【自用】学习代码中不懂东西...
一、OS模块和sys模块
1、import os 和 import sys
- os模块提供了一种方便的使用操作系统函数的方法。
- sys模块可供访问由解释器使用或维护的变量和与解释器进行交互的函数。
总结:os模块负责程序与操作系统的交互,提供了访问操作系统底层的接口;sys模块负责程序与Python解释器的交互,提供了一系列的函数和变量,用于操控Python的运行时环境。
os常用方法
os.remove(‘path/filename’) 删除文件
os.rename(oldname, newname) 重命名文件
os.walk() 生成目录树下的所有文件名
os.chdir('dirname') 改变目录
os.mkdir/makedirs('dirname')创建目录/多层目录
os.rmdir/removedirs('dirname') 删除目录/多层目录
os.listdir('dirname') 列出指定目录的文件
os.getcwd() 取得当前工作目录
os.chmod() 改变目录权限
os.path.basename(‘path/filename’) 去掉目录路径,返回文件名
os.path.dirname(‘path/filename’) 去掉文件名,返回目录路径
os.path.join(path1[,path2[,...]]) 将分离的各部分组合成一个路径名
os.path.split('path') 返回( dirname(), basename())元组
os.path.splitext() 返回 (filename, extension) 元组
os.path.getatime\ctime\mtime 分别返回最近访问、创建、修改时间
os.path.getsize() 返回文件大小
os.path.exists() 是否存在
os.path.isabs() 是否为绝对路径
os.path.isdir() 是否为目录
os.path.isfile() 是否为文件
sys 常用方法
sys.argv 命令行参数List,第一个元素是程序本身路径
sys.modules.keys() 返回所有已经导入的模块列表
sys.exc_info() 获取当前正在处理的异常类,exc_type、exc_value、exc_traceback当前处理的异常详细信息
sys.exit(n) 退出程序,正常退出时exit(0)
sys.hexversion 获取Python解释程序的版本值,16进制格式如:0x020403F0
sys.version 获取Python解释程序的版本信息
sys.maxint 最大的Int值
sys.maxunicode 最大的Unicode值
sys.modules 返回系统导入的模块字段,key是模块名,value是模块
sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
sys.platform 返回操作系统平台名称
sys.stdout 标准输出
sys.stdin 标准输入
sys.stderr 错误输出
sys.exc_clear() 用来清除当前线程所出现的当前的或最近的错误信息
sys.exec_prefix 返回平台独立的python文件安装的位置
sys.byteorder 本地字节规则的指示器,big-endian平台的值是'big',little-endian平台的值是'little'
sys.copyright 记录python版权相关的东西
sys.api_version 解释器的C的API版本
2、用到的os函数
1. os.makedirs(name, mode=0o777, exist_ok=False)
作用:用来创建多层目录(单层使用os.mkdir)
参数说明:
name:想创建的目录名
mode:为目录设置的权限数字模式,默认的模式为 0o777 (八进制)。
exist_ok:是否在目录存在时触发异常。
if(exist_ok == False(默认值))
FileExistsError #在目标目录已存在的情况下触发异常
if(exist_ok == True)
在目标目录已存在的情况下不会触发ileExistsError异常。
2、getattr() 函数
getattr() 函数用于返回一个对象属性值。
语法:
getattr(object, name[, default])
参数:
object:对象。
name:字符串,对象属性。
default: 默认返回值,如果不提供该参数,在没有对应属性时,将触发 AttributeError。
返回值:返回对象属性值。
例子:
>>>class A(object):
... bar = 1
...
>>> a = A()
>>> getattr(a, 'bar') # 获取属性 bar 值
1
二、Tqdm
Tqdm 是一个快速,可扩展的Python进度条,可以在 Python 长循环中添加一个进度提示信息,用户只需要封装任意的迭代器。
效果:
100%|███████████████████████████████████| 857K/857K [00:04<00:00, 246Kloc/s]
三、GPU、NVIDIA、CUDA和cuDNN
在深度学习中,常常要对图像数据进行处理和计算,而CPU因为需要处理的事情多,并不能满足我们对图像处理和计算速度的要求,显卡GPU就是来帮助CPU来解决这个问题的。
GPU特别擅长处理图像数据,而CUDA(Compute Unified Device Architecture),是显卡厂商NVIDIA推出的运算平台。CUDA™是一种由NVIDIA推出的通用并行计算架构,该架构使GPU能够解决复杂的计算问题。它包含了CUDA指令集架构(ISA)以及GPU内部的并行计算引擎,安装CUDA之后,可以加快GPU的运算和处理速度。
1、显卡、显卡驱动、CUDA之间的关系
显卡:(GPU),主流是NVIDIA的GPU,因为深度学习本身需要大量计算。GPU的并行计算能力,在过去几年里恰当地满足了深度学习的需求。AMD的GPU基本没有什么支持,可以不用考虑。
驱动:没有显卡驱动,就不能识别GPU硬件,不能调用其计算资源。但是呢,NVIDIA在Linux上的驱动安装特别麻烦,屏蔽第三方显卡驱动。
CUDA:是显卡厂商NVIDIA推出的只能用于自家GPU的并行计算框架。只有安装这个框架才能够进行复杂的并行计算。主流的深度学习框架也都是基于CUDA进行GPU并行加速的,几乎无一例外。
cuDNN:针对深度卷积神经网络的加速库。
2、为什么GPU特别擅长处理图像数据呢?
因为图像上的每一个像素点都有被处理的需要,而且每个像素点处理的过程和方式都十分相似,GPU就是用很多简单的计算单元去完成大量的计算任务,类似于纯粹的人海战术。GPU不仅可以在图像处理领域大显身手,它还被用来科学计算、密码破解、数值分析,海量数据处理(排序,Map-Reduce等),金融分析等需要大规模并行计算的领域。
3、用到的函数
1、torch.backends.cudnn.benchmark
一般加在开头,比如在设置使用 GPU 的同时,后边补一句:
if args.use_gpu and torch.cuda.is_available():
device = torch.device('cuda')
torch.backends.cudnn.benchmark = True
else:
device = torch.device('cpu')
'''师兄代码'''
torch.backends.cudnn.benchmark = True
torch.backends.cudnn.deterministic = True
四、argparse模块
parse_args(argsparse):python和命令行之间的交互
1.引入模块
import argparse
2.建立解析对象
parser = argparse.ArgumentParser()
3.增加属性:给xx实例增加一个aa属性 # xx.add_argument("aa")
parser.add_argument("echo")
4.属性给与args实例:把parser中设置的所有"add_argument"给返回到args子类实例当中, 那么parser中增加的属性内容都会在args实例中,使用即可。
args = parser.parse_args()
parser.parse_args()
5.打印定位参数/属性echo
print(args.echo)
1、用到的函数
1、函数add_argumen()
第一个是选项,第二个是数据类型,第三个默认值,第四个是help命令时的说明。
调用:args.属性名
- 在 add_argument 前,给属性名之前加上"- -",就能将之变为可选参数。
-# 3增加属性:这里的bool是一个可选参数,返回给args的是 args.bool
parser.add_argument("--bool",help = "Whether to pirnt sth.")
#属性给与args实例: parser中增加的属性内容都在args实例中
args = parser.parse_args()
#如果有输入内容,则打印1
if args.bool:
print('bool = 1')
---输入:
python argp.py --bool 1
---得到:
bool = 1
可选参数"--bool":
既然是可选的,如果不指定(就是不使用它)的话,对应的变量会被设置为None。
- type: parse.add_argument() 对于接受的值默认其为str,如果要将之视为int类型,额外加一句 “type=int”。
#增加属性:在命令行中,该py文件希望用户能给他一个参数,最终将之转化为:args.square
parser.add_argument("square", type = int, help = "To sqaure the number given", )
#属性给与args实例:add_argument 返回到 args 子类实例
args = parser.parse_arg()
print(args.square**2)
具体可参考博主,写的很详细!:https://blog.csdn.net/zjc910997316/article/details/85319894
五、Util
Util是utiliy的缩写,是一个多功能、基于工具的开源软件包。
- 定以CodeSearchDataset类
CodeSearchDataset类继承Datasets必须继承__init_()和__getitim__()。
首先继承data.Dataset,然后在__init__()方法中得到图像的路径,然后将图像路径组成一个数组,这样在__getitim__()中就可以直接读取。
- 定义CodeSearchDataset类还会遇到DataLoader类,它可以
调utils.data.DataLoader,可以使用torch.multiprocessing worker并行加载多个样本。
CodeSearchDataset类:读入数据并且对该数据进行了索引。
但是光有这个功能是不够用的,在实际的加载数据集的过程中,我们的数据量往往都很大,对此我们还需要一下几个功能:
- batch_size:可以分批次读取
- shuffle = True/False:可以对数据进行随机读取,可以对数据进行洗牌操作(shuffling),打乱数据集内数据分布的顺序
- num_workers = ?:可以并行加载数据(利用多核处理器加快载入数据的效率
- batch :可以分批次读取batch-size
这时候就需要Dataloader类了,Dataloader这个类并不需要我们自己设计代码,我们只需要利用DataLoader类读取我们设计好的ShipDataset即可:
train_loader = DataLoader(dataset=train_data, batch_size=6, shuffle=True ,num_workers=4)
test_loader = DataLoader(dataset=test_data, batch_size=6, shuffle=False,num_workers=4)
- 除了读取数据集的代码,我们实际的图像数据应该怎么去放置呢?这就要用到txt文件了。——但我做的不是分类算法,应该不需要标签
一般来说,自己制作的数据集一般包含三个部分:训练集、验证集和测试集。
因为数据集较大,所以一般我们将这三个模块分别放到三个文件夹下面,利用代码直接调用吗,简单又方便而且不容易出错。
调用的时候,我们不仅要调用图片还有图片的路径和标签信息等,所以我们使用txt文件,在txt文件中加入两种信息,一种是图片的路径,我们可以通过图片的路径来找到图,从而读取图片;另一种是图片的标签,将每张图片的信息和标签一 一对应。
参考文章,写的很棒!https://blog.csdn.net/sinat_42239797/article/details/90641659
六、Dataload
torch.utils.data.DataLoader是PyTorch中数据读取的一个重要接口,该接口定义在 dataloader.py 脚本中。
只要是用PyTorch来训练模型基本都会用到该接口,该接口主要用来将自定义的数据读取接口的输出或者PyTorch已有的数据读取接口的输入按照batch size封装成Tensor,后续只需要再包装成Variable即可作为模型的输入,因此该接口有点承上启下的作用,比较重要。
七、常用缩写
dir:directory,一般指路径、目录。
desc:description,指自然语言描述。
attr:,attributes,属性。
src:source,源文件目录。
末:我知道的步骤
1、关于数据集
IR:数据集需要 ir 和 desc 。
数据集处理:转成IR需要格式的输入数据
-
ir.txt 和 desc.txt 文件【或许是all_ir.txt和all_desc.txt】
ir.txt文件是由(点,点,边类型)存储方便;dexc.txt直接通过token存储。 -
得到原始文件 origin.ir_all.txt 和 origin.desc_all.txtx 文件:指从llvm中得到的原始 ir 数据。
-
得到 origin.ir.txt 和 origin.desc.txt 文件
对origin.ir_all.txt和origin.desc_all.txt文件进行处理,运行data_consist.py设定需要的数据集大小以及对齐两种形式数据得到origin.ir.txt和origin.desc.txt。
查看后与all_ir.txt内容一致,只是开头大小写字母不同。 -
得到 train 和 test 数据文件
为了得到模型需要的输入格式,运行 util_desc.py 和 util_ir.py 进行处理。该程序需要设定词典大小等,与config文件一致(如下图),先运行 util_desc.py 再运行util_ir.py,因为 util_desc.py 会生成一个中间文件。
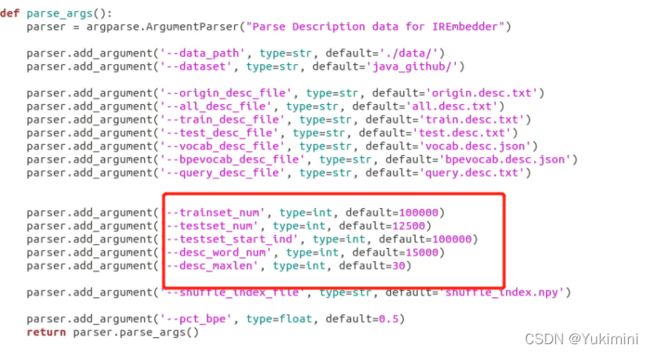
通过上述就可以生成数据,运行train.py和test.py进行训练和测试,通过config.py调参。
ir数据通过.json读入;
desc数据通过.h5读入
2、处理步骤
处理过程大概是:
- 先爬到需要的代码,包含很多很多函数以及每个函数的注释。
- 分别把他们合到一个文件里面,一个是存代码的,一个是存注释的。
- 最后按照源代码->ir文件->ir图->分训练集和测试集->存为字典格式.json。
ir图文件格式:
从origin_ir文件经过某程序处理得到。
BeginFun:0表示在源IR文件中的行数
45表示节点数
66表示边数

3、各函数的作用
1. data_consist.py——跑通
作用:检查 ir_all.txt 和 desc_all.txt 是否对齐。
我的更改:输入路径、数据集的名称。读写数据按 utf-8 编码。
生成的文件:origin_ir.txt 和 origin_desc.txt。

2. util_desc.py——跑通
作用:生成 desc 的词典;划分 desc 的训练集和测试集;去掉了BeginFunc:IndexedElementsBinder.bindIndexed#1。
我的更改: 输入路径、数据集的名称。
步骤:
#生成shuffle_index.npy文件,就是一个index数组,最大值为函数个数
shuffle()
#划分数据集:train test
split_data(args)
#build dictionary only for train
create_dict_file(args)
#转成h5
dir_path = args.data_path + args.dataset
# train.desc.txt -> train.desc.h5(and test...)
sents2indexes(dir_path+args.train_desc_file, dir_path+args.vocab_desc_file, args.desc_maxlen)
sents2indexes(dir_path+args.test_desc_file, dir_path+args.vocab_desc_file, args.desc_maxlen)
生成的文件:

用到的函数:
- json.dumps() 和 json.loads() 是json格式处理函数,主要用来读写json文件。
(1) json.dumps() 函数将一个Python数据类型列表进行json格式的编码(可以这么理解,json.dumps()函数是将字典转化为字符串)
(2) json.loads() 函数将json格式数据转换为字典(可以这么理解,json.loads()函数是将字符串转化为字典)
存储为.h5文件:
phrases = [] # 存储处理过UNK_ID的整个数据,根据vocab的key查询每个word的index并存储,不直接存储word
indices = [] # 存储每个句子的长度和起始索引,通过此来区分phrass中怎么区分每个句子
- Counter()类
对字符串\列表\元祖\字典进行计数,返回一个字典类型的数据,键是元素,值是元素出现的次数。
most_common(n) :统计出现最多次数的n个元素。
elements :返回一个Counter计数后的各个元素的迭代器。
update :类似集合的update,进行更新。
3. util_ir.py——跑通
作用:生成 ir 的词典;划分 ir 的训练集和测试集。
我的更改: 输入路径、数据集的名称。
步骤:
preprocess_origin_ir(args)
# 生成shuffle_index.npy文件,就是一个index数组,最大值为函数个数
construct_shuffle_data(args)
# 划分训练集和测试集
split_data(args)
# 创建词典
create_dict_file(args)
# 转成json
dir_path = args.data_path + args.dataset
ir_txt_all_file_path = dir_path + args.all_ir_file
txt2json(args, ir_txt_all_file_path)
dir_path = args.data_path + args.dataset
ir_txt_train_file_path = dir_path + args.train_ir_file
ir_txt_test_file_path = dir_path + args.test_ir_file
txt2json(args, ir_txt_train_file_path)
txt2json(args, ir_txt_test_file_path)
用到的函数:
4. h5py包读取数据
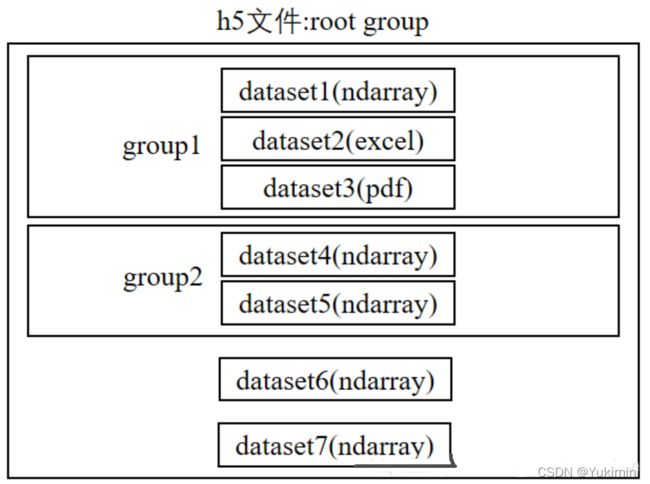
.h5文件的数据组织方式: h5文件中有两个核心的概念:组“group”和数据集“dataset”。 一个h5文件就是 “dataset” 和 “group” 二合一的容器。
- dataset :简单来讲类似数组组织形式的数据集合,像 numpy
数组一样工作,一个dataset即一个numpy.ndarray。具体的dataset可以是图像、表格,甚至是pdf文件和excel. - group:包含了其它dataset(数组)和其它 group ,像字典一样工作。
一个h5文件被像linux文件系统一样被组织起来:dataset是文件,group是文件夹,它下面可以包含多个文件夹(group)和多个文件(dataset)。
FA-AST
基于ast_tree,加入数据流和控制流边。
数据流边:Child,Parent,NextSib,NextToken,NextUse。
- Child:连接非终结节点到子节点。
- Parent:连接非终结节点到父节点。
- NextSib:连接节点和它的相邻节点。将node连接到其下一个兄弟姐妹 (从左到条件右)。因为图神经网络不考虑节点的顺序,所以有必要向我们的神经网络模型提供子的顺序。
- NextToken:将一个终端节点连接到下一个终端节点。在ASTs中,终端节点参考程序源代码中的标识符令牌,因此NextToken边缘将标识符令牌连接到相应源代码中的下一个令牌。
- NextUse:将变量使用的节点连接到其下一次"出现"。NextUse边可以利用来自ASTs的有用数据流信息。
控制流边:顺序执行,If语句,While和For循环。