灵感论文精读《End-to-End Multi-Person Pose Estimation with Transformers》
整理论文《End-to-End Multi-Person Pose Estimation with Transformers》
- 论文结构
-
- 框架结构
- 论文观点
- 实现方法
-
- 模型结构
-
- 模型分析
- 视觉特征编码器(Visual Feature Encoder)
- 姿态解码器(Pose Decoder)
- 关节解码器(Joint Decoder)
- 损失函数(Loss Functions)
-
- 对象关键点相似度损失(OKS loss)
- 热图损失(Heatmap loss)
- 总体损失(Overall loss)
- 实验结果
- 论文结论
论文结构
框架结构
Abstract --> Introduction -->Related Work -->Methodology -->Experiments --> Conclusion --> Acknowledgments --> References
论文观点
本文章提出了一个基于Transformers的完全端到端多人姿态估计框架,称为PETR。该方法通过将姿态估计定义为一个分层集预测问题,将人实例和细粒度身体关节定位相结合。给定多个随机初始化的姿态查询,姿态解码器学习推理对象的关系,并在全局图像上下文基础上估计一组实例感知的姿态。然后,设计一个关节解码器来探索不同关节之间的结构关系,并进一步在更精细的水平上优化全身姿态。
- 与现有的单阶段方法相比,PETR设计了分层解码器,可以分层地处理与目标关键点最相关的特征,很大程度上克服了特征错位问题,通过注意机制捕获人实例和运动关节之间的关系。
- PETR基于端到端查询的框架是通过二分图匹配策略学习的,避免了启发式标签分配,消除了NMS后处理的需要。
实现方法
模型结构
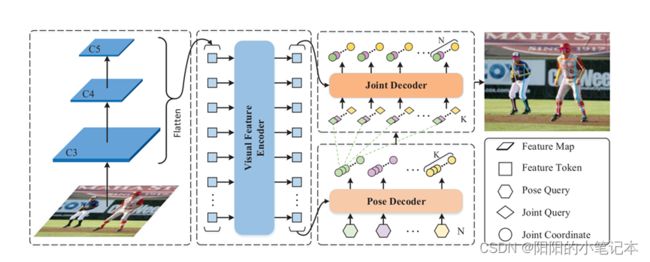
如图1所示,所提出的框架由三个关键模块组成:视觉特征编码器(Visual Feature Encoder)、姿态解码器(Pose Decoder)和关节解码器(Joint Decoder),其中
- 视觉特征编码器(Visual Feature Encoder)用于细化从骨干网络中提取的多尺度特征图
- 姿态解码器(Pose Decoder)用于预测多个全身姿态,
- 关节解码器(Joint Decoder)用于进一步细化关节级别的全身姿态。
模型分析
上图模型中,C3到C5是从骨干网中提取的多尺度特征图(如ResNet50)。视觉特征编码器(Visual Feature Encoder)以平面化的图像特征为输入,对其进行细化。给定N个姿态查询和改进的多尺度特征标记(multi-scale feature tokens),姿态解码器(Pose Decoder)并行预测N个全身姿态。在此之后,附加的关节解码器(Joint Decoder)将每个分散的姿态(即每个姿态的运动关节)作为参考点,并将细化后的姿态作为最终结果输出。K是每个实例的关键点数量(例如,在COCO数据集中K = 17)。
例如:
给定一个图像 I ∈ R H × W × 3 I∈\mathbb{R}^{H×W×3} I∈RH×W×3,我们从主干的后三个阶段(例如ResNet)中提取多尺度特征图 C 3 C_3 C3、 C 4 C_4 C4和 C 5 C_5 C5,其步幅分别为8、16和32。通过空间全连接(FC)层将多尺度特征图投影到256通道的特征图上,然后将其平展为特征标记(feature tokens) C 3 ′ C'_3 C3′, C 4 ′ C'_4 C4′和 C 5 ′ C'_5 C5′。 C i ′ C'_i Ci′ 是 L i × 256 L_i × 256 Li×256,式中 L i = h / 2 i × w / 2 i L_i = h/2^i× w/2^i Li=h/2i×w/2i。
接下来,使用连接的特征标记(feature tokens) [ C 3 ′ C'_3 C3′, C 4 ′ C'_4 C4′, C 5 ′ C'_5 C5′ ] 作为输入,视觉特征编码器(Visual Feature Encoder)输出经过细化的多尺度特征令牌 F ∈ R L × 256 F∈\mathbb{R} ^{L×256} F∈RL×256,其中 L = L 3 + L 4 + L 5 L = L_3 + L_4 + L_5 L=L3+L4+L5 为特征标记(feature tokens)总数。然后,利用N个随机初始化的姿态查询,在全局图像上下文下直接推理N个全身姿态(及其相应的置信度分数)。最后,我们将每个全身姿态分散到一系列身体关节中,并采用关节解码器(Joint Decoder)进一步细化它们。
视觉特征编码器(Visual Feature Encoder)
相对于多头自注意编码器来说,由于可变形注意层的计算复杂度较低,因此采用可变注意模块来实现特征编码器可以合并和细化多尺度特征图。每个编码器层包括一个多尺度可变形注意模块(multi-scale deformable attention module)和一个前馈网络(FFN)。为了识别每个特征标记所处的特征级别,除了位置嵌入之外,我们还添加了等级嵌入(scale-level embedding)。在我们的视觉特征编码器中,有6个可变形编码器层按顺序堆叠。在此之后,我们可以得到细化的多尺度视觉特征记忆F。
姿态解码器(Pose Decoder)
在姿态解码器中,目标是在全局图像上下文(即特征记忆F)下推理一组全身姿态。类似于视觉特征编码器,由于其效率,我们使用可变形注意力模块来构建我们的姿态解码器。具体来说,给定N个随机初始化的姿态查询 Q p o s e ∈ R N × D Q_{pose}∈\mathbb{R}^{N×D} Qpose∈RN×D,姿态解码器输出N个全身姿态 [ P i ] i = 1 N ∈ R N × 2 K {[P_i]}^N_{i=1}∈\mathbb{R}^{N×2K} [Pi]i=1N∈RN×2K,其中 P i = [ ( x i j , y i j ) ] j = 1 K P_i = {[(x^j _i, y^j_i)]}^K_{j=1} Pi=[(xij,yij)]j=1K表示第i个人的K个关节坐标,D表示查询嵌入的维数。

姿态解码器的详细结构如图2所示。首先,查询嵌入(query embeddings)被输入到自注意模块(pose-to-pose attention)中,用于相互交互。然后每个查询通过可变形的交叉注意模块(feature-to-pose attention)从多尺度特征存储器(the multi-scale feature memory)F中提取特征。有K个参考点,作为我们可变形交叉注意模块中全身姿势的初始位置,随后,实例感知的查询特征(the instance-aware query features)被输入到多任务预测头(the multi-task prediction heads)中。分类头(the classification head)通过线性投影层(FC)预测每个对象的置信度分数。姿态回归头(The pose regression head)使用隐藏大小为256的多层感知器(MLP)预测K个参考点的相对偏移量。在我们的姿态解码器中依次应用了三个解码器层。
我们不再只使用最终的解码器层来预测姿态坐标,而是利用所有的解码器层来逐步估计姿态坐标。具体来说,每一层都是根据前一层的预测来改进姿势。形式上,给定由 ( d − 1 ) (d−1) (d−1)个解码器层预测的规范化位姿 P d − 1 P_{d−1} Pd−1,第d个解码器层将该位姿细化为
P d = σ ( σ − 1 ( P d − 1 + Δ P d ) P_d=σ(σ^{-1}(P_{d-1}+ΔP_d) Pd=σ(σ−1(Pd−1+ΔPd)
其中 Δ P d ΔP_d ΔPd是第d层的预测偏移量, σ σ σ和 σ − 1 σ^{−1} σ−1分别表示sigmoid函数和逆sigmoid函数。这样, P d − 1 P_{d−1} Pd−1作为第d阶解码器层交叉注意模块的新参考点。初始参考点 P 0 P_0 P0是一个随机初始化的矩阵,在训练过程中与模型参数共同更新。因此,渐进变形交叉注意模块可以处理与目标关键点最相关的视觉特征,自然地克服了特征错位的问题。
关节解码器(Joint Decoder)

如图3所示,我们提出了关节解码器来探索关节之间的结构关系,并进一步细化关节层面的全身姿态。我们使用可变形的注意力模块来构建我们的关节解码器,就像在姿态解码器中一样。具体来说,给定K个随机初始化的关节查询 Q j o i n t ∈ R K × D Q_{joint}∈\mathbb{R}^{K×D} Qjoint∈RK×D,关节解码器将前一个姿态解码器预测的每个全身姿态的关节位置作为初始参考点,然后进一步细化关节位置。注意,所有的姿态都可以并行处理,因为它们在关节解码器中是相互独立的。
关节查询( joint queries)首先通过一个自注意模块(joint-to-joint attention)相互交互,然后在一个可变形的交叉注意模块(feature-to-joint attention)中提取视觉特征。随后,关节回归头(joint regression head)通过应用多层感知器(MLP)预测2-D关节位移 Δ J = ( Δ x , Δ y ) ΔJ = (Δx, Δy) ΔJ=(Δx,Δy)。与姿态解码器类似,关节坐标是逐步细化的。形式上,设 J d − 1 J_{d−1} Jd−1为第 ( d − 1 ) (d−1) (d−1)个解码器层预测的归一化关节坐标,第d个解码器层预测的关节坐标为 J d = σ ( σ − 1 ( J d − 1 ) + Δ J d ) J_d = σ(σ^{−1}(J_{d−1})+ ΔJ_d) Jd=σ(σ−1(Jd−1)+ΔJd),其中 J 0 J_0 J0为前一个姿态解码器预测的姿态关节位置。
损失函数(Loss Functions)
使用基于集的匈牙利损失,对每个真实姿态强制进行唯一的预测。我们的姿态解码器的分类头使用了相同的分类损失函数(记为 L c l s L_{cls} Lcls)。此外,我们在姿态解码器和关节解码器中分别采用L1损失(记为Lreg)和OKS损失(记为Loks)作为姿态回归头和关节回归头。
对象关键点相似度损失(OKS loss)
最常用的L1损失对于小姿态和大姿态具有不同的尺度,即使它们的相对误差相似。为了缓解这个问题,我们建议额外使用对象关键点相似度(OKS)损失,它可以表述为:
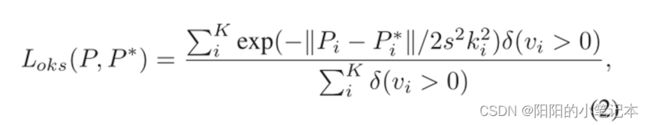
∥ P i − P i ∗ ∥ \Vert P_i-P_i^* \Vert ∥Pi−Pi∗∥是第i个预测关键点与ground-truth 1之间的欧氏距离, v i v_i vi是ground-truth的可见性标志, s s s是对象尺度, k i k_i ki是控制下降的perkeypoint常数。如上所示,OKS损失由人实例的规模标准化与关键点的重要性相等。
热图损失(Heatmap loss)
我们使用辅助热图回归训练实现快速收敛。我们从视觉特征编码器的 C 3 C_3 C3输出中收集特征标记,并将标记重塑为原始的空间形状。其结果用 F C 3 ∈ R ( H / 8 ) × ( W / 8 ) × D FC_3∈\mathbb{R}^{(H/8)×(W/8)×D} FC3∈R(H/8)×(W/8)×D表示。我们使用可变变压器编码器来生成热图预测。然后,我们计算了预测热图和真实热图之间焦点损失的变体(记为Lhm)。注意,热图分支只用于辅助训练,在推理中被丢弃。
总体损失(Overall loss)
形式上,我们模型的总体损失函数可以表述为:
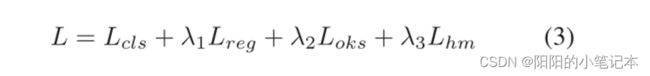
其中, λ 1 、 λ 2 、 λ 3 λ_1、λ_2、λ_3 λ1、λ2、λ3分别为损失权值。