用于实体和关系抽取的封装式悬空标记
Packed Levitated Marker for Entity and Relation Extraction
用于实体和关系抽取的封装式悬空标记

1. Abstract
最近的实体和关系提取工作主要集中在研究如何从预先训练的编码器中获得更好的跨度表示。然而,现有工作的一个主要局限性是它们忽略了跨度(对)之间的相互关系。本文提出了一种新的跨度表示方法,称为填充悬浮标记(PL-Marker),通过在编码器中策略性地包装token来考虑跨度(对)之间的相互关系。特别是,本文提出了一种面向邻域的布局策略,该策略综合考虑了邻域跨度,以更好地对实体边界信息进行建模。此外,对于较复杂的跨度对分类任务,本文设计了一种面向subject的打包策略,将每个subject及其所有object打包,以建模相同subject跨度对之间的相互关系。实验结果表明,利用增强的标记特征,本文的模型在6个NER基准上提升了基线,在ACE04和ACE05上获得了4.1%-4.3%的严格关系F1改进,并且速度更快。
2. Instruction
三种SPAN表示提取方法被广泛使用:(1)T-Concat将SPAN的边界(开始和结束)标记的表示连接起来,以获得SPAN表示。它在token级收集信息,但在跨度的边界标记通过网络时忽略它们之间的连接;(2)Solid Marker明确地在跨度前后插入两个实心标记,以在输入文本中突出显示该跨度。并插入两对标记来定位跨度对中的subject和object。然而,该方法不能同时处理多个跨距对,因为它在从序列中的多于两对标记中指定跨距对的固体标记方面存在弱点。(3)Levitated Marker悬浮标记首先设置一对悬浮标记与跨度的边界标记处于同一位置,然后通过定向注意将一对标记捆绑在一起。具体地说,一对内的标记被设置为在注意掩码矩阵中彼此可见,但对文本标记和其他标记对不可见。现有的工作简单地将固体标记替换为悬浮标记以实现高效的批处理计算,但牺牲了模型的性能。

在这项工作中,本文引入了包装悬浮标记(PL-Marker),通过在编码阶段策略性地包装悬浮标记来建模跨度(对)之间的相互关系。将悬浮标记打包在一起用于跨度分类任务的一个关键挑战是,插入的悬浮标记的数量增加将平方地加剧PLM的复杂性。因此,为了提高速度和可行性,本文必须将跨度分成几组来控制每个输入序列的长度。在这种情况下,有必要整体考虑相邻跨度,这可以帮助模型比较相邻跨度,例如具有相同开始token的跨度,以获得更精确的实体边界。因此,本文提出了一种面向邻域的打包策略,将具有相同起始token的跨度尽可能地打包到一个训练实例中,以更好地区分实体边界。
对于较复杂的跨度对分类任务,理想的包装方案是将所有跨度对与多对悬浮标记打包在一起,对所有跨度对进行整体建模。然而,由于每一对悬浮标记已经被定向注意捆绑在一起,如果本文继续应用定向注意来绑定两对标记,悬浮标记将无法识别相同跨度的伙伴标记。因此,本文采用了固体标记物和悬浮标记物的融合,并使用面向subject的打包策略对subject及其所有相关object进行整体建模。具体地说,本文用固体标记物强调subject跨度,并用悬浮标记物包装其所有候选object跨度。此外,本文应用了面向subject的包装策略来实现完整的双向建模。
本文考察了PL-Marker在两个典型的跨度(对)分类任务NER和End-to-End RE上的效果。实验结果表明,面向邻域布局的PL-Marker在NER上的性能明显好于随机布局的模型,说明了综合考虑邻域跨度的必要性。并在6个NER基准上提出了TConcat模型,验证了SPAN标记获取特征的有效性。此外,与现有的RE模型相比,本文的模型在ACE04和ACE05上获得了4.1%-4.3%的严格关系F1改进,并且在SciERC上也取得了更好的性能,这表明了考虑面向subject的跨度对之间的相互关系的重要性。
3 Method
3.1 Background: Levitated Marker
悬浮标记被用作固体标记的近似,它允许模型同时对多对实体进行分类,以加快推理过程。与跨度相关联的一对悬浮标记由开始token标记和结束token标记组成。这两个标记与相应跨度的开始和结束标记共享相同的嵌入位置,同时保持原始文本标记的位置ID不变。为了并行地指定多对悬浮标记,应用了定向注意掩码矩阵。具体地说,每个悬浮标记对于注意掩码矩阵中成对的其伙伴标记是可见的,但对于文本标记和其他悬浮标记不可见。同时,悬浮标记器能够关注文本标记以聚集其关联跨度的信息。
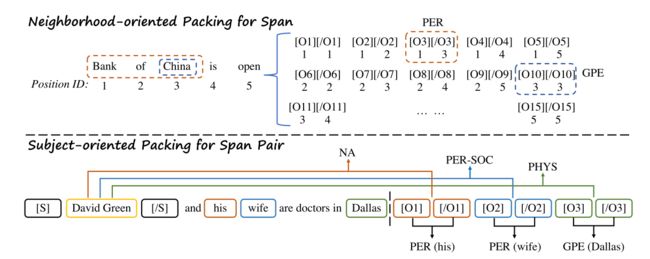
3.2 Neighborhood-oriented Packing for Span
得益于悬浮标记器的并行性,本文可以灵活地将一系列相关跨度打包成一个训练实例。在实践中,本文将多个关联的悬浮标记附加到输入序列中,以对每个跨度进行全面的建模。
然而,即使实体长度受到限制,一些跨度分类任务仍然包含大量的候选跨度。因此,本文必须将标记分成几个批次,以使模型在实践中具有更高的速度和可行性。为了更好地模拟具有相同起始token的跨度之间的连接,本文采用了面向邻域的打包方案。如图2所示,本文首先对悬浮标记对进行排序,将开始标记的位置作为第一个关键字,结束标记的位置作为第二个关键字。之后,本文将它们分成大小最大为K的组,从而将相邻的跨度聚集到同一组中。本文将每组标记打包,并在多次运行中分散处理它们。
形式上,给定N个文本标记的序列, X = { x 1 , . . . , x N } X=\{x_1,...,x_N\} X={x1,...,xN}和最大跨度长度L,本文将候选跨度集定义为 S ( X ) = { ( 1 , 1 ) , . . . , ( 1 , L ) , . . . , ( N , N − L ) , . . . , ( N , N ) } S(X)=\{(1,1),...,(1,L),...,(N,N-L),...,(N,N)\} S(X)={(1,1),...,(1,L),...,(N,N−L),...,(N,N)}。本文首先按顺序将S(X)分成直到K大小的多个组。例如,本文将K个跨度 { ( 1 , 1 ) , ( 1 , 2 ) , . . . , ( K L , K − K − 1 L ∗ L ) } \{(1,1),(1,2),...,(\frac{K}{L},K-\frac{K-1}{L}*L)\} {(1,1),(1,2),...,(LK,K−LK−1∗L)}聚集到组 S 1 S_1 S1中。
![]()
本文将一对悬浮标记与 S 1 S_1 S1中的每个跨度相关联。然后,本文将文本token和插入的悬浮标记的组合序列提供给PLM(例如BERT)以获得开始token标记 H ( s ) = { h i ( s ) } H^{(s)}=\{h_i^{(s)}\} H(s)={hi(s)}和结束token标记 H ( e ) = { h i ( e ) } H^{(e)}=\{h_i^{(e)}\} H(e)={hi(e)}的上下文表示。这里,$H{(s)}与跨度H{(e)}相关联,本文得到其跨度表示:
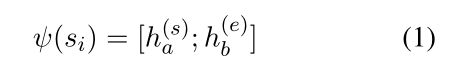
其中[A;B]表示向量A和B上的串联运算。
例如,本文将悬浮标记应用于一个典型的重叠跨度分类任务NER,该任务旨在为句子中的每个可能的跨度分配一个实体类型或一个非实体类型。本文通过填充的悬浮标记从PLM中获得跨度表示,然后结合PL-Marker和T-Concat的特征来更好地预测候选跨度的实体类型。
3.3 Subject-oriented Packing for Span Pair
为了获得跨度对表征,一种可行的方法是采用悬浮标记来同时强调一系列主object跨度。通常,每一对悬浮标记都被定向注意捆绑在一起。但如果本文继续应用定向注意来绑定两对标记,悬浮的标记将无法识别相同跨度的伙伴标记。因此,如图2所示,本文的跨度对模型采用了面向融合subject的打包方案,为相同的subject跨度提供了一个完整的建模。
形式上,给定输入序列X,主语跨度 s i = ( a , b ) s_i=(a,b) si=(a,b)及其候选宾语跨度 ( c 1 , d 1 ) , ( c 2 , d 2 ) , . . , ( c m , d m ) (c_1,d_1),(c_2,d_2),..,(c_m,d_m) (c1,d1),(c2,d2),..,(cm,dm),本文在主语跨度前后插入一对实心标记[S]和[/S]。
然后,本文将悬浮标记[O]和[/O]应用到所有候选object跨度,并将它们打包成一个实例。让 X ∧ \overset{\wedge}{X} X∧表示此修改
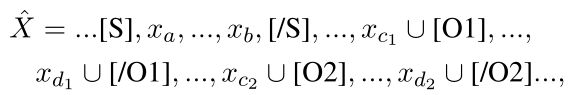
其中由符号∪连接的token共享相同的位置嵌入。本文在 X ∧ \overset{\wedge}{X} X∧上应用预先训练的编码器,最终得到 s i = ( a , b ) a n d s j = ( c , d ) s_i=(a,b) and s_j=(c,d) si=(a,b)andsj=(c,d)的跨度对表示:
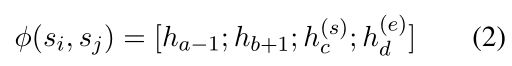
其中[;]表示串联操作。 h a − 1 a n d h b + 1 h_{a-1} and h_{b+1} ha−1andhb+1表示用于 s i s_i si的插入的实心标记的上下文表示; h c ( s ) a n d h d ( e ) h_c^{(s)} and h_d^{(e)} hc(s)andhd(e)是用于 s j s_j sj的插入的悬浮标记的上下文表示。
与分别在subject和object上使用两对固体标记物的方法相比,本文的融合标记物方案用悬浮标记物代替了固体标记物,这在一定程度上会影响对object跨度的强调。为了提供补充信息,本文引入了从object到主语的反向关系来进行双向预测。例如,本文在一个典型的SPAN对分类任务-端到端RE上对本文的模型进行了评估,该任务集中于识别所有SPAN对是否相关以及它们的关系类型。本文首先使用NER模型对候选实体跨度进行过滤,然后得到过滤后实体跨度对的跨度对表示,以预测它们之间的关系。此外,为了建立实体类型和关系类型之间的联系,本文增加了一个辅助损失来预测object实体的类型。
3.4 Complexity Analysis
在大型前馈网络的主导下,PLM的计算量几乎随着小序列长度的增加而线性上升。逐渐地,随着序列长度的继续增长,由于自我注意模块,计算呈二次曲线扩大。显然,悬浮标记的插入延长了输入序列的长度。对于跨度对分类任务,候选跨度数相对较少,因此增加的计算量有限。对于跨度分类任务,本文将tokens分成几个批次,这样可以将序列长度控制在复杂度近似线性增加的区间内。对于NER,本文列举了一个小句子中的候选跨度,然后利用它的上下文词将句子扩展到512个标记词,在实践中,一个句子中候选跨度的数量通常少于上下文长度。因此,在包装群数目较少的情况下,PL-Marker的复杂性仍然与以前的模型的复杂性接近线性。
此外,为了进一步降低推理成本,本文采用了PL-Marker作为两阶段模型的后处理模块,用于从一个更简单、更快的模型提出的少量候选实体中识别实体。
4 Experiment
4.2 Named Entity Recognition
4.2.1 Results
本文在表2中显示了平面NER结果,在表3的Ent列中显示了嵌套的NER结果。
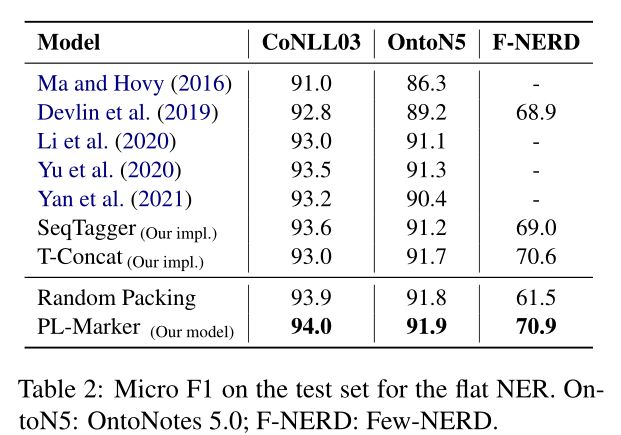

实验结果表明:
- 在三个平坦的NER数据集上,基于邻域布局策略的模型性能均优于采用随机布局策略的模型,尤其是对Few-NERD的性能提高了9.4%。Few-NERD包含更长的句子,因此平均包含325个候选跨度,而CoNLL03和OntoNotes5.0分别仅包含90个和174个候选跨度。结果表明,面向邻域的打包策略能够很好地处理句子较长、标记组较多的数据集,较好地模拟了邻域跨度之间的相互关系。
- 在使用相同的大型预训练编码器的情况下,PL-Marker在所有六个NER基准测试中的F1绝对值比T-Concat提高了+0.1%-1.1%,这表明了悬浮式标记器在聚合跨度表示实体类型预测方面的优势。
- 在CoNLL03、OntoNote 5.0和Low-Nerd中,PL-Marker的绝对F1分别比SeqTagger高+0.4%、+0.7%和+1.9%,其中CoNL03、OntoNote 5.0和Low-Nerd分别包含4、18和66种实体类型。这些改进证明了PL-Marker在处理不同类型实体之间的不同相互关系方面的有效性。
4.3 Relation Extraction
4.3.1 Results
如表3所示,使用相同的BERT-BASE编码器,本文的方法比以前的方法在ACE05上的F1严格提高了1.7%,在ACE04上的F1值严格提高了2.5%。
使用SciBERT编码器,本文的方法在SciERC上也实现了最佳性能。使用更大的编码器ALBERT-XXLARGE,本文的NER和RE模型都得到了进一步的改进。与之前最先进的模型PURE(FULL)相比,本文的模型分别在ACE05和ACE04上获得了显著的+4.1%和+4.3%的严格关系F1改进。这些相对于PURE的改进表明了在训练过程中对相同subject或相同object实体对之间的相互关系进行建模的有效性。
4.4 Inference Speed
在这一部分中,本文比较了模型在批处理大小为32的A100 GPU上的推理速度。本文在实验中使用了用于ACE05和SciERC的基本尺寸编码器和用于平板NER模型的大尺寸编码器。
4.4.1 Speed of Span Model
在CoNLL03和FewNERD上评估了不同组大小的PL-Marker的推理速度。本文还评估了一个级联两阶段模型,它使用一个快速的基本大小的T-Concat模型来为本文的模型过滤候选跨度。如表4所示,与CoNLL03相比,PL-Marker实现了0.4F1的改进,但与SeqTagger模型相比,速度损失了60%。

本文观察到,本文提出的两阶段模型与PL-Marker的性能相似,在少数人上的加速比为3.1倍,这表明使用PL-Marker作为后处理模块来阐述简单模型中的粗略预测是更有效的。此外,当团队规模增长到512时,由于transformer的复杂性增加,PLMarker的速度会变慢。因此,在实践中,本文选择256个组大小。
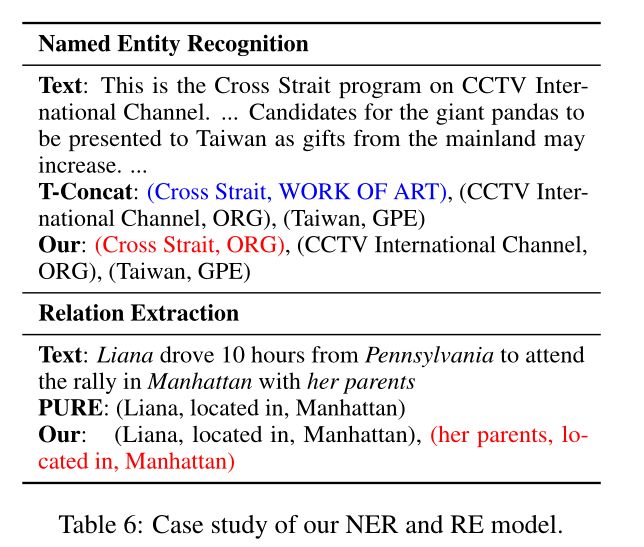
4.5 Case Study
本文给出了几个例子来比较本文的SPAN模型和T-CONCAT,以及本文的SPAN对模型和纯(FULL)模型。如表6所示,本文的SPAN模型可以收集加下划线的SPAN的上下文信息,如台湾和大陆,帮助预测其类型为组织而不是艺术品。本文的SPAN模型学习在训练阶段综合考虑同一subject关系事实之间的相互关系,从而成功地获得利亚娜和她的父母都在曼哈顿的事实。
4.6 Ablation Study
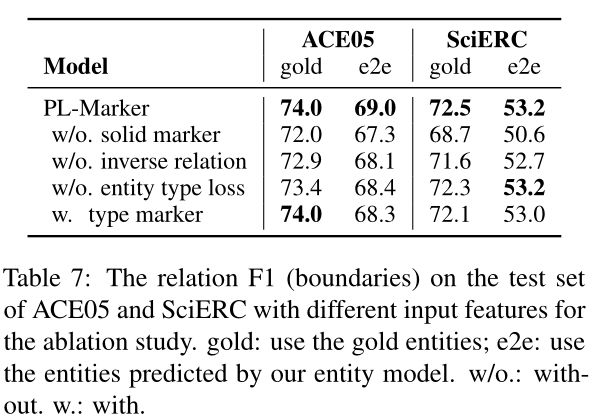
在这一部分,本文进行消融研究,以调查不同的组件对本文的RE模型的贡献,其中本文在实验中使用了基本尺寸编码器。
Two pairs of Levitated Markers
本文评估了w/o实体标记基线,它将两对悬浮标记分别应用于subject和object,并将所有跨度对打包到一个实例中。如表7所示,与PL-Marker相比,当给出黄金实体时,没有可靠标记的模型在ACE05和SciERC上的F1下降了2.0%-3.8%。
结果表明,由于一对悬浮标记已经被定向注意捆绑,因此继续应用定向注意捆绑两对悬浮标记是次优的。
Inverse Relation逆关系
本文为双向预测的每个不对称关系建立一个逆关系。本文对没有逆关系的模型进行了评估,该模型用非关系类型代替了所构造的逆关系,并采用了单向预测。如表7所示,在给定黄金实体的情况下,没有反向关系的模型在两个数据集上都下降了0.9%-1.1%F1,这表明了在本文的非对称框架中对从object实体到subject实体的信息建模的重要性。
Entity Type
在RE模型中加入辅助实体类型损失,引入实体类型信息。如表7所示,当给定黄金实体时,没有实体类型损失的模型在两个数据集上都下降了0.4%-0.7%的F1,这表明了实体类型信息在RE中的重要性。此外,本文还尝试使用类型标记,如[subject:PER]和[object:GPE],将NER模型预测的实体类型信息注入到RE模型中。
本文发现,在端到端设置中,带有类型标记的RE模型的性能略逊于具有实体类型丢失的模型。结果表明,如果采用类型标记符作为输入特征,则NER模型的实体类型预测误差可以传播到RE模型。最后,本文讨论了何时使用RE模型中的实体类型预测来细化附录中的NER预测,并根据ACE04和ACE05的数据集统计数据最终细化了除SciERC之外的ACE04和ACE05的实体类型。
5 启示
- 在大环境都是联合抽取的情况下,陈丹琪大佬提出了流水线方法,这篇文章是其升级版。
- 由于计算了所有可能的span,因此时间复杂度比较高,作者也提出了方法缓解这个问题,由于没有复现代码,因此不敢评论时间复杂度如何。
- 在实体和关系抽取上的表现出奇的高,有兴趣的可以尝试继续做下去。
- 欢迎关注微信公众号:自然语言处理CS,一起来交流NLP。