论文翻译《Dense Relation Distillation with Context-aware Aggregation for Few-Shot Object Detection》
论文地址:https://arxiv.org/abs/2103.17115
代码地址:https://github.com/hzhupku/DCNet
目录
- Abstract
- 1.Introduction
- 2.Related Work
-
- 2.1. General Object Detection
- 2.2. Few-Shot Learning
- 2.3. Few-Shot Object Detection
- 3. Method
-
- 3.1. Preliminaries.
- 3.2. DCNet
- 3.2.1. Dense Relation Distillation Module
- 3.2.2. Context-aware Feature Aggregation
- 3.3. Learning Strategy
- 4. Experiments
-
- 4.1. Datasets and Settings
- 4.2. Experiments on PASCAL VOC
-
-
- 4.2.1 Comparisons with State-of-the-art Methods
- 4.2.2 Ablation Study
- 4.2.3 Qualitative Results
- 4.3. Experiments on MS COCO
-
- 5. Conclusions
Abstract
Conventional deep learning based methods for object detection require a large amount of bounding box annotations for training, which is expensive to obtain such high quality annotated data. Few-shot object detection, which learns to adapt to novel classes with only a few annotated examples, is very challenging since the fine-grained feature of novel object can be easily overlooked with only a few data available. In this work, aiming to fully exploit features of annotated novel object and capture fine-grained features of query object, we propose Dense Relation Distillation with Context-aware Aggregation (DCNet) to tackle the few-shot detection problem. Built on the meta-learning based framework, Dense Relation Distillation module targets at fully exploiting support features, where support features and query feature are densely matched, covering all spatial locations in a feed-forward fashion. The abundant usage of the guidance information endows model the capability to handle common challenges such as appearance changes and occlusions. Moreover, to better capture scale-aware features, Context-aware Aggregation module adaptively harnesses features from different scales for a more comprehensive feature representation. Extensive experiments illustrate that our proposed approach achieves state-of-the-art results on PASCAL VOC and MS COCO datasets. Code will be made available at https://github.com/hzhupku/DCNet
传统的基于深度学习的物体检测方法需要大量的边界框注释来进行训练,获取如此高质量的标注数据代价高昂。小样本目标检测在只有少数注释实例的情况下学习适应新的类别,这是一种非常具有挑战性的方法,因为在只有少量可用数据的情况下,新对象的细粒度特征很容易被忽略。在本文中,为了充分利用带注释的新对象的特征,获取查询对象的细粒度特征,我们提出了基于上下文感知聚合的密集关系蒸馏法(DCNet) 来解决小样本目标检测的问题。密集关系蒸馏模块建立在基于元学习的框架之上,旨在充分利用支撑特征(支撑特征和查询特征是密集匹配的),以前馈方式覆盖所有空间位置。指导信息的大量使用使模型有能力外观变化和遮挡等常见的挑战。此外,为了更好地捕捉尺度感知的特征,上下文感知聚合模块自适应地利用不同尺度的特征,以获得更全面的特征表示。大量的实验表明,我们提出的方法在PASCAL VOC和MS COCO数据集上取得了最先进的结果。代码将展示在https://github.com/hzhupku/DCNet。
1.Introduction
With the success of deep convolutional neural works, object detection has made great progress these years [20, 23, 8]. The success of deep CNNs, however, heavily relies on large-scale datasets such as ImageNet [2] that enable the training of deep models. When the labeled data becomes scarce, CNNs can severely overfit and fail to generalize. While in contrast, human beings have exhibited strong performance in learning a new concept with only a few examples available. Since some object categories naturally have scarce examples or bounding box annotations are laborsome to obtain such as medical data. These problems have triggered increasing attentions to deal with learning models with limited examples. Few-shot learning aims to train models to generalize well with a few examples provided. However, most existing few-shot learning works focus on image classification [29, 26, 27] problem and only a few focus on few-shot object detection problem. Since object detection not only requires class prediction, but also demands localization of the object, making it much more difficult than few-shot classification task.
随着深度卷积神经工作的成功,目标检测在近年来取得了很大进展[20,23,8]。然而,深度CNN的成功在很大程度上依赖于大规模的数据集,如ImageNet[2],它支持深度模型的训练。当标记数据变得稀缺时,CNN会严重过拟合,无法进行泛化。与此相反,人类在学习一个新概念时,即使面对很少的例子,也能表现出很强的学习能力。由于某些对象类别的示例自然稀少,或者边界框注释很难获取,例如医疗数据。这些问题引起了人们对有限例学习模型的关注。小样本学习的目的是在提供了少数示例的情况下训练模型的泛化能力。然而,现有的小样本学习工作侧重于图像分类问题[29,26,27],只有少数侧重于小样本目标检测问题。这是因为目标检测不仅需要进行类别预测,而且需要对目标进行定位,这比小样本分类任务要困难得多。
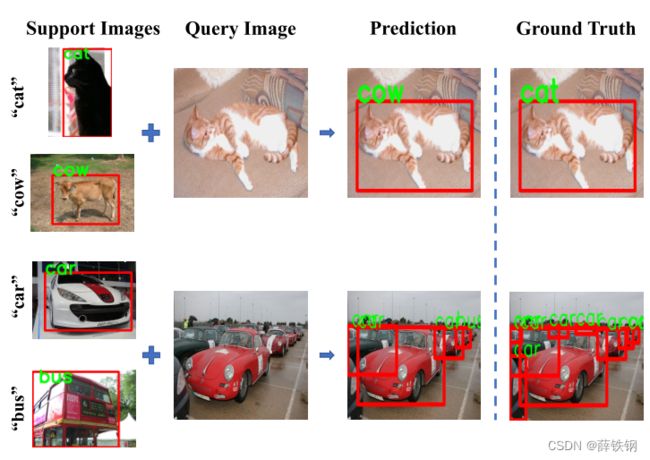
Figure 1. Two challenges for few-shot object detection. a) Appearance changes between support and query images are common, which results in a misleading manner. b) Occlusion problem brings about incomplete feature representation, causing false classification and missing detection.
图1。小样本目标检测的两个挑战。a)支撑图像和查询图像之间的外观变化很常见,这会导致误导。b)遮挡问题导致特征表示不完整,造成错误分类和漏检。
Prior studies in few-shot object detection mainly consist of two groups. Most of them [13, 35, 34] adopt a meta learning [5] based framework to perform feature reweighting for a class-specific prediction. While Wang et al.[31] adopt a two-stage fine-tuning approach with only finetuning the last layer of detectors and achieve state-of-the-artperformance. Wu et al. [33] also use similar strategy and focus on the scale variation problem in few-shot detection.
以往的小样本目标检测研究主要分为两大类。其中大部分[13,35,34]采用基于元学习的[5]框架,对特定类的预测进行特征重加权。而Wang等人[31]采用两阶段微调方法,只对最后一层检测器进行微调,取得了最先进的性能。Wu等人[33]也采用了类似的策略,关注了小样本目标检测中的尺度变化问题。
However, aforementioned methods often suffer from several drawbacks due to the challenging nature of few-shot object detection. Firstly, relations between support features and query feature are hardly fully explored in previous few-shot detection works, where global pooling operation on support features is mostly adopted to modulate the query branch, which is prone to loss of detailed local context. Specifically, appearance changes and occlusions are common for objects, as shown Fig. 1. Without enough discriminative information provided, the model is obstructed from learning critical features for class and bounding box predictions. Secondly, although scale variation problem has been widely studied in prior works [17, 15, 33], it remains a serious obstacle in few-shot detection tasks. Under few-shot settings, feature extractor with scale-aware modifications is inclined to overfitting, leading to a deteriorated performance for both base and novel classes.
然而,由于小样本目标检测的挑战性,上述方法往往存在一些缺点。首先,在以往的小样本目标检测工作中,支撑特征与查询特征之间的关系几乎没有得到充分的探讨,多采用对支撑特征的全局池化操作来调节查询分支,这很容易造成局部上下文细节的丢失。具体来说,如图1所示,物体的外观变化和遮挡是常见的。如果不提供足够的判别信息,模型就会受到阻碍,无法学习关键的特征来进行类别和边界框的预测。其次,尽管尺度变化问题在前人的工作中得到了广泛的研究[17,15,33],但它仍然是小样本目标检测任务中的一个严重障碍。在小样本设置下,具有尺度感知修改的特征提取器可能会过拟合,导致基类和新类性能下降。
In order to alleviate the above issues, we first propose the dense relation distillation module to fully exploit support set. Given a query image and a few support images from novel classes, the shared feature learner extracts query feature and support features for subsequent matching procedure. Intuitively, the criteria that determines whether query object and support object belong to the same category mainly measures how much feature similarity they share in common. When appearance changes or occlusions occur, local detailed features are dominant for matching candidate objects and template ones. Hence, instead of obtaining global representations of support set, we propose a dense relation distillation mechanism where query and support features are matched in a pixel-wise level. Specifically, key and value maps are produced from features, which serve as encoding visual semantics for matching and containing detailed appearance information for decoding respectively. With local information of support set effectively retrieved for guidance, the performance can be significantly boosted, especially in extremely low-shot scenarios.
为了缓解上述问题,我们首先提出了密集关系蒸馏模块,以充分利用支持集。给定一个查询图像和一些来自新类的支撑图像,共享特征学习器提取查询特征和支撑特征,用于后续的匹配过程。直观地说,判断查询对象和支撑对象是否属于同一类别的标准主要是衡量它们有多少共同的特征相似性。当出现外观变化或遮挡时,局部细节特征在匹配查询对象和模板对象时占主导地位。因此,我们没有获得支撑集的全局表示,而是提出了一种密集关系蒸馏机制,在这种机制中,查询特征和支撑特征是在一个像素级的水平上匹配的。具体而言,从特征中生成键映射和值映射,分别作为匹配的视觉语义编码和解码的详细外观信息。通过有效地检索支持集的局部信息进行制导,可以显著提高性能,特别是在极少样本场景下。
Furthermore, for the purpose of mitigating the scale variation problem, we design the context-aware feature aggregation module to capture essential cues for different scales during RoI pooling. Since directly modifying feature extractor could result in overfitting, we choose to perform adjustment from a more flexible perspective. Recognition of objects with different scales requires different levels of contextual information, while the fixed pooling resolution may bring about loss of substantial context information. Hence, an adaptive aggregation mechanism that allocates specific attention to local and global features simultaneously could help preserve contextual information for different scales of objects. Therefore, instead of performing RoI pooling with one fixed resolution, we choose three different pooling reso-lutions to capture richer context features. Then an attention mechanism is introduced to adaptively aggregate output features to present a more comprehensive representation.
此外,为了缓解尺度变化问题,我们设计了基于上下文感知的特征聚合模块,以捕获RoI池化过程中不同尺度的基本线索。由于直接修改特征提取器可能导致过拟合,我们选择从更灵活的角度进行调整。不同尺度目标的识别需要不同层次的上下文信息,而固定的池化分辨率可能会导致大量上下文信息的丢失。因此,一种同时对局部和全局特征分配特定注意力的自适应聚合机制可以帮助保留不同尺度物体的上下文信息。因此,我们没有使用一个固定分辨率进行RoI池化,而是选择三个不同的池化分辨率来捕获更丰富的上下文特征。然后,引入注意机制来自适应地聚合输出特征,以呈现更全面的表示。
The contributions of this paper can be summarized as follows:
- We propose a dense relation distillation module for few-shot detection problem, which targets at fully exploiting support information to assist the detection process for objects from novel classes.
- We propose an adaptive context-aware feature aggregation module to better capture global and local features to alleviate scale variation problem, boosting the performance of few-shot detection.
- Extensive experiments illustrate that our approach has achieved a consistent improvement on PASCAL VOC and MS COCO datasets. Specially, our approach achieves better performance than the state-of-the-art methods on the two datasets.
本文的研究成果主要体现在以下几个方面:
1.我们提出了一种针对小样本目标检测问题的密集关系蒸馏模块,其目标是充分利用支撑信息来辅助新类目标的检测过程。
2. 我们提出了一种自适应的上下文感知特征聚合模块,以更好地捕捉全局和局部特征,以缓解尺度变化问题,提高小样本目标检测的性能。
3.大量的实验表明,我们的方法在PASCAL VOC和MS COCO数据集上都取得了改进。特别地,我们的方法在这两个数据集上取得了比最先进方法更好的性能。
2.Related Work
2.1. General Object Detection
Deep learning based object detection can be mainly divided into two categories: one-stage and two-stage detectors. One-stage detector YOLO series [20, 21, 22] provide a proposal-free framework, which uses a single convolutional network to directly perform class and bounding box predictions. SSD [18] uses default boxes to adjust to various object shapes. On the other hand, RCNN and its variants [7, 9, 6, 23, 8] fall into the second category. These methods first extract class-agnostic region proposals of the potential objects from a given image. The generated boxes are then further refined and classified into different categories by subsequent modules. Moreover, many works are proposed to handle scale variance [17, 15, 24, 25]. Compared to one-stage methods, two-stage methods are slower but exhibit better performance. In our work, we adopt Faster R-CNN as the base detector.
基于深度学习的目标检测主要分为单阶段检测器和两阶段检测器两大类。两阶段检测器YOLO系列[20,21,22]提供了一种无提议框架,它使用一个卷积网络直接执行类和边界框预测。SSD[18]使用默认框来适应各种物体形状。另一方面,RCNN及其变体[7,9,6,23,8]属于第二类。这些方法首先从给定的图像中提取潜在目标的类无关的区域提议框。然后,生成的方框被后续模块进一步细化并划分为不同的类别。此外,许多研究提出了处理尺度方差的方法[17,15,24,25]。与单阶段方法相比,两阶段方法速度较慢,但表现出更好的性能。在我们的工作中,我们采用Faster R-CNN作为基检测器。
2.2. Few-Shot Learning
Few-shot learning aims to learn transferable knowledge that can be generalized to new classes with scarce examples. Bayesian inference is utilized in [4] to generalize knowledge from a pretrained model to perform one-shot learning. Meta-learning based methods have been prevalent in few-shot learning these days. Metric learning based methods [16, 29, 26, 27] have achieved state-of-the-art performance in few-shot classification tasks. Matching Network [29] encodes input into deep neural features and performs weighted nearest neighbor matching to classify query images. Our proposed method is also based on matching mechanism. Prototypical Network [26] represents each class with one prototype which is a feature vector. Relation Network [27] learns a distance metric to compare the target image with a few labeled images. While optimization based methods [19, 5] are proposed for fast adaptation to new few-shot task. [11] proposes a cross-attention mechanism to learn correlations between support and query images. Above methods are focusing on the few-shot classification task while few-shot object detection problem is relatively under-explored.
小样本学习的目的是学习可转移的知识,可以推广到新的类和稀缺的例子。[4]中使用贝叶斯推理从预训练的模型中归纳出知识来执行一次学习(one-shot learning)。目前,基于元学习的方法在一次学习中非常流行。基于度量学习的方法[16,29,26,27]在小样本分类任务中取得了最先进的性能。匹配网络[29]将输入编码为深度神经特征,并进行加权最近邻匹配对查询图像进行分类。我们提出的方法也是基于匹配机制。原型网络(Prototypical Network)[26]用一个原型代表每个类别,其中一个原型是一个特征向量。关系网络[27]学习一个距离度量来比较目标图像与一些标记图像。而基于优化的方法[19,5]则被提出用于快速适应新的小样本任务。[11]提出了一种交叉注意机制来学习支持和查询图像之间的相关性。上述方法主要针对的是小样本分类任务,而对小样本目标检测问题的研究相对较少。
2.3. Few-Shot Object Detection
Few-shot object detection aims to detect object from novel classes with only a few annotated training examples provided. LSTD [1] and RepMet [14] adopt a general transfer learning framework which reduces overfitting by adapting pretrained detectors to few-shot scenarios. Recently, Meta YOLO [13] designs a novel few-shot detection model with YOLO v2 [21] that learns generalizable meta features and automatically reweights the features for novel classes by producing classspecific activating coefficients from support examples. Meta R-CNN [35] and FsDetView [34] perform similar process with base detector as Faster R-CNN. TFA [31] simply performs two-stage finetuning approach by only finetuning the classifier on the second stage and achieves better performance. MPSR [33] proposes multiscale positive sample refinement to handle scale variance problem. CoAE [12] proposes non-local RPN and focuses on one-shot detection from the view of tracking by comparing itself with other tracking methods, while our method performs cross-attention on features extracted by the backbone in a more straightforward way and targets at few-shot detection task. FSOD [3] proposes attention-RPN, multi-relation detector and contrastive training strategy to detect novel object. In our work, we adopt the similar meta-learning based framework as Meta R-CNN and further improve the performance. Moreover, with our proposed method, the class-specific prediction procedure can be successfully removed, simplifying the overall process.
小样本目标检测的目的是在只提供少数有注释的训练实例的情况下检测新类别的物体。LSTD[1]和RepMet[14]采用了一种通用的迁移学习框架,通过调整预训练的检测器来减少过拟合,以适应小样本的场景。最近,Meta YOLO[13]使用YOLO v2[21]设计了一种新颖的小样本目标检测模型,该模型学习了可通用的元特征,并通过从支持实例中生成特定类别的激活系数,自动为新类调整特征的权重。Meta R-CNN[35]和FsDetView[34]执行与Faster R-CNN相似的基本检测器过程。TFA[31]简单地执行了两阶段的微调方法,只在第二阶段对分类器进行微调,并取得了更好的性能。MPSR[33]提出了多尺度正样本细化方法来处理尺度方差问题。CoAE[12]提出了非局部RPN,通过与其他跟踪方法的比较,从跟踪的角度关注一次检测,而我们的方法更直接地对backbone提取的特征进行交叉注意,针对的是小样本检测任务。FSOD[3]提出了attention-RPN、多关系检测器和对比训练策略来检测新目标。在我们的工作中,我们采用了类似于Meta R-CNN的基于元学习的框架,进一步提高了性能。此外,通过我们提出的方法,可以成功地去除特定类别的预测程序,简化了整个过程。
3. Method
3.1. Preliminaries.
Problem Definition. Following setting in [13, 35], object classes are divided into base classes C b a s e C_{base} Cbase with abundant annotated data and novel classes C n o v e l C_{novel} Cnovelwith only a few annotated samples, where C b a s e C_{base} Cbase and C n o v e l C_{novel} Cnovelhave no intersection. We aim to obtain a few-shot detection model with the ability to detect objects from both base and novel classes in testing by leveraging generalizable knowledge from base classes. The number of instances per category for novel classes is set as k (i.e., k-shot).
问题的定义。 根据[13,35]的设置,对象类分为基类 C b a s e C_{base} Cbase和新类 C n o v e l C_{novel} Cnovel,基类 C b a s e C_{base} Cbase有丰富的标注数据,新类 C n o v e l C_{novel} Cnovel只有少量的标注样本,其中 C b a s e C_{base} Cbase和 C n o v e l C_{novel} Cnovel没有交集。我们的目标是利用基类的可泛化知识,获得一个能够检测基类和新类对象的小样本目标检测模型。每个新类类别的实例数设置为k(即k-shot)。
We align the training scheme with the episodic paradigm [29] for few-shot scenario. Given a k-shot learning task, each episode is constructed by sampling: 1) a support set containing image-mask pairs for different classes S = x i , y i i = 1 N S={x_{i},y_{i}}_{i=1}^{N} S=xi,yii=1N, where x i ∈ R h × w × 3 x_{i}\in\mathbb R^{h \times w \times 3} xi∈Rh×w×3 is an RGB image, y i ∈ R h × w y_{i} \in\mathbb R^{h \times w} yi∈Rh×w is a binary mask for objects of class i in the support image generated from bounding box annotations and N is the number of classes in the training set; 2) a query image q and annotations m for the training classes in the query image. The input to the model is the support pairs and query image, the output is detection prediction for query image.
我们的训练方案和[29]的适用场景相一致,用于小样本场景。给定一个k-shot学习任务,每个episode都是通过采样构建的:1)一个包含不同类的图像-掩码对的支持集 S = x i , y i i = 1 N S={x_{i},y_{i}}_{i=1}^{N} S=xi,yii=1N,其中 x i ∈ R h × w × 3 x_{i}\in\mathbb R^{h \times w \times 3} xi∈Rh×w×3 是RGB图像, y i ∈ R h × w y_{i} \in\mathbb R^{h \times w} yi∈Rh×w是由边界框注释生成的支持图像中第i类对象的二进制掩码,N是训练集中的类数;2)查询图像q和查询图像中训练类别的注释m。模型的输入是支撑对和查询图像,输出是对查询图像的预测结果。
Basic Object Detection. The choice of base detectors is varied. [13] utlizes YOLO v2 [21] which is a one-stage detector, while [35] adopts Faster R-CNN [23] which is a two-stage detector and provides consistently better results. Therefore, we also adopt Faster R-CNN as our base detector which consists of a feature extractor, region proposal network (RPN) and the detection head (RoI head).
基本的对象检测。 基础检测器的选择是多种多样的。[13]使用YOLO v2[21],这是一个单阶段检测器,而[35]采用Faster R-CNN[23],这是两阶段检测器,通常来讲效果更好。因此,我们也采用Faster R-CNN作为我们的基础检测器,它由一个特征提取器、区域建议网络(RPN)和检测头(RoI头)组成。
Feature Reweighting for Detection. We choose Meta-RCNN [35] as our baseline method. Formally, let I denote an input query image, { I s i , M s i } ∣ i = 1 N \{I_{si}, M_{si}\}|_{i=1}^{N} {Isi,Msi}∣i=1N denote support images and masks converted from bounding-box annotations, where N is the number of training classes. RoI features z j ∣ j = 1 n z^j|_{j=1}^n zj∣j=1nis generated by the RoI pooling layer (n is the number of RoIs) and class-specific vectors w i ∈ R C , i = 1 , 2 , . . . , N w_{i} \in\mathbb R^C, i =1, 2, ..., N wi∈RC,i=1,2,...,Nare produced with a reweighting module which shares its backbone parameters with the feature extractor, where C is the feature dimension. Then class-specific feature z i z_i zi is achieved with:
z i = z ⊗ w i , i = 1 , 2 , … … , N , (1) z_{i} = z \otimes w_{i}, i = 1, 2,……, N, \tag{1} zi=z⊗wi,i=1,2,……,N,(1)
where ⊗ \otimes ⊗denotes channel-wise multiplication. Then classspecific prediction is performed to output the detection results. Based on this methodology, we further make a significant improvement and simplify the prediction procedure by removing the class-specific prediction.
检测的特征重加权。 我们选择Meta R-CNN[35]作为基线方法。形式上,让 I 表示一个输入查询图像, { I s i , M s i } ∣ i = 1 N \{I_{si}, M_{si}\}|_{i=1}^{N} {Isi,Msi}∣i=1N表示支撑图像和由边界框注释转换的掩码,其中N是训练类的数量。RoI特征$zj|_{j=1}n由RoI池化层(n为RoI个数)和类特定向量 w i ∈ R C , i = 1 , 2 , . . . , N w_{i} \in\mathbb R^C, i =1, 2, ..., N wi∈RC,i=1,2,...,N生成, N通过与特征提取器共享其backbone参数的重加权模块产生,其中C为特征维。然后用以下方法获得类特定的特征 z i z_i zi :
z i = z ⊗ w i , i = 1 , 2 , … … , N , (1) z_{i} = z \otimes w_{i}, i = 1, 2,……, N, \tag{1} zi=z⊗wi,i=1,2,……,N,(1)
其中 ⊗ \otimes ⊗表示逐通道相乘。然后进行分类预测,输出检测结果。在此方法的基础上,我们进一步进行了显著的改进,并通过删除特定于类的预测来简化预测过程。
3.2. DCNet
As illustrated in Fig. 2, we present the Dense Relation Distillation (DRD) module with Context-aware Feature Aggregation (CFA) module to fully exploit support features and capture essential context information. The two proposed components form the final model DCNet. We will first depict the architecture of the proposed DRD module. Then we will bring out the details of the CFA module.
如图2所示,我们提出了密集关系蒸馏(DRD)模块和上下文感知特征聚合(CFA)模块,以充分利用支撑特征并捕获基本的上下文信息。这两个组件组成了最终的模型DCNet。我们将首先介绍DRD模块的体系结构,再介绍CFA模块的细节。
3.2.1. Dense Relation Distillation Module
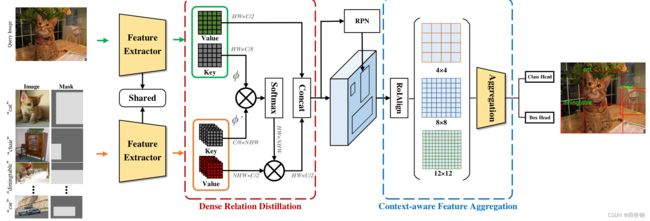
Figure 2. The overall framework of our proposed DCNet. For training, the input for each episode consists of a query image and N support image-mask pairs from N classes. The shared feature extractor first produces query feature and support features. Then, the dense relation distillation (DRD) module performs dense feature match to activate co-exisiting features of input query. With proposals produced by RPN, context-aware feature aggregation (CFA) module adaptively harnesses features generated with different scales of pooling operations, capturing different levels of features for a more comprehensive representation
图2。我们提出的DCNet的总体框架。对于训练,每个episode的输入由一个查询图像和来自N个类的N个支撑图像掩码对组成。共享特征提取器首先产生查询特征和支撑特征。然后,密集关系蒸馏模块(DRD)进行密集特征匹配,激活输入查询的共存特征。根据RPN提出的建议,上下文感知特征聚合(CFA)模块自适应地利用由不同尺度的池化操作生成的特征,捕获不同级别的特征,以实现更全面的表示。
Key and Value Embedding. Given a query image and support set, query and support features are produced by feeding them into the shared feature extractor. The input of the dense relation distillation (DRD) module is the query feature and support features. Both parts are first encoded into pairs of key and value maps through the dedicated deep en-coders. The query encoder and support encoder adopt the same structure while not sharing parameters.
键和值的嵌入。 给定查询图像和支撑集,通过将查询图像和支撑集输入共享特征提取器来生成查询和支撑特征。密集关系精馏(DRD)模块的输入是查询特征和支撑特征。这两个部分首先通过专用的深度编码器被编码为一对键和值。查询编码器和支撑编码器采用相同的结构,但是不共享参数。
The encoder takes one or multiple feature as input and outputs two feature maps for each input feature: key and value with two parallel 3 × 3 3 \times 3 3×3 convolution layers, which serve as reducing the dimension of the input feature to save computation cost. Specifically, key maps are used for measuring the similarities between query feature and support features, which help determine where to retrieve relevant support values. Therefore, key maps are learned to encode visual semantics for matching and value maps store detailed information for recognition. Hence, for query feature, the output is a pair of key and value maps: k q ∈ R C / 8 × H × W k_{q} \in\mathbb R^{C/8 \times H \times W} kq∈RC/8×H×W , v q ∈ R C / 2 × H × W v_{q}\in\mathbb R^{C/2 \times H \times W} vq∈RC/2×H×W , where C is the feature dimension, H is the height, and W is the width of input feature map. For support features, each of the features is independently encoded into key and value maps, the output is k s ∈ R N × C / 8 × H × W k_{s} \in\mathbb R^{N\times C/8 \times H \times W} ks∈RN×C/8×H×W , v s ∈ R N × C / 2 × H × W v_{s}\in\mathbb R^{N\times C/2 \times H \times W} vs∈RN×C/2×H×W , where N is the number of target classes (also the number of support samples). The generated key and value maps are further fed into the relation distillation part where keys maps of query and support are densely matched for addressing target objects.
编码器将一个或多个特征作为输入,并为每个输入特征输出两个特征:键和值,具有两个并行的 3 × 3 3 \times 3 3×3卷积层,用于降低输入特征的维数以节省计算成本。具体来说,键映射用于度量查询特征和支撑特征之间的相似性,这有助于确定在哪里检索相关的支持值。因此,键映射用于编码视觉语义进行匹配,值映射存储了详细的信息用于识别。因此,对于查询特征,输出是一对键值映射: k q ∈ R C / 8 × H × W k_{q} \in\mathbb R^{C/8 \times H \times W} kq∈RC/8×H×W , v q ∈ R C / 2 × H × W v_{q}\in\mathbb R^{C/2 \times H \times W} vq∈RC/2×H×W ,其中C为特征维数,H为高度,W为输入特征映射的宽度。对于支撑特征,每个特征都独立编码为键和值,输出为 k s ∈ R N × C / 8 × H × W k_{s} \in\mathbb R^{N\times C/8 \times H \times W} ks∈RN×C/8×H×W, v s ∈ R N × C / 2 × H × W v_{s}\in\mathbb R^{N\times C/2 \times H \times W} vs∈RN×C/2×H×W ,其中N为目标类的数量(即支撑样本的数量)。生成的键和值映射被进一步送入到关系蒸馏模块,其中查询和支撑的键映射被密集匹配以寻址目标对象。
Relation Distillation. After acquiring the key/value maps of query and support features, relation distillation is performed. As illustrated in Fig. 2, soft weights for value maps of support features are computed via measuring the similarities between key maps of query feature and support features. The pixel-wise similarity is performed in a non-local manner, formulated as: F ( k q i , k s j ) = φ ( k q i ) T φ ′ ( k s j ) , (2) F(k_{qi}, k_{sj}) = φ(k_{qi})^T φ'(k_{sj}), \tag{2} F(kqi,ksj)=φ(kqi)Tφ′(ksj),(2) where i and j are the index of the query and support location, φ , φ 0 φ, φ_{0} φ,φ0 denote two different linear transformations with parameters learned via back propagation during training process, forming a dynamically learned similarity function. After computing the similarity of pixel features, we perform softmax normalization to output the final weight W : W i j = e x p ( F ( k q i , k s j ) ) ∑ i e x p ( F ( k q i , k s j ) ) . (3) W_{ij} = \frac{exp(F(k_{qi}, k_{sj}))}{\sum_{i}exp(F(k_{qi}, k_{sj}))}.\tag{3} Wij=∑iexp(F(kqi,ksj))exp(F(kqi,ksj)).(3)Then the value of the support features are retrieved by a weighted summation with the soft weights produced and then it is concatenated with the value map of query feature. Hence, the final output is formulated as: y = c o n c a t [ v q , W ∗ v s ] , (4) y = concat[v_q, W * v_s],\tag{4} y=concat[vq,W∗vs],(4) where ∗ denotes matrix inner-product. Noted that there are N support features, which brings N key-value pairs. We perform summation over N output results to obtain the final result, which is a refined query feature, activated by support features where there are co-existing classes of objects in query and support images.
关系蒸馏。 获取查询和支撑特征的键/值映射后,进行关系蒸馏。如图2所示,通过测量查询特征与支撑特征关键映射的相似度,计算支撑特征值映射的软权重。像素级别的相似性以非局部的方式进行,表述为: F ( k q i , k s j ) = φ ( k q i ) T φ ′ ( k s j ) , (2) F(k_{qi}, k_{sj}) = φ(k_{qi})^T φ'(k_{sj}), \tag{2} F(kqi,ksj)=φ(kqi)Tφ′(ksj),(2)
其中i和j为查询和支撑位置的索引, φ , φ 0 φ, φ_{0} φ,φ0 表示两个不同的线性变换,在训练过程中通过反向传播学习参数,形成一个动态学习的相似函数。计算出像素特征的相似度后,进行softmax归一化,输出最终权重W: W i j = e x p ( F ( k q i , k s j ) ) ∑ i e x p ( F ( k q i , k s j ) ) . (3) W_{ij} = \frac{exp(F(k_{qi}, k_{sj}))}{\sum_{i}exp(F(k_{qi}, k_{sj}))}.\tag{3} Wij=∑iexp(F(kqi,ksj))exp(F(kqi,ksj)).(3)
然后将软权重进行加权求和,得到支撑特征的值,将其与查询特征的值映射相连接,因此,最终输出的公式为: y = c o n c a t [ v q , W ∗ v s ] , (4) y = concat[v_q, W * v_s],\tag{4} y=concat[vq,W∗vs],(4) 其中 ∗ 表示矩阵内积。注意到有N个支撑特征,带来了N个键值对。我们对 N 个输出结果进行求和以获得最终结果,这是一个细化的查询特征,由支撑特征激活,这些支撑特征的类别是查询和支撑图像集中共存的。
Previous trials [13, 35, 34] utilize class-wise vectors generated by global pooling of support features to modulate the query feature, which guide the feature learning from a holistic view. However, since appearance changes or occlusions are common in natural images, the holistic feature may be misleading when objects of the same class vary much between query and support samples. Also, when most parts of the objects are unseen due to the occlusions, the retrieval of local detailed features becomes substantial, which former methods completely neglect. Hence, equipped with the dense relation distillation module, pixel-level relevant information can be distilled from support features. As long as there exist some common characteristics, the pixels of query features belonging to the co-existing objects between query and support samples will be further activated, providing a robust modulated feature to facilitate the prediction of class and bounding-box.
之前的实验[13,35,34]利用支撑特征的全局池化生成的分类向量来调整查询特征,从整体角度指导特征学习。然而,由于外观变化或遮挡在自然图像中是常见的,当同一类对象在查询和支撑样本之间变化很大时,整体特征可能会产生误导。另外,当大部分物体由于遮挡而看不见时,局部细节特征的检索变得非常重要,而以往的方法完全忽略了这一点。因此,本模型提出了密集关系蒸馏模块,可以从支撑特征中提取像素级的相关信息。只要存在一些共同的特征,属于查询样本和支撑样本之间共存对象的查询特征的像素将被进一步激活,提供一个鲁棒的调整特征,便于类和边界框的预测。
Our distillation method can be seen as an extension of the non-local self-attention mechanism [28, 30]. However, instead of performing self-attention, we specially design the relation distillation model to realize information retrieval from support features to modulate the query feature, which can be treated as a cross attention.
我们的蒸馏方法可以被视为非局部自注意机制的延伸[28,30]。但是,我们没有使用自注意力机制,而是专门设计了密集关系蒸馏模型,从支撑特征中实现信息检索,以调整查询特征,这一手段可以被看作是交叉注意力机制。
3.2.2. Context-aware Feature Aggregation
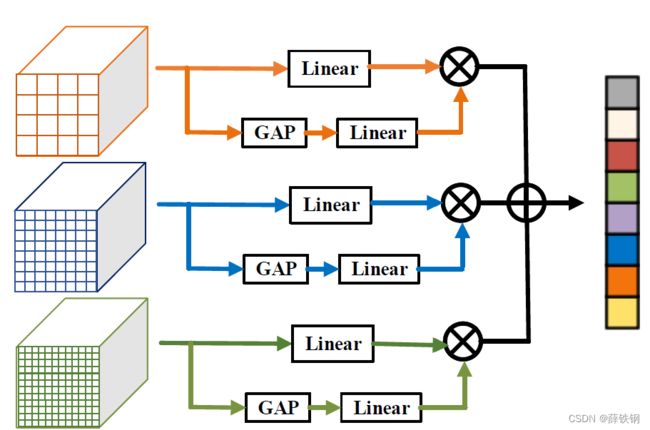
Figure 3. Illustration of context-aware feature aggregation. Attention mechanism is adopted to adaptively aggregate different features, where the weights are normalized with softmax function.
图3。上下文感知特征聚合的说明。采用注意机制对不同特征进行自适应聚合,其中 GAP 代表全局平均池化,Linear 代表全连接层,权重用softmax函数归一化。
After performing dense relation distillation, DRD module has fulfilled its duty. The refined query feature is subsequently fed into RPN where region proposals are output. Taking proposals and feature as input, RoI Align module performs feature extraction for final class prediction and bounding-box regression. Normally, pooling operation is implemented with a fixed resolution 8 in our original implementation, which is likely to cause information loss during training. For general object detection, this kind of information loss can be remedied with large scale of training data, while the problem becomes severe in few-shot detection scenarios with only a few training data available, which is inclined to induce a misleading detection results. Moreover, with scale variation amplified due to the few-shot nature, the model tends to lose the generalization ability to novel classes with adequate adaption to different scales. To this end, we propose Context-aware Feature Aggregation (CFA) module. Instead of using a fixed resolution 8, we empirically choose 4, 8 and 12 three resolutions and perform parallel pooling operation to obtain a more comprehensive feature representation. The larger resolution tends to focus on local detailed context information specially for smaller objects, while the smaller resolution targets at capturing holis-tic information to benefit the recognition of larger objects, providing a simple and flexible way to alleviate the scale variation problem.
在执行密集关系蒸馏之后,DRD模块已经完成了它的职责。细化后的查询特征随后被送入RPN,在RPN中输出区域建议框。RoI Align模块以proposals和特征为输入,进行特征提取,最终进行类预测和边界框回归。在我们原来的实现中,池操作通常是用固定的分辨率8来实现的,这很容易在训练过程中造成信息丢失。对于一般的目标检测,这种信息丢失可以通过大规模的训练数据来弥补,而在训练数据较少的小样本目标检测场景中,这种信息丢失问题会变得严重,容易导致检测结果的误导。由于小样本的特性,尺度变化被放大,模型往往会失去对新类别的泛化能力。为此,我们提出了上下文感知的特征聚合(CFA)模块。我们不使用固定的分辨率8,而是根据经验地选择4,8和12三种分辨率,并进行并行池化操作,以获得更全面的特征表示。较大的分辨率倾向于关注较小对象的局部详细上下文信息,而小分辨率的目标是捕捉整体信息,有利于较大的物体的识别,为缓解尺度变化问题提供了一种简单而灵活的方法。
Since each generated feature contains different level of semantic information. With the intention to efficiently aggregate features generated from different scales of RoI pooling, we further propose an attention mechanism to adaptively fuse the pooling results. As illustrated in Fig. 3, we add an attention branch for each feature which consists of two blocks. The first block contains a global average pooling. The second one contains two consecutive fc layers. Afterwards, we add a softmax normalization to the generated weights for balancing the contribution of each feature. Then the final output of the aggregated feature is the weighted summation of the three features.
因为每个生成的特征包含不同层次的语义信息。为了有效地聚合不同规模RoI池化生成的特征,我们进一步提出了一种自适应融合池化结果的注意机制。如图3所示,我们为每个特征添加一个注意力分支,它由两个块组成。第一个块包含一个全局平均池。第二个包含两个连续的fc层。在这之后,我们为生成的权重添加一个softmax归一化,以平衡每个特征的贡献。那么聚合特征的最终输出就是三个特征的加权和。
3.3. Learning Strategy

Figure 4. Demonstration of learning strategy of meta-learning based few-shot detection framework. The meta learner aims to acquire meta information and help the model to generalize to novel classes.
图4. 基于元学习的小样本目标检测框架的学习策略演示。元学习器的目的是获取元信息,帮助模型推广到新的类。
As illustrated in Fig. 4, we follow the training paradigm in [13, 35, 34], which consists of meta-training and meta fine-tuning. In the phase of meta-training, abundant annotated data from base classes is provided. We jointly train the feature extractor, dense relation distillation module, context-aware feature aggregation module and other basic components of detection model. In meta fine-tuning phase, we train the model on both base and novel classes. As only k labeled bounding-boxes are available for the novel classes, to balance between samples from base and novel classes, we also include k boxes for each base class. The training procedure is the same as the meta-training phase but with fewer iterations for model to converge.
如图4所示,我们遵循[13,35,34]中的训练范式,包括元训练和元微调。在元训练阶段,提供了来自基类的大量注释数据。我们联合训练特征提取器、密集关系蒸馏模块、上下文感知特征聚合模块和检测模型的其他基本组件。在元微调阶段,我们在基类和新类上训练模型。由于新类只有k个标记的边界框可用,为了平衡基类和新类的样本,我们还为每个基类包括k个框。训练过程与元训练阶段相同,但模型收敛的迭代次数更少。
4. Experiments
In this section, we first introduce the implementation details and experimental configurations in Sec. 4.1. Then we present our detailed experimental analysis on PASCAL VOC dataset in Sec. 4.2 together with ablation studies and qualitative results. Finally, results on COCO dataset will be presented in Sec. 4.3.
在本节中,我们首先介绍第4.1节中的实现细节和实验配置。然后,在第4.2节中介绍了我们对PASCAL VOC数据集的详细实验分析,以及消融研究和定性结果。最后,COCO数据集的结果将在第4.3节中给出。
4.1. Datasets and Settings
Following the instructions in [13], we construct the few-shot detection datasets for fair comparison with other state-of-the-art methods. Moreover, to achieve a more stable few-shot detection results, we perform 10 random runs with different randomly sampled shots. Hence, all the results in the experiments is averaged results by 10 random runs.
根据[13]中的说明,我们构建了小样本检测数据集,以便与其他先进方法进行比较。此外,为了获得更稳定的小样本检测结果,我们对不同的随机采样数量进行了10次随机运行。因此,所有的实验结果都是10次随机运行的平均结果。
PASCAL VOC. For PASCAL VOC dataset, we train our model on the VOC 2007 trainval and VOC 2012 trainval sets and test the model on VOC 2007 test set. The evaluation metric is the mean Average Precision (mAP). Both the trainval sets are split by object categories, where 5 are randomly chosen as novel classes and the left 15 are base classes. We use the same split as [13], where novel classes for four splits are {“bird”, “bus”, “cow”, “motorbike” (“mbike”), “sofa”}, {“aeroplane”(“aero”, “bottle”, “cow”, “horse”, “sofa”}, {“boat”, “cat”, “motorbike”, “sheep”, “sofa”}, respectively. For few-shot object detection experiments, the few-shot dataset consists of images where k object instances are available for each category and k is set as 1/3/5/10.
PASCAL VOC. 对于PASCAL VOC数据集,我们在VOC 2007 trainval集和VOC 2012 trainval集上训练模型,并在VOC 2007测试集上测试模型。评价指标是平均精度(mAP)。这两个训练集都按对象类别划分,其中5个随机选择为新类,其余15个为基类。我们使用与[13]相同的拆分,其中四个拆分的新类分别是{" bird “,” bus “,” cow “,” motorbike " (" mbike “),” sofa “}, {” aeroplane " (" aero ", " bottle “,” cow ", " horse ", " sofa “}, {” boat “,” cat “,” motorbike ", " sheep “,” sofa "}。对于小样本目标检测实验,小样本数据集由图像组成,其中每个类别有k个对象实例,k设置为1/3/5/10。
COCO. MS COCO dataset has 80 object categories, where the 20 categories overlapped with PASCAL VOC are set to be novel classes. 5000 images from the validation set noted as minival are used for evaluation while the left images in the train and validation set are used for training. The process of constructing few-shot dataset is similar to PASCAL VOC dataset and k is set as 10/30.
COCO. COCO数据集有80个对象类别,其中与PASCAL VOC重叠的20个类别被设置为新类。来自minival验证集的5000张图像用于评估,而训练集和验证集中剩下的图像用于训练。构建小样本数据集的过程类似于PASCAL VOC数据集,k设为10/30。
Implementation Details. We perform training and testing process on images with a single scale. The shorter side of the query image is resized to 800 pixels and longer sides are less than 1333 pixels while maintaining the aspect ratio. The support image is resized to a squared image of 256 × 256. We adopt ResNet-101 [10] as feature extractor and RoI Align [8] as RoI feature extractor. The weights of
the backbone is pre-trained on ImageNet [2]. After training on base classes, only the last fully-connected layer (for classification) is removed and replaced by a new one randomly initialized. It is worth noting that all parts of the model participate in learning process in the second meta fine-tuning phase without any freeze operation. We train our model with a mini-batch size as 4 with 2 GPUs. We utilize the
SGD optimizer with the momentum of 0.9, and weight decay of 0.0001. For meta-training on PASCAL VOC, models are trained for 240k, 8k, and 4k iterations with learning rates of 0.005, 0.0005 and 0.00005 respectively. For meta fine-tuning on PASCAL VOC, models are trained for 1300, 400 and 300 iterations with learning rates as 0.005, 0.0005 and 0.00005 respectively. As for MS COCO dataset, during
meta-training, models are trained for 56k, 14k and 10k iterations with learning rates of 0.005, 0.0005 and 0.00005 respectively. And during meta fine-tuning, model are trained for 2800, 700 and 500 iteration for 10-shot fine-tuning and 5600, 1400 and 1000 iterations for 30-shot fine-tuning.
实验细节。 我们对单一尺度的图像进行训练和测试。查询图像较短的边被调整为800像素,较长的边小于1333像素,同时保持长宽比。支持图像被调整为256 × 256的平方图像。我们采用ResNet-101[10]作为特征提取器,RoI Align[8]作为RoI特征提取器。Backbone的权重在ImageNet[2]上进行预训练。在基类上训练之后,只有最后一个全连接层(用于分类)被移除,并被一个随机初始化的新层所取代。值得注意的是,在第二个元微调阶段,模型的所有部分都参与了学习过程,没有任何冻结操作。我们设置mini-batch大小为4,2个GPU来训练模型。使用SGD优化器,momentum 为0.9,weight decay 为0.0001。在PASCAL VOC上进行元训练时,训练模型240k、8k和4k迭代,学习率分别为0.005、0.0005和0.00005。为了在PASCAL VOC上进行元微调,对模型进行1300、400和300次迭代训练,学习率分别为0.005、0.0005和0.00005。对于MS COCO数据集,在元训练过程中,对模型进行56k、14k和10k迭代训练,学习率分别为0.005、0.0005和0.00005。在元微调过程中,训练模型2800、700和500次迭代进行10次微调,训练模型5600、1400和1000次迭代进行30次微调。
Baseline Method. Since we adopt Faster-RCNN as base detector, we choose Meta R-CNN [35] as the baseline method. Moreover, we implement it by ourselves for a more fair comparison.
基线方法。 由于我们采用Faster-RCNN作为基础检测器,我们选择Meta R-CNN[35]作为基线方法。此外,我们自己实现了它,以进行更公平的比较。
4.2. Experiments on PASCAL VOC
In this section, we conduct experiments on PASCAL VOC dataset. We first compare our method with the state-of-the-art methods. Then we carry out ablation studies to perform comprehensive analysis of the components of our proposed DCNet. Finally, some qualitative results are presented to provide an intuitive view of the validity of our method. For all the experiments, we run 10 trials with random support data and report the averaged performance.
在本节中,我们在PASCAL VOC数据集上进行实验。首先将我们的方法与最先进的方法进行比较。然后进行消融研究,对我们提出的DCNet的组成部分进行综合分析。最后,给出了一些定性的结果,以便对我们方法的有效性提供一个直观的看法。对于所有的实验,我们使用随机支持数据运行10个试验,并报告平均性能。
4.2.1 Comparisons with State-of-the-art Methods
In Table 1, we compare our method with former state-of-the-art methods which mostly report results with multiple random runs. Our proposed DCNet achieves state-of-the-art results on almost all the splits with different shots and out-performs previous methods by a large margin. Specifically, in extremely low-shot settings (i.e. 1-shot), our method out-performs others by about 10% in split 1 and 3, providing a convincing proof that our DCNet is able to capture local detailed information to overcome the variations brought by the randomly sampled training shots.
在表1中,将我们的方法与以前最先进的方法进行比较,这些方法大多报告了多次随机运行的结果。我们提出的DCNet在几乎所有不同样本的分割上都取得了最先进的结果,并且大大优于以前的方法。具体来说,在极小样本设置(即1个样本)下,我们的方法在分割1和分割3中比其他方法高出约10%,提供了一个令人信服的证据,证明我们的DCNet能够捕获局部详细信息,克服随机采样训练样本带来的变化。
4.2.2 Ablation Study
We present results of comprehensive ablation studies to analyze the effectiveness of various components of the proposed DCNet. All ablation studies are conducted on the PASCAL VOC 2007 test set with the first novel splits. All results are averaged over 10 random runs.
我们提出了综合消融研究的结果,以分析所提出的DCNet的各个组成部分的有效性。所有的消融实验都是在PASCAL VOC 2007测试集上进行的,并采用了第一种新的分割方式。所有结果均为10次随机运行的平均值。
Impact of dense relation distillation module. We conduct experiments to validate the superiority of the proposed dense relation distillation (DRD) module. Specifically, we implement the baseline method for meta-learning based few-shot detection Meta R-CNN with class-specific prediction for the final box classification and regression. While the DRD module requires no extra class-specific process-
ing. As shown in line 1 and 2 of Table 2, DCNet w/o CFA equals to Faster R-CNN equipped with DRD module, our proposed DRD module achieves consistent improvement on all novel splits with all shots number, which effectively demonstrates the supremacy of the relation distillation mechanism over the baseline method. Moreover, the improvement over baseline is significant when the shot number is low, which proves that the DRD module successfully exploits useful information from limited support data.
密集关系蒸馏模块的影响。 通过实验验证了所提出的密集关系蒸馏DRD)模块的优越性。具体而言,我们实现了基于元学习的小样本目标检测Meta R-CNN的基线方法,并对最终的目标框分类和回归进行了特定类别的预测。而DRD模块不需要额外的类特定处理。如表2的第1和2行所示,DCNet w/o CFA等于配置了DRD模块的Faster R-CNN,我们提出的DRD模块在所有新分割和所有样本数数上都实现了一致的改进,这有效地证明了关系蒸馏机制优于基线方法。此外,当样本数量较小时,对基线的改进是显著的,这证明DRD模块成功地利用了有限的支持数据中的有用信息。
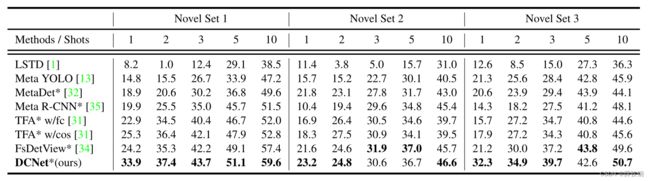
Table 1. Few-shot object detection performance on VOC 2007 test set of PASCAL VOC dataset. We report the mAP with IoU threshold 0.5 (AP50) under three different splits for five novel classes. * denotes the results averaged over multiple random runs.
表1。PASCAL VOC数据集的VOC 2007测试集上的小样本目标检测性能。我们报告了在五个新类别的三种不同划分下,IoU阈值为0.5(AP50)的mAP。*表示多次随机运行的结果的平均值。
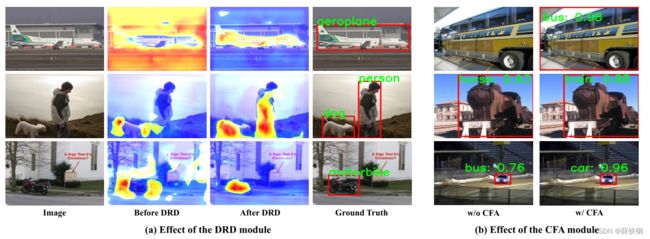
Figure 5. (a). Visualizations of features before and after dense relation distillation module. (b). Visualizations of effect of context-aware feature aggregation module.
图5。(a).密集关系蒸馏模块前后的特征可视化。(b).上下文聚合模块效果的可视化。
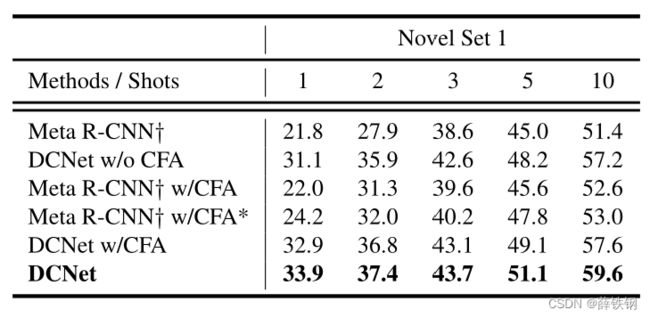
Table 2. Ablation study to evaluate the effectiveness of different components in our proposed method. The mAP with IoU threhold 0.5 (AP50) is reported. * denotes CFA module with attention aggregation fashion. † denotes our implementation.
表2。 消融研究,以评估我们提出的方法中不同组件的有效性。报告了IoU达到0.5时的mAP(AP50)。*表示具有注意力聚集方式的CFA模块。†表示我们的实施。
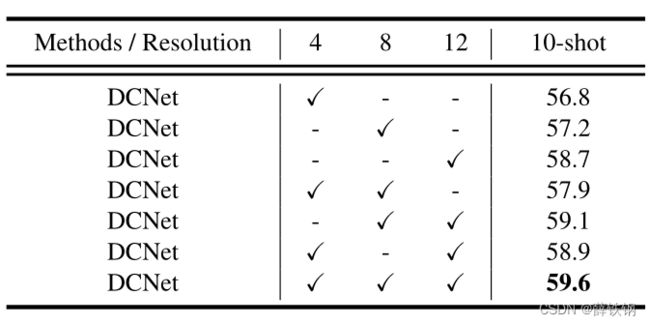
Table 3. The impact of different RoI pooling resolutions. The experiments are conducted on VOC 2007 test set of PASCAL VOC dataset with novel split1 and AP50 on 10-shot task averaged from 10 random runs is reported.
表3。不同RoI池化的影响。在PASCAL VOC数据集的VOC 2007测试集上,采用新型split1和AP50对10次随机运行中平均的10次任务进行了实验。
Impact of context-aware feature aggregation module.
We carry out experiments to evaluate the validity of the proposed context-aware feature aggregation (CFA) module. Specifically, RoI features generated from parallel branches are aggregated with a simple summation. From line 1 and 3 of the table, with the introduction of CFA module, Meta R-CNN achieves notable gains over the baseline. Since CFA module targets at preserving detailed information in a scale-aware manner, different levels of detailed features can be retrieved to assist the prediction process.
上下文感知特性聚合模块的影响。
我们通过实验来评估所提出的上下文感知特征聚合(CFA)模块的有效性。具体来说,从并行分支生成的RoI特征通过简单的求和进行聚合。从表2的第一行和第三行,随着CFA模块的引入,Meta R-CNN比基线取得了显著的进步。由于CFA模块的目标是以规模意识的方式保留详细信息,不同层次的详细特征可以被检索,以帮助预测过程。
Impact of different RoI pooling resolutions.
To further evaluate the impact of different RoI pooling resolutions, we perform explicit experiments to show the detailed perfor-mance. As shown in Table 3, solely adopting larger pooling resolution could yield better performance. However, only when aggregating features generated with all three resolutions, the best performance could be obtained.
不同RoI池化解决方案的影响。
为了进一步评估不同RoI池化的影响,我们进行了显式实验来显示详细的性能。如表3所示,仅采用较大的池化分辨率可以产生更好的性能。然而,只有在聚合所有三种分辨率产生的特征时,才能获得最佳性能。
Impact of attentive aggregation fashion for CFA module. Based on the plain CFA module, we further propose an attention-based aggregation mechanism to adaptively fuse different RoI features. As presented in line 3 and line 4 of Table 2, the attention aggregation mechanism can further boost the performance of the model, which promotes the plain CFA module with a more comprehensive feature representation, effectively balancing the contributions of each extracted features. Finally, with the combination of DRD module and CFA module, we present DCNet, which achieves the best performance according to Table 2.
聚合方式对CFA模块的影响。 在普通CFA模块的基础上,我们进一步提出了一种基于注意力的聚合机制,以自适应融合不同的RoI特征。如表2第3行和第4行所示,注意力聚合机制可以进一步提升模型的性能,促进普通CFA模块具有更全面的特征表示,有效地平衡了每个提取的特征的贡献。最后,通过DRD模块和CFA模块的结合,我们提出了DCNet,其性能达到了表2所示的最佳。
4.2.3 Qualitative Results
To further comprehend the effect of dense relation distillation (DRD) module, we visualize features before and after DRD module. As shown in Fig. 5 (a), after relation distillation, query features can be activated to facilitate the subsequent detection procedure. Moreover, different from former meta-learning based methods which performs prediction in a class-wise manner, our proposed DRD module can model relations between query and support features in all classes at the same time as shown in the second line of Fig. 5 (a). The DRD module enables the model to focus more on the query objects under the guidance of support information. Additionally, we also visualize the effect of CFA module presented in Fig. 5 (b). With a relatively large or small query object as input, DCNet w/o CFA suffers from false classification or missing detection , while the introduction of CFA module could effectively resolve this issue.
为了进一步理解密集关系蒸馏(DRD)模块的效果,我们可视化了DRD模块前后的特征。如图5 (a)所示,在进行关系蒸馏后,可以激活查询特征,方便后续的检测过程。此外,与以往基于元学习的基于类的预测方法不同,我们提出的DRD模块可以同时建模所有类中的查询和支持特征之间的关系,如图5 (a)的第二行所示。DRD模块使模型在支持信息的引导下更关注查询对象。此外,我们还可视化了CFA模块的效果,如图5 (b)所示。当输入的查询对象比较大或比较小时,DCNet w/o CFA存在误分类或漏检的问题,而CFA模块的引入可以有效地解决这一问题。
4.3. Experiments on MS COCO
We evaluate 10/30-shot setups on MS COCO benchmark and report the averaged performance with the standard COCO metrics over 10 runs with random shots. The results on novel classes can be seen in Table 4. Despite the challenging nature of COCO dataset with large number of categories, our proposed DCNet achieves state-of-the-art performance on most of the metrics.
我们在MS COCO基准上评估了10/30次样本设置,并报告了在10次随机样本中使用标准COCO指标的平均表现。新类的结果如表4所示。尽管COCO数据集具有大量类别的挑战性,我们提出的DCNet在大多数指标上实现了最先进的性能。
5. Conclusions
In this paper, we have presented the Dense Relation Distillation Network with Context-aware Aggregation (DCNet) to tackle few-shot object detection problem. Dense relation distillation module adopts dense matching strategy between query and support features to fully exploit support information. Furthermore, context-aware feature aggregation module adaptively harnesses features from different scales to produce a more comprehensive feature representation. The ablation experiments demonstrate the effectiveness of each component of DCNet. Our proposed DCNet achieves state-of-the-art results on two benchmark datasets, i.e. PASCAL VOC and MS COCO.
本文提出了一种基于上下文感知聚合的密集关系蒸馏网络(DCNet)来解决少镜头目标检测问题。密集关系蒸馏模块采用查询与支持特征之间的密集匹配策略,充分利用支持信息。此外,上下文感知的特征聚合模块自适应地利用来自不同尺度的特征,产生更全面的特征表示。消融实验验证了DCNet各组成的有效性。我们提出的DCNet在两个基准数据集上实现了最先进的结果,即PASCAL VOC和MS COCO。