因果推断6--多任务学习(个人笔记)
目录
1多任务学习
1.1问题描述
1.2数据集
1.3网络结构
1.4结果
2因果推断使用多任务方式
2.1DRNet
2.2Dragonet
2.3Deep counterfactual networks with propensity-dropout
2.4VCNet
3思考
1多任务学习
keras-mmoe/census_income_demo.py at master · drawbridge/keras-mmoe · GitHub
推荐系统-(16)多任务学习:谷歌MMOE原理与实践 - 知乎
1.1问题描述
近年来,深度神经网络的应用越来越广,如推荐系统。推荐系统通常需要同时优化多个目标,如电影推荐中不仅需要预测用户是否会购买,还需要预测用户对于电影的评分,在比如电商领域同时需要预测物品的点击率CTR和转化率CVR。因此,多任务学习模型成为研究领域的一大热点。
1.2数据集
- Example demo of running the model with the census-income dataset from UCI
- This dataset is the same one in Section 6.3 of the paper
1.3网络结构
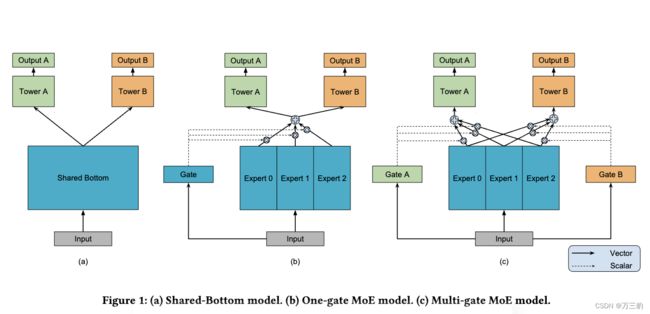
1.4结果
2因果推断使用多任务方式
采用多任务学习方式学习因果关系,尤其是多调研推荐系统的多任务学习模式,进行相应的补充。
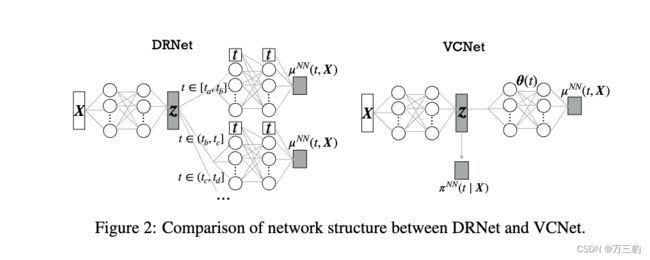
2.1DRNet
Learning Counterfactual Representations for Estimating Individual Dose-Response Curves

- L1 base layers的参数参与所有数据集的训练,L2 treatment layers的参数只参与Treatment组样本的训练
- 能够应用于更加复杂的干预场景下,离散状态干预+连续状态干预,对于每一种干预组合,分别使用head网络进行学习
- 我们举个通俗易懂的case,我们想试验不同药剂对不同病人的影响。t=0~k-1分别代表不同组别病人,t=0是正常组,t=1~k-1 分别代表糖尿病人组,高血压病人组以及其它病人组,药剂量级m分为a,b,c分别代表低剂量/中剂量/高剂量,分别对t和m的不同组合采用head网络学习。每个处理层进一步细分为E个头部层(上面只显示了t = 0处理的一组E = 3个头部层)。
2.2Dragonet
Adapting Neural Network for the Estimation of Treatment Effects
- dragonNet(学习非线性关系):两阶段方法,先学习表示模型,在学习推断模型
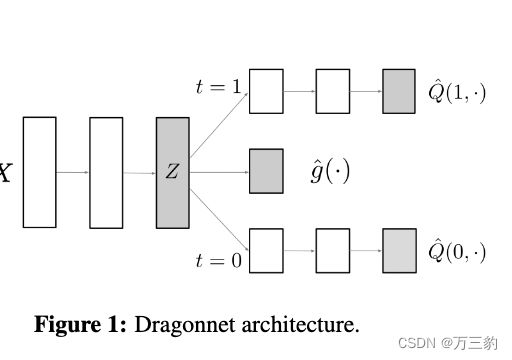
如果倾向分的网络丢掉之后, 这个网络结构就是和TARNET的结构相同,后面做了和这种方法的试验对比。 这个loss 中有倾向分部分这个部分会导致网络权重对于g(x) 相关性差的特征自动权重降低,有利于进行特征选择。 下面引入target regularizaiton 进行loss的改进。
2.3Deep counterfactual networks with propensity-dropout
摘要: 我们提出了一种从观察数据推断治疗(干预)的个体化因果效应的新方法。我们的方法将因果推断概念化为一个多任务学习问题;我们使用一个深度多任务网络,在事实和反事实结果之间有一组共享层,以及一组特定于结果的层,为受试者的潜在结果建模。通过倾向-退出正则化方案缓解了观察数据中选择偏差的影响,其中网络通过依赖于相关倾向分数的退出概率对每个训练示例进行减薄。该网络在交替阶段进行训练,在每个阶段中,我们使用两个潜在结果之一(处理过的和控制过的人群)的训练示例来更新共享层和各自特定结果层的权重。基于真实世界观察研究的数据进行的实验表明,我们的算法优于最先进的算法。
代码:GitHub - Shantanu48114860/Deep-Counterfactual-Networks-with-Propensity-Dropout: Implementation of the paper "Deep Counterfactual Networks with Propensity-Dropout"(https://arxiv.org/pdf/1706.05966.pdf) in pytorch framework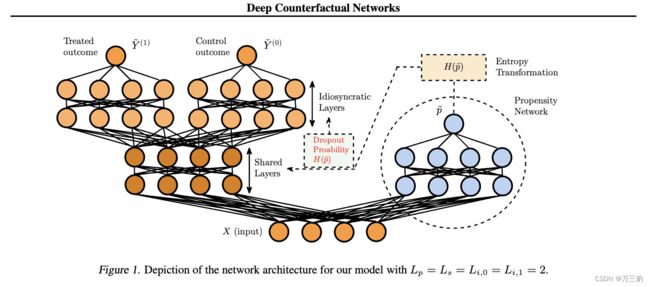
- 模型采用多目标建模思想,将Treatment组和Control组样本放在同一个模型中,降低模型冗余
- 左边部分是多目标框架,Treatment组和Control组的样本有共享层和各自独立的网络层,从而来学习Treatment模型和Control模型
- 右边Propensity Network网络主要控制左边模型的复杂度,如果数据好分,通过生成Dropout-Propensity控制左边模型,让其简单些;如果数据不好分,则控制左边模型复杂些
- 训练的时候Treatment组和Control组的样本分开训练,迭代次数是奇数时,训练Treatment组样本;偶数时,训练Control组样本
网络:
如果一个参数requires_grad=False,并且这个参数在optimizer里面,则不对它进行更新,并且程序不会报错
network.hidden1_Y1.weight.requires_grad = False
import torch
import torch.nn as nn
import torch.optim as optim
from DCN import DCN
class DCN_network:
def train(self, train_parameters, device):
epochs = train_parameters["epochs"]
treated_batch_size = train_parameters["treated_batch_size"]
control_batch_size = train_parameters["control_batch_size"]
lr = train_parameters["lr"]
shuffle = train_parameters["shuffle"]
model_save_path = train_parameters["model_save_path"].format(epochs, lr)
treated_set = train_parameters["treated_set"]
control_set = train_parameters["control_set"]
print("Saved model path: {0}".format(model_save_path))
treated_data_loader = torch.utils.data.DataLoader(treated_set,
batch_size=treated_batch_size,
shuffle=shuffle,
num_workers=1)
control_data_loader = torch.utils.data.DataLoader(control_set,
batch_size=control_batch_size,
shuffle=shuffle,
num_workers=1)
network = DCN(training_flag=True).to(device)
optimizer = optim.Adam(network.parameters(), lr=lr)
lossF = nn.MSELoss()
min_loss = 100000.0
dataset_loss = 0.0
print(".. Training started ..")
print(device)
for epoch in range(epochs):
network.train()
total_loss = 0
train_set_size = 0
if epoch % 2 == 0:
dataset_loss = 0
# train treated
network.hidden1_Y1.weight.requires_grad = True
network.hidden1_Y1.bias.requires_grad = True
network.hidden2_Y1.weight.requires_grad = True
network.hidden2_Y1.bias.requires_grad = True
network.out_Y1.weight.requires_grad = True
network.out_Y1.bias.requires_grad = True
network.hidden1_Y0.weight.requires_grad = False
network.hidden1_Y0.bias.requires_grad = False
network.hidden2_Y0.weight.requires_grad = False
network.hidden2_Y0.bias.requires_grad = False
network.out_Y0.weight.requires_grad = False
network.out_Y0.bias.requires_grad = False
for batch in treated_data_loader:
covariates_X, ps_score, y_f, y_cf = batch
covariates_X = covariates_X.to(device)
ps_score = ps_score.squeeze().to(device)
train_set_size += covariates_X.size(0)
treatment_pred = network(covariates_X, ps_score)
# treatment_pred[0] -> y1
# treatment_pred[1] -> y0
predicted_ITE = treatment_pred[0] - treatment_pred[1]
true_ITE = y_f - y_cf
if torch.cuda.is_available():
loss = lossF(predicted_ITE.float().cuda(),
true_ITE.float().cuda()).to(device)
else:
loss = lossF(predicted_ITE.float(),
true_ITE.float()).to(device)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
dataset_loss = total_loss
elif epoch % 2 == 1:
# train controlled
network.hidden1_Y1.weight.requires_grad = False
network.hidden1_Y1.bias.requires_grad = False
network.hidden2_Y1.weight.requires_grad = False
network.hidden2_Y1.bias.requires_grad = False
network.out_Y1.weight.requires_grad = False
network.out_Y1.bias.requires_grad = False
network.hidden1_Y0.weight.requires_grad = True
network.hidden1_Y0.bias.requires_grad = True
network.hidden2_Y0.weight.requires_grad = True
network.hidden2_Y0.bias.requires_grad = True
network.out_Y0.weight.requires_grad = True
network.out_Y0.bias.requires_grad = True
for batch in control_data_loader:
covariates_X, ps_score, y_f, y_cf = batch
covariates_X = covariates_X.to(device)
ps_score = ps_score.squeeze().to(device)
train_set_size += covariates_X.size(0)
treatment_pred = network(covariates_X, ps_score)
# treatment_pred[0] -> y1
# treatment_pred[1] -> y0
predicted_ITE = treatment_pred[0] - treatment_pred[1]
true_ITE = y_cf - y_f
if torch.cuda.is_available():
loss = lossF(predicted_ITE.float().cuda(),
true_ITE.float().cuda()).to(device)
else:
loss = lossF(predicted_ITE.float(),
true_ITE.float()).to(device)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
dataset_loss = dataset_loss + total_loss
print("epoch: {0}, train_set_size: {1} loss: {2}".
format(epoch, train_set_size, total_loss))
if epoch % 2 == 1:
print("Treated + Control loss: {0}".format(dataset_loss))
# if dataset_loss < min_loss:
# print("Current loss: {0}, over previous: {1}, Saving model".
# format(dataset_loss, min_loss))
# min_loss = dataset_loss
# torch.save(network.state_dict(), model_save_path)
torch.save(network.state_dict(), model_save_path)
@staticmethod
def eval(eval_parameters, device):
print(".. Evaluation started ..")
treated_set = eval_parameters["treated_set"]
control_set = eval_parameters["control_set"]
model_path = eval_parameters["model_save_path"]
network = DCN(training_flag=False).to(device)
network.load_state_dict(torch.load(model_path, map_location=device))
network.eval()
treated_data_loader = torch.utils.data.DataLoader(treated_set,
shuffle=False, num_workers=1)
control_data_loader = torch.utils.data.DataLoader(control_set,
shuffle=False, num_workers=1)
err_treated_list = []
err_control_list = []
for batch in treated_data_loader:
covariates_X, ps_score, y_f, y_cf = batch
covariates_X = covariates_X.to(device)
ps_score = ps_score.squeeze().to(device)
treatment_pred = network(covariates_X, ps_score)
predicted_ITE = treatment_pred[0] - treatment_pred[1]
true_ITE = y_f - y_cf
if torch.cuda.is_available():
diff = true_ITE.float().cuda() - predicted_ITE.float().cuda()
else:
diff = true_ITE.float() - predicted_ITE.float()
err_treated_list.append(diff.item())
for batch in control_data_loader:
covariates_X, ps_score, y_f, y_cf = batch
covariates_X = covariates_X.to(device)
ps_score = ps_score.squeeze().to(device)
treatment_pred = network(covariates_X, ps_score)
predicted_ITE = treatment_pred[0] - treatment_pred[1]
true_ITE = y_cf - y_f
if torch.cuda.is_available():
diff = true_ITE.float().cuda() - predicted_ITE.float().cuda()
else:
diff = true_ITE.float() - predicted_ITE.float()
err_control_list.append(diff.item())
# print(err_treated_list)
# print(err_control_list)
return {
"treated_err": err_treated_list,
"control_err": err_control_list,
}我们将我们的潜在结果模型称为深度反事实网络(DCN),我们使用首字母缩写DCN- pd来指代具有倾向-退出正则化的DCN。由于我们的模型同时捕捉了倾向得分和结果,因此它是一个双稳健模型(doubly-robust model)。
2.4VCNet
@article{LizhenNie2021VCNetAF, title={VCNet and Functional Targeted Regularization For Learning Causal Effects of Continuous Treatments}, author={Lizhen Nie and Mao Ye and Qiang Liu and Dan L. Nicolae}, journal={arXiv: Learning}, year={2021}}
参考:
- dcn(deep cross network)三部曲 - 知乎
- 因果推理实战(1)——借助因果关系从示教中学习任务规则 - 知乎
- 通俗解释因果推理 causal inference - 知乎
- AB实验的高端玩法系列1 - 走看看
- 收藏|浅谈多任务学习(Multi-task Learning) - 知乎
- 多任务学习在风控场景的应用探索及案例分享 - 知乎
- keras-mmoe/census_income_demo.py at master · drawbridge/keras-mmoe · GitHub
- keras-mmoe/census_income_demo.py at master · drawbridge/keras-mmoe · GitHub
- 多目标建模(一) - 知乎
- 推荐系统(8)—— 多目标优化应用总结_1 - 深度机器学习 - 博客园
- 多任务学习在因果建模上应用 - 知乎
- 深度学习【22】Mxnet多任务(multi-task)训练_DCD_Lin的博客-CSDN博客_多任务训练
- 因果推断在多任务优化场景有什么好的实践? - 知乎
- https://huaweicloud.csdn.net/63802f23dacf622b8df8639e.html
- 神经网络训练多任务学习(MTL)时,多个loss怎么分配权重(附代码)_神经网络多任务训练_Ciao112的博客-CSDN博客
问题:
1、多目标训练,X_T_Y(唯一的),特效x [y1,y2],行形式是x [y1,null]?
答:采用参数不更新的方式训练。
3思考
1、使用因果推断给相关性模型纠偏,因果推断和机器学习是什么关系呢?

2、因果推断和机器学习都是解决什么问题?
答:机器学习解决预测问题,不需要知道原因;因果推断知道原因下,预测结果。
3、机器学习解决不了什么问题?
答:不去干预,不去探索原因。
答:回答不了因果问题。
4、因果推断解决不了什么问题?
5、没干预的问题还是因果问题吧?
答:理解不是了。
6、偏差解决方式?