PYTORCH 笔记 DILATE 代码解读
dilate 完整代码路径:vincent-leguen/DILATE: Code for our NeurIPS 2019 paper "Shape and Time Distortion Loss for Training Deep Time Series Forecasting Models" (github.com)
1 main 函数
1.1 导入库
import numpy as np
import torch
from data.synthetic_dataset import create_synthetic_dataset, SyntheticDataset
from models.seq2seq import EncoderRNN, DecoderRNN, Net_GRU
from loss.dilate_loss import dilate_loss
from torch.utils.data import DataLoader
import random
from tslearn.metrics import dtw, dtw_path
import matplotlib.pyplot as plt
import warnings
import warnings; warnings.simplefilter('ignore')1.2 设置超参数
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
random.seed(0)
# parameters
batch_size = 100
N = 500
#训练集和测试集样本的数量(500个时间序列)
N_input = 20
# 输入的time step
N_output = 20
# 输出的time step
sigma = 0.01
# 噪声的标准差
gamma = 0.01
#soft-dtw时需要的平滑参数1.3 导入数据集
num_workers那里,在windows操作环境下,只能设置为0,否则会报错
pytorch错误解决: BrokenPipeError: [Errno 32] Broken pipe_UQI-LIUWJ的博客-CSDN博客
# Load synthetic dataset
X_train_input,X_train_target,X_test_input,X_test_target,train_bkp,test_bkp = \
create_synthetic_dataset(N,N_input,N_output,sigma)
##训练集的 input 训练集的output 测试集的input 测试集的output,训练集的陡降点,测试集的陡降点
dataset_train = SyntheticDataset(X_train_input,
X_train_target,
train_bkp)
dataset_test = SyntheticDataset(X_test_input,
X_test_target,
test_bkp)
trainloader = DataLoader(dataset_train,
batch_size=batch_size,
shuffle=True,
num_workers=0)
testloader = DataLoader(dataset_test,
batch_size=batch_size,
shuffle=False,
num_workers=0)
#train和test的 Dataloader
数据集部分具体实现见 2:
1.4 train_model 训练模型的方法
def train_model(net,
loss_type,
learning_rate,
epochs=1000,
gamma = 0.001,
print_every=50,
eval_every=50,
verbose=1,
Lambda=1,
alpha=0.5):
optimizer = torch.optim.Adam(net.parameters(),lr=learning_rate)
criterion = torch.nn.MSELoss()
#优化函数和默认损失函数
for epoch in range(epochs):
for i, data in enumerate(trainloader, 0):
inputs, target, _ = data
#[batch_size,input_size,1]
inputs = torch.tensor(inputs, dtype=torch.float32).to(device)
target = torch.tensor(target, dtype=torch.float32).to(device)
batch_size, N_output = target.shape[0:2]
# forward + backward + optimize
outputs = net(inputs)
#outputs:[batch_size,output_size,1],学到的输出
loss_mse,loss_shape,loss_temporal = torch.tensor(0),torch.tensor(0),torch.tensor(0)
if (loss_type=='mse'):
loss_mse = criterion(target,outputs)
loss = loss_mse
#如果是mse,那么直接设置loss值,进入接下来的数据更新即可
if (loss_type=='dilate'):
loss, loss_shape, loss_temporal = dilate_loss(target,
outputs,
alpha,
gamma,
device)
#如果是dilate,那么就是用dilate_loss(在loss.dilate_loss中定义)
#见第四小节
if (loss_type=='soft'):
_, loss,loss_temporal = dilate_loss(target,
outputs,
alpha,
gamma,
device)
#如果是soft-dtw,把么就是用dilate_loss中的shape loss
optimizer.zero_grad()
loss.backward()
optimizer.step()
#pytorch 老三样
if(verbose):
if (epoch % print_every == 0):
print('epoch ', epoch, ' loss ',loss.item(),' loss shape ',loss_shape.item(),' loss temporal ',loss_temporal.item())
eval_model(net,testloader, gamma,verbose=1)
#每print_every轮打印一次当前结果1.5 eval_model 函数(评估模型当前的效果)
def eval_model(net,loader, gamma,verbose=1):
criterion = torch.nn.MSELoss()
losses_mse = []
losses_dtw = []
losses_tdi = []
for i, data in enumerate(loader, 0):
loss_mse, loss_dtw, loss_tdi = torch.tensor(0),torch.tensor(0),torch.tensor(0)
# get the inputs
inputs, target, breakpoints = data
#输入值,目标预测值,突变点
inputs = torch.tensor(inputs, dtype=torch.float32).to(device)
target = torch.tensor(target, dtype=torch.float32).to(device)
batch_size, N_output = target.shape[0:2]
outputs = net(inputs)
#预测的输出
# MSE
loss_mse = criterion(target,outputs)
#以MSE作为loss function的情况下,损失函数是多少
loss_dtw, loss_tdi = 0,0
# DTW and TDI
for k in range(batch_size):
#一个batch中的每对时间序列,进行比较
target_k_cpu = target[k,:,0:1].view(-1).detach().cpu().numpy()
output_k_cpu = outputs[k,:,0:1].view(-1).detach().cpu().numpy()
path, sim = dtw_path(target_k_cpu, output_k_cpu)
#dtw的最佳path,dtw最优值
loss_dtw += sim
#这个batch的总和dtw
Dist = 0
for i,j in path:
Dist += (i-j)*(i-j)
#路径上每一个点离对角线的距离
loss_tdi += Dist / (N_output*N_output)
loss_dtw = loss_dtw /batch_size
loss_tdi = loss_tdi / batch_size
# print statistics
losses_mse.append( loss_mse.item() )
losses_dtw.append( loss_dtw )
losses_tdi.append( loss_tdi )
print( ' Eval mse= ', np.array(losses_mse).mean() ,' dtw= ',np.array(losses_dtw).mean() ,' tdi= ', np.array(losses_tdi).mean())
1.6 基本seq2seq模型
详细见3
encoder = EncoderRNN(input_size=1,
hidden_size=128,
num_grulstm_layers=1,
batch_size=batch_size).to(device)
#一个GRU:输入维度1维,输出&隐藏层维度128维,单层GRU,batch_first
decoder = DecoderRNN(input_size=1,
hidden_size=128,
num_grulstm_layers=1,
fc_units=16,
output_size=1).to(device)
'''
一个GRU:输入维度1维,输出&隐藏层维度128维,单层GRU,batch_first
两个全连接:128-》16,16-》1
'''1.7 基于不同的loss function,建立不同的network(并训练之)
注,每个不同的model,需要对应不同的encoder和decoder(也就是每一个network在train之前,都需要新建一堆encoder-decoder
1.7.1 基于Dilate
net_gru_dilate = Net_GRU(encoder,
decoder,
N_output,
device).to(device)
train_model(net_gru_dilate,
loss_type='dilate',
learning_rate=0.001,
epochs=500,
gamma=gamma,
print_every=50,
eval_every=50,
verbose=1)
1.7.2 基于soft-dtw
重新新建一对encoder-decoder
encoder1 = EncoderRNN(input_size=1,
hidden_size=128,
num_grulstm_layers=1,
batch_size=batch_size).to(device)
#一个GRU:输入维度1维,输出&隐藏层维度128维,单层GRU,batch_first
decoder1 = DecoderRNN(input_size=1,
hidden_size=128,
num_grulstm_layers=1,
fc_units=16,
output_size=1).to(device)
'''
一个GRU:输入维度1维,输出&隐藏层维度128维,单层GRU,batch_first
两个全连接:128-》16,16-》1
'''
net_gru_soft = Net_GRU(encoder1,
decoder1,
N_output,
device).to(device)
train_model(net_gru_soft,
loss_type='soft',
learning_rate=0.001,
epochs=500,
gamma=gamma,
print_every=50,
eval_every=50,
verbose=1)1.7.3基于MSE
encoder2 = EncoderRNN(input_size=1,
hidden_size=128,
num_grulstm_layers=1,
batch_size=batch_size).to(device)
#一个GRU:输入维度1维,输出&隐藏层维度128维,单层GRU,batch_first
decoder2 = DecoderRNN(input_size=1,
hidden_size=128,
num_grulstm_layers=1,
fc_units=16,
output_size=1).to(device)
'''
一个GRU:输入维度1维,输出&隐藏层维度128维,单层GRU,batch_first
两个全连接:128-》16,16-》1
'''
net_gru_mse = Net_GRU(encoder2,
decoder2,
N_output,
device).to(device)
train_model(net_gru_mse,
loss_type='mse',
learning_rate=0.001,
epochs=500,
gamma=gamma,
print_every=50,
eval_every=50,
verbose=1)
1.7.4 可视化结果
# Visualize results
gen_test = iter(testloader)
test_inputs, test_targets, breaks = next(gen_test)
#取一个batch的test data
test_inputs = torch.tensor(test_inputs, dtype=torch.float32).to(device)
test_targets = torch.tensor(test_targets, dtype=torch.float32).to(device)
criterion = torch.nn.MSELoss()
nets = [net_gru_mse,net_gru_soft,net_gru_dilate]
for ind in range(1,51):
plt.figure()
plt.rcParams['figure.figsize'] = (30.0,10.0)
k = 1
for net in nets:
pred = net(test_inputs).to(device)
input = test_inputs.detach().cpu().numpy()[ind,:,:]
target = test_targets.detach().cpu().numpy()[ind,:,:]
preds = pred.detach().cpu().numpy()[ind,:,:]
plt.subplot(1,3,k)
#一行三列的三个子图
plt.plot(range(0,N_input) ,input,label='input',linewidth=3)
plt.plot(range(N_input-1,N_input+N_output), np.concatenate([ input[N_input-1:N_input], target ]) ,label='target',linewidth=3)
plt.plot(range(N_input-1,N_input+N_output), np.concatenate([ input[N_input-1:N_input], preds ]) ,label='prediction',linewidth=3)
plt.xticks(range(0,40,2))
plt.legend()
k = k+1
plt.show()2 data/synthetic_dataset.py
2.1 导入库
import numpy as np
import torch
import random
from torch.utils.data import Dataset, DataLoader2.2 create_synthetic_dataset 生成人工合成数据
def create_synthetic_dataset(N, N_input,N_output,sigma):
# N: number of samples in each split (train, test)
# N_input: import of time steps in input series
# N_output: import of time steps in output series
# sigma: standard deviation of additional noise
X = []
breakpoints = []
for k in range(2*N):
serie = np.array([ sigma*random.random() for i in range(N_input+N_output)])
# input 和output的值 N(0,0.01)
i1 = random.randint(1,10)
i2 = random.randint(10,18)
#i1,i2 随机两个input 位置的脉冲信号峰值(产生突变)
j1 = random.random()
j2 = random.random()
#两个脉冲峰值 N(0,1)
interval = abs(i2-i1) + random.randint(-3,3)
#输出陡降的位置
serie[i1:i1+1] += j1
serie[i2:i2+1] += j2
#两个脉冲位置赋值
serie[i2+interval:] += (j2-j1)
#输出陡降的位置之后的位置,全部减去 j2和j1振幅的差距
X.append(serie)
breakpoints.append(i2+interval)
#陡降点
X = np.stack(X)
breakpoints = np.array(breakpoints)
return X[0:N,0:N_input], X[0:N, N_input:N_input+N_output], X[N:2*N,0:N_input], X[N:2*N, N_input:N_input+N_output],breakpoints[0:N], breakpoints[N:2*N]
#训练集的 input 训练集的output 测试集的input 测试集的output,训练集的陡降点,测试集的陡降点
#[N,N_input]2.3 SyntheticDataset 为了pytorch的Dataloader 准备
pytorch笔记:Dataloader_UQI-LIUWJ的博客-CSDN博客_torch的dataloader
class SyntheticDataset(torch.utils.data.Dataset):
def __init__(self, X_input, X_target, breakpoints):
super(SyntheticDataset, self).__init__()
self.X_input = X_input
self.X_target = X_target
self.breakpoints = breakpoints
def __len__(self):
return (self.X_input).shape[0]
def __getitem__(self, idx):
return (self.X_input[idx,:,np.newaxis], self.X_target[idx,:,np.newaxis] , self.breakpoints[idx])
3 seq2seq.py 模型部分
3.1 导入库
import torch
import torch.nn as nn
import torch.nn.functional as F3.2 encoder 部分
pytorch笔记:torch.nn.GRU_UQI-LIUWJ的博客-CSDN博客
class EncoderRNN(torch.nn.Module):
def __init__(self,input_size, hidden_size, num_grulstm_layers, batch_size):
super(EncoderRNN, self).__init__()
self.hidden_size = hidden_size
self.batch_size = batch_size
self.num_grulstm_layers = num_grulstm_layers
self.gru = nn.GRU(input_size=input_size,
hidden_size=hidden_size,
num_layers=num_grulstm_layers,
batch_first=True)
def forward(self, input, hidden):
# input [batch_size, length T, dimensionality d]
output, hidden = self.gru(input, hidden)
return output, hidden
def init_hidden(self,device):
#[num_layers*num_directions,batch,hidden_size]
return torch.zeros(self.num_grulstm_layers,
self.batch_size,
self.hidden_size,
device=device)
#初始化h03.3 decoder部分
class DecoderRNN(nn.Module):
def __init__(self, input_size, hidden_size, num_grulstm_layers,fc_units, output_size):
super(DecoderRNN, self).__init__()
self.gru = nn.GRU(input_size=input_size,
hidden_size=hidden_size,
num_layers=num_grulstm_layers,
batch_first=True)
self.fc = nn.Linear(hidden_size, fc_units)
self.out = nn.Linear(fc_units, output_size)
def forward(self, input, hidden):
output, hidden = self.gru(input, hidden)
output = F.relu( self.fc(output) )
output = self.out(output)
return output, hidden3.4 seq2seq (encoder和decoder拼起来)
class Net_GRU(nn.Module):
#一个encoder-decoder结构
def __init__(self, encoder, decoder, target_length, device):
super(Net_GRU, self).__init__()
self.encoder = encoder
self.decoder = decoder
self.target_length = target_length
self.device = device
def forward(self, x):
#x:[batch_size,input_size,1]
input_length = x.shape[1]
#因为是batch_first,所以这里是sequence length
encoder_hidden = self.encoder.init_hidden(self.device)
#初始化h0 [1,batch_size,hidden_size]
for ei in range(input_length):
encoder_output, encoder_hidden = self.encoder(x[:,ei:ei+1,:] ,
encoder_hidden)
#读入输入的部分
decoder_input = x[:,-1,:].unsqueeze(1)
# first decoder input= last element of input sequence
decoder_hidden = encoder_hidden
#encoder最后一个hidden元素作为decoder第一个hidden元素
outputs = torch.zeros([x.shape[0],
self.target_length,
x.shape[2]] ).to(self.device)
#outputs:[batch_size,output_size,1]
for di in range(self.target_length):
decoder_output, decoder_hidden = self.decoder(decoder_input,
decoder_hidden)
decoder_input = decoder_output
outputs[:,di:di+1,:] = decoder_output
return outputs
#outputs:[batch_size,output_size,1]4 dilate_loss.py 计算dilate_loss
import torch
from . import soft_dtw
from . import path_soft_dtw
def dilate_loss(outputs, targets, alpha, gamma, device):
# outputs, targets: shape (batch_size, N_output, 1)
batch_size, N_output = outputs.shape[0:2]
loss_shape = 0
softdtw_batch = soft_dtw.SoftDTWBatch.apply
#我们自定义了SoftDTWBatch 这个torch.autograd 方法的前向和反向传播
#使用apply,表示softdtw是其的一个别名
D = torch.zeros((batch_size, N_output,N_output )).to(device)
#(batch_size,N_output,N_output)
for k in range(batch_size):
Dk = soft_dtw.pairwise_distances(targets[k,:,:].view(-1,1),
outputs[k,:,:].view(-1,1))
#当前target序列和output序列任意两个点之间的欧几里得距离,拼成一个N_output * N_output的矩阵
D[k:k+1,:,:] = Dk
loss_shape = softdtw_batch(D,gamma)
#这一个batch的平均shape loss
path_dtw = path_soft_dtw.PathDTWBatch.apply
#我们自定义了PathDTWBatch这个torch.autograd 方法的前向和反向传播
#使用apply,表示path_dtw是其的一个别名
path = path_dtw(D,gamma)
#这一个batch 的平均 argminA*的平滑(dtw的一阶梯度)
Omega = soft_dtw.pairwise_distances(
torch.range(1,N_output).view(N_output,1)).to(device)
#||i-j||^2,也就是没有除以k^2的Ω矩阵
loss_temporal = torch.sum( path*Omega ) / (N_output*N_output)
#计算TDI 除的部分是是Ω中的k^2
loss = alpha*loss_shape+ (1-alpha)*loss_temporal
#loss dilate
return loss, loss_shape, loss_temporal pytorch 笔记: 扩展torch.autograd_UQI-LIUWJ的博客-CSDN博客
5 soft_dtw.py 计算soft dtw (shape loss)
5.1 导入库
import numpy as np
import torch
from numba import jit
from torch.autograd import Function
#numba的作用是加速计算5.2 pairwise_distances 两个序列任意两点之间的距离
def pairwise_distances(x, y=None):
'''
Input: x is a Nxd matrix
y is an optional Mxd matirx
Output: dist is a NxM matrix where dist[i,j] is the square norm between x[i,:] and y[j,:]
if y is not given then use 'y=x'.
i.e. dist[i,j] = ||x[i,:]-y[j,:]||^2
'''
'''
x,y :(N_output,1)
'''
x_norm = (x**2).sum(1).view(-1, 1)
#每一个N_output元素的各个维度 算出平方和
#(N_output,1)
if y is not None:
y_t = torch.transpose(y, 0, 1)
y_norm = (y**2).sum(1).view(1, -1)
else:
y_t = torch.transpose(x, 0, 1)
y_norm = x_norm.view(1, -1)
#else算的就是不除以k^2的Ω矩阵了
dist = x_norm + y_norm - 2.0 * torch.mm(x, y_t)
#||x-y||^2
return torch.clamp(dist, 0.0, float('inf'))
#[0,+inf]的范围
#x序列和y序列任意两个点之间的欧几里得距离
5.3 compute_softdtw 计算soft-dtw
@jit(nopython = True)
def compute_softdtw(D, gamma):
#D_[k,:,:]————当前target序列和output序列任意两个点之间的欧几里得距离
N = D.shape[0]
M = D.shape[1]
#N,M 都是N_output
R = np.zeros((N + 2, M + 2)) + 1e8
#给N*M的R矩阵周围围上一圈,防止下标越界
R[0, 0] = 0
for j in range(1, M + 1):
for i in range(1, N + 1):
r0 = -R[i - 1, j - 1] / gamma
r1 = -R[i - 1, j] / gamma
r2 = -R[i, j - 1] / gamma
rmax = max(max(r0, r1), r2)
rsum = np.exp(r0 - rmax) + np.exp(r1 - rmax) + np.exp(r2 - rmax)
softmin = - gamma * (np.log(rsum) + rmax)
#rmax的出现是为了防止exp之后,数值过大,导致上溢出
R[i, j] = D[i - 1, j - 1] + softmin
#由于R周围围了一圈,所以R[i,j]对应的是D[i-1,j-1]
#即soft-dtw的递推公式
return R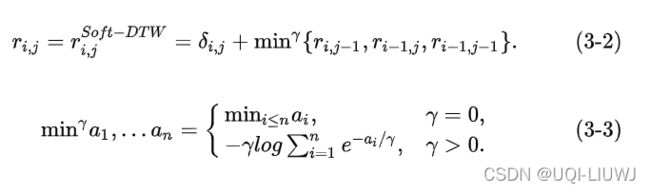
5.4 compute_softdtw_backward 使用动态规划的soft-dtw反向传播
@jit(nopython = True)
def compute_softdtw_backward(D_, R, gamma):
#这里其实也是在计算dtw,只不过实现方式和path_soft_dtw里面的略有不同
#D_——当前target序列和output序列任意两个点之间的欧几里得距离
N = D_.shape[0]
M = D_.shape[1]
#(N_output,N_output)
D = np.zeros((N + 2, M + 2))
E = np.zeros((N + 2, M + 2))
D[1:N + 1, 1:M + 1] = D_
E[-1, -1] = 1
R[:, -1] = -1e8
R[-1, :] = -1e8
R[-1, -1] = R[-2, -2]
for j in range(M, 0, -1):
for i in range(N, 0, -1):
a0 = (R[i + 1, j] - R[i, j] - D[i + 1, j]) / gamma
b0 = (R[i, j + 1] - R[i, j] - D[i, j + 1]) / gamma
c0 = (R[i + 1, j + 1] - R[i, j] - D[i + 1, j + 1]) / gamma
#γ log d (r_i+1,j)/d (r_i,j)=(r_i+1,j)-(r_i,j)-(δ_i+1,j)
a = np.exp(a0)
b = np.exp(b0)
c = np.exp(c0)
E[i, j] = E[i + 1, j] * a + E[i, j + 1] * b + E[i + 1, j + 1] * c
return E[1:N + 1, 1:M + 1]

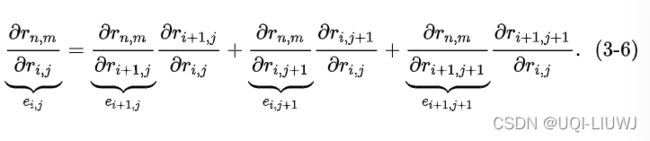
5.5 SoftDTWBatch——自定义的、扩展torch.autograd的损失函数(L-shape)
class SoftDTWBatch(Function):
@staticmethod
def forward(ctx, D, gamma = 1.0):
# D.shape: [batch_size, N , N]
#D_——当前target序列和output序列任意两个点之间的欧几里得距离
dev = D.device
batch_size,N,N = D.shape
#(batch_size,N_output,N_output)
gamma = torch.FloatTensor([gamma]).to(dev)
D_ = D.detach().cpu().numpy()
g_ = gamma.item()
#soft-dtw需要的γ
total_loss = 0
R = torch.zeros((batch_size, N+2 ,N+2)).to(dev)
#(batch_size,N_output+2,N_output+2)
for k in range(0, batch_size):
# 一个batch中每对sequence都进行比较
Rk = torch.FloatTensor(compute_softdtw(D_[k,:,:], g_)).to(dev)
'''
D_[k,:,:]
#当前target序列和output序列任意两个点之间的欧几里得距离
'''
R[k:k+1,:,:] = Rk
#R——softdtw的结果矩阵
total_loss = total_loss + Rk[-2,-2]
ctx.save_for_backward(D, R, gamma)
return total_loss / batch_size
#这一个batch的平均shape loss
@staticmethod
def backward(ctx, grad_output):
dev = grad_output.device
D, R, gamma = ctx.saved_tensors
batch_size,N,N = D.shape
D_ = D.detach().cpu().numpy()
R_ = R.detach().cpu().numpy()
g_ = gamma.item()
E = torch.zeros((batch_size, N ,N)).to(dev)
for k in range(batch_size):
Ek = torch.FloatTensor(compute_softdtw_backward(D_[k,:,:], R_[k,:,:], g_)).to(dev)
#Ek就是之前所说的E矩阵
E[k:k+1,:,:] = Ek
return grad_output * E, None
#D的loss

6 path_soft_dtw 计算temporal loss
6.1 导入库
import numpy as np
import torch
from torch.autograd import Function
from numba import jit6.2 辅助函数
6.2.1 my_max
@jit(nopython = True)
def my_max(x, gamma):
# use the log-sum-exp trick
max_x = np.max(x)
exp_x = np.exp((x - max_x) / gamma)
Z = np.sum(exp_x)
return gamma * np.log(Z) + max_x, exp_x / Z
#相当于是max(x),(e^x)/(Σe^x)6.2.2 my_min
@jit(nopython = True)
def my_min(x,gamma) :
min_x, argmax_x = my_max(-x, gamma)
return - min_x, argmax_x
#相当于是min(x),(e^x)/(Σe^x)6.2.3 my_max_hessian_product & my_min_hessian_product
二阶导的部分我其实没太搞明白
@jit(nopython = True)
def my_max_hessian_product(p, z, gamma):
return ( p * z - p * np.sum(p * z) ) /gamma
@jit(nopython = True)
def my_min_hessian_product(p, z, gamma):
return - my_max_hessian_product(p, z, gamma)6.2.4 dtw_grad
@jit(nopython = True)
def dtw_grad(theta, gamma):
#theta——当前target序列和output序列任意两个点之间的欧几里得距离
m = theta.shape[0]
n = theta.shape[1]
#(N_output,N_output)
V = np.zeros((m + 1, n + 1))
V[:, 0] = 1e10
V[0, :] = 1e10
V[0, 0] = 0
Q = np.zeros((m + 2, n + 2, 3))
for i in range(1, m + 1):
for j in range(1, n + 1):
# theta is indexed starting from 0.
v, Q[i, j] = my_min(np.array([V[i, j - 1],
V[i - 1, j - 1],
V[i - 1, j]]) , gamma)
#min(V[i, j - 1],V[i - 1, j - 1],V[i - 1, j]])
'''
第二项相当于
e^{-r i,j-1}/(e^{-r i,j-1}+e^{-r i-1,j-1}+e^{-r i-1,j})=d r i,j/d r i,j-1
e^{-r i-1,j-1}/(e^{-r i,j-1}+e^{-r i-1,j-1}+e^{-r i-1,j})=d r i,j/d r i-1,j-1
e^{-r i-1,j}/(e^{-r i,j-1}+e^{-r i-1,j-1}+e^{-r i-1,j})=d r i,j/d r i-1,j
'''
V[i, j] = theta[i - 1, j - 1] + v
#soft-dtw结果矩阵
E = np.zeros((m + 2, n + 2))
#也是外面围了一圈
E[m + 1, :] = 0
E[:, n + 1] = 0
E[m + 1, n + 1] = 1
Q[m + 1, n + 1] = 1
for i in range(m,0,-1):
for j in range(n,0,-1):
E[i, j] = Q[i, j + 1, 0] * E[i, j + 1] + \
Q[i + 1, j + 1, 1] * E[i + 1, j + 1] + \
Q[i + 1, j, 2] * E[i + 1, j]
#e ij=d (r_i,j+1)/d (r_i,j) * e_i,j+1+\
# d (r_i+1,j+1)/d (r_i,j) * e_i+1,j+1+\
# d (r_i+1,j)/ d(r_i,j) * e_i+1,j
#soft-dtw backward DTW的一阶导
return V[m, n], E[1:m + 1, 1:n + 1], Q, E
'''
V:soft-dtw 结果
E: dtw一阶导
Q:每一个元素都是r_i,j 相对与影响他前向传播的r的偏导(顺时针顺序)
'''

6.2.5 dtw_hessian_prod dtw一阶梯度的梯度(散度)
@jit(nopython = True)
def dtw_hessian_prod(theta, Z, Q, E, gamma):
#theta——当前target序列和output序列任意两个点之间的欧几里得距离
#Z-#input的梯度
#Q_cpu_k:每一个元素都是r_i,j 相对与影响他前向传播的r的偏导(顺时针顺序)
#E_cpu_k: dtw一阶导(外面围了一圈0)
m = Z.shape[0]
n = Z.shape[1]
V_dot = np.zeros((m + 1, n + 1))
V_dot[0, 0] = 0
Q_dot = np.zeros((m + 2, n + 2, 3))
for i in range(1, m + 1):
for j in range(1, n + 1):
# theta is indexed starting from 0.
V_dot[i, j] = Z[i - 1, j - 1] + \
Q[i, j, 0] * V_dot[i, j - 1] + \
Q[i, j, 1] * V_dot[i - 1, j - 1] + \
Q[i, j, 2] * V_dot[i - 1, j]
v = np.array([V_dot[i, j - 1],
V_dot[i - 1, j - 1],
V_dot[i - 1, j]])
Q_dot[i, j] = my_min_hessian_product(Q[i, j], v, gamma)
E_dot = np.zeros((m + 2, n + 2))
for j in range(n,0,-1):
for i in range(m,0,-1):
E_dot[i, j] = Q_dot[i, j + 1, 0] * E[i, j + 1] + \
Q[i, j + 1, 0] * E_dot[i, j + 1] + \
Q_dot[i + 1, j + 1, 1] * E[i + 1, j + 1] + \
Q[i + 1, j + 1, 1] * E_dot[i + 1, j + 1] + \
Q_dot[i + 1, j, 2] * E[i + 1, j] + \
Q[i + 1, j, 2] * E_dot[i + 1, j]
#二阶何塞矩阵的链式法则(带dot的就是二阶导)
return V_dot[m, n], E_dot[1:m + 1, 1:n + 1]6.2.6 PathDTWBatch——返回argminA*
class PathDTWBatch(Function):
@staticmethod
def forward(ctx, D, gamma): # D.shape: [batch_size, N , N]
#D——当前target序列和output序列任意两个点之间的欧几里得距离
batch_size,N,N = D.shape
#(batch_size,N_output,N_output)
device = D.device
D_cpu = D.detach().cpu().numpy()
gamma_gpu = torch.FloatTensor([gamma]).to(device)
grad_gpu = torch.zeros((batch_size, N ,N)).to(device)
Q_gpu = torch.zeros((batch_size, N+2 ,N+2,3)).to(device)
E_gpu = torch.zeros((batch_size, N+2 ,N+2)).to(device)
for k in range(0,batch_size): # loop over all D in the batch
_, grad_cpu_k, Q_cpu_k, E_cpu_k = dtw_grad(D_cpu[k,:,:], gamma)
'''
V:soft-dtw 结果
grad_cpu_k: dtw一阶导 [1:m + 1, 1:n + 1] argmin的平滑近似
Q_cpu_k:每一个元素都是r_i,j 相对与影响他前向传播的r的偏导(顺时针顺序)
E_cpu_k: dtw一阶导(外面围了一圈0)
'''
grad_gpu[k,:,:] = torch.FloatTensor(grad_cpu_k).to(device)
Q_gpu[k,:,:,:] = torch.FloatTensor(Q_cpu_k).to(device)
E_gpu[k,:,:] = torch.FloatTensor(E_cpu_k).to(device)
ctx.save_for_backward(grad_gpu,D, Q_gpu ,E_gpu, gamma_gpu)
return torch.mean(grad_gpu, dim=0)
#把一个batch的平均掉
#argminA*
@staticmethod
def backward(ctx, grad_output):
device = grad_output.device
grad_gpu, D_gpu, Q_gpu, E_gpu, gamma = ctx.saved_tensors
D_cpu = D_gpu.detach().cpu().numpy()
#D——当前target序列和output序列任意两个点之间的欧几里得距离
Q_cpu = Q_gpu.detach().cpu().numpy()
#Q_cpu_k:每一个元素都是r_i,j 相对与影响他前向传播的r的偏导(顺时针顺序)
E_cpu = E_gpu.detach().cpu().numpy()
#E_cpu_k: dtw一阶导(外面围了一圈0)
gamma = gamma.detach().cpu().numpy()[0]
Z = grad_output.detach().cpu().numpy()
#input的梯度
batch_size,N,N = D_cpu.shape
Hessian = torch.zeros((batch_size, N ,N)).to(device)
for k in range(0,batch_size):
_, hess_k = dtw_hessian_prod(D_cpu[k,:,:],
Z,
Q_cpu[k,:,:,:],
E_cpu[k,:,:],
gamma)
Hessian[k:k+1,:,:] = torch.FloatTensor(hess_k).to(device)
return Hessian, None