
//回滚数据
conn.rollback();
} catch (SQLException e1) {
e1.printStackTrace();
}
}finally{
//3.关闭连接等操作
//① JDBCUtils.closeResource();
//② 使用dbutils提供的jar包中提供的DbUtils类提供了关闭的相关操作
}
}
JDBC缺点:
SQL夹在Java代码块里,耦合度高导致硬编码内伤
维护不易且实际开发需求中sql是有变化,频繁修改的情况多见
第三章:Mybatis使用
3.1.1环境搭建与测试
sql测试表准备:(自行插入数据)
CREATE TABLE `tbl_employee` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`last_name` varchar(255) DEFAULT NULL,
`gender` char(1) DEFAULT NULL,
`email` varchar(255) DEFAULT NULL,
`d_id` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `fk_emp_dept` (`d_id`),
CONSTRAINT `fk_emp_dept` FOREIGN KEY (`d_id`) REFERENCES `tbl_dept` (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=utf8;
第一步pom.xml创建坐标导入依赖:
<dependency>
<groupId>org.mybatisgroupId>
<artifactId>mybatisartifactId>
<version>3.4.5version>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>5.1.6version>
dependency>
<dependency>
<groupId>log4jgroupId>
<artifactId>log4jartifactId>
<version>1.2.12version>
dependency>
<dependency>
<groupId>junitgroupId>
<artifactId>junitartifactId>
<version>4.10version>
dependency>
<dependency>
<groupId>org.projectlombokgroupId>
<artifactId>lombokartifactId>
<version>1.18.12version>
<scope>providedscope>
dependency>
放入log4j.properties:
# Set root category priority to INFO and its only appender to CONSOLE.
#log4j.rootCategory=INFO, CONSOLE debug info warn error fatal
log4j.rootCategory=debug, CONSOLE, LOGFILE
# Set the enterprise logger category to FATAL and its only appender to CONSOLE.
log4j.logger.org.apache.axis.enterprise=FATAL, CONSOLE
# CONSOLE is set to be a ConsoleAppender using a PatternLayout.
log4j.appender.CONSOLE=org.apache.log4j.ConsoleAppender
log4j.appender.CONSOLE.layout=org.apache.log4j.PatternLayout
log4j.appender.CONSOLE.layout.ConversionPattern=%d{ISO8601} %-6r [%15.15t] %-5p %30.30c %x - %m\n
# LOGFILE is set to be a File appender using a PatternLayout.
log4j.appender.LOGFILE=org.apache.log4j.FileAppender
log4j.appender.LOGFILE.File=d:axis.log
log4j.appender.LOGFILE.Append=true
log4j.appender.LOGFILE.layout=org.apache.log4j.PatternLayout
log4j.appender.LOGFILE.layout.ConversionPattern=%d{ISO8601} %-6r [%15.15t] %-5p %30.30c %x - %m\n
第二步:创建实体类:
@Data
public class Employee{
private Integer id;
private String lastName;
private String email;
private Integer gender;
}
dao的接口:
public interface EmployeeMapper {
/**
* 查询所有操作
*/
List<Employee> getAllEmp();
}
第三步:mybatis-config.xml
<configuration>
<environments default="dev_mysql">
<environment id="dev_mysql">
<transactionManager type="JDBC">transactionManager>
<dataSource type="POOLED">
<property name="driver" value="com.mysql.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://localhost:3306/mybatis"/>
<property name="username" value="root"/>
<property name="password" value="123"/>
dataSource>
environment>
environments>
<mappers>
<mapper resource="cn/codewhite/dao/EmployeeMapper.xml"/>
mappers>
configuration>
第四步:创建映射配置文件EmployeeMapper.xml
<mapper namespace="cn.codewhite.dao.EmployeeMapper">
<select id="getAllEmp" resultType="cn.codewhite.pojo.Employee">
select * from tbl_employee
select>
mapper>
案例测试:
@Test
public void test01() {
InputStream is = null;
SqlSession sqlSession = null;
try {
// 第一步:读取配置文件(获取输入流)
is = Resources.getResourceAsStream("mybatis-config.xml");
// 第二步:创建SqlSessionFactory工厂
SqlSessionFactoryBuilder builder = new SqlSessionFactoryBuilder();
SqlSessionFactory sqlSessionFactory = builder.build(is);
// 第三步:创建SqlSession.openSession();
sqlSession = sqlSessionFactory.openSession();
// 第四步:创建Dao接口的代理对象
EmployeeMapper empMapper = sqlSession.getMapper(EmployeeMapper.class);
// 第五步:执行dao中的方法
List<Employee> allEmp = empMapper.getAllEmp();
//打印:
allEmp.forEach(System.out::println);
} catch (IOException e) {
e.printStackTrace();
} finally {
// 第六步:释放资源
sqlSession.close();
if (is != null){
try {
is.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
如果遇到bug:
1.在mybatis-config.xml没有告知mybatis映射配置的位置
Exception in thread "main" org.apache.ibatis.binding.BindingException: Type interface cn.codewhite.dao.EmployeeMapper is not known to the MapperRegistry.
答案:在SqlMapConifg.xml加入以下内容
<mappers>
<mapper resource="cn/codewhite/dao/EmployeeMapper.xml"/>
mappers>
★ 总结:
第一步:创建maven工程并导入坐标依赖
第二步:创建实体类和dao的接口
第三步:创建Mybatis的主配置文件
mybatis-config.xml
第四步:创建映射配置文件
EmployeeMapper.xml
环境搭建的注意事项:
第一个:创建EmployeeMapper.xml和 EmployeeMapper.java时名称是为了和我们之前的知识保持一致。
在Mybatis中它把持久层的操作接口名称和映射文件也叫做:Mapper
所以:EmployeeDao 和 EmployeeMapper是一样的
第二个:在idea中创建目录的时候,它和包是不一样的
包在创建时:com.itheima.dao它是三级结构
目录在创建时:com.itheima.dao是一级目录
第三个:mybatis的映射配置文件位置必须和dao接口的包结构相同
第四个:映射配置文件的mapper标签namespace属性的取值必须是dao接口的全限定类名
第五个:映射配置文件的操作配置(select),id属性的取值必须是dao接口的方法名
当我们遵从了第三,四,五点之后,我们在开发中就无须再写dao的实现类。
mybatis的入门案例
第一步:读取配置文件
第二步:创建SqlSessionFactory工厂
第三步:创建SqlSession
第四步:创建Dao接口的代理对象
第五步:执行dao中的方法
第六步:释放资源
3.1.2★小结问题:
1、接口式编程
原生: Dao ====> DaoImpl
mybatis: Mapper ====> xxMapper.xml
2、SqlSession代表和数据库的一次会话;用完必须关闭;close
3、SqlSession和connection一样它都是非线程安全。每次使用都应该去获取新的对象。
4、mapper接口没有实现类,但是mybatis会为这个接口生成一个代理对象。
(将接口和xml进行绑定)
EmployeeMapper empMapper = sqlSession.getMapper(EmployeeMapper.class);
5、两个重要的配置文件:
mybatis的全局配置文件:包含数据库连接池信息,事务管理器信息等…系统运行环境信息
sql映射文件:保存了每一个sql语句的映射信息:
将sql抽取出来。
- 1、根据xml配置文件(全局配置文件)创建一个SqlSessionFactory对象 有数据源一些运行环境信息
- 2、sql映射文件;配置了每一个sql,以及sql的封装规则等。
- 3、将sql映射文件注册在全局配置文件中
- 4、写代码:
- 1)、根据全局配置文件得到SqlSessionFactory;
- 2)、使用sqlSession工厂,获取到sqlSession对象使用他来执行增删改查
- 一个sqlSession就是代表和数据库的一次会话,用完关闭
- 3)、使用sql的唯一标志来告诉MyBatis执行哪个sql。sql都是保存在sql映射文件中的。
sql关系映射文件:存在dao包下的:EmployeeMapper.xml
全局配置文件:mybatis-config.xml,并且在全局配置文件中不要忘了写映射文件的地址
第四章:★Mybatis全局配置文件
配置文件配置项顺序:
properties→settings→typeAliases→typeHandlers→objectFactory→objectWrapperFactory→reflectorFactory→plugins→environments→databaseIdProvider→mappers。
4.1.1 properties标签
在配置文件内配置数据库环境,可以通过外部的properties配置文件引入信息。
标签属性:
resource:引入类路径下的资源:如果在某包下:cn/codewhite/xxxxx
url:引入网络路径或者磁盘路径下的资源
<properties resource="jdbconfig.properties">properties>
<environments default="dev_mysql">
<environment id="dev_mysql">
<transactionManager type="JDBC">transactionManager>
<dataSource type="POOLED">
<property name="driver" value="${jdbc.driver}"/>
<property name="url" value="${jdbc.url}"/>
<property name="username" value="${jdbc.username}"/>
<property name="password" value="${jdbc.password}"/>
dataSource>
environment>
environments>
properties:
jdbc.username=root
jdbc.password=123
jdbc.url=jdbc:mysql://localhost:3306/eesy_mybatis
jdbc.driver=com.mysql.jdbc.Driver
4.1.2 ★settings标签
settings包含很多重要的设置项
setting:用来设置每一个设置项
name:设置项名
value:设置项取值
4.1.3 ★驼峰命名开启
驼峰命名对应开启:mapUnderscoreToCamelCase
在我的数据库表中姓名命名为:last_name,而在JavaBean中:lastName
在不使用别名的情况下,没有开启驼峰命名它就无法封装信息:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZsIF9wFa-1590116276176)(C:\Users\JUN\AppData\Roaming\Typora\typora-user-images\image-20200515123534188.png)]](http://img.e-com-net.com/image/info8/8a03fb2a74424a8b80ad83a55907f4c9.jpg)
如何开启:全局配置文件中加入settings配置:mapUnderscoreToCamelCase为true
<settings>
<setting name="mapUnderscoreToCamelCase" value="true"/>
settings>
4.1.4 typeAliases别名处理器
typeAliases:别名处理器:可以为我们的java类型起别名,别名不区分大小写
全局配置文件:
1、typeAlias:为某个java类型起别名
type:指定要起别名的类型全类名;默认别名就是类名小写;employee
alias:指定新的别名
2、package:为某个包下的所有类批量起别名
name:指定包名(为当前包以及下面所有的后代包的每一个类都起一个默认别名(类名小写))
3、批量起别名的情况下,使用@Alias注解为某个类型指定新的别名
<typeAliases>
<package name="cn.codewhite.pojo"/>
typeAliases>
批量起别名,使用@Alias注解为某个类型指定新的别名
@Alias("emp)
public class Employee implements Serializable {
别名使用:在sql关系映射文件中使用别名
<select id="getAllEmp" resultType="emp">
select * from tbl_employee
select>
注意事项: 在使用注解别名的时候,必须要开启批量别名模式,否则报错。
4.1.5 ★environments标签
environments标签:环境,mybatis可以配置多种环境 ,default指定使用某种环境。可以达到快速切换环境。
transactionManager事务管理器
type事务管理器的类型
1.JDBC(JdbcTransactionFactory):使用JDBC的方式进行事务的回滚以及提交等
2.MANAGED(ManagedTransactionFactory):使用JEE服务器容器的方式进行事务控制,
其实是两个别名,这里一般用Spring来配置
自定义事务管理器:实现TransactionFactory接口.type指定为全类名。
dataSource数据源:
type:数据源类型
1.UNPOOLED(UnpooledDataSourceFactory):不使用连接池技术,从数据库拿连接
2.POOLED(PooledDataSourceFactory):使用数据库连接池技术
3.JNDI(JndiDataSourceFactory)使用JNDI连接技术
可以自定义德鲁伊,C3P0数据库连接池等
自定义数据源:实现DataSourceFactory接口,type是全类名
其实在Configuration中定义的都是别名:
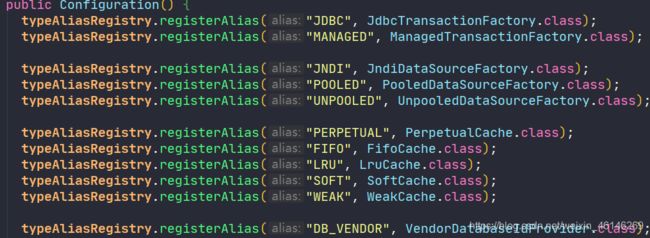
<environments default="dev_mysql">
<environment id="dev_mysql">
<transactionManager type="JDBC">transactionManager>
<dataSource type="POOLED">
<property name="driver" value="${jdbc.driver}"/>
<property name="url" value="${jdbc.url}"/>
<property name="username" value="${jdbc.username}"/>
<property name="password" value="${jdbc.password}"/>
dataSource>
environment>
<environment id="dev_oracle">
<transactionManager type="JDBC" />
<dataSource type="POOLED">
<property name="driver" value="${orcl.driver}" />
<property name="url" value="${orcl.url}" />
<property name="username" value="${orcl.username}" />
<property name="password" value="${orcl.password}" />
dataSource>
environment>
environments>
4.1.6 databaseIdProvide标签
databaseIdProvide支持多数据库厂商的,作用就是得到数据库厂商的标识
type="DB_VENDOR":VendorDatabaseIdProvider (驱动getDatabaseProductName()),
mybatis就能根据数据库厂商标识来执行不同的sql;
一般是:
MySQL,Oracle,SQL Server
全局配置文件设置:
<databaseIdProvider type="DB_VENDOR">
<property name="MySQL" value="mysql"/>
<property name="Oracle" value="oracle"/>
databaseIdProvider>
在sql映射文件中,输入databaseId="别名"指定使用的数据库:
<select id="getAllEmp" resultType="emp" databaseId="mysql">
select * from tbl_employee
select>
默认加载所有不带规则的SQL语句,如果当前是mysql,一般加载更精确的sql语句,(指的是标识)
4.1.7 ★mappers标签映射注册
mapper标签:注册一个sql映射
注册配置文件方式:
resource:引用类路径下的sql映射文件,如:mybatis/mapper/EmployeeMapper.xml
url:引用网路路径或者磁盘路径下的sql映射文件如:file:///var/mappers/AuthorMapper.xml
注册接口方式:
class:引用(注册)接口,
1、有sql映射文件,映射文件名必须和接口同名,并且放在与接口同一目录下;
2、没有sql映射文件,所有的sql都是利用注解写在接口上;
推荐:
比较重要的,复杂的Dao接口我们来写sql映射文件
不重要,简单的Dao接口为了开发快速可以使用注解.
将我们写好的sql映射文件(EmployeeMapper.xml)一定要注册到全局配置文件(mybatis-config.xml)中
全局配置文件:(注册方式选一种就好)
<mappers>
<package name="cn.codewhite.dao"/>
mappers>
这里需要讲的是:
注册接口注解开发模式:
java代码: 写上注解
public interface EmployeeMapperAnnotation {
@Select("select * from tbl_employee where id = #{id}")
Employee getEmpById(Integer id);
}
注册接口模式:(有sql映射文件,映射文件名必须和接口同名,并且放在与接口同一目录下;)
4.1.8同一个包的概念:
下图这样属于同一个包。

在Maven工程中:其实这两个也是算同一个包内:
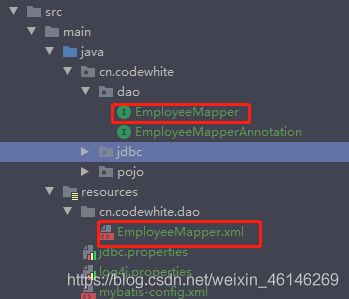
mybatis的映射配置文件位置必须和dao接口的包结构相同。
因为所有的文件都放在Bin目录下,只要我设置了3层目录,所以也等同于同一个目录
在idea中创建目录的时候,它和包是不一样的
包在创建时:com.itheima.dao它是三级结构
目录在创建时:com.itheima.dao是一级目录
第五章:★Mybatis关系映射文件
mapper常用属性:
-
namespace:名称空间;指定为接口的全类名
-
id:唯一标识
-
resultType:返回值类型
-
#{id}:从传递过来的参数中取出id值
-
parameterType参数类型
5.1.1 ★sql关系映射文件的CRUD
mapper接口:
public interface EmployeeMapper {
List<Employee> getAllEmp();
void addEmp(Employee emp);
int updateEmp(Employee emp);
boolean deleteEmpById(Integer id);
}
sql关系映射文件:
<mapper namespace="cn.codewhite.dao.EmployeeMapper">
<select id="getAllEmp" resultType="emp" databaseId="mysql">
select * from tbl_employee
select>
<insert id="addEmp" parameterType="cn.codewhite.pojo.Employee">
insert into tbl_employee(last_name,email,gender)
values (#{lastName},#{email},#{gender})
insert>
<update id="updateEmp" parameterType="cn.codewhite.pojo.Employee">
update tbl_employee
set last_name = #{lastName},email = #{email},gender = #{gender}
where id = #{id}
update>
<delete id="deleteEmpById" parameterType="cn.codewhite.pojo.Employee">
delete from tbl_employee where id = #{id}
delete>
CRUD前:

CRUD后:
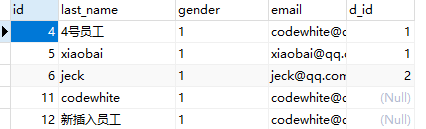
CRUD测试代码:
@Test
public void testCRUD() {
SqlSession sqlSession = null;
try {
SqlSessionFactory sqlSessionFactory = getSqlSessionFactory();
//1、获取到的SqlSession不会自动提交数据
sqlSession = sqlSessionFactory.openSession();
EmployeeMapper mapper = sqlSession.getMapper(EmployeeMapper.class);
//查询
List<Employee> allEmp = mapper.getAllEmp();
allEmp.forEach(System.out::println);
//插入1个员工
mapper.addEmp(new Employee(null, "新插入员工", "[email protected]", 1, null));
//修改4号员工
System.out.println(mapper.updateEmp(new Employee(4, "4号员工", "[email protected]", 1, null)));
//删除1号员工
System.out.println(mapper.deleteEmpById(1));
//2、提交数据
sqlSession.commit();
} catch (IOException e) {
e.printStackTrace();
} finally {
if (sqlSession != null) {
sqlSession.close();
}
}
}
注意问题: 增删改需要提交事务!!!否则无法生效
5.1.2 MySQL获取主键:
mysql支持自增主键,自增主键值的获取,mybatis也是利用statement.getGenreatedKeys();
useGeneratedKeys="true";使用自增主键获取主键值策略
keyProperty;指定对应的主键属性,也就是mybatis获取到主键值以后,将这个值封装给javaBean的哪个属性
<insert id="addEmp" parameterType="cn.codewhite.pojo.Employee"
useGeneratedKeys="true" keyProperty="id">
insert into tbl_employee(last_name,email,gender)
values (#{lastName},#{email},#{gender})
insert>
测试代码:此时就能够获取刚刚add的员工的id了
//插入1个员工
Employee employee = new Employee(null, "新插入员工3", "[email protected]", 0, null);
mapper.addEmp(employee);
System.out.println(employee.getId());
打印结果:14
5.2.1 Mybatis参数处理★
何为参数: 参数就是接口方法里定义的形参,然后需要在xml关系映射文件中使用#{参数名}获取参数。
如:Mapper接口方法:
Employee getEmpById(Integer id)
映射文件: 其中#{id}就是获取参数
<select id="getEmpById" resultType="cn.codewhite.pojo.Employee">
select * from tbl_employee where id = #{id}
select>
5.2.2 单个参数:
mybatis不会做特殊处理,
因为只有一个参数
#{参数名/任意名}:取出参数值。
Mapper映射文件:#{id}可以写成#{任意名}
原因:在Mapper接口只定义了一个参数Employee getEmpById(Integer id);
关系映射文件: 此时的#{id}可以写成任何名,如:#{idxxxx}都能够识别参数id
<select id="getEmpById" resultType="cn.codewhite.pojo.Employee">
select * from tbl_employee where id = #{id}
select>
测试:
getEmpById(1)结果:
Employee [id=1, lastName=Tom, email=jerry@atguigu.com, gender=0]
5.2.3 多个参数:
mybatis会做特殊处理。
多个参数会被封装成 一个map
key:param1…paramN,或者参数的索引也可以
value:传入的参数值
#{}就是从map中获取指定的key的值;
接口方法:Employee getEmpByIdAndLastName(Integer id,String lastName);
若直接使用#{id},#{lastName}取值,那么会直接报异常:
org.apache.ibatis.binding.BindingException:
Parameter 'id' not found.
Available parameters are [1, 0, param1, param2]
解决方法:使用命名参数,使用多个参数处理。
如何使用多个参数处理:
sql关系映射文件配置:
<select id="getEmpByIdAndLastName" resultType="cn.codewhite.pojo.Employee">
select * from tbl_employee where id = #{param1} and last_name = #{param2}
select>
或者:
<select id="getEmpByIdAndLastName" resultType="cn.codewhite.pojo.Employee">
select * from tbl_employee where id = #{arg0} and last_name = #{arg1}
select>
5.2.4 使用命名参数:
明确指定封装参数时map的key;使用注解:@Param("id")
多个参数会被封装成 一个map,
key:使用@Param注解指定的值
value:参数值
#{指定的key}取出对应的参数值
如何使用: 在方法里添加注解@Param("xxx") 注解方式:
EmployeeMapper接口方法:
Employee getEmpByIdAndLastName(@Param("id") Integer id, @Param("lastName") String lastName);
sql关系映射文件:此时就可以直接使用#{注解中定义的参数名}
<select id="getEmpByIdAndLastName" resultType="cn.codewhite.pojo.Employee">
select * from tbl_employee where id = #{id} and last_name = #{lastName}
select>
Map方式解决:
EmployeeMapper接口方法:
Employee getEmpByMap(Map<String, Object> map);
sql关系映射文件配置:
<select id="getEmpByMap" resultType="cn.codewhite.pojo.Employee">
select * from tbl_employee where id = #{id} and last_name = #{lastName}
select>
测试使用:通过map自定义key-value值来配置参数。
@Test
public void testMap(){
SqlSession sqlSession = null;
try {
SqlSessionFactory sqlSessionFactory = getSqlSessionFactory();
sqlSession = sqlSessionFactory.openSession();
EmployeeMapper mapper = sqlSession.getMapper(EmployeeMapper.class);
//重点:使用map定制,向map中放入指定的属性与属性值
Map<String, Object> map = new HashMap<>();
map.put("id",5);
map.put("lastName","xiaobai");
System.out.println(mapper.getEmpByMap(map));
} catch (IOException e) {
e.printStackTrace();
} finally {
if (sqlSession != null) {
sqlSession.close();
}
}
}
测试结果:Employee(id=5, lastName=xiaobai, email=xiaobai@qq.com, gender=1, dept=null)
5.2.5 参数处理推荐使用方法:
推荐的用法:POJO,MAP,TO。
POJO使用如下:
EmployeeMapper接口方法定义:
Employee getEmpByIdAndLastName(Employee employee);
XML:
<select id="getEmpByIdAndLastName" resultType="cn.codewhite.pojo.Employee">
select * from tbl_employee where id = #{id} and last_name = #{lastName}
select>
测试方法:通过javabean的属性来查询
@Test
public void getEmpByIdAndLastName() throws IOException {
SqlSessionFactory sqlSessionFactory = getSqlSessionFactory();
SqlSession sqlSession = sqlSessionFactory.openSession();
EmployeeMapper mapper = sqlSession.getMapper(EmployeeMapper.class);
Employee tom = mapper.getEmpByIdAndLastName(new Employee(1, "Tom", null, null));
System.out.println(tom);
}
MAP使用: 就是5.2.4里的map方法。
TO使用:
如果多个参数不是业务模型中的数据,但是经常要使用,推荐来编写一个TO(Transfer Object)数据传输对象
Page{
int index;
int size;
}
5.2.6 ★参数处理总结:
public Employee getEmp(@Param("id")Integer id,String lastName);
那么xml中取值:id==>#{id/param1} lastName==>#{param2}
public Employee getEmp(Integer id,@Param("e")Employee emp);
那么xml中取值:id==>#{param1} lastName===>#{param2.lastName/e.lastName}
注意: 如果是Collection(List、Set)类型或者是数组,
也会特殊处理。也是把传入的list或者数组封装在map中。
key:Collection(collection),如果是List还可以使用这个key(list)
数组(array)
public Employee getEmpById(List<Integer> ids);
5.3.1 ★#{}与${}的区别:
#{}:可以获取map中的值或者pojo对象属性的值;
${}:可以获取map中的值或者pojo对象属性的值;
xml映射文件:
select * from tbl_employee where id=${id} and last_name=#{lastName}
执行结果:Preparing: select * from tbl_employee where id=2 and last_name=?
以上测试代码发现:
#{}:是以预编译的形式,将参数设置到sql语句中;PreparedStatement;防止sql注入
${}:取出的值直接拼装在sql语句中;会有安全问题;
使用:原生jdbc不支持占位符的地方我们就可以使用${}进行取值
比如分表、排序…;按照年份分表拆分
select * from ${year}_salary where xxx;
select * from tbl_employee order by ${f_name} ${order}
#{}:更丰富的用法:
规定参数的一些规则:
javaType、 jdbcType、 mode(存储过程)、 numericScale、
resultMap、typeHandler、jdbcTypeName、 expression(未来准备支持的功能);
jdbcType通常需要在某种特定的条件下被设置:
在我们数据为null的时候,有些数据库可能不能识别mybatis对null的默认处理。比如Oracle(报错);
JdbcType OTHER:无效的类型;因为mybatis对所有的null都映射的是原生Jdbc的OTHER类型,oracle不能正确处理;
由于全局配置中:jdbcTypeForNull=OTHER;oracle不支持;两种办法
1、#{email,jdbcType=OTHER};
2、jdbcTypeForNull=NULL
5.4.1 ★select标签
- Id:唯一标识符。
–用来引用这条语句,需要和接口的方法名一致 - parameterType:参数类型。
–可以不传,MyBatis会根据TypeHandler自动推断 - resultType:返回值类型。
–别名或者全类名,如果返回的是集合,定义集合中元素的类型。不能和resultMap同时使用
5.4.2 返回值类型为List集合
EmployeeMapper.xml:
<select id="getEmpsByLastNameLike" resultType="cn.codewhite.pojo.Employee">
select * from tbl_employee where last_name like #{lastName}
select>
EmployeeMapper接口:
List<Employee> getEmpsByLastNameLike(String lastName);
测试方法:
@Test
public void test05() throws IOException {
// 1、获取sqlSessionFactory对象
SqlSessionFactory sqlSessionFactory = getSqlSessionFactory();
// 2、获取sqlSession对象
SqlSession openSession = sqlSessionFactory.openSession();
try {
// 3、获取接口的实现类对象
//会为接口自动的创建一个代理对象,代理对象去执行增删改查方法
EmployeeMapper mapper = openSession.getMapper(EmployeeMapper.class);
List<Employee> empsByLastNameLike = mapper.getEmpsByLastNameLike("%t%");
System.out.println(empsByLastNameLike);
} finally {
openSession.close();
}
}
测试结果:
[Employee [id=1, lastName=Tom, email=jerry@atguigu.com, gender=0]]
5.4.3 返回值类型为Map集合
EmployeeMapper.xml:
<select id="getEmpByIdReturnMap" resultType="map">
select * from tbl_employee where id = #{id}
select>
EmployeeMapper接口:
//返回一条记录的map;key就是列名,值就是对应的值
Map<String, Object> getEmpByIdReturnMap(Integer id);
测试方法:
@Test
public void test06() throws IOException {
// 1、获取sqlSessionFactory对象
SqlSessionFactory sqlSessionFactory = getSqlSessionFactory();
// 2、获取sqlSession对象
SqlSession openSession = sqlSessionFactory.openSession();
try {
// 3、获取接口的实现类对象
//会为接口自动的创建一个代理对象,代理对象去执行增删改查方法
EmployeeMapper mapper = openSession.getMapper(EmployeeMapper.class);
Map<String, Object> empByIdReturnMap = mapper.getEmpByIdReturnMap(1);
System.out.println(empByIdReturnMap);
} finally {
openSession.close();
}
}
结果:
//key=value&key=vlaue,其中key就是列名
{gender=1, d_id=1, last_name=xiaobai, id=5, email=xiaobai@qq.com}
5.4.4 自定义映射规则:
select标签:使用自定义某个javaBean的封装规则
type:自定义规则的Java类型
id:唯一id方便引用
resultMap自定义封装规则
指定主键列的封装规则
id定义主键会底层有优化;
column:指定哪一列
property:指定对应的javaBean属性
映射文件:
<resultMap id="formatMap" type="cn.codewhite.pojo.Employee">
<id column="id" property="id"/>
<result column="last_name" property="lastName"/>
<result column="email" property="email"/>
resultMap>
<select id="getEmpById" resultMap="formatMap">
select * from tbl_employee where id=#{id}
select>
EmployeeMapper接口:
Employee getEmpById(Integer id);
测试结果:
@Test
public void testFormatMap() throws IOException {
// 1、获取sqlSessionFactory对象
SqlSessionFactory sqlSessionFactory = getSqlSessionFactory();
// 2、获取sqlSession对象
SqlSession openSession = sqlSessionFactory.openSession();
try {
// 3、获取接口的实现类对象
EmployeeMapper mapper = openSession.getMapper(EmployeeMapper.class);
Employee empById = mapper.getEmpById(5);
System.out.println(empById);
} finally {
openSession.close();
}
}
测试结果:Employee(id=5, lastName=xiaobai, email=xiaobai@qq.com, gender=1, dept=null)
5.5.1 多表查询
5.5.2:mysql复习:
联合查询:
union 联合 合并:将多条查询语句的结果合并成一个结果
语法:
查询语句1
union
查询语句2
union
应用场景:
要查询的结果来自于多个表,且多个表没有直接的连接关系,但查询的信息一致时
特点:★
1、要求多条查询语句的查询列数是一致的!
2、要求多条查询语句的查询的每一列的类型和顺序最好一致
3、union关键字默认去重,如果使用union all 可以包含重复项
连接查询:
语法:
select 查询列表
from 表1 别名 【连接类型】
join 表2 别名
on 连接条件
【where 筛选条件】
【group by 分组】
【having 筛选条件】
【order by 排序列表】
分类:
内连接(★):inner
外连接
左外(★):left 【outer】
右外(★):right 【outer】
全外:full【outer】
交叉连接:cross
表的修改:
语法
alter table 表名 add|drop|modify|change column 列名 【列类型 约束】;
alter table 表明 add|drop|change|modify
#①修改列名
ALTER TABLE book CHANGE COLUMN publishdate pubDate DATETIME;
#②修改列的类型或约束
ALTER TABLE book MODIFY COLUMN pubdate TIMESTAMP;
#③添加新列
ALTER TABLE author ADD COLUMN annual DOUBLE;
#④删除列
ALTER TABLE book_author DROP COLUMN annual;
#⑤修改表名
ALTER TABLE author RENAME TO book_author;
DESC book;
多表环境搭建:Department:JavaBean
@Data
public class Department {
private Integer id;
private String departmentName;
private List<Employee> emps;
}
Employee下添加
private Department dept;
SQL创建:
CREATE TABLE `tbl_dept` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`dept_name` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8;
插入数据:
INSERT INTO `eesy_mybatis`.`tbl_dept`(`dept_name`) VALUES ('测试部')
INSERT INTO `eesy_mybatis`.`tbl_dept`(`dept_name`) VALUES ('开发部')
添加外键:
ALTER TABLE tbl_employee ADD CONSTRAINT
fk_emp_dept FOREIGN KEY(d_id) REFERENCES
tbl_dept(id);
添加:约束
UPDATE `eesy_mybatis`.`tbl_employee` SET `d_id` = 2 WHERE `id` = 3
表结构:
tbl_employee:
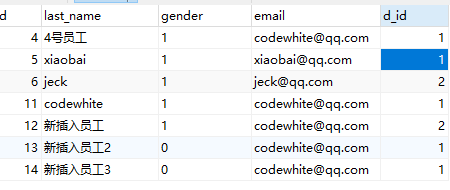
tbl_dept:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LvJf5Gbf-1590116276183)()]](http://img.e-com-net.com/image/info8/b6f72e81f0744460b3a3a12e0b4d4b0f.png)
5.5.3:关联查询:
需求:查询指定的Employee的同时查询员工对应的部门
Employee===Department
一个员工有与之对应的部门信息;
id last_name gender d_id did dept_name (private Department dept;)
EmployeeMapper接口:
Employee getEmpAndDept(Integer id);
EmployeeMapper.xml:
第一种封装: 联合查询:级联属性封装结果集
<resultMap type="cn.codewhite.pojo.Employee" id="MyEmp">
<id column="id" property="id"/>
<result column="last_name" property="lastName"/>
<result column="gender" property="gender"/>
<result column="did" property="dept.id"/>
<result column="dept_name" property="dept.departmentName"/>
resultMap>
<select id="getEmpAndDept" resultMap="MyEmp">
SELECT e.id id,e.last_name last_name,e.gender gender,e.email email,
e.d_id d_id,d.id did,d.dept_name dept_name
FROM tbl_employee e JOIN tbl_dept d ON e.d_id=d.id
WHERE e.id=#{id}
select>
结果:
Employee(id=5, lastName=xiaobai, email=xiaobai@qq.com, gender=1, dept=Department(id=1, departmentName=开发部, emps=null))
第二种封装:使用association定义关联的单个对象的封装规则;
EmployeeMapper.xml:
<resultMap id="MyEmp2" type="cn.codewhite.pojo.Employee">
<id column="id" property="id"/>
<result column="last_name" property="lastName"/>
<result column="gender" property="gender"/>
<result column="email" property="email"/>
<association property="dept" javaType="cn.codewhite.pojo.Department">
<id column="did" property="id"/>
<result column="dept_name" property="departmentName"/>
association>
resultMap>
<select id="getEmpAndDept" resultMap="MyEmp">
SELECT e.id id,e.last_name last_name,e.gender gender,e.email email,
e.d_id d_id,d.id did,d.dept_name dept_name
FROM tbl_employee e JOIN tbl_dept d ON e.d_id=d.id
WHERE e.id=#{id}
select>
5.5.4:分步查询:
方法:
1、先按照员工id查询员工信息
2、根据查询员工信息中的d_id值去部门表查出部门信息
3、部门设置到员工中;
分步查询:
DepartmentMapper.xml:
<select id="getDepdById" resultType="cn.codewhite.pojo.Department">
select id,dept_name departmentName from tbl_dept where id = #{id}
select>
EmployeeMapper.xml:
<resultMap id="MyEmpByStep" type="cn.codewhite.pojo.Employee">
<id column="id" property="id"/>
<result column="last_name" property="lastName"/>
<result column="email" property="email"/>
<result column="gender" property="gender"/>
<association property="dept" select="cn.codewhite.dao.DepartmentMapper.getDeptById"
column="d_id">
association>
resultMap>
<select id="getEmpByIdStep" resultMap="MyEmpByStep">
select * from tbl_employee where id = #{id}
select>
测试结果:
Employee empByIdStep = mapper.getEmpByIdStep(5);
结果:
Employee(id=5, lastName=xiaobai, email=xiaobai@qq.com, gender=1, dept=Department(id=1, departmentName=开发部, emps=null))
5.5.5:★关联集合封装
collection标签定义关联的集合类型的属性封装规则:
collection定义关联集合类型的属性的封装规则, ofType`:指定集合里面元素的类型
实现效果: 查询指定id部门下的所有员工并且将员工封装到员工集合中
DepartmentMapper:
Department getListByDeptId(Integer id);
DepartmentMapper.xml:
<resultMap id="myList" type="cn.codewhite.pojo.Department">
<id column="did" property="id"/>
<result column="dept_name" property="departmentName"/>
<collection property="emps" ofType="cn.codewhite.pojo.Employee">
<id column="emp_id" property="id"/>
<result column="emp_name" property="lastName"/>
<result column="gender" property="gender"/>
<result column="email" property="email"/>
collection>
resultMap>
<select id="getListByDeptId" resultMap="myList">
SELECT d.id did,d.dept_name,e.id emp_id,
e.last_name emp_name,gender,email
FROM tbl_dept d
LEFT JOIN tbl_employee e ON d.id=e.d_id
WHERE d.id = #{id}
select>
测试结果:getListByDeptId(1)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cx7OiYW7-1590116276184)()]](http://img.e-com-net.com/image/info8/be5a36f785d64da98a9310c150e9951f.jpg)
5.5.6:★一对多查询(关联集合分步查询封装):
实现需求: 查询指定id部门下的所有员工并且将员工封装到员工集合中,分两步:
先查询指定id的部门,然后查询指定id部门下的所有员工
DepartmentMapper:
Department getDeptByIdStep(Integer id);
DepartmentMapper.xml: 在selcet中:column="id"的值就是传入#{id}的值
<resultMap id="myStepMap" type="cn.codewhite.pojo.Department">
<id column="id" property="id"/>
<result column="dept_name" property="departmentName"/>
<collection property="emps" select="cn.codewhite.dao.EmployeeMapper.getEmpsListByDeptId"
column="id">
collection>
resultMap>
<select id="getDeptByIdStep" resultMap="myStepMap">
select id,dept_name from tbl_dept where id = #{id}
select>
扩展:多列的值传递过去:
将多列的值封装map传递;
column="{key1=column1,key2=column2}"
EmployeeMapper:
List<Employee> getEmpsListByDeptId(Integer deptId);
EmployeeMapper.xml
<select id="getEmpsListByDeptId" resultType="cn.codewhite.pojo.Employee">
select * from tbl_employee where d_id = #{deptId}
select>
测试结果:
getDeptByIdStep(1);
结果:
Department(id=1, departmentName=开发部, emps=[Employee(id=4, lastName=4号员工, email=codewhite@qq.com, gender=1, dept=null), Employee(id=5, lastName=xiaobai, email=xiaobai@qq.com, gender=1, dept=null), Employee(id=11, lastName=codewhite, email=codewhite@qq.com, gender=1, dept=null), Employee(id=13, lastName=新插入员工2, email=codewhite@qq.com, gender=0, dept=null), Employee(id=14, lastName=新插入员工3, email=codewhite@qq.com, gender=0, dept=null)])
我遇到的bug:
Error querying database. Cause: org.apache.ibatis.reflection.ReflectionException: Error instantiating interface cn.codewhite.dao.DepartmentMapper with invalid types () or values (). Cause: java.lang.NoSuchMethodException: cn.codewhite.dao.DepartmentMapper.<init>()
### The error may exist in cn/codewhite/dao/DepartmentMapper.xml
### The error may involve cn.codewhite.dao.DepartmentMapper.getDeptByIdStep
### The error occurred while handling results
### SQL: select id,dept_name from tbl_dept where id = ?
### Cause: org.apache.ibatis.reflection.ReflectionException: Error instantiating interface cn.codewhite.dao.DepartmentMapper with invalid types () or values (). Cause: java.lang.NoSuchMethodException: cn.codewhite.dao.DepartmentMapper.<init>()
由于我的在Mapper中结果集封装写错了:
<resultMap type="cn.codewhite.pojo.Department" id="MyDeptStep">
type写成了:cn.codewhite.dao.DepartmentMapper
5.5.7:延迟加载
可以使用延迟加载(懒加载);(按需加载)
fetchType=“lazy”:表示使用延迟加载;
lazy:延迟eager立即

Employee==>Dept:
我们每次查询Employee对象的时候,都将一起查询出来。
部门信息在我们使用的时候再去查询;
分段查询的基础之上加上两个配置:(全局配置文件中)
<setting name="lazyLoadingEnabled" value="true"/>
<setting name="aggressiveLazyLoading" value="false"/>
测试代码:延迟加载是需要用到的时候再加载,立即加载是先加载执行所有sql语句
@Test
public void getListByDeptId() throws IOException {
// 1、获取sqlSessionFactory对象
SqlSessionFactory sqlSessionFactory = getSqlSessionFactory();
// 2、获取sqlSession对象
SqlSession openSession = sqlSessionFactory.openSession();
try {
// 3、获取接口的实现类对象
DepartmentMapper mapper = openSession.getMapper(DepartmentMapper.class);
Department deptByIdStep = mapper.getDeptByIdStep(1);
//这里只需要获取指定id
System.out.println(deptByIdStep.getId());
//这里需要获取部门
System.out.println(deptByIdStep.getEmps());
} finally {
openSession.close();
}
}


5.6.1 鉴别器
<resultMap type="com.atguigu.mybatis.bean.Employee" id="MyEmpDis">
<id column="id" property="id"/>
<result column="last_name" property="lastName"/>
<result column="email" property="email"/>
<result column="gender" property="gender"/>
<discriminator javaType="string" column="gender">
<case value="0" resultType="com.atguigu.mybatis.bean.Employee">
<association property="dept"
select="com.atguigu.mybatis.dao.DepartmentMapper.getDeptById"
column="d_id">
association>
case>
<case value="1" resultType="com.atguigu.mybatis.bean.Employee">
<id column="id" property="id"/>
<result column="last_name" property="lastName"/>
<result column="last_name" property="email"/>
<result column="gender" property="gender"/>
case>
discriminator>
resultMap>
第六章:★动态SQL
6.1.1 if判断标签与where标签
test:判断表达式(OGNL) 像JSTL表达式:c:if test
OGNL参照PPT或者官方文档。
从参数中取值进行判断,遇见特殊符号应该去写转义字符: &&:
查询员工,要求,携带了哪个字段查询条件就带上这个字段的值
关系映射文件:
<select id="getEmpsByConditionIf" resultType="cn.codewhite.pojo.Employee">
select * from tbl_employee where
<if test="id!=null">
id = #{id}
if>
<if test="lastName!=null and lastName != "" ">
and last_name like #{lastName}
if>
<if test="email!=null and email.trim()!=""">
and email=#{email}
if>
<if test="gender==0 or gender==1">
and gender=#{gender}
if>
select>
测试:
@Test
public void testEmployeeMapperDynamicSQL() throws IOException {
// 1、获取sqlSessionFactory对象
SqlSessionFactory sqlSessionFactory = getSqlSessionFactory();
// 2、获取sqlSession对象
SqlSession openSession = sqlSessionFactory.openSession();
try {
// 3、获取接口的实现类对象
//会为接口自动的创建一个代理对象,代理对象去执行增删改查方法
EmployeeMapper mapper = openSession.getMapper(EmployeeMapper.class);
List<Employee> empsByConditionIf = mapper.getEmpsByConditionIf(new Employee(6,"%e%", null, null, null));
empsByConditionIf.forEach(System.out::println);
} finally {
openSession.close();
}
}
结果:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xIhR2tJF-1590116276187)()]](http://img.e-com-net.com/image/info8/7244a32f5639448381bb56526e0ad8c9.jpg)
问题一:上述情况,如果new Employee(null, "%e%", null, null, null),可以使用where与trim解决
id为空那么报错:因为sql语句拼接多了一个and

还有,判断情况if下,test是形参的变量,别将lastName写成了last_name
添加

使用new Employee(null, "%e%", null, null, null)测试:此时即使id为Null,也不会拼接多一个and再where的后边

6.1.2 trim标签
trim 字符串截取(where(封装查询条件), set(封装修改条件))
prefix="":前缀:trim标签体中是整个字符串拼串 后的结果。
prefix给拼串后的整个字符串加一个前缀
prefixOverrides="":
前缀覆盖: 去掉整个字符串前面多余的字符
suffix="":后缀
suffix给拼串后的整个字符串加一个后缀
suffixOverrides=""
后缀覆盖:去掉整个字符串后面多余的字符
在6.1.1中的if语句,还存在一个问题:若and写在了sql语句的后边,如:id=#{id} and,这个问题where是不能截取的,where只能截取前面的and,此时可以使用trim来截取
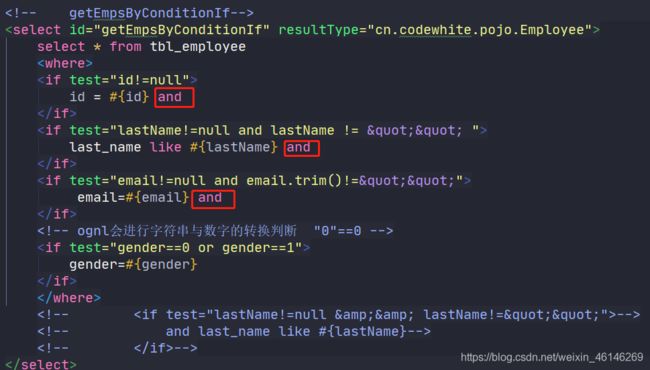
解决方案:
mapper接口方法:
<select id="getEmpsByConditionTrim" resultType="cn.codewhite.pojo.Employee">
select * from tbl_employee
<trim prefix="where" suffixOverrides="and">
<if test="id!=null">
id=#{id} and
if>
<if test="lastName!=null && lastName!=""">
last_name like #{lastName} and
if>
<if test="email!=null and email.trim()!=""">
email=#{email} and
if>
<if test="gender==0 or gender==1">
gender=#{gender}
if>
trim>
select>
6.1.3 choose标签
choose(when, otherwise):分支选择;带了break的swtich-case,如果带了id就用id查,如果带了lastName就用lastName查;只会进入其中一个。
实现效果:如果带了id就用id查,如果带了lastName就用lastName查;只会进入其中一个
mapper接口:
List<Employee> getEmpsByConditionChoose(Employee employee);
关系映射文件:
<select id="getEmpsByConditionChoose" resultType="cn.codewhite.pojo.Employee">
select * from tbl_employee
<where>
<choose>
<when test="id!=null">
id=#{id}
when>
<when test="lastName!=null">
last_name like #{lastName}
when>
<when test="email!=null">
email = #{email}
when>
<otherwise>
gender = 0
otherwise>
choose>
where>
select>
测试代码:这里我只带了id,所以是根据id查询
@Test
public void getEmpsByConditionChoose() throws IOException {
// 1、获取sqlSessionFactory对象
SqlSessionFactory sqlSessionFactory = getSqlSessionFactory();
// 2、获取sqlSession对象
SqlSession openSession = sqlSessionFactory.openSession();
try {
// 3、获取接口的实现类对象
EmployeeMapper mapper = openSession.getMapper(EmployeeMapper.class);
List<Employee> choose = mapper.getEmpsByConditionChoose(new Employee(5, null, null, 1, null));
System.out.println(choose);
} finally {
openSession.close();
}
}
结果:[Employee(id=5, lastName=xiaobai, email=xiaobai@qq.com, gender=1, dept=null)]
6.1.4 set标签
实现需求:修改指定id的员工
EmployeeMapper方法:
void updateEmp(Employee employee);
EmployeeMapper.xml:
<!--public void updateEmp(Employee employee); -->
<update id="updateEmp">
update tbl_employee
<!-- set可以截取后边的逗号 “,”-->
<set>
<if test="lastName!=null">
last_name=#{lastName},
</if>
<if test="email!=null">
email=#{email},
</if>
<if test="gender!=null">
gender=#{gender},
</if>
</set>
where id=#{id}
</update>
测试结果:
如果没有使用
update tbl_employee set email=?, gender=?, where id=?
加入了set标签后,就会截取多余的逗号。发送的语句:
update tbl_employee SET email=?, gender=? where id=?
第二种修改方法:这样也能达到效果,使用Trim标签
<update>
<trim prefix="set" suffixOverrides=",">
<if test="lastName!=null">
last_name=#{lastName},
if>
<if test="email!=null">
email=#{email},
if>
<if test="gender!=null">
gender=#{gender}
if>
trim>
where id=#{id}
update>
6.1.5 foreach标签与批量插入
前提条件:mysql子查询复习
一条查询语句中又嵌套了另一条完整的select语句,其中被嵌套的select语句,称为子查询或内查询,在外面的查询语句,称为主查询或外查询
特点:
1、子查询都放在小括号内
2、子查询可以放在from后面、select后面、where后面、having后面,但一般放在条件的右侧
3、子查询优先于主查询执行,主查询使用了子查询的执行结果
4、子查询根据查询结果的行数不同分为以下两类:
① 单行子查询
结果集只有一行
一般搭配单行操作符使用:> < = <> >= <=
非法使用子查询的情况:
a、子查询的结果为一组值
b、子查询的结果为空
② 多行子查询
结果集有多行
一般搭配多行操作符使用:any、all、in、not in
in: 属于子查询结果中的任意一个就行
any和all往往可以用其他查询代替
foreach 标签:遍历集合
要求,查询任意一个员工,添加到集合中:
EmployeeMapper接口:千万不要在接口中少了@Param("ids")这个注解否则报以下异常:
List<Employee> getEmpsByConditionForeach(@Param("ids")List<Integer> ids);
异常:
Error querying database. Cause: org.apache.ibatis.binding.BindingException: Parameter 'ids' not found. Available parameters are [collection, list]
Cause: org.apache.ibatis.binding.BindingException: Parameter 'ids' not found. Available parameters are [collection, list]
EmployeeMapper.xml:
<select id="getEmpsByConditionForeach" resultType="cn.codewhite.pojo.Employee">
select * from tbl_employee
<foreach collection="ids" item="item_id" separator=","
open="where id in(" close=")">
#{item_id}
foreach>
select>
测试代码:
@Test
public void testgetEmpsByConditionForeach() throws IOException {
// 1、获取sqlSessionFactory对象
SqlSessionFactory sqlSessionFactory = getSqlSessionFactory();
// 2、获取sqlSession对象
SqlSession openSession = sqlSessionFactory.openSession();
try {
// 3、获取接口的实现类对象
//会为接口自动的创建一个代理对象,代理对象去执行增删改查方法
EmployeeMapper mapper = openSession.getMapper(EmployeeMapper.class);
List empsByConditionForeach = mapper.getEmpsByConditionForeach(Arrays.asList(5,6,8));
empsByConditionForeach.forEach(System.out::println);
} finally {
openSession.close();
}
}
结果:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hlI9j586-1590116276192)()]](http://img.e-com-net.com/image/info8/651eb44a2d4a4eb0a854c55f2274bb79.jpg)
6.1.6 抽取可重复sql的值
抽取可重用的sql片段。方便后面引用
1、sql抽取:经常将要查询的列名,或者插入用的列名抽取出来方便引用
2、include来引用已经抽取的sql:
3、include还可以自定义一些property,sql标签内部就能使用自定义的属性
include-property:取值的正确方式${prop}, #{不能使用这种方式}
mapper映射文件:
<insert id="addEmp" parameterType="cn.codewhite.pojo.Employee"
useGeneratedKeys="true" keyProperty="id">
insert into tbl_employee(
<include refid="insertColumn">
<property name="testColomn" value="abc"/>
include>
)
values (#{lastName},#{email},#{gender})
insert>
<sql id="insertColumn">
<if test="_databaseId=='mysql'">
last_name,email,gender
if>
sql>
取值用法:在include中定义的属性使用${属性}取值。
<include refid="insertColumn">
<property name="testColomn" value="abc"/>
include>
<sql id="insertColumn">
<if test="_databaseId=='mysql'">
last_name,email,gender,d_id,${testColomn}
if>
sql>
6.1.7 内置参数:
不只是方法传递过来的参数,可以用来判断,取值
第一个:_parameter:代表整个参数
单个参数:_parameter就是这个参数
多个参数:参数会封装成一个map:_parameter:就是整个参数
`_databaseId`:如果配置了`databaseIdProvider`标签
那么_databaseId就是代表当前数据库的别名这里我配置了是mysql
xml配置文件:如果是mysql就执行mysql的sql语句
<select id="queryTestParamAndDatabaseId" resultType="cn.codewhite.pojo.Employee">
<if test="_databaseId=='mysql'">
select * from tbl_employee
<if test="_parameter!=null">
where last_name = #{lastName}
if>
if>
<if test="_databaseId=='oracle'">
select * from tbl_employee
if>
select>
6.1.8 bink标签
bind:可以将OGNL表达式的值绑定到一个变量中,方便后来引用这个变量的值
如:
<select id="queryTestParamAndDatabaseId" resultType="cn.codewhite.pojo.Employee">
<if test="_databaseId=='mysql'">
select * from tbl_employee
<bind name="_lastName" value="'%'+lastName+'%'"/>
<if test="_parameter!=null">
where last_name like #{lastName}
if>
if>
第七章:★Mybatis缓存
7.1.1 一级缓存:
(本地缓存):sqlSession级别的缓存。一级缓存是一直开启的;SqlSession级别的一个Map。
与数据库同一次会话期间查询到的数据会放在本地缓存中。
以后如果需要获取相同的数据,直接从缓存中拿,没必要再去查询数据库;
一级缓存失效情况(没有使用到当前一级缓存的情况,效果就是,还需要再向数据库发出查询):
1、sqlSession不同。
2、sqlSession相同,查询条件不同.(当前一级缓存中还没有这个数据)
3、sqlSession相同,两次查询之间执行了增删改操作(这次增删改可能对当前数据有影响)
4、sqlSession相同,手动清除了一级缓存(缓存清空)
测试代码:
@Test
public void testFirstLevelCache() throws IOException{
SqlSessionFactory sqlSessionFactory = getSqlSessionFactory();
SqlSession openSession = sqlSessionFactory.openSession();
try{
EmployeeMapper mapper = openSession.getMapper(EmployeeMapper.class);
Employee emp01 = mapper.getEmpById(1);
System.out.println(emp01);
//xxxxx
//1、sqlSession不同。
//SqlSession openSession2 = sqlSessionFactory.openSession();
//EmployeeMapper mapper2 = openSession2.getMapper(EmployeeMapper.class);
//2、sqlSession相同,查询条件不同
//3、sqlSession相同,两次查询之间执行了增删改操作(这次增删改可能对当前数据有影响)
//mapper.addEmp(new Employee(null, "testCache", "cache", "1"));
//System.out.println("数据添加成功");
//4、sqlSession相同,手动清除了一级缓存(缓存清空)
//openSession.clearCache();
Employee emp02 = mapper.getEmpById(1);
//Employee emp03 = mapper.getEmpById(3);
System.out.println(emp02);
//System.out.println(emp03);
System.out.println(emp01==emp02);
//openSession2.close();
}finally{
openSession.close();
}
}
7.1.2 二级缓存

(全局缓存):基于namespace级别的缓存:一个namespace对应一个二级缓存:
工作机制:
1、一个会话,查询一条数据,这个数据就会被放在当前会话的一级缓存中;
2、如果会话关闭;一级缓存中的数据会被保存到二级缓存中;新的会话查询信息,就可以参照二级缓存中的内容;
3、sqlSession=EmployeeMapper>Employee
DepartmentMapper===>Department
不同namespace查出的数据会放在自己对应的缓存中(map)
效果:数据会从二级缓存中获取
查出的数据都会被默认先放在一级缓存中。
只有会话提交或者关闭以后,一级缓存中的数据才会转移到二级缓存中
使用:
1)、开启全局二级缓存配置:
2)、去mapper.xml中配置使用二级缓存:
3)、我们的POJO需要实现序列化接口
全局config配置:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WdUrzoKi-1590116276193)()]](http://img.e-com-net.com/image/info8/3487f9fe767a4189b2a27799df9e4f4e.jpg)
EmployeeMapper.xml二级缓存:
eviction:缓存的回收策略:
• LRU– 最近最少使用的:移除最长时间不被使用的对象。
• FIFO– 先进先出:按对象进入缓存的顺序来移除它们。
• SOFT – 软引用:移除基于垃圾回收器状态和软引用规则的对象。
•WEAK – 弱引用:更积极地移除基于垃圾收集器状态和弱引用规则的对象。
• 默认的是 LRU。
flushInterval:缓存刷新间隔:缓存多长时间清空一次,默认不清空,设置一个毫秒值
readOnly:是否只读:
true:只读;mybatis认为所有从缓存中获取数据的操作都是只读操作,不会修改数据。
mybatis为了加快获取速度,直接就会将数据在缓存中的引用交给用户。不安全,速度快
false:非只读:mybatis觉得获取的数据可能会被修改。
mybatis会利用序列化&反序列的技术克隆一份新的数据给你。安全,速度慢
size:缓存存放多少元素;
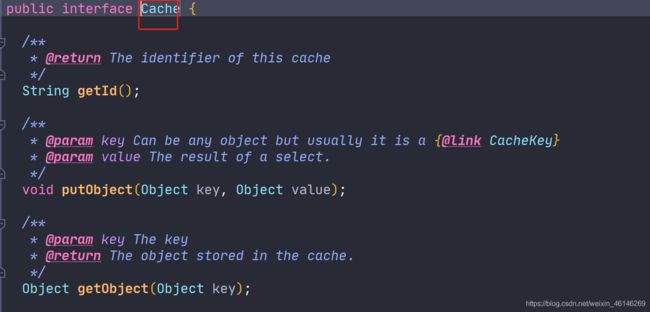
type="":指定自定义缓存的全类名;
实现Cache接口即可,Cache接口:
 这里我EmployeeMapper.xml二级缓存使用默认配置:
这里我EmployeeMapper.xml二级缓存使用默认配置:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DfA5uAXg-1590116276195)()]](http://img.e-com-net.com/image/info8/a7047adc4af744cd8f6f872024ae2ae3.jpg)
测试代码:
@Test
public void testCache() {
SqlSession sqlSession = null;
try {
SqlSessionFactory sqlSessionFactory = getSqlSessionFactory();
sqlSession = sqlSessionFactory.openSession();
EmployeeMapper mapper = sqlSession.getMapper(EmployeeMapper.class);
Employee emp1 = mapper.getEmpById(5);
System.out.println(emp1);
//必须关闭会话
sqlSession.close();
sqlSession.clearCache();
SqlSession sqlSession1 = sqlSessionFactory.openSession();
EmployeeMapper mapper1 = sqlSession1.getMapper(EmployeeMapper.class);
Employee emp2 = mapper1.getEmpById(5);
System.out.println(emp2);
System.out.println(emp1 == emp2);
} catch (IOException e) {
e.printStackTrace();
}
}
测试结果:
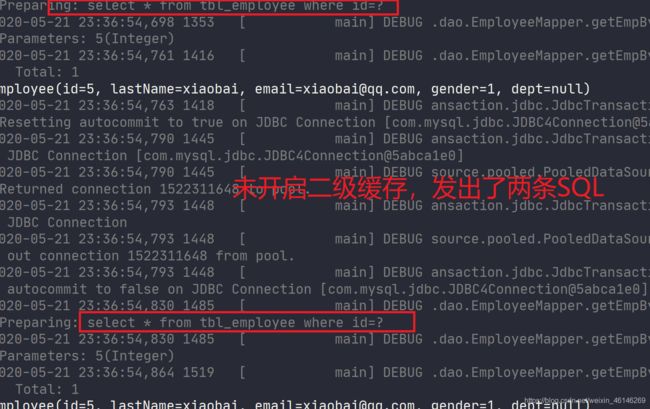
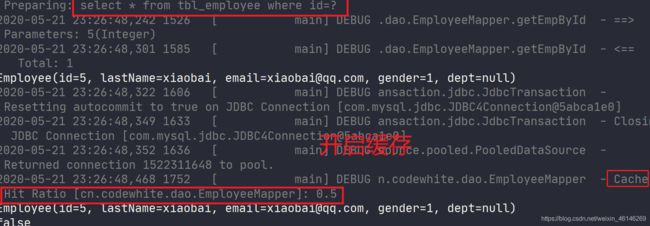
可以看到,未开启二级缓存的时候,发出两个sql,开启了后,只发出一个sql,他们是不同会话的!
二级缓存其他配置:
和缓存有关的设置/属性:
1)cacheEnabled=true:false:关闭缓存(二级缓存关闭)(一级缓存一直可用的)
全局配置文件中:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-aeEwNDLP-1590116276197)(]](http://img.e-com-net.com/image/info8/1e930984bc3f486190a367d95ae18d27.jpg)
2)、每个select标签都有useCache="true":false:不使用缓存(一级缓存依然使用,二级缓存不使用),默认true
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4HEVVsnP-1590116276197)()]](http://img.e-com-net.com/image/info8/53c987bdbb2045af9626c34359351002.jpg)
3)、【每个增删改标签的:flushCache=“true”:(一级二级都会清除)】
增删改执行完成后就会清楚缓存;
测试:flushCache=“true”:一级缓存就清空了;二级也会被清除;

查询标签:flushCache="false":
如果flushCache=true;每次查询之后都会清空缓存;缓存是没有被使用的;
![]()
4)、sqlSession.clearCache();只是清除当前session的一级缓存;

5)、localCacheScope:本地缓存作用域:(一级缓存SESSION);当前会话的所有数据保存在会话缓存中;
STATEMENT:可以禁用一级缓存;
7.1.3 自定义缓存
1.导入第三方缓存包即可;
2.导入与第三方缓存整合的适配包;官方有;
3.mapper.xml中使用自定义缓存
ehcache.xml:
<diskStore path="D:\44\ehcache" />
<defaultCache
maxElementsInMemory="10000"
maxElementsOnDisk="10000000"
eternal="false"
overflowToDisk="true"
timeToIdleSeconds="120"
timeToLiveSeconds="120"
diskExpiryThreadIntervalSeconds="120"
memoryStoreEvictionPolicy="LRU">
defaultCache>
ehcache>
第八章:★Mybatis插件开发
8.1.1 generator插件
依赖导入:
<dependency>
<groupId>org.mybatis.generatorgroupId>
<artifactId>mybatis-generator-coreartifactId>
<version>1.3.7version>
dependency>
mgb.xml:
<generatorConfiguration>
<context id="DB2Tables" targetRuntime="MyBatis3Simple">
<jdbcConnection driverClass="com.mysql.jdbc.Driver"
connectionURL="jdbc:mysql://localhost:3306/eesy_mybatis?allowMultiQueries=true"
userId="root"
password="123">
jdbcConnection>
<javaTypeResolver >
<property name="forceBigDecimals" value="false" />
javaTypeResolver>
<javaModelGenerator targetPackage="cn.codewhite.pojo"
targetProject=".\src\main\java">
<property name="enableSubPackages" value="true" />
<property name="trimStrings" value="true" />
javaModelGenerator>
<sqlMapGenerator targetPackage="cn.codewhite.dao"
targetProject=".\src\main\resources">
<property name="enableSubPackages" value="true" />
sqlMapGenerator>
<javaClientGenerator type="XMLMAPPER" targetPackage="cn.codewhite.dao"
targetProject=".\src\main\java">
<property name="enableSubPackages" value="true" />
javaClientGenerator>
<table tableName="tbl_dept" domainObjectName="Department">table>
<table tableName="tbl_employee" domainObjectName="Employee">table>
context>
generatorConfiguration>
创建mgb工程代码:
@Test
public void testMbg() throws Exception {
List<String> warnings = new ArrayList<String>();
boolean overwrite = true;
File configFile = new File("src/main/resources/mbg.xml");
ConfigurationParser cp = new ConfigurationParser(warnings);
Configuration config = cp.parseConfiguration(configFile);
DefaultShellCallback callback = new DefaultShellCallback(overwrite);
MyBatisGenerator myBatisGenerator = new MyBatisGenerator(config,
callback, warnings);
myBatisGenerator.generate(null);
}
一键生成成功:
测试代码:
@Test
public void selectAll() throws IOException {
SqlSessionFactory sqlSessionFactory = getSqlSessionFactory();
SqlSession sqlSession = sqlSessionFactory.openSession();
EmployeeMapper mapper = sqlSession.getMapper(EmployeeMapper.class);
List<Employee> employees = mapper.selectAll();
employees.forEach(System.out::println);
sqlSession.close();
}
结果:
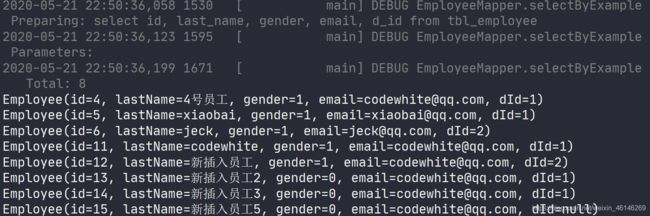
拼装SQL测试:
@Test
public void testmyBatis3() {
SqlSession sqlSession = null;
try {
sqlSession = getSqlSessionFactory().openSession();
EmployeeMapper mapper = sqlSession.getMapper(EmployeeMapper.class);
//xxxExample就是封装查询条件的
//1、查询所有
//List emps = mapper.selectByExample(null);
//2、查询员工名字中有e字母的,和员工性别是1的
//封装员工查询条件的example
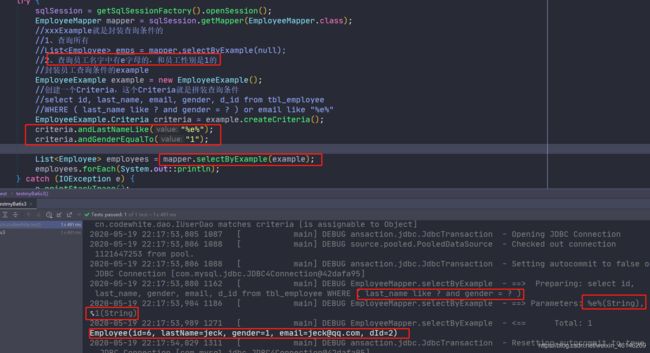
EmployeeExample example = new EmployeeExample();
//创建一个Criteria,这个Criteria就是拼装查询条件
//select id, last_name, email, gender, d_id from tbl_employee
//WHERE ( last_name like ? and gender = ? ) or email like "%e%"
EmployeeExample.Criteria criteria = example.createCriteria();
criteria.andLastNameLike("%e%");
criteria.andGenderEqualTo("1");
List<Employee> employees = mapper.selectByExample(example);
employees.forEach(System.out::println);
} catch (IOException e) {
e.printStackTrace();
} finally {
assert sqlSession != null;
sqlSession.close();
}
结果:
8.1.2 page插件
官方文档:page官方文档
依赖导入:
<dependency>
<groupId>com.github.pagehelpergroupId>
<artifactId>pagehelperartifactId>
<version>5.1.2version>
dependency>
EmployeeMapper:
List<Employee> getEmp();
EmployeeMapper.xml:
<select id="getEmp" resultType="cn.codewhite.pojo.Employee">
select id,last_name,gender,email from tbl_employee
select>
测试代码:
@Test
public void test01() throws IOException {
// 1、获取sqlSessionFactory对象
SqlSessionFactory sqlSessionFactory = getSqlSessionFactory();
// 2、获取sqlSession对象
SqlSession openSession = sqlSessionFactory.openSession();
try {
EmployeeMapper mapper = openSession.getMapper(EmployeeMapper.class);
Page<Object> page = PageHelper.startPage(5, 1);
List<Employee> emps = mapper.getEmp();
//传入要连续显示多少页
PageInfo<Employee> info = new PageInfo<>(emps, 5);
for (Employee employee : emps) {
System.out.println(employee);
}
/*System.out.println("当前页码:"+page.getPageNum());
System.out.println("总记录数:"+page.getTotal());
System.out.println("每页的记录数:"+page.getPageSize());
System.out.println("总页码:"+page.getPages());*/
///xxx
System.out.println("当前页码:" + info.getPageNum());
System.out.println("总记录数:" + info.getTotal());
System.out.println("每页的记录数:" + info.getPageSize());
System.out.println("总页码:" + info.getPages());
System.out.println("是否第一页:" + info.isIsFirstPage());
System.out.println("连续显示的页码:");
int[] nums = info.getNavigatepageNums();
for (int i = 0; i < nums.length; i++) {
System.out.println(nums[i]);
}
//xxxx
} finally {
openSession.close();
}
}
8.1.3 批量插入插件
ExecutorType.BATCH
@Test
public void testBatch() throws IOException{
SqlSessionFactory sqlSessionFactory = getSqlSessionFactory();
//可以执行批量操作的sqlSession
SqlSession openSession = sqlSessionFactory.openSession(ExecutorType.BATCH);
long start = System.currentTimeMillis();
try{
EmployeeMapper mapper = openSession.getMapper(EmployeeMapper.class);
for (int i = 0; i < 10000; i++) {
mapper.addEmp(new Employee(UUID.randomUUID().toString().substring(0, 5), "b", "1"));
}
openSession.commit();
long end = System.currentTimeMillis();
//批量:(预编译sql一次==>设置参数===>10000次===>执行(1次))
//Parameters: 616c1(String), b(String), 1(String)==>4598
//非批量:(预编译sql=设置参数=执行)==》10000 10200
System.out.println("执行时长:"+(end-start));
}finally{
openSession.close();
}
}
整合Spring:
<bean id="sqlSession" class="org.mybatis.spring.SqlSessionTemplate">
<constructor-arg name="sqlSessionFactory" ref="sqlSessionFactoryBean">constructor-arg>
<constructor-arg name="executorType" value="BATCH">constructor-arg>
bean>
8.1.4 插件开发
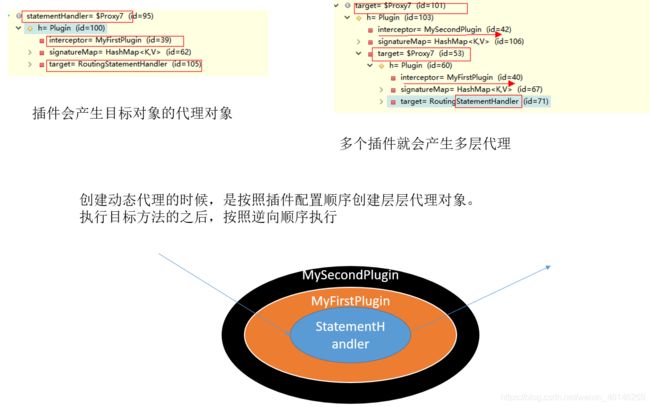

插件原理:在四大对象创建的时候
1、每个创建出来的对象不是直接返回的,而是
interceptorChain.pluginAll(parameterHandler);
2、获取到所有的Interceptor(拦截器)(插件需要实现的接口);
调用interceptor.plugin(target);返回target包装后的对象
3、插件机制,我们可以使用插件为目标对象创建一个代理对象;AOP(面向切面)
我们的插件可以为四大对象创建出代理对象;
代理对象就可以拦截到四大对象的每一个执行;
public Object pluginAll(Object target) {
for (Interceptor interceptor : interceptors) {
target = interceptor.plugin(target);
}
return target;
}
插件编写:
- 编写Interceptor的实现类
- 使用@Intercepts注解完成插件签名
- 将写好的插件注册到全局配置文件中
MyFirstPlugin:
/**
* 完成插件签名:
* 告诉MyBatis当前插件用来拦截哪个对象的哪个方法
*/
@Intercepts(
{ @Signature(type=StatementHandler.class,method="parameterize",args=java.sql.Statement.class)
})
public class MyFirstPlugin implements Interceptor{
/**
* intercept:拦截:
* 拦截目标对象的目标方法的执行;
*/
@Override
public Object intercept(Invocation invocation) throws Throwable {
// TODO Auto-generated method stub
System.out.println("MyFirstPlugin...intercept:"+invocation.getMethod());
//动态的改变一下sql运行的参数:以前1号员工,实际从数据库查询11号员工
Object target = invocation.getTarget();
System.out.println("当前拦截到的对象:"+target);
//拿到:StatementHandler==>ParameterHandler===>parameterObject
//拿到target的元数据
MetaObject metaObject = SystemMetaObject.forObject(target);
Object value = metaObject.getValue("parameterHandler.parameterObject");
System.out.println("sql语句用的参数是:"+value);
//修改完sql语句要用的参数
metaObject.setValue("parameterHandler.parameterObject", 11);
//执行目标方法
Object proceed = invocation.proceed();
//返回执行后的返回值
return proceed;
}
/**
* plugin:
* 包装目标对象的:包装:为目标对象创建一个代理对象
*/
@Override
public Object plugin(Object target) {
// TODO Auto-generated method stub
//我们可以借助Plugin的wrap方法来使用当前Interceptor包装我们目标对象
System.out.println("MyFirstPlugin...plugin:mybatis将要包装的对象"+target);
Object wrap = Plugin.wrap(target, this);
//返回为当前target创建的动态代理
return wrap;
}
/**
* setProperties:
* 将插件注册时 的property属性设置进来
*/
@Override
public void setProperties(Properties properties) {
// TODO Auto-generated method stub
System.out.println("插件配置的信息:"+properties);
}
}
MySecondPlugin :
@Intercepts(
{ @Signature(type=StatementHandler.class,method="parameterize",args=java.sql.Statement.class)
})
public class MySecondPlugin implements Interceptor{
@Override
public Object intercept(Invocation invocation) throws Throwable {
System.out.println("MySecondPlugin...intercept:"+invocation.getMethod());
return invocation.proceed();
}
@Override
public Object plugin(Object target) {
// TODO Auto-generated method stub
System.out.println("MySecondPlugin...plugin:"+target);
return Plugin.wrap(target, this);
}
@Override
public void setProperties(Properties properties) {
// TODO Auto-generated method stub
}
}
全局配置文件注册插件:
<plugins>
<plugin interceptor="com.atguigu.mybatis.dao.MyFirstPlugin">
<property name="username" value="root"/>
<property name="password" value="123456"/>
plugin>
<plugin interceptor="com.atguigu.mybatis.dao.MySecondPlugin">plugin>
plugins>
第九章: 拓展功能
9.1.1 Mybatis调用存储过程
Oracle:创建带游标的储存过程
CREATE OR REPLACE PROCEDURE
hello_test(
p_start IN INT,p_end IN INT,p_count OUT INT,
p_emps OUT sys_refcursor
)AS
BEGIN
SELECT count(*) INTO p_count FROM employees;
OPEN p_emps FOR
SELECT * FROM (SELECT rownum rn,e.* FROM employees e
WHERE rownum <= p_end)
WHERE rn>=p_start;
END hello_test;
关系映射文件:
<select id="getPageByProcedure" statementType="CALLABLE" databaseId="oracle">
{call hello_test(
#{start,mode=IN,jdbcType=INTEGER},
#{end,mode=IN,jdbcType=INTEGER},
#{count,mode=OUT,jdbcType=INTEGER},
#{emps,mode=OUT,jdbcType=CURSOR,javaType=ResultSet,resultMap=PageEmp}
)}
select>
<resultMap type="cn.codewhite.pojo.Employee" id="PageEmp">
<id column="EMPLOYEE_ID" property="id"/>
<result column="LAST_NAME" property="email"/>
<result column="EMAIL" property="email"/>
resultMap>
OraclePage:
@Data
public class OraclePage {
private int start;
private int end;
private int count;
private List<Employee> emps;
}
测试代码:
/**
* oracle分页:
* 借助rownum:行号;子查询;
* 存储过程包装分页逻辑
* @throws IOException
*/
@Test
public void testProcedure() throws IOException{
SqlSessionFactory sqlSessionFactory = getSqlSessionFactory();
SqlSession openSession = sqlSessionFactory.openSession();
try{
EmployeeMapper mapper = openSession.getMapper(EmployeeMapper.class);
OraclePage page = new OraclePage();
page.setStart(1);
page.setEnd(5);
mapper.getPageByProcedure(page);
System.out.println("总记录数:"+page.getCount());
System.out.println("查出的数据:"+page.getEmps().size());
System.out.println("查出的数据:"+page.getEmps());
}finally{
openSession.close();
}
}
9.1.2 自定义类型处理器
环境搭建:sql
ALTER TABLE tbl_employee ADD empStatus INT;
EmpStaus:枚举类
/**
* 希望数据库保存的是100,200这些状态码,而不是默认0,1或者枚举的名
* @create 2020-05-22 9:53
*/
public enum EmpStatus {
LOGIN(100, "用户登陆"), LOGOUT(200, "用户登出"), REMOVE(300, "用户不存在");
private Integer code;
private String msg;
private EmpStatus(Integer code, String msg) {
this.code = code;
this.msg = msg;
}
//getter,setter自行添加
//按照状态码返回枚举对象
public static EmpStatus getEmpStatusByCode(Integer code){
switch (code){
case 100:
return LOGIN;
case 200:
return LOGOUT;
case 300:
return REMOVE;
default:
return LOGOUT;
}
}
}
Employee:
@Data
public class Employee implements Serializable {
private Integer id;
private String lastName;
private String email;
private Integer gender;
//员工状态:
private EmpStatus empStatus = EmpStatus.LOGOUT;
}
自定义的类型处理器:
/**
* 1、实现TypeHandler接口。或者继承BaseTypeHandler
* @author JUNSHI
* @create 2020-05-22 10:01
*/
public class MyEnumEmpStatusTypeHandler implements TypeHandler<EmpStatus> {
/**
* 定义当前数据如何保存到数据库中
*/
@Override
public void setParameter(PreparedStatement ps, int i, EmpStatus parameter, JdbcType jdbcType) throws SQLException {
System.out.println("要保存的状态码:"+parameter.getCode());
ps.setObject(i,parameter.getCode());
}
@Override
public EmpStatus getResult(ResultSet rs, String columnName) throws SQLException {
//需要根据从数据库中拿到的枚举的状态码返回一个枚举对象
int code = rs.getInt(columnName);
System.out.println("从数据库中获取的状态码:"+code);
EmpStatus status = EmpStatus.getEmpStatusByCode(code);
return status;
}
@Override
public EmpStatus getResult(ResultSet rs, int columnIndex) throws SQLException {
int code = rs.getInt(columnIndex);
System.out.println("从数据库中获取的状态码:"+code);
EmpStatus status = EmpStatus.getEmpStatusByCode(code);
return status;
}
@Override
public EmpStatus getResult(CallableStatement cs, int columnIndex) throws SQLException {
int code = cs.getInt(columnIndex);
System.out.println("从数据库中获取的状态码:"+code);
EmpStatus status = EmpStatus.getEmpStatusByCode(code);
return status;
}
}
全局配置文件开启:
<typeHandlers>
<typeHandler handler="cn.codewhite.pojo.MyEnumEmpStatusTypeHandler" javaType="cn.codewhite.pojo.EmpStatus"/>
typeHandlers>
写在后边:
写得不好,若有任何问题可以找我。
以上我学习的资料来源于:百度百科,官方文档,黑马,尚硅谷等