模型融合方法:Voting/Averaging、Stacking、Boosting和Bagging。
一般来说,通过融合多个不同的模型,可能提升机器学习的性能,这一方法在各种机器学习比赛中广泛应用,比如在kaggle上的otto产品分类挑战赛①中取得冠军和亚军成绩的模型都是融合了1000+模型的“庞然大物”。
常见的集成学习&模型融合方法包括:简单的Voting/Averaging(分别对于分类和回归问题)、Stacking、Boosting和Bagging。
-->Voting/Averaging
在不改变模型的情况下,直接对各个不同的模型预测的结果,进行投票或者平均,这是一种简单却行之有效的融合方式。
比如对于分类问题,假设有三个相互独立的模型,每个正确率都是70%,采用少数服从多数的方式进行投票。那么最终的正确率将是:
![]()
即结果经过简单的投票,使得正确率提升了8%。这是一个简单的概率学问题——如果进行投票的模型越多,那么显然其结果将会更好。但是其前提条件是模型之间相互独立,结果之间没有相关性。越相近的模型进行融合,融合效果也会越差。
模型之间差异越大,融合所得的结果将会更好。//这种特性不会受融合方式的影响。注意这里所指模型之间的差异,并不是指正确率的差异,而是指模型之间相关性的差异。
对于回归问题,对各种模型的预测结果进行平均,所得到的结果通过能够减少过拟合,并使得边界更加平滑,单个模型的边界可能很粗糙。这是很直观的性质,随便放张图②就不另外详细举例了。
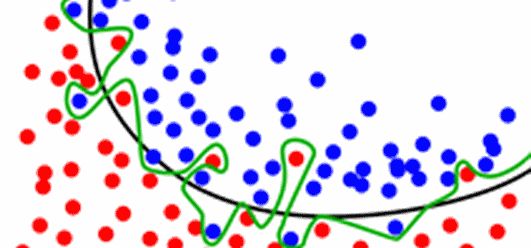
在上述融合方法的基础上,一个进行改良的方式是对各个投票者/平均者分配不同的权重以改变其对最终结果影响的大小。对于正确率低的模型给予更低的权重,而正确率更高的模型给予更高的权重。这也是可以直观理解的——想要推翻专家模型(高正确率模型)的唯一方式,就是臭皮匠模型(低正确率模型)同时投出相同选项的反对票。具体的对于权重的赋值,可以用正确率排名的正则化等。
这种方法看似简单,但是却是下面各种“高级”方法的基础。
-->Boosting
Boosting是一种将各种弱分类器串联起来的集成学习方式,每一个分类器的训练都依赖于前一个分类器的结果,顺序运行的方式导致了运行速度慢。和所有融合方式一样,它不会考虑各个弱分类器模型本身结构为何,而是对训练数据(样本集)和连接方式进行操纵以获得更小的误差。但是为了将最终的强分类器的误差均衡,之前所选取的分类器一般都是相对比较弱的分类器,因为一旦某个分类器较强将使得后续结果受到影响太大。所以多用于集成学习而非模型融合(将多个已经有较好效果的模型融合成更好的模型)。
这里引用知乎专栏 《【机器学习】模型融合方法概述》③处引用的加州大学欧文分校Alex Ihler教授的两页PPT:

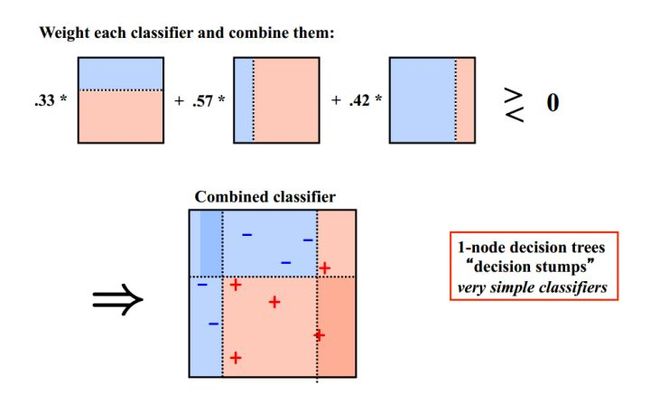
其基本工作机制如下:
1、从初始样本集中训练出一个基学习器;
2、根据基学习器的表现对样本集分布进行调整,使得做错的样本能在之后的过程中受到更多的关注;
3、用调整后的样本集训练下一个基学习器;
4、重复上述步骤,直到满足一定条件。
注意,一般只有弱分类器都是同一种分类器(即同质集成)的时候,才将弱分类器称为基学习器,如果是异质集成,则称之为个体学习器。由于不是本文重点,所以此处不作区分。特此说明。
最终将这些弱分类器进行加权相加。
常见的Boosting方法有Adaboost、GBDT、XGBOOST等。 //下面仅从思想层次上简单介绍各种方法,具体的算法推理公式推导以及可用的工具包等参考本文附录。
-->Bagging
Bagging是Bootstrap Aggregating的缩写。这种方法同样不对模型本身进行操作,而是作用于样本集上。采用的是随机有放回的选择训练数据然后构造分类器,最后进行组合。与Boosting方法中各分类器之间的相互依赖和串行运行不同,Bagging方法中基学习器之间不存在强依赖关系,且同时生成并行运行。
其基本思路为:
1、在样本集中进行K轮有放回的抽样,每次抽取n个样本,得到K个训练集;
2、分别用K个训练集训练得到K个模型。
3、对得到的K个模型预测结果用投票或平均的方式进行融合。
在这里,训练集的选取可能不会包含所有样本集,未被包含的数据成为包/袋外数据,可用来进行包外误差的泛化估计。每个模型的训练过程中,每次训练集可以取全部的特征进行训练,也可以随机选取部分特征训练,例如极有代表性的随机森林算法就是每次随机选取部分特征。
下面仅从思想层面介绍随机森林算法:
1、在样本集中进行K轮有放回的抽样,每次抽取n个样本,得到K个训练集,其中n一般远小于样本集总数;
2、选取训练集,在整体特征集M中选取部分特征集m构建决策树,其中m一般远小于M;
3、在构造每棵决策树的过程中,按照选取最小的基尼指数进行分裂节点的选取进行决策树的构建。决策树的其他结点都采取相同的分裂规则进行构建,直到该节点的所有训练样例都属于同一类或者达到树的最大深度;
4、重复上述步骤,得到随机森林;
5、多棵决策树同时进行预测,对结果进行投票或平均得到最终的分类结果。
多次随机选择的过程,使得随机森林不容易过拟合且有很好的抗干扰能力。
-->Boosting与Bagging的比较④
优化方式上>
在机器学习中,我们训练一个模型通常是将定义的Loss最小化的过程。但是单单的最小化loss并不能保证模型在解决一般化的问题时能够最优,甚至不能保证模型可用。训练数据集的Loss与一般化数据集的Loss之间的差异被称为generalization error。
![]()
Variance过大会导致模型过拟合,而Bias过大会使得模型欠拟合。
Bagging方法主要通过降低Variance来降低error,Boosting方法主要通过降低Bias来降低error。
Bagging方法采用多个不完全相同的训练集训练多个模型,最后结果取平均。由于
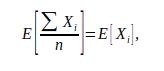
所以最终结果的Bias与单个模型的Bias相近,一般不会显著降低Bias。
另一方面,对于Variance则有:
Bagging的多个子模型由不完全相同的数据集训练而成,所以子模型间有一定的相关性但又不完全独立,所以其结果在上述两式的中间状态。因此可以在一定程度上降低Variance从而使得总error减小。
Boosting方法从优化角度来说,是用forward-stagewise这种贪心法去最小化损失函数

是前n步得到的子模型的和。因此Boosting在最小化损失函数,Bias自然逐步下降,而由于模型间强相关,不能显著降低Variance。
Bagging里面每个分类器是强分类器,因为他降低的是方差,方差过高需要降低是过拟合。
boosting里面每个分类器是弱分类器,因为他降低的是偏差,偏差过高是欠拟合。
样本选择上>
Bagging:训练集是在原始集中有放回选取的,从原始集中选出的各轮训练集之间是独立的。
Boosting:每一轮的训练集不变,只是训练集中每个样例在分类器中的权重发生变化。而权值是根据上一轮的分类结果进行调整。
样例权重>
Bagging:使用均匀取样,每个样例的权重相等
Boosting:根据错误率不断调整样例的权值,错误率越大则权重越大
预测函数>
Bagging:所有预测函数的权重相等。
Boosting:每个弱分类器都有相应的权重,对于分类误差小的分类器会有更大的权重
并行计算>
Bagging:各个预测函数可以并行生成
Boosting:理论上各个预测函数只能顺序生成,因为后一个模型参数需要前一轮模型的结果。计算角度来看,两种方法都可以并行。bagging,random forest并行化方法显而意见。boosting有强力工具stochastic gradient boosting
-->Stacking
“Here be dragons. With 7 heads. Standing on top of 30 other dragons. ”
接下来介绍在各种机器学习比赛中被誉为“七头龙神技”的Stacking方法。
(但因其模型的庞大程度与效果的提升程度往往不成正比,所以一般很难应用于实际生产中)
下面以一种易于理解但不会实际使用的两层的stacking方法为例,简要说明其结构和工作原理:(这种模型问题将在后续说明)
假设我们有三个基模型M1,M2,M3,用训练集对其进行训练后,分别用来预测训练集和测试集的结果,得到P1,T1,P2,T2,P3,T3
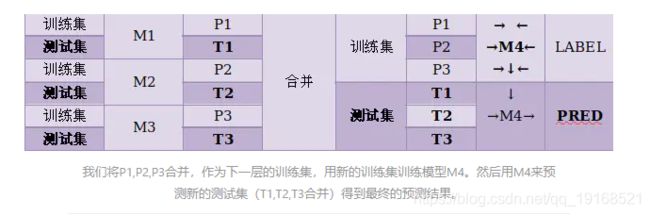
这种方法的问题在于,模型M1/2/3是我们用整个训练集训练出来的,我们又用这些模型来预测整个训练集的结果,毫无疑问过拟合将会非常严重。因此在实际应用中往往采用交叉验证的方法来解决过拟合问题。
首先放几张图⑤,我们着眼于Stacking方法的第一层,以5折交叉验证为例说明其工作原理:
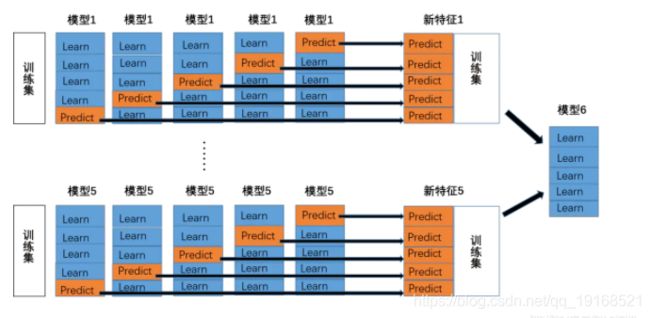
1、首先我们将训练集分为五份。
2、对于每一个基模型来说,我们用其中的四份来训练,然后对未用来的训练的一份训练集和测试集进行预测。然后改变所选的用来训练的训练集和用来验证的训练集,重复此步骤,直到获得完整的训练集的预测结果。
3、对五个模型,分别进行步骤2,我们将获得5个模型,以及五个模型分别通过交叉验证获得的训练集预测结果。即P1、P2、P3、P4、P5。
4、用五个模型分别对测试集进行预测,得到测试集的预测结果:T1、T2、T3、T4、T5。
5、将P1~5、T1~5作为下一层的训练集和测试集。在图中分别作为了模型6的训练集和测试集。

Stacking方法的整体结构如下图所示:

-->Blending
Blending是一种和Stacking很相像的模型融合方式,它与Stacking的区别在于训练集不是通过K-Fold的CV策略来获得预测值从而生成第二阶段模型的特征,而是建立一个Holdout集,例如10%的训练数据,第二阶段的stacker模型就基于第一阶段模型对这10%训练数据的预测值进行拟合。
说白了,就是把Stacking流程中的K-Fold CV 改成HoldOut CV。
以第一层为例,其5折HoldOut交叉验证将如下图③所示:

需要注意的是,网上很多文章在介绍Stacking的时候都用了上面Blending的图还强行解释了的,比如③、⑤等。
Stacking与Blending相比,Blending的优势在于:
1、Blending比较简单,而Stacking相对比较复杂;
2、能够防止信息泄露:generalizers和stackers使用不同的数据;
3、不需要和你的队友分享你的随机种子;
而缺点在于:
1、只用了整体数据的一部分;
2、最终模型可能对留出集(holdout set)过拟合;
3、Stacking多次交叉验证要更加稳健。
文献②中表示两种技术所得的结果都相差不多,如何选择取决于个人喜好。如果难以抉择的话,可以同时使用两种技术并来个第三层将其结果合并起来。
【参考文献】
①https://www.kaggle.com/c/otto-group-product-classification-challenge
②https://mlwave.com/kaggle-ensembling-guide/
③https://zhuanlan.zhihu.com/p/25836678
④https://blog.csdn.net/Mr_tyting/article/details/72957853
⑤https://blog.csdn.net/data_scientist/article/details/78900265
⑥https://mlwave.com/human-ensemble-learning/
⑦https://blog.csdn.net/sinat_29819401/article/details/71191219
⑧https://blog.csdn.net/zwqjoy/article/details/80431496
⑨http://lib.csdn.net/article/machinelearning/35135