CVPR 2022 | 清华大学提出首个细粒度动作质量评估数据集—FineDiving

©作者 | 徐婧林
单位 | 清华大学博士后
研究方向 | 视频理解
在这里和大家分享一下我们被录用为 CVPR 2022 Oral 的工作。

论文标题:
FineDiving: A Fine-grained Dataset for Procedure-aware Action Quality Assessment
作者单位:
清华大学
收录会议:
CVPR 2022 Oral
论文链接:
https://arxiv.org/pdf/2204.03646.pdf
代码链接:
https://github.com/xujinglin/FineDiving

简介
竞技体育视频理解已成为计算机视觉领域的热门研究课题。作为理解体育动作的关键技术之一,动作质量评估(AQA)近年来受到越来越多的关注。在 2020 年东京奥运会的体操比赛项目中,AI 评分系统不仅能对运动员的表现进行打分,以减少在跳水、体操等诸多主观评分项目得分的争议,还能通过反馈动作质量来提高运动员的竞技水平。
AQA 通过分析视频中动作的表现来评估动作的执行质量。与传统的动作识别不同,AQA 更具有挑战性:动作识别可以从一张或几张图像中识别一个动作,AQA 则需要遍历整个动作序列来评估动作的质量。现有的大多数 AQA 方法都是通过视频的深度特征来回归不同的动作质量得分,然而,在相似背景下评估差异很小的不同动作之间的质量是很困难的。
例如,跳水比赛通常都是在水上运动中心拍摄的,并且视频中所有运动员都执行相同的动作程式:起跳、空中动作、入水。这些动作程式的细微差别主要体现在执行空中动作时,运动员翻腾转体的周数、空中姿势以及入水情况(e.g., 水花大小)。
捕捉这些细微的差异需要 AQA 方法不仅能够解析跳水动作的各个步骤,还要明确量化这些步骤的动作执行质量。如果我们仅通过整个视频的深度特征来回归动作得分,考虑到现有的 AQA 数据集缺少对动作过程的细粒度注释,我们无法分析各个动作步骤的执行情况、解释最终得分,那么这种评估方式是不清晰不透明的。因此,我们构建一个细粒度的竞技体育视频数据集,助力设计一种更可靠、更透明的评分方式,迈向可解释的 AQA。
我们构建的数据集“FineDiving”(Fine-grained Diving 的缩写)专注于各种跳水赛事,这是第一个用于 AQA 的细粒度视频数据集。FineDiving 包含如下特性:
1)两层语义结构。所有视频都在两个 level 上进行语义标注,即动作类型(action Type)和子动作类型(sub-action Type),其中,不同的 action types 由不同的 sub-action types 组合生成;
2)两层时序结构。每个视频中的动作实例都标注了时间边界,并且根据定义好的字典将其分解为连续的步骤(steps);
3)来自国际泳联的官方跳水得分(dive score)、裁判分数、难度系数。如图(1)所示。基于 FineDiving,我们进一步提出一种基于过程感知(procedure-aware)的 AQA 方法来评估动作质量。所提出的框架通过构建新的时间分割注意模块(Temporal Segmentation Attention,TSA)学习过程感知嵌入,以实现具有更好可解释性的可靠评分。

▲(1)An overview of the FineDiving dataset and procedure-aware action quality assessment approach.

FineDiving数据集
我们收集了奥运会、世界杯、世锦赛以及欧锦赛的跳水项目比赛视频。每个比赛视频都提供了丰富的内容,包括所有运动员的跳水记录、不同视角的慢速回放等。
我们构建了一个两层语义结构(如图(2)),作为字典来标注动作级标签和步骤级标签。动作级标签(action-level labels)描述了运动员的动作类型(action types),步骤级标签(step-level labels)刻画了动作过程中连续步骤的子动作类型(sub-action types),其中,每个动作过程中的相邻步骤(steps)属于不同的 sub-action types。
例如,action type“5255B”,由 sub-action types 分别为“Back”、“2.5 Somersaults Pike”以及“2.5 Twists”的 steps 按顺序执行。此外,我们构建了一个两层时间结构(如图(3)),action-level labels 标注了每个运动员执行一个完整动作实例的时间边界(在此注释过程中,丢弃所有不完整的动作实例并过滤掉慢速播放)。Step-level labels 标注了动作过程中连续步骤的起始帧。例如,action type 为“5152B”的动作实例,它的连续步骤的起始帧分别为 18930、18943、18957、18967 和 18978。
▲(2)Two-level semantic structure.

▲(3)Two-level temporal structure.
给定一个原始的跳水视频,annotator 利用我们定义好的 lexicon 来标注每个动作实例及其过程。我们完成了从粗粒度到细粒度的两个注释阶段:粗粒度阶段标注每个动作实例的 action type 及其时间边界和得分,细粒度阶段标注动作过程中每个 step 的 sub-action type 以及它的起始帧。
FineDiving 数据集包含 3000 个样本,涵盖 52 种 action types、29 种 sub-action types 以及 23 种难度难度系数,如图(4)所示。
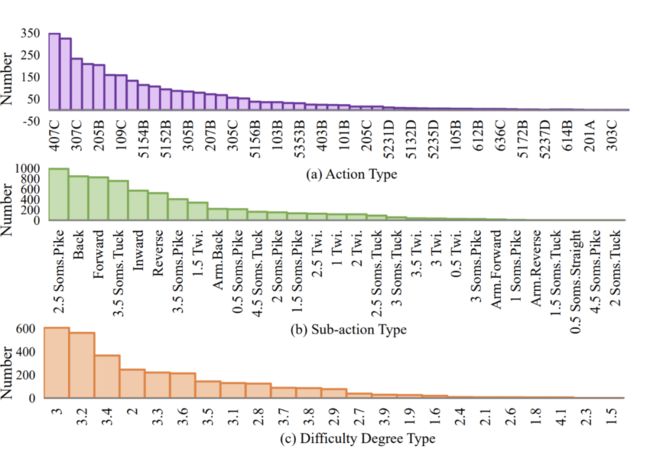
▲(4)Statistics of FineDiving.
根据表(5)可知,FineDiving 在注释类型和数据规模上不同于现有的 AQA 数据集:MIT-Dive、UNLV 以及 AQA-7-Dive 数据集仅提供动作分数,MTL-AQA 提供粗粒度注释(即动作类型和时间边界),而 FineDiving 提供了细粒度注释(包括动作类型、子动作类型、粗粒度和细粒度时间边界以及动作分数)。此外,由于缺乏动作得分,其他细粒度的运动数据集不能用于评估动作质量。不难发现,FineDiving 作为第一个用于 AQA 任务的细粒度运动视频数据集,填补了 AQA 中细粒度注释的空白。

▲(5)Comparison of existing sports video datasets and Fine-Diving. Score表示动作得分; Step表示细粒度的类别和时间边界; Action表示粗粒度的类别和时间边界; Tube包含细粒度的类别、时间边界以及空间定位。

方法
我们进一步提出一种过程感知方法来评估动作质量,通过构建一个新的时间分割注意模块(Temporal Segmentation Attention,TSA),以可解释的方式评估动作得分。TSA 包含三个部分:动作过程分割(procedure segmentation),过程感知交叉注意(procedure-aware cross-attention)以及细粒度对比回归(fine-grained contrastive regression)。
首先,动作过程分割将成对的查询动作实例和参考动作实例解析为语义和时间对齐的连续步骤。其次,过程感知交叉注意通过学习发现成对 query step 和 exemplar step 之间的时空对应关系,并在这两个步骤中生成新特征。成对的步骤相互补充,以引导模型关注 exemplar step 和 query step 中的一致区域,其中,exemplar step 保留了特征图的空间信息。
最后,细粒度对比回归通过学习成对步骤的相对分数来量化查询动作实例和示例动作实例之间的一些列步骤偏差,以指导模型来评估动作质量。

▲(6)The architecture of the proposed procedure-aware action quality assessment.
关于 TSA 中 exemplar 的选择策略。根据 action type 从训练集中选择 exemplar。在训练阶段,对于每个训练样本(query),从具有相同 action type 的其他训练样本中随机选择一个作为 exemplar。在推理阶段,采用多样本投票策略:从具有相同 action type 的训练样本中随机选择 M 个样本作为 M 个 exemplars。

实验
4.1 Metrics
我们通过以下三个指标来评估我们的方法:
Average Intersection over Union:

Spearman's rank correlation
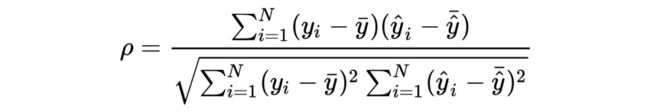
Relative L2-distance

4.2 Results and Analysis
我们的方法(TSA)与其他 AQA 方法的对比结果(见表(7))。

▲(7)Comparisons of performance with existing AQA methods on FineDiving.
我们的方法(TSA)的消融实验(见表(8))。
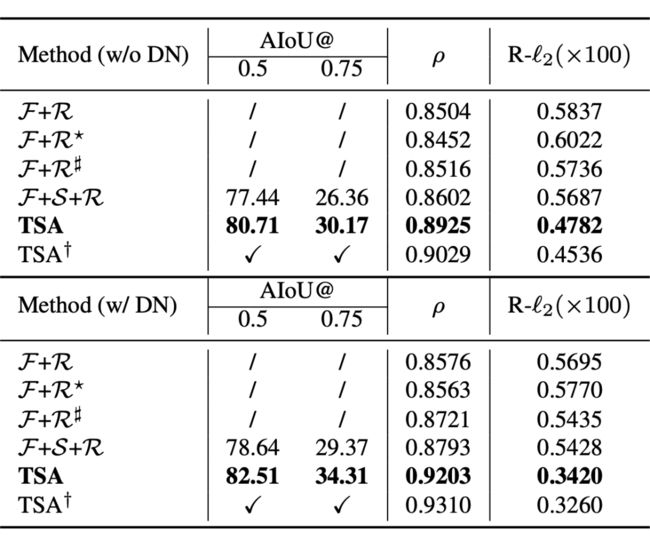
▲(8)Ablation studies on FineDiving.
投票 exemplar 的数目对 TSA 的影响(见表(9))。

▲(9)Effects of the number of exemplars for voting.
成对查询和参考示例之间的过程感知交叉注意的可视化。

▲(10)The visualization of procedure-aware cross attention between pairwise query and exemplar procedures.
我们的方法可以专注于与查询步骤一致的参考区域,这使得逐步骤的动作质量相对差异的量化更加可靠,其中,呈现的成对查询和参考具有相同的 action type 和 sub-action type。

结论
FineDiving 是第一个用于 AQA 任务的细粒度体育视频数据集。在 FineDiving 基础上,我们通过构建一个新的 TSA 模块提出了一种过程感知动作质量评估方法,该模块在查询和参考的成对步骤中学习语义、时空一致区域,使得动作质量评价得推理过程更具可解释性,并对现有的 AQA 方法实现了实质性改进。

参考文献
[1] Xumin Yu, Yongming Rao, Wenliang Zhao, Jiwen Lu, and Jie Zhou.Group-aware contrastive regression for action quality assessment. In ICCV, 2021.
[2] Yansong Tang, Zanlin Ni, Jiahuan Zhou, Danyang Zhang, Jiwen Lu, Ying Wu, and Jie Zhou. Uncertainty-aware score distribution learning for action quality assessment. In CVPR, 2020.
[3] Dian Shao, Yue Zhao, Bo Dai, and Dahua Lin. Finegym: A hierarchical video dataset for fine-grained action understanding. In CVPR, 2020.
[4] Paritosh Parmar and Brendan Tran Morris.What and how well you performed? a multitask learning approach to action quality assessment. In CVPR, 2019.
[5] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, DirkWeissenborn, XiaohuaZhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv:2010.11929, 2020.
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
投稿通道:
• 投稿邮箱:[email protected]
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
