2022.7.3 第十三次周报
目录
一、基本概念 What is RL?
1.Machine Learning编辑Looking for a Function
2.Example:Playing Video Game
3.Example:Learning to play Go
4.Step1:Function with Unknown
5.Step2:Define"Loss"
6.Step3:Optimization
二、Policy Gradient
1.How to control your actor
2.Policy Gradient
3.On-policy V.S. Off-policy
4.Proximal Policy Optimization(PPO)
5.Collection Training Data:Exploration
三、Actor-Critic
1.Critic
2.How to estimate 编辑(s)
3.MC V.S. TD
4.Tip of Actor-Critic
四、Reward Shaping
1.Sparse Reward
2.Reward Shaping-Curiosity
五、No Reward:Learning from Demonstration
1.Motivation
2.Imitation Learning
3.Inverse Reinforcement Learning
4.Framework of IRL
一、基本概念 What is RL?
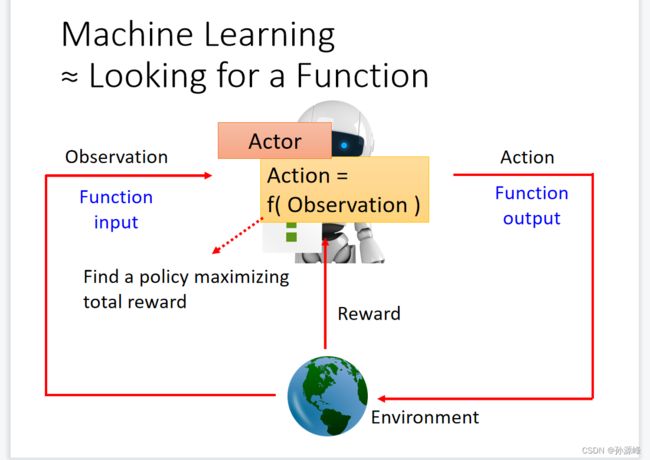
1.Machine Learning Looking for a Function
Looking for a Function
强化学习(Reinforcement Learning, RL),又称再励学习、评价学习或增强学习,是机器学习的范式和方法论之一,用于描述和解决智能体(agent)在与环境的交互过程中通过学习策略以达成回报最大化或实现特定目标的问题。
强化学习是智能体(Agent)以“试错”的方式进行学习,通过与环境进行交互获得的奖赏指导行为,目标是使智能体获得最大的奖赏,强化学习不同于连接主义学习中的监督学习,主要表现在强化信号上,强化学习中由环境提供的强化信号是对产生动作的好坏作一种评价(通常为标量信号),而不是告诉强化学习系统RLS(reinforcement learning system)如何去产生正确的动作。由于外部环境提供的信息很少,RLS必须靠自身的经历进行学习。通过这种方式,RLS在行动-评价的环境中获得知识,改进行动方案以适应环境。
强化学习把学习看作试探评价过程,Agent选择一个动作用于环境,环境接受该动作后状态发生变化,同时产生一个强化信号(奖或惩)反馈给Agent,Agent根据强化信号和环境当前状态再选择下一个动作,选择的原则是使受到正强化(奖)的概率增大。选择的动作不仅影响立即强化值,而且影响环境下一时刻的状态及最终的强化值。
2.Example:Playing Video Game

3.Example:Learning to play Go

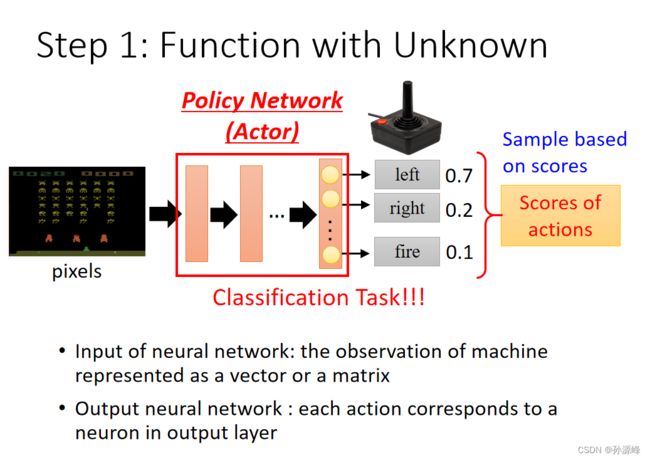
4.Step1:Function with Unknown
以空间入侵游戏为例:输入的是游戏画面,输出是不同行为的概率(相同的输入可能有不同的输出,输出具有随机性)
5.Step2:Define"Loss"
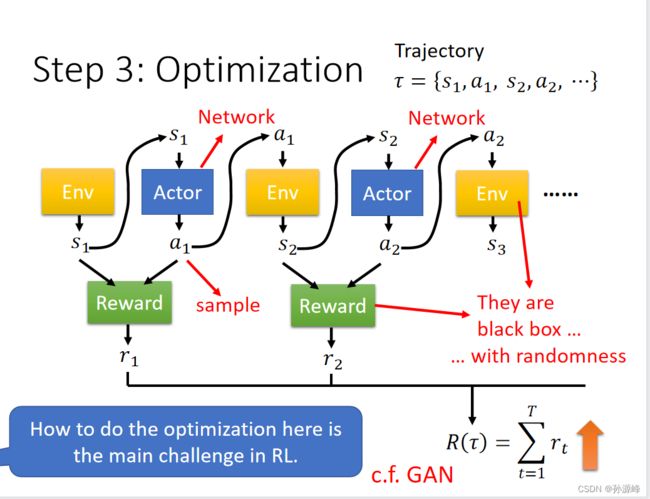
看到一个游戏画面会产生行为然后会产生游戏的reward,再接下去另一个游戏画面输出行为,一直持续到游戏结束,将所有的reward相加,并且最大化reward,RL的损失函数为负的Total reward。

6.Step3:Optimization
二、Policy Gradient
1.How to control your actor
- 对于一个具体的观察如果要有一个固定的行为,就使损失函数越小越好
- 如果是不要采取一个行为,就使损失函数越大越好
最后收集训练资料,对于某一个s要输出a或者不要输出a,赋予权重来说明好或不好及其程度,然后计算交叉熵与权重相乘再全部相加,使这个损失函数最小化。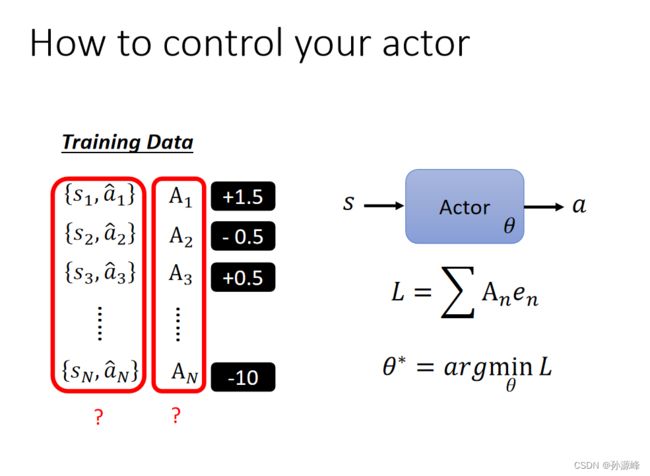
2.Policy Gradient
每次更新模型参数时,都需要再次收集整个训练集。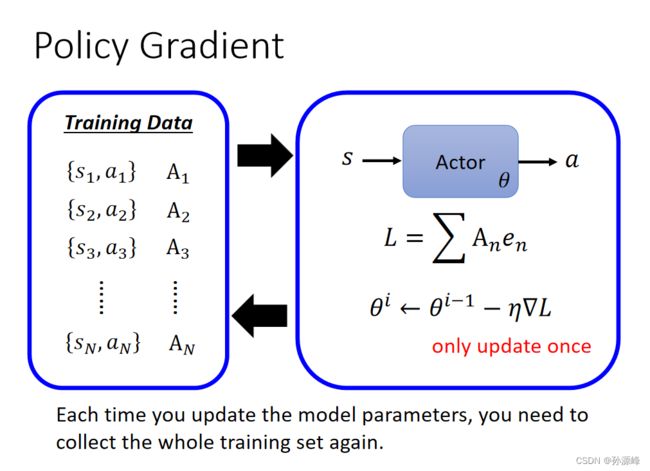
3.On-policy V.S. Off-policy
On-policy: 学习到的agent以及和环境进行互动的agent是同一个agent
Off-policy: 学习到的agent以及和环境进行互动的agent是不同的agent

4.Proximal Policy Optimization(PPO)
要训练的演员必须知道它与演员的区别才能进行互动。
例子:DeepMind-PPO
OpenAI-PPO
5.Collection Training Data:Exploration
在数据收集过程中,参与者需要具有随机性。随机性是非常重要的。假设你的actor总是“向左移动”。我们永远不知道如果采取“开火”会发生什么。所以有时候我们会故意加大随机性在模型里。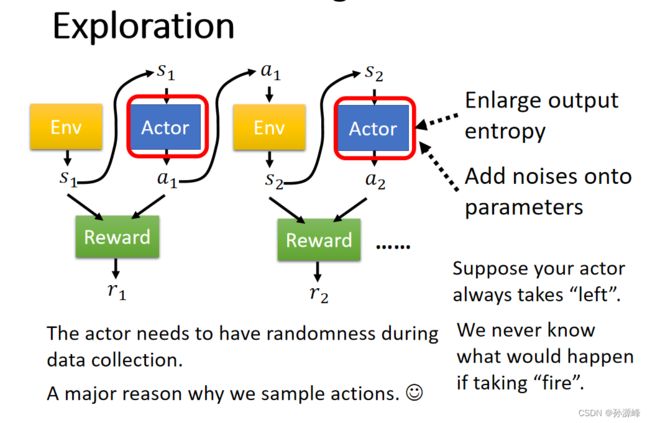
三、Actor-Critic
1.Critic
评估某个actor看到游戏画面输出行为接下来得到的reward。Critic是衡量在state s情况下这个actor有多好,是一种比较程度的好坏。而![]() 得到的值既取决于actor
得到的值既取决于actor ,又取决于当前的state s。
,又取决于当前的state s。

2.How to estimate 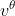 (s)
(s)
有两种方法可以评估![]() (s)
(s)
第一种是Monte-Carlo (MC)based approach
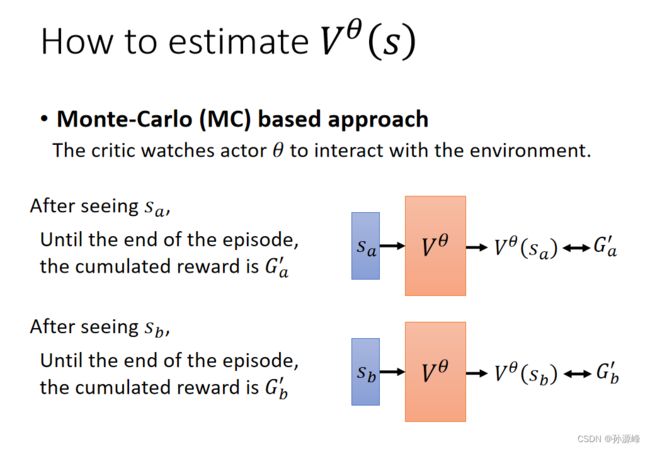
MC based方法,根据sa获得的reward的累计值Ga通过输入sa线性回归预测,预测值即为![]() (sa)
(sa)
注意,Ga累计值是要游戏玩到结束才能得到的估测值。
第二种是Temporal-difference (TD) approach

MC based方法要游戏结束才能更新游戏,对于有些非常长的游戏可能收集不到太多的数据。因此引入了TD based方法,不需要游戏玩到底就可以更新参数。此时的训练目标就是希望通过![]() 神经网络对St,St+1预测出来的
神经网络对St,St+1预测出来的![]() (St)与
(St)与![]() (St+1)的差值越接近Rt越好。
(St+1)的差值越接近Rt越好。
3.MC V.S. TD

4.Tip of Actor-Critic
小技巧:两个Network的部分参数可以共用。

四、Reward Shaping
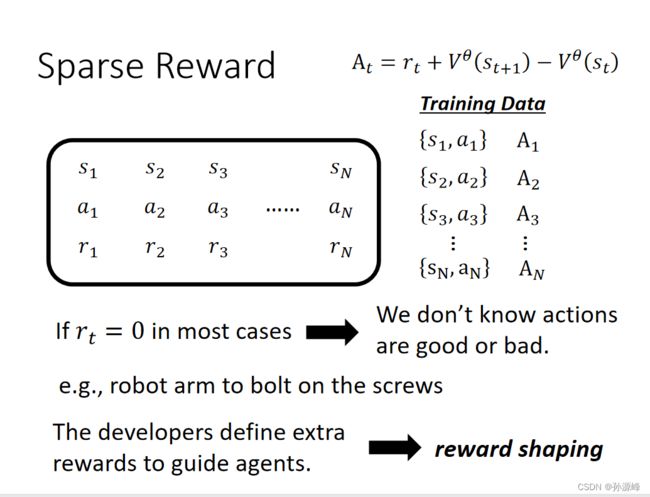
当reward的分布非常分散时,对于机器而言学习如何行动会十分困难。
比如说要让一个机器人倒水进水杯里,如果不对机器人做任何指导,可能它做很多次尝试,reward都一直是零。
因此,在训练或指导一个actor去做你想要它做的事情时,需要进行reward shaping
1.Sparse Reward
比如下棋,每一步的reward都是0,直到下完棋才有reward
所以需要定义额外的reward来指导机器学习,这就叫做reward shaping
2.Reward Shaping-Curiosity
当机器看到新的东西就加分(这个新的东西要有意义)所以要克服没意义的新的东西,即杂讯。
五、No Reward:Learning from Demonstration
1.Motivation
- 机器也可以和环境进行互动,但是不能明显的得到reward
- 在某些任务中很难定义reward
- 人为涉及的奖励可能会得到不受控制的行为
因此需要 imitation learning: 让一个专家来示范应该如何解决问题,而机器则试着去模仿专家

2.Imitation Learning
每次行为之后不产生reward,使人类与环境进行互动来示范,让机器模仿人类的行为。

3.Inverse Reinforcement Learning
在前面介绍过的RL中:环境和reward是用来生成一个actor的,但是在IRL中,没有reward function,而是用一个专家来和环境做互动并学到一个reward function,然后这个reward function才会被用来训练actor。生成的reward可能会很简单,但也可能会导致复杂的policy。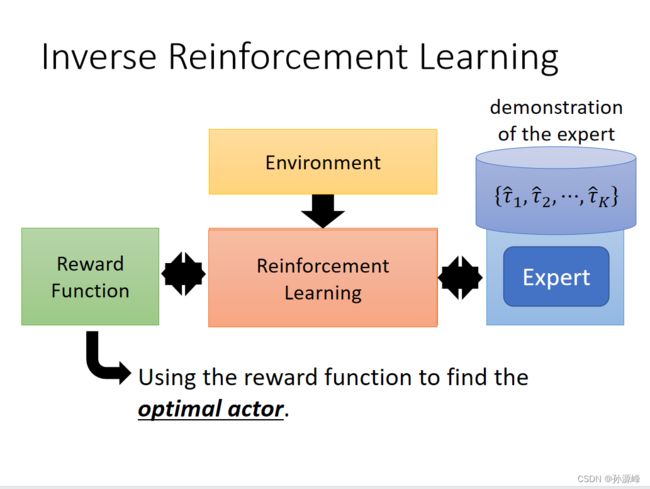
原则:老师永远是最好的。
基本理念:
初始化执行组件
在每次迭代中
参与者与环境交互以获得一些轨迹。
定义奖励函数,使老师的轨迹比演员更好。
演员学习根据新的奖励函数最大化奖励。
输出奖励函数和从奖励函数中学习的参与者
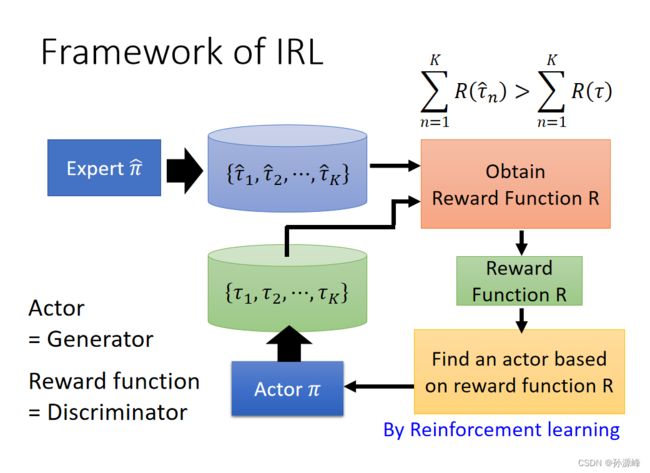
4.Framework of IRL
- 专家和actor都会生成对应的 trajectory.
- 生成的reward function需要满足专家的累积reward总是比actor的大
- 使用reward function来训练一个新的actor替换原来旧的actor
- 重复上述步骤.