附代码 DenseASPP for Semantic Segmentation in Street Scenes论文解读
DenseASPP for Semantic Segmentation in Street Scenes论文解读
代码地址:https://github.com/Tramac/awesome-semantic-segmentation-pytorch
目录
-
- 摘要:(对ASPP的进一步改进)
- 主要内容:
- 感受野计算方法:
- 感受野大小对比:
- 代码:
摘要:(对ASPP的进一步改进)
虽然ASPP能够生成多尺度特征,但我们认为在尺度轴上的特征分辨率对于自动驾驶场景还不够密集。为此,我们提出了密集连接的空间金字塔池(DenseASPP),它以密集的方式连接了一组空洞卷积层,从而生成了不仅覆盖更大尺度运行的多尺度特征。
ASPP优点:提出将由空洞卷积生成的具有不同扩张率的特征图连接起来,使输出特征图中的神经元包含多个接受域大小,从而编码多尺度信息,最终提高性能。
缺点:当输入图像是高分辨率时,要求神经元有更大的接受域。为了在ASPP中获得足够大的感受野,必须采用足够大的扩张比。然而,随着膨胀速率的增加(如d>24),膨胀卷积变得越来越无效,并逐渐失去其建模能力。
因此提出DenseASPP。DenseASPP中,每个空洞卷积层只使用具有合理膨胀速率的空洞卷积滤波器(d≤24),DenseASPP由一个基本网络和一个级联的空洞卷积层组成。它使用密集连接将每个卷积层的输出输入到前面所有未访问的卷积层。
DenseASPP优点:
- DenseASPP能够生成覆盖非常大范围(就接受域大小而言)的特性。
- DenseASPP生成的特性能够以非常密集的方式覆盖上述尺度范围。
值得注意的是,上述两个性质不能同时通过简单地级联或并行地叠加空洞卷积层来实现。
主要内容:
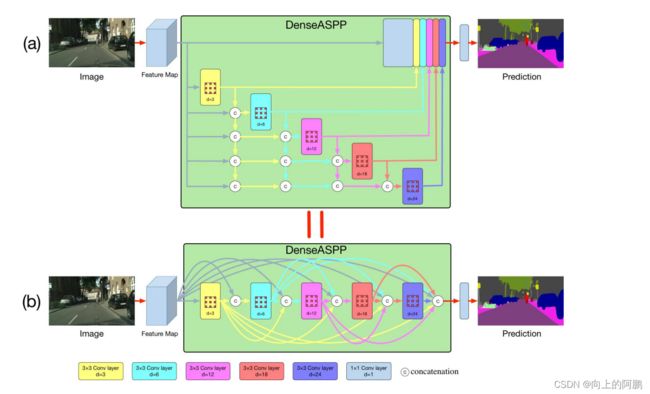
DenseASPP如图:其中每一层的膨胀率一层一层地增加。下部是小膨胀率的层,上面是大膨胀率的层。DenseASPP的最终输出是一个由多膨胀率、多尺度的空洞卷积生成的特征图。
公式:

dl表示第l层的膨胀率,[…]表示concat操作。[yl−1,···,y0]是指通过连接之前所有层的输出而形成的特征图。与最初的ASPP相比,DenseASPP将所有扩展的层堆叠在一起,并通过密集的连接将它们连接起来。这种变化给我们带来了主要的两个好处:更密集的特征金字塔和更大的接受域。
为了控制模型的大小并防止网络变得太宽,在DenseASPP的每一个扩张层之前增加一个1×1的卷积层来减少特征图宽度,以将特征图的深度减少到原始大小的一半。
在我们的设置中,在扩张层之前的每1×1个卷积层将尺寸减小为c0/2通道。我们为DenseASPP中所有卷积层设置n=c0/8。因此,DenseASPP中的参数数量可以计算如下:
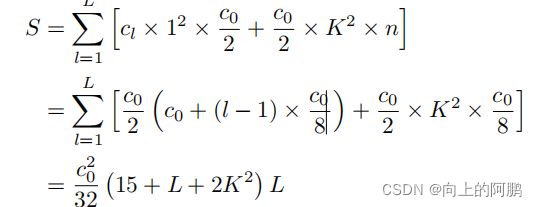
感受野计算方法:
对于膨胀率为d、核大小为K的膨胀卷积层,等效的感受野大小为:
![]()
例如,对于具有d=3的3×3卷积层,相应的感受野大小为7。
将两个卷积层叠加在一起可以给我们提供一个更大的感受野。假设我们有两个卷积层,滤波器大小分别为k1和k2,新的感受野为:

例如,内核大小为3的卷积层与内核大小为3的卷积层堆叠,将产生大小为5的感受野。
因此,感受野计算如下图所示,
感受野大小对比:
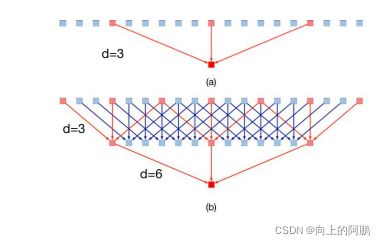
下图(a)为传统的一维空洞卷积层,其膨胀率为6。这种卷积的接受域大小为13。然而,在如此大的核中,只有3个像素被采样进行计算。这种现象在二维情况下会变得更糟。虽然获得了较大的接受域,但在计算过程中却放弃了大量的信息,在DenseASPP中,扩张率一层层地增加,因此,上层的卷积可以利用下层的特征,使像素采样更密集。下图(b)说明了这一过程:在膨胀速率3的层下方放置膨胀速率6的膨胀层。对于膨胀速率为6的原始膨胀层,7像素的信息将有助于最终的计算,比原来的3像素密度更大。在二维图像中,将有49个像素信息被获取。
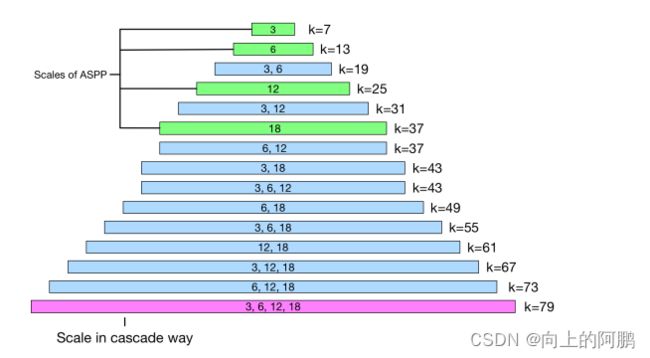
设Rmax表示特征金字塔的最大接受场,函数RK,d表示核大小为K、扩张率为d的卷积层。因此,ASPP(6,12,18,24)最大的接受域是:

而,DenseASPP:

这样大的接受域可以为高分辨率图像中的大物体提供全局信息。
代码:
class _DenseASPPConv(nn.Sequential):
def __init__(self, in_channels, inter_channels, out_channels, atrous_rate,
drop_rate=0.1, norm_layer=nn.BatchNorm2d, norm_kwargs=None):
super(_DenseASPPConv, self).__init__()
self.add_module('conv1', nn.Conv2d(in_channels, inter_channels, 1)),
self.add_module('bn1', norm_layer(inter_channels, **({} if norm_kwargs is None else norm_kwargs))),
self.add_module('relu1', nn.ReLU(True)),
self.add_module('conv2', nn.Conv2d(inter_channels, out_channels, 3, dilation=atrous_rate, padding=atrous_rate)),
self.add_module('bn2', norm_layer(out_channels, **({} if norm_kwargs is None else norm_kwargs))),
self.add_module('relu2', nn.ReLU(True)),
self.drop_rate = drop_rate
def forward(self, x):
features = super(_DenseASPPConv, self).forward(x)
if self.drop_rate > 0:
features = F.dropout(features, p=self.drop_rate, training=self.training)
return features
class _DenseASPPBlock(nn.Module):
def __init__(self, in_channels, inter_channels1, inter_channels2,
norm_layer=nn.BatchNorm2d, norm_kwargs=None):
super(_DenseASPPBlock, self).__init__()
self.aspp_3 = _DenseASPPConv(in_channels, inter_channels1, inter_channels2, 3, 0.1,
norm_layer, norm_kwargs)
self.aspp_6 = _DenseASPPConv(in_channels + inter_channels2 * 1, inter_channels1, inter_channels2, 6, 0.1,
norm_layer, norm_kwargs)
self.aspp_12 = _DenseASPPConv(in_channels + inter_channels2 * 2, inter_channels1, inter_channels2, 12, 0.1,
norm_layer, norm_kwargs)
self.aspp_18 = _DenseASPPConv(in_channels + inter_channels2 * 3, inter_channels1, inter_channels2, 18, 0.1,
norm_layer, norm_kwargs)
self.aspp_24 = _DenseASPPConv(in_channels + inter_channels2 * 4, inter_channels1, inter_channels2, 24, 0.1,
norm_layer, norm_kwargs)
def forward(self, x):
aspp3 = self.aspp_3(x)
x = torch.cat([aspp3, x], dim=1)
aspp6 = self.aspp_6(x)
x = torch.cat([aspp6, x], dim=1)
aspp12 = self.aspp_12(x)
x = torch.cat([aspp12, x], dim=1)
aspp18 = self.aspp_18(x)
x = torch.cat([aspp18, x], dim=1)
aspp24 = self.aspp_24(x)
x = torch.cat([aspp24, x], dim=1)
return x