代数与逻辑:作业四 神经网络
代数与逻辑:作业四 神经网络
文章目录
- 代数与逻辑:作业四 神经网络
-
- 一、作业要求
- 二、简述神经网络模型
- 三、编程实现感知机模型与二隐层神经网络
-
- 1、感知机模型
- 2、二隐层神经网络
- 四、选择公开数据集,测试感知机模型与二隐层神经网络性能
一、作业要求
- 简述神经网络模型
- 编程实现感知机模型与二隐层神经网络
- 选择公开数据集,测试感知机模型与二隐层神经网络性能
二、简述神经网络模型
神经网络(Neural Networks,NN)是由大量的、简单的处理单元(称为神经元)广泛地互相连接而形成的复杂网络系统,它反映了人脑功能的许多基本特征,是一个高度复杂的非线性动力学习系统。神经网络具有大规模并行、分布式存储和处理、自组织、自适应和自学能力,特别适合处理需要同时考虑许多因素和条件的、不精确和模糊的信息处理问题。神经网络的发展与神经科学、数理科学、认知科学、计算机科学、人工智能、信息科学、控制论、机器人学、微电子学、心理学、光计算、分子生物学等有关,是一门新兴的边缘交叉学科。
神经网络的基础在于神经元。
神经元是以生物神经系统的神经细胞为基础的生物模型。在人们对生物神经系统进行研究,以探讨人工智能的机制时,把神经元数学化,从而产生了神经元数学模型。
大量的形式相同的神经元连结在—起就组成了神经网络。神经网络是一个高度非线性动力学系统。虽然,每个神经元的结构和功能都不复杂,但是神经网络的动态行为则是十分复杂的;因此,用神经网络可以表达实际物理世界的各种现象。
神经网络模型是以神经元的数学模型为基础来描述的。人工神经网络(ArtificialNuearlNewtokr)s,是对人类大脑系统的一阶特性的一种描。简单地讲,它是一个数学模型。神经网络模型由网络拓扑.节点特点和学习规则来表示。神经网络对人们的巨大吸引力主要在下列几点:
- 并行分布处理。
- 高度鲁棒性和容错能力。
- 分布存储及学习能力。
- 能充分逼近复杂的非线性关系。
在控制领域的研究课题中,不确定性系统的控制问题长期以来都是控制理论研究的中心主题之一,但是这个问题一直没有得到有效的解决。利用神经网络的学习能力,使它在对不确定性系统的控制过程中自动学习系统的特性,从而自动适应系统随时间的特性变异,以求达到对系统的最优控制;显然这是一种十分振奋人心的意向和方法。
人工神经网络的模型现在有数十种之多,应用较多的典型的神经网络模型包括BP神经网络、Hopfield网络、ART网络和Kohonen网络。
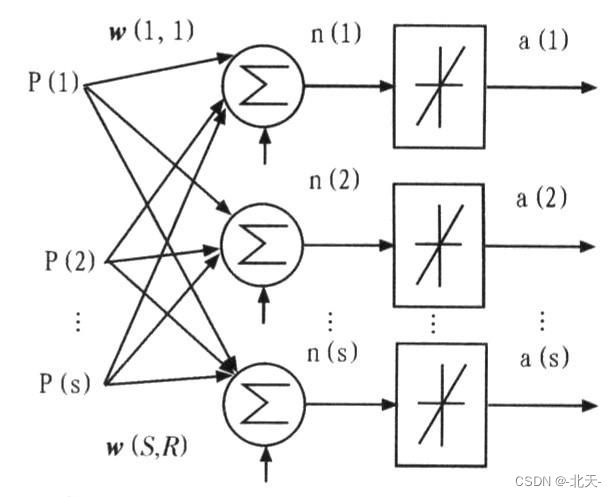
三、编程实现感知机模型与二隐层神经网络
1、感知机模型
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import joblib
plt.style.use("fivethirtyeight")
class Perceptron:
def __init__(self, eta, epochs):
self.weights = np.random.randn(3) * 1e-4 # 随机权重分配
print(f"训练前的初始权重: n{self.weights}")
self.eta = eta # 学习率
self.epochs = epochs
def activationFunction(self, inputs, weights):
z = np.dot(inputs, weights) # z = W * X
return np.where(z > 0, 1, 0) # 激活函数
def fit(self, X, y):
self.X = X
self.y = y
X_with_bias = np.c_[self.X, -np.ones((len(self.X), 1))]
print(f"X 偏差: n{X_with_bias}")
for epoch in range(self.epochs):
print("--"*10)
print(f"for epoch: {epoch}")
print("--"*10)
y_hat = self.activationFunction(X_with_bias, self.weights) # 向前传播
print(f"前向传播后的预测值: n{y_hat}")
self.error = self.y - y_hat
print(f"错误: n{self.error}")
self.weights = self.weights + self.eta * np.dot(X_with_bias.T, self.error) # 反向传播
print(f"epoc后更新权重:n{epoch}/{self.epochs} : n{self.weights}")
print("#####"*10)
def predict(self, X):
X_with_bias = np.c_[X, -np.ones((len(X), 1))]
return self.activationFunction(X_with_bias, self.weights) # 预测功能
def total_loss(self):
total_loss = np.sum(self.error)
print(f"总体损耗: {total_loss}")
return total_loss
def prepare_data(df):
X=df.drop("y",axis=1)
y=df["y"]
return X,y
AND = {
"x1": [0,0,1,1],
"x2": [0,1,0,1],
"y": [0,0,0,1],
}
df = pd.DataFrame(AND)
X,y = prepare_data(df)
ETA = 0.3 # 0 和 1
EPOCHS = 10
model = Perceptron(eta=ETA, epochs=EPOCHS)
model.fit(X, y)# 调用函数
model.total_loss()
运行的结果是:
训练前的初始权重: n[-7.00846923e-05 -3.71909786e-05 -6.15635785e-05]
X 偏差: n[[ 0. 0. -1.]
[ 0. 1. -1.]
[ 1. 0. -1.]
[ 1. 1. -1.]]
--------------------
for epoch: 0
--------------------
前向传播后的预测值: n[1 1 0 0]
错误: n0 -1
1 -1
2 0
3 1
Name: y, dtype: int64
epoc后更新权重:n0/10 : n[ 2.99929915e-01 -3.71909786e-05 2.99938436e-01]
##################################################
--------------------
for epoch: 1
--------------------
前向传播后的预测值: n[0 0 0 0]
错误: n0 0
1 0
2 0
3 1
Name: y, dtype: int64
epoc后更新权重:n1/10 : n[ 5.99929915e-01 2.99962809e-01 -6.15635785e-05]
##################################################
--------------------
for epoch: 2
--------------------
前向传播后的预测值: n[1 1 1 1]
错误: n0 -1
1 -1
2 -1
3 0
Name: y, dtype: int64
epoc后更新权重:n2/10 : n[ 2.99929915e-01 -3.71909786e-05 8.99938436e-01]
##################################################
--------------------
for epoch: 3
--------------------
前向传播后的预测值: n[0 0 0 0]
错误: n0 0
1 0
2 0
3 1
Name: y, dtype: int64
epoc后更新权重:n3/10 : n[0.59992992 0.29996281 0.59993844]
##################################################
--------------------
for epoch: 4
--------------------
前向传播后的预测值: n[0 0 0 1]
错误: n0 0
1 0
2 0
3 0
Name: y, dtype: int64
epoc后更新权重:n4/10 : n[0.59992992 0.29996281 0.59993844]
##################################################
--------------------
for epoch: 5
--------------------
前向传播后的预测值: n[0 0 0 1]
错误: n0 0
1 0
2 0
3 0
Name: y, dtype: int64
epoc后更新权重:n5/10 : n[0.59992992 0.29996281 0.59993844]
##################################################
--------------------
for epoch: 6
--------------------
前向传播后的预测值: n[0 0 0 1]
错误: n0 0
1 0
2 0
3 0
Name: y, dtype: int64
epoc后更新权重:n6/10 : n[0.59992992 0.29996281 0.59993844]
##################################################
--------------------
for epoch: 7
--------------------
前向传播后的预测值: n[0 0 0 1]
错误: n0 0
1 0
2 0
3 0
Name: y, dtype: int64
epoc后更新权重:n7/10 : n[0.59992992 0.29996281 0.59993844]
##################################################
--------------------
for epoch: 8
--------------------
前向传播后的预测值: n[0 0 0 1]
错误: n0 0
1 0
2 0
3 0
Name: y, dtype: int64
epoc后更新权重:n8/10 : n[0.59992992 0.29996281 0.59993844]
##################################################
--------------------
for epoch: 9
--------------------
前向传播后的预测值: n[0 0 0 1]
错误: n0 0
1 0
2 0
3 0
Name: y, dtype: int64
epoc后更新权重:n9/10 : n[0.59992992 0.29996281 0.59993844]
##################################################
总体损耗: 0
2、二隐层神经网络
# importing the library
import numpy as np
# 创建输入数组
X=np.array([[1,0,1,0],[1,0,1,1],[0,1,0,1]])
print ('\n 输入:')
print(X)
# 创建输出数组
y=np.array([[1],[1],[0]])
print ('\n 实际输出:')
print(y)
# 定义 Sigmoid 函数
def sigmoid (x):
return 1/(1 + np.exp(-x))
# Sigmoid 函数的导数
def derivatives_sigmoid(x):
return x * (1 - x)
# 初始化变量
epoch=5000 # 训练迭代次数
lr=0.1 # 学习率
inputlayer_neurons = X.shape[1] # 数据集中的特征数量
hiddenlayer_neurons = 3 # 隐藏层神经元数量
output_neurons = 1 # 输出层神经元数量
# 初始化权重和偏差
wh=np.random.uniform(size=(inputlayer_neurons,hiddenlayer_neurons))
bh=np.random.uniform(size=(1,hiddenlayer_neurons))
wout=np.random.uniform(size=(hiddenlayer_neurons,output_neurons))
bout=np.random.uniform(size=(1,output_neurons))
# 训练模型
for i in range(epoch):
# 前向传播
hidden_layer_input1=np.dot(X,wh)
hidden_layer_input=hidden_layer_input1 + bh
hiddenlayer_activations = sigmoid(hidden_layer_input)
output_layer_input1=np.dot(hiddenlayer_activations,wout)
output_layer_input= output_layer_input1+ bout
output = sigmoid(output_layer_input)
# 反向传播
E = y-output
slope_output_layer = derivatives_sigmoid(output)
slope_hidden_layer = derivatives_sigmoid(hiddenlayer_activations)
d_output = E * slope_output_layer
Error_at_hidden_layer = d_output.dot(wout.T)
d_hiddenlayer = Error_at_hidden_layer * slope_hidden_layer
wout += hiddenlayer_activations.T.dot(d_output) *lr
bout += np.sum(d_output, axis=0,keepdims=True) *lr
wh += X.T.dot(d_hiddenlayer) *lr
bh += np.sum(d_hiddenlayer, axis=0,keepdims=True) *lr
print ('\n 模型的输出:')
print (output)
运行的结果是:
输入:
[[1 0 1 0]
[1 0 1 1]
[0 1 0 1]]
实际输出:
[[1]
[1]
[0]]
模型的输出:
[[0.98491117]
[0.97408061]
[0.03540449]]
四、选择公开数据集,测试感知机模型与二隐层神经网络性能
首先,可以使用scikit-learn库中的load_*函数来加载公开数据集,例如load_iris()来加载鸢尾花数据集。
然后,可以使用Perceptron或MLPClassifier类来实例化感知机模型或2隐层神经网络模型,并使用fit()函数来训练模型。
最后,可以使用score()函数来评估模型的性能,或使用cross_val_score()函数来使用交叉验证来评估模型性能。
from sklearn.datasets import load_iris
from sklearn.neural_network import MLPClassifier
from sklearn.linear_model import Perceptron
from sklearn.model_selection import cross_val_score
iris = load_iris()
X, y = iris.data, iris.target
#使用感知机模型
perceptron = Perceptron()
scores = cross_val_score(perceptron, X, y)
print("感知机模型: %0.2f (+/- %0.2f)" % (scores.mean(), scores.std() * 2))
#使用2隐层神经网络模型
mlp = MLPClassifier(hidden_layer_sizes=(2,))
scores = cross_val_score(mlp, X, y)
print("2隐层神经网络: %0.2f (+/- %0.2f)" % (scores.mean(), scores.std() * 2))
运行的结果是:
感知机模型: 0.73 (+/- 0.13)
2隐层神经网络: 0.35 (+/- 0.27)