An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale——ViT
文章目录
-
- 摘要
- Introduction
- 相关工作
- 方法
-
- Vision Transformer(ViT)
- Fine-Tuning and Higher Resolution(微调和高分辨率)
- 实验
-
- Setup(实验设置)
- Comparison to State of The Art
- Pre-training data requirements
- Scaling Study(扩展研究)
- Inspecting Vision Transformer
- Self-Supervison
- 结论
- Reference
论文:https://arxiv.org/abs/2010.11929
Code:https://github.com/google-research/vision_transformer
timm:https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/vision_transformer.py
Publish:ICLR2021
摘要
Transformer架构已经称为自然语言处理(NLP)任务事实上的标准,但在计算机视觉(CV)领域应用仍然很有限。在视觉领域,Attention(注意力)要么与卷积网络结合使用,要么在保持卷积网络的整体结构下替换其某些组件。该文证明了依赖CNN是不必要的,一个单纯的Transformer可以直接应用于Image patches序列,很好的执行图像分类任务。当在大规模数据上进行预训练之后,然后迁移到中等规模或小规模图像识别基准上(ImageNet,CIFAR-100,VTAB等),同卷积网络的SOTA相比,Vision Transformer(VIT) 获得了更好的结果,并且训练需要的计算资源更少。
Introduction
基于self-attention的架构,尤其是Transformer1,已经称为NLP任务的首选模型。主要的方法是在大型文本语料库上进行预训练,然后再特定的较小的数据集上进行微调。由于Transformer的计算效率核可伸缩性,已经有可能训练出超过100B参数的超大规模模型,并且随着模型核数据集的增长,仍然没有性能饱和的迹象。
然而,在计算机视觉领域,卷积神经网络一致占据主导地位。受到NLP领域的成功,许多工作尝试将CNN架构同self-attention结合起来,而有一些则完全取代了卷积。这种完全替代卷积的模型虽然在理论上是有效的,但因为使用了专门的attention pattern,并没有在现代硬件加速器上得到有效扩展。因此,在大规模图像识别中,经典的ResNet架构仍然是SOTA。
受到Transformer在NLP上的成功拓展,我们尝试将标准Transformer直接应用于图像,尽可能不做修改。为此,我们把Image分割为patches,并将这些patches的线性嵌入序列作为Transformer的输入。Image patches与 NLP应用程序中的tokens(words)同等对待。然后用有监督方式对该模型进行图像分类训练。
在没有强正则化的中型数据集(比如ImageNet)上训练时,这些模型的精确度比同等规模的ResNet略低几个百分点。这看似令人沮丧的结果是意料之中的:Transformer缺乏CNNs架构固有的inductive biases,比如平移不变性和局部性,因此在数据量不足的情况下无法很好的泛化。
然而,如果模型在更大的数据集(14M-300M images)上训练,则图像就会发生变化。我们发现大规模训练要胜过inductive bias。我们的Vision Transformer (ViT)在足够规模上进行预训练并迁移到具有较少数据点任务时,仍可以获得优异结果。当在ImageNet-21k或JFT-300M数据集上进行预训练时,VIT在多个图像识别基准上接近或超过了SOTA。其中,最好的模型在ImageNet上达到了88.55%的准确率,在ImageNet-Real上达到90.72%的准确率,在CIFAR-100上达到94.55%的准确率,在19个任务的VTAB suite上达到77.63%。
相关工作
Transformer是在2017年提出被用于机器翻译,之后在许多NLP任务中取得了SOTA。Large Transformer-based 模型通常在大型语料库上进行预训练,然后针对具体任务进行微调:BERT2 就是使用denoising self-supervised pre-training task(去噪自监督预训练任务),而GPT工作先使用语言建模作为其预训练任务。
将self-attention应用到image的应用需要每个像素都关注到其他像素。 由于像素数量的quadratic cost(二次代价函数),这不能扩展到实际的输入大小。因此,为了在图像处理环境中应用Transformer,尝试了几种近似方法。Parmar et al.(2018)3 对于每个查询像素,仅在局部而非在全局应用self-attention。在不同的工作领域,Sparse Transformers(Child et al,2019)4使用global self-attention的近似收缩以便将其应用于图像。
许多这种专门的attention架构在CV任务上展示了不错的结果,但需要在硬件加速器上实现复杂的工程。
将CNNs与self-attention结合也引起了人们很大的兴趣,比如通过增加特征图用于图像分类或者用self-attention进一步处理CNN的输出用于目标检测,视频处理,图像分类、无监督目标发现、统一文本-视觉任务等。
另一个相关的模型是Image GPT(iGPT) 5 ,其是在降低图像分辨率和色彩空间后将Transformer应用于image pixels(图像像素)。该模型以无监督方式训练产生为生成式模型,然后对结果表示进行微调或线性探测以提高分类性能,并且在ImageNet上达到了72%的准确率。
我们的工作中涵盖了许多论文,这些论文探索了比标准ImageNet更大的图像识别数据集,额外数据的使用有助于实现在标准benchmarks上实现SOTA。而且,Sun et al.(2017)6 研究了CNN性能如何随数据集大小而变化,Kolesnikov et al.(2020)7、Djolonga et al.(2020)8探索了大规模数据集(ImageNet-21k和JFT-300M)上的CNN迁移学习。我们也比较关注这两个数据集,但是训练Transformer而不是之前工作中的ResNet-based模型。
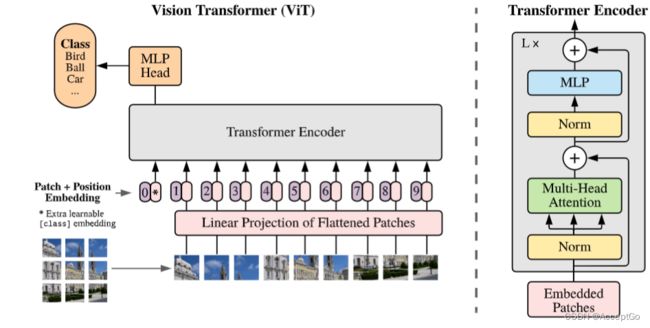
图一:模型概览。分割图像为固定大小的patches,线性嵌入每个块,添加position embeddings(位置嵌入),将得到的向量序列作为标准Transformer encoder的输入,为执行分类任务,使用一种标准方法:添加一个额外科学系的classification token到序列中
方法
在模型设计上,尽可能遵循了原本的Transformer,这种可以简单设置的一个优点就是可扩展的NLP Transformer架构其高效的实现几乎可以开箱即用。
Vision Transformer(ViT)
图一描述了模型的概述。标准Transformer接收token embeddings的1D序列作为输入。为处理2D图像,我们重塑图像 x ∈ R H × W × C x \in R^{H \times W \times C} x∈RH×W×C 为flattened 2D patches x p ∈ R N × ( P 2 ⋅ C ) x_p \in R^{N \times(P^2 \cdot C)} xp∈RN×(P2⋅C),其中, ( H , W ) (H,W) (H,W) 是原始图像的分辨率, C C C 是通道数, ( P , P ) (P,P) (P,P) 是每个 i m a g e p a t c h image patch imagepatch 的分辨率,并且 N = H W / P 2 N=HW/P^2 N=HW/P2是分割后的patches的数量,同时也是Transformer的有效输入序列长度。Transformer在所有层中使用恒定大小为 D D D 的向量,因此我们flatten the patches(平铺patches)并且用一个可训练的线性投影映射到 D D D 维(等式(1)),该投影的输出作为patch embeddings。
类似于BERT's的 [class] token,我们在embedded patches ( z 0 0 = x c l a s s ) (z_0^0=x_{class}) (z00=xclass)前添加了一个可学习的embedding,它在Transformer encoder z L 0 z_L^0 zL0 输出处的状态作为图像表示 y y y(等式(4))。在预训练和微调期间,classification head连接到 z L 0 z_L^0 zL0。classification head是在预训练时由一个带有单个隐藏层的MLP实现的,其在微调期间由单个linear layer(线性层)实现。
Postion embeddings被添加到patch embeddings来保留位置信息。我们使用标准科学系的1D position embeddings(一维位置嵌入),因为我们没有观察到使用更高级的2D-aware position embeddings可以带来显著的性能提升。然后将embedding vectors(嵌入向量)序列作为enconder的输入。
Transformer encoder由multiheaded self-attention(MSA)和MLP blocks(等式(2)、(3))组成。Layernorm(LN)(批量归一层)被应用于每个block之前,residual connection(残差连接)在每个block之后。MLP包含两个GELU non-linearity层。
z 0 = [ x c l a s s ; x p 1 E ; x p 2 E ; . . . ; x p N E ] + E p o s , E ∈ R ( p 2 ⋅ C ) × D , E p o s ∈ R N + 1 × D 等 式 ( 1 ) z l ′ = M S A ( L N ( z l − 1 ) ) + z l − 1 l = 1... L 等 式 ( 2 ) z l = M L P ( L N ( z l ′ ) ) + z l ′ l = 1... L 等 式 ( 3 ) y = L N ( z L 0 ) 等 式 ( 4 ) z_0=[x_{class};x_p^1E;x_p^2E;...;x_p^NE]+E_{pos}, \quad E \in R^{(p^2 \cdot C) \times D},E_{pos} \in R^{N+1} \times D \quad \quad 等式(1) \\ z_l'=MSA(LN(z_{l-1}))+z_{l-1} \quad\quad\quad \quad l=1...L \quad\quad\quad 等式(2)\\ z_l=MLP(LN(z_l'))+z_l' \quad\quad\quad \quad\quad\quad l=1...L \quad\quad\quad 等式(3)\\ y=LN(z_L^0) \quad\quad\quad \quad\quad\quad \quad\quad\quad \quad\quad\quad \quad\quad\quad \quad\quad\quad 等式(4)\\ z0=[xclass;xp1E;xp2E;...;xpNE]+Epos,E∈R(p2⋅C)×D,Epos∈RN+1×D等式(1)zl′=MSA(LN(zl−1))+zl−1l=1...L等式(2)zl=MLP(LN(zl′))+zl′l=1...L等式(3)y=LN(zL0)等式(4)
Inductive bias(归纳偏置)。 Vision Transformer与CNNs相比,其image-specific inductive bias更弱。在CNN中,locality(局部性)、two-dimensional neighborhood (二维邻域)结构以及translation equivariance (平移不变性)贯穿于整个模型的每一层中。在VIT 中,只有MLP层具备local and translationally equivariant(局部性和平移不变性),但self-attention层是全局具备的。two-dimensional neighborhood结构的使用很少:在模型开始时,将image裁剪为patches,在模型微调时,调整不同分辨率图像的position embeddings。此外,初始化时的position embeddings不含有patches的2D positions的信息,并且patches间的spatial relations(空间关系)都要从0开始学习。
Hybrid Architecture(混合架构)。作为原始image patches的替代,输入序列可以由CNN的feature maps(特征图)形成。在这个混合模型中,patch embedding projection E(等式(1))被应用于从CNN feature map提取出来的patches。作为特例,patches的spatial size可以为 1 × 1 1 \times 1 1×1 ,这意味着只需要flattening feature map(特征图)的spatial dimensions并且映射到Transformer维度就可以得到输入序列。
Fine-Tuning and Higher Resolution(微调和高分辨率)
典型地,我们在大规模数据集上预训练ViT,然后在小数据集(或下游任务)上微调。为此,我们移除到了预训练的prediction head(预测头)并添加了一个零初始化的 D × K D \times K D×K 的前馈层,其中, K K K 是downstream classes(下游类别)的数量。与预训练前相比,以更高的分辨率进行微调是更有益的。当馈送分辨率较高的图像时,保持patch size不变,从而可以产生更长更有效的序列长度。Vision Transformer可以处理任意长度序列(受限于内存大小),然而,这时,预训练的position embeddings或许不再有意义。因此,我们根据它们在原始图像中的位置,执行预训练position embeddings的2D interpolation(2D内插)。注意到,该分辨率调整和patch 提取是关于图像2D结构的inductive bias手动注入到Vision Transformer的唯一点。
实验
实验评估了ResNet、Vision Transformer(ViT)、hybrid(混合)的表征学习能力。为了解每个模型的数据需求,我们在不同大小的数据集上进行预训练,并评估许多benchmark task(基准任务)。当考虑预训练模型的计算成本时,ViT表现非常出色以较低的预训练成本在大多数识别基准上取得了SOTA。最后我们做了一个自监督的小型实验,表明了自监督ViT未来的前景。
Setup(实验设置)
Dataset。 为探索模型可伸缩性,我们使用ILSVRC-2012 ImageNet dataset ,其中有1k种类别和1.3M的images。它的超集ImageNet-21k有21k种类别和14M的images。JFT有18k种类别和303M高分辨率图像。我们对预训练使用的数据集进行了去重操作,以下是下游任务的测试集。我们迁移在这些数据集上训练过的模型到几个基准任务中:原始验证标签上和清理后的真实标签的ImageNet、CIFAR-10/100、Oxford-IIIT Pets、Oxford Flowers-102。

我们也评估了包含19-task VTAB的分类套件,VTAB对不同任务的low-data迁移进行评估,每个任务使用1000个训练样例。任务分为三个groups:
- Natural——任务如,Pets、CIFAR
- Specialized——医学和卫星图像
- Structured——任务需要了解几何知识
Model Variants(模型变体)。ViT配置基于BERT的配置,如表1所示。"Base"和"Large"模型直接采用BERT模型配置,我们添加了"Huge"模型。下面内容中,我们使用简明符号来表示模型大小和输入patch size。例如,ViT-L/16指的是patch size为 16 × 16 16 \times 16 16×16 的Large模型变体。Transformer的序列长度与patch size的平方成反比,因此patch size较小的模型计算成本更高。
对于基线CNNs,我们用ResNet,但使用Group Normalization(组归一化)替换Batch Normalization(批量归一化),并使用标准化卷积。这些修改提升了迁移,将修改后的模型称之为ResNet(BiT)。对于混合体,我们将中间特征图馈送到一个像素的patch size的ViT。为了试验不同的序列长度,我们可以选择(1)去常规ResNet50阶段4的输出(2)移除阶段4,用阶段3相同数量的层数替代,然后取出这个扩展的阶段3的输出。选择(2)会导致序列长度增加4倍,并且ViT模型成本更高。
Training & Fine-tuning(训练和微调) 。训练所有的模型,包括ResNets ,使用的是Adam,其中 β 1 = 0.9 , β 2 = 0.999 , b a t c h s i z e = 4096 , w e i g h t d e c a y = 0.1 \beta_1=0.9,\beta_2=0.999,batch_size=4096,weight_decay=0.1 β1=0.9,β2=0.999,batchsize=4096,weightdecay=0.1,这对所有模型的迁移是有用的,并且使用线性学习率来warmup and decay(预热和衰变)。在微调期间,使用待用动量的SGD,其中,batch_size=512。对于表2中的ImageNet 的结果,我们使用高分辨率图像进行微调:512 for ViT-L/16和 518 for ViT-H/14,并且平均系数为0.9999。
Metrics(指标)。通过few-shot或者fine-tuning在下游任务数据集记录准确率。微调准确度是在数据集上进行微调之后捕获每个模型的性能。Few-shot准确率是通过解决最小二乘回归问题映射训练图像子集的表示到 { − 1 , + 1 } K \{-1,+1\}^K {−1,+1}K目标向量上。这个公式使我们可以以封闭形式恢复精确解。尽管我们主要关注微调性能,但我们有时使用线性few-shot准确率来进行快速动态评估,但这种情况下,微调的成本很高。
Comparison to State of The Art
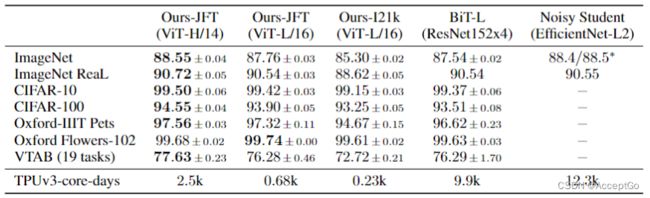
首先比较最大的模型——ViT-H/14和ViTal-L/6同CNN的SOTA。第一个比较点是Big Transfer(BIT),它使用Large ResNets执行监督迁移学习。第二个是Noisy Student,这是使用ImageNet和JFT-300M并去除label进行半监督学习的大型EfficientNet。当前,Noisy Student是ImageNet和BiT-L上等其他数据集上的SOTA。所有的模型使用TPUv3进行训练,记录每个模型预训练TPUv3-core-days,也就是TPUv3 cores的数量乘以以天为单位的训练时长。
表2是结果。在JFT-300M预训练的smaller ViT-L/16性能要由于在其他任务上的BiT-L,同时训练需要的计算资源更少。对于大模型:ViT-H/14进一步提高了性能,尤其是在ImageNet、CIFAR-100和VTAB suite。与之前的SOTA相比,这个模型预训练需要的计算量仍少的多。然而我们注意到,预训练的效率可能不仅受架构选择、也受其他参数的影响,比如training schedule(训练计划)、optimizer(优化器)、weight decay(权重衰减)等。在4.4节中,我们提供了不同架构的性能比较。在ImageNet-21k数据集上预训练的ViT-L/16在大多数其他数据集也表现很好,同时预训练所需资源更少,它可以在大约30天内使用8核的标准云TPUv3进行训练。
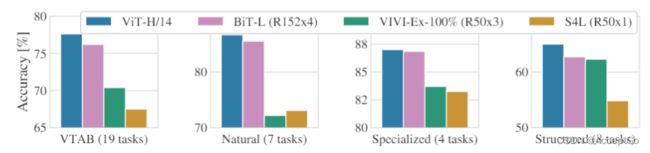
Pre-training data requirements
ViT在大型JFT-300M数据集上预训练表现很好。优于对vision的inductive bias比ResNet更小,则数据集的大小就很重要。为此,做了一些列实验。
首先,在数据集大小渐增的数据集上进行预训练:ImageNet、ImageNet-21k、JFT-300M。为提升在小数据集上的性能,优化了三个基本正则化参数:weight decay、dropout、label smoothing(标签平滑)。图三展示了在ImageNet上微调后的结果。当在最小的数据集ImageNet上预训练时,尽管有适当的正则化,但ViT-Large模型的表现仍不如ViT-Base模型。在ImageNet-21k上预训练时,它们的表现相似。只有在JFT-300M预训练时,larger model才有更好的表现。图三也展示了不同大小的BiT模型所跨越的性能区域。BiT CNNs在ImageNet表现上优于ViT,但在更大数据集上,ViT表现更好。
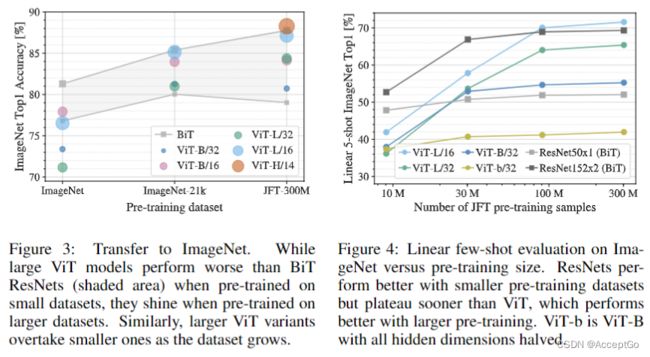
其次,我们在9M、30M和90M的随机子集以及完整的JFT-300M数据集上训练我们的模型。我们不对较小的子集执行额外的正则化,并且在所有设置中使用相同的超参数。这样,我们评估的是模型属性,而非是正则化的影响。然而,确实使用了early-stopping,并且记录了在训练期间获得的最佳验证准确性。ViT在较小的数据集比ResNet更容易过拟合,且两种模型计算成本相当。例如,ViT-B/32比ResNet50略快,但在9M子集上表现很差,而在90M+子集中表现更好。ResNet152x2 和ViT-L/16也是如此。这个结果强化了卷积inductive bias对于较小的数据集是有用的直觉,但对于较大的数据集,直接从数据中学习相关模式就足够。
Scaling Study(扩展研究)
通过评估JFT-300M的迁移性能,我们对不同模型进行了可控扩展研究。在这种设置下,数据大小不会影响模型的性能,并且评估每个模型的预训练成本和性能。模型集包括:7种ResNets、R50x1、R50x2 R01x1、R152x2预训练7个epoches。 R152x2和R200x3预训练14个epoches。6种ViT、ViT-B/32、B/16、L/32、L/16预训练7个epoches,L/16、H/14预训练14个epoches。并且5种混合模型R50+ViT-B/32、B/16、L/32、L/16预训练7个epoches,R50+ViT-L/16预训练14个epoches。
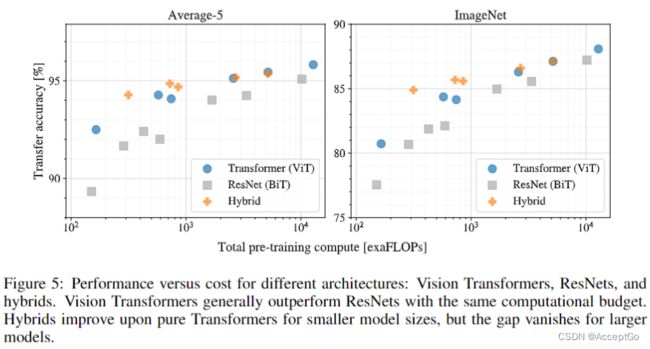
图5包含了总的预训练计算与迁移性能的比较。可以观察到一些模式。首先,ViT在性能/计算量方面占据主导。ViT使用大约2-4倍的计算量获得相同的性能。第二,在较小的计算预算下,混合模型性能略优于ViT,但对于大模型,这种差异就不存在了。
Inspecting Vision Transformer
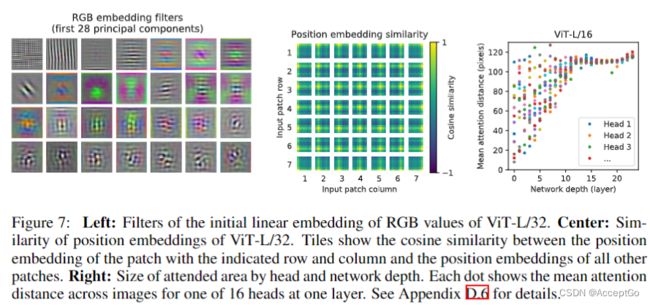
为了理解ViT如何处理图像数据,我们分析了它的内部表示。ViT的第一层线性映射flattened patches到低维空间(等式1)。图7展示了学习的embedding filters的顶部主要部件。这些组件类似于每个 patch微调结构的低维表示的偏差函数。
在映射之后,学习到的postion embedding添加到patch表示中。从图7可以看出,模型学习到在图像postion embedding的相似处进行距离编码。越近的patches往往有更多相似的position embedding。此外,还存在row-column结构,在相同的raw/column中,有类似的embedding。position embeddings学习到2D 图像的拓扑表示,这解释了为什么人工2D-aware embedding变体不会有所改善。
self-attention可以整合整个image的信息,即使是在最低层。我们研究了网络在多大程度上可以利用这种能力,特别地,根据注意力权重计算图像空间中集成的信息的平均距离(图7右)。该attention distance类似于CNNs的感受野大小。我们发现,一些heads关注的是最底层的大部分图像,这表明模型确实具备全局信息的整合能力。其他的注意力头在低层的attention distance一直很小。在Transformer之前,应用ResNet的混合模型中,这种高度局部的attention不太明显。这表明它可能具有类似CNN卷积层的功能。而且,attention distance随网络深度增加而增加。在全局上,我们发现模型关注与分类语义相关的图像区域(图6)。

Self-Supervison
Transformer在NLP任务上的表现令人兴奋。然而,它们的成功不仅依赖于其可扩展性也依赖于大规模自监督预训练。我们也模拟BERT中使用的masked language modeling(遮蔽语言模型)任务,对self-supervision(自监督)masked patch进行了探索。通过自监督预训练,更小的ViT-B/16模型在ImageNet上达到了79.9%的准确率,比从头开始训练提高了2%,但仍比监督学习预训练低4%。
结论
文中探索了Transformer在图像识别中的直接应用。不同之前在CV领域使用self-attention,除了最初的patch提取,不会在模型架构中引入image-specific inductive bias。相反,我们把image解释为一个patches序列,并使用NLP中使用的标准Transformer encoder来对patches进行处理。当在大型数据集上预训练时,这种简单可扩展的策略很好。因此,ViT在许多图像分类数据集上超过了SOTS,而且其训练成本相对较低。
· ViT的表现很好,但仍存在许多挑战,第一,将ViT应用于其他CV任务,比如检测和分割。另一个挑战是继续探索自监督预训练方法。最初的实验表明,自监督预训练的效果有所改善,但和大规模监督预训练仍存在很大差距。最后,ViT的进一步扩展,可能会提高其性能。