【持续更新】【机器学习】线性回归算法(句句注释,超级详细,机器学习经典算法)
```python
#线性回归算法:
#加载数据文件
#数据预处理
#建立模型f(x)=wx+b
#定义损失函数
#判断数据量和特征值大小
#如果大,损失函数用梯度下降法
#如果小,用最小二乘法
#进行参数求解
#模型检测
#经济预测
#结束
import numpy as np
from scipy import stats
import matplotlib.pyplot as plt
#加载数据
x = np.arange(0.,10.,0.2) #x=[0. 0.2 0.4 0.6 0.8 1. 1.2 1.4 1.6 1.8 2. 2.2 2.4 2.6 2.8 3. 3.2 3.4
# 3.6 3.8 4. 4.2 4.4 4.6 4.8 5. 5.2 5.4 5.6 5.8 6. 6.2 6.4 6.6 6.8 7.
# 7.2 7.4 7.6 7.8 8. 8.2 8.4 8.6 8.8 9. 9.2 9.4 9.6 9.8]
m = len(x) #m为x中向量的个数
print(m) #打印出来
x0 = np.full(m,1.0) #x0创建了一个与xshape相同的矩阵,并全部用0填充
input_data = np.vstack((x0,x)).T #将x0与x垂直方向堆叠,然后取转置,得到b在第一列的增广矩阵
target_data = 2 * x + 5 + np.random.randn(m) #目标标签为2X+5+随机数的函数,这个随机数服从高斯分布
#迭代停止条件
loop_max=1000 #最大迭代次数
epsilon=0.001 #预测值与实际值之间的差距为0.001
#初始化权值 (超参数)
np.random.seed(0) #定义随机数种子
w=np.random.randn(2) #初始化w为1行2列的服从高斯分布的向量
alpha=0.001 #学习率
#diff=0.
error = np.zeros(2) #初始化误差为1行2列的
count=0 #循环次数
finish = 0 #终止标志
while count<loop_max: #相当于死循环,因为永远达不到这个不成立
count+=1 #计数器加一
sum_m=np.zeros(2) #初始化sum_m为1行2列的全为零的矩阵
for i in range(m): #循环m次
diff=(np.dot(w,input_data[i])-target_data[i])*input_data[i] #求偏导根据(h(x)-y)*x
sum_m=sum_m+diff #根据多特征迭代式,上面计算的m组的梯度做一个累加
w=w-alpha*sum_m #更新参数的值
#判断是否收敛
if np.linalg.norm(w-error)<epsilon: #norm函数默认求矩阵整体平方根再求根号,即w与error差值的绝对值再与阈值相比
finish=1 #这个为终止判断条件,我觉得有和没有差别不大
break #跳出while循环
else:
error=w #每次更新error让其如下一次的w作差,随着梯度下降越来越缓慢,两者的差值是在不断减小的,
# 如果w与error的差值小于我们能接受的数值,则可以停止循环。
print('loop count = %d'%count,'\tw:',w) #每一次循环都输出循环步数
print('loop count = %d'%count,'\tw:',w) #循环结束后也要输出循环步数,即最后一步。
#用Scipy线性回归检查
slope,intercept,r_value,p_value,std_error = stats.linregress(x,target_data) #这五个参数分别是斜率,截距,相关系数,p值,估计梯度的标准差,
#其中p值为利用检验统计量的t分布的Wald检验,对原假设为斜率为零的假设检验的双侧p值进行检验。
print('intercept = %s slope = %s'% (intercept,slope)) #输出截距和斜率
#用matplotlib画图
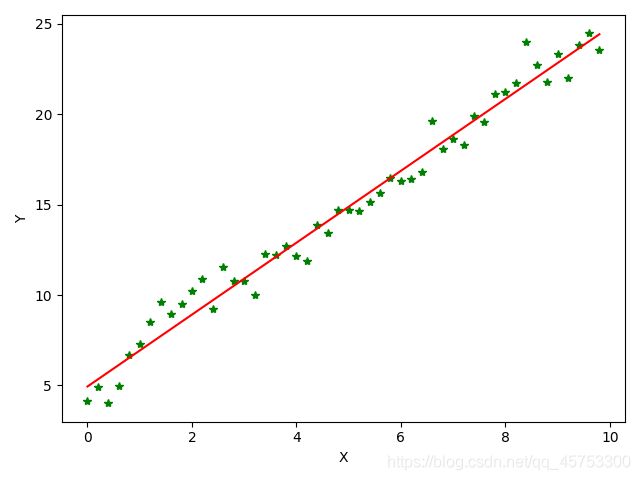
plt.plot(x,target_data,'g*') #横轴为x,纵轴为target_data,离散点为绿色星点
plt.plot(x,w[1]*x+w[0],'r') #横轴为x,纵轴为预测的值,用红线
plt.xlabel("X") #横轴做X标记
plt.ylabel("Y") #横轴做Y标记
plt.show() #展示图片
运行结果图: