2022.7.16 第十五次周报
目录
一、Life Long Learning 终身学习
1.What people think about AI
2.Life Long Learning in real-world applications
3.Example
3.1 影像辨识
3.2 QA问答
4.Catastrophic Forgetting 灾难性遗忘
5.Life-Long V.S. Transfer
6.Evaluation
二、Research Directions 研究方向
1.Selective Synaptic Plasticity
2.Additional Neural Resource Allocation
3.Memory Reply
一、Life Long Learning 终身学习
1.What people think about AI
人们希望机器可以通过学习一个又一个的任务,来获得更多的技能。
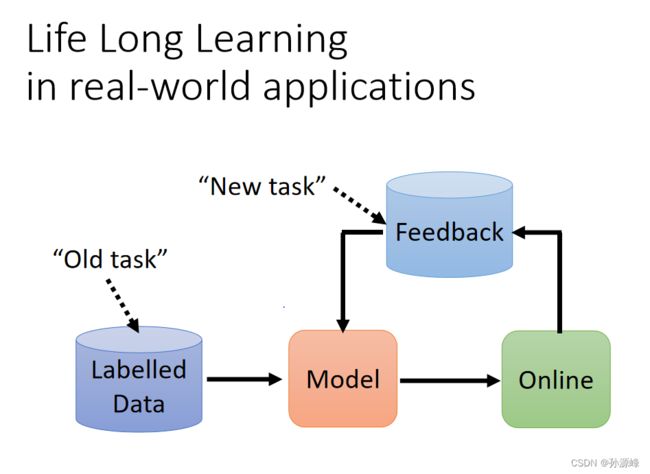
2.Life Long Learning in real-world applications
Life Long Learning就是让机器可以持续学习,能处理各种各样的任务。也就是模型通过不断看新的资料,得到反馈,然后更新自身,变得更厉害,能处理更多事情。
3.Example
3.1 影像辨识
我们先用任务一的数据库对其进行导入,进行学习训练,当我们进行检验的时候发现,这个模型完任务一的准确率是百分之九十,完成任务二的准确率是百分之九十六。当我们把上一步训练好的模型参数作为训练任务二的模型初始值的时候,我们再经过训练发现,任务一数字识别的准确率变为百分之八十,任务二数字识别的准确率变为百分之九十七,可以看到的是任务二仅仅提高了百分之一,但是任务一却忘记了。我们发现,机器学完一个任务之后,再去学另一个任务,那第一任务就会被遗忘,而且这与模型自身的能力无关,因为当两种训练数据同时训练时,模型在两种任务上的表现都是好的。

3.2 QA问答
例子中,模型连续训练20个任务,和模型同时训练20个任务的结果,左图发现,模型训练到任务5时,准确率很高,在学习其它任务后,就降下去了,右图则表示这个模型有能力训练这20个任务。

4.Catastrophic Forgetting 灾难性遗忘
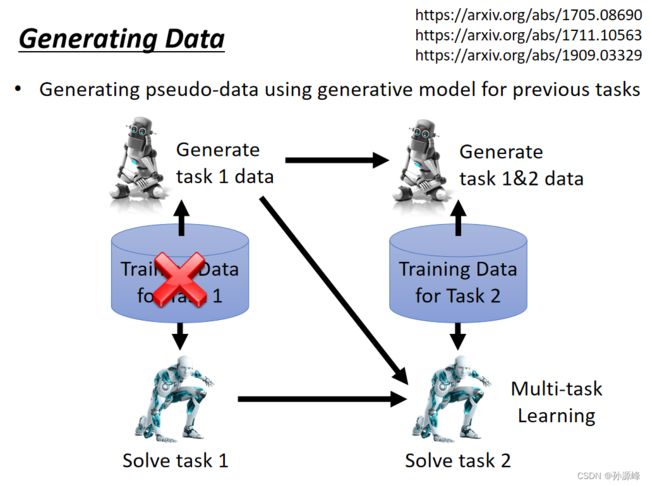
我们将上面两个例子展现的情况成为灾难性遗忘。那么为什么我们不将所有的训练资料同时训练,达到让模型具有多种能力?这种训练方式叫做Multi-task训练,但会有一个问题,机器需要存储所有的训练资料,并且在学新知识时需要计算所有的训练资料。有论文提出,Multi-task的结果可以作为life-long learning的上界。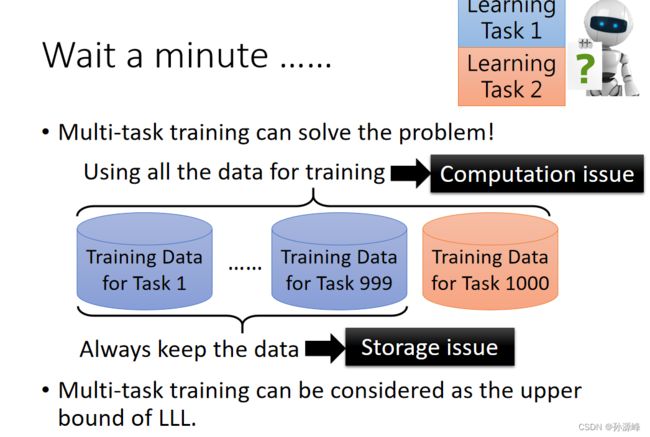
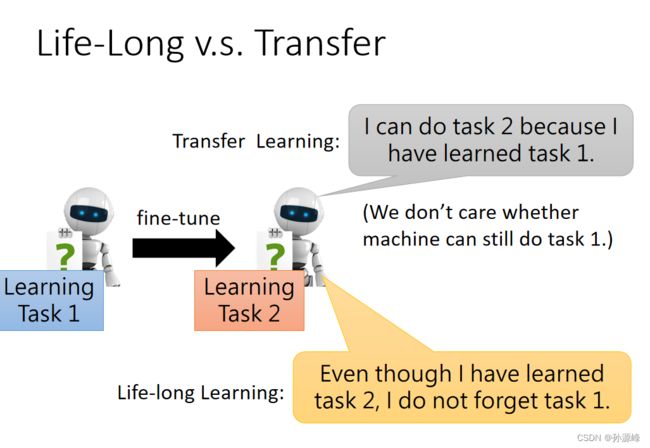
5.Life-Long V.S. Transfer
Life Long Learning和Transfer Learning最主要的区别在于学会新任务后,会不会忘记之前学过的任务。
6.Evaluation
下面讲到一种评估终身学习的办法,里面涉及三种指标。分别是:
Accuracy,就是训练完最后一个任务后,在所有任务做测试得到的平均分;
Backward Transfer,训练过任务i之后,最后一个任务训完之后,任务i的测试得分和训练任务i的得分差,然后再求和取平均;(一般这个值都是负的,因为会有遗忘)
Forward Transfer,前i-1个任务训练之后的模型在任务i的测试得分与随机初始化的得分的差,然后求和取平均。(它反映了任务i是否收到前i-1个任务的影响,导致有所提升)

二、Research Directions 研究方向
1.Selective Synaptic Plasticity
为什么会发生灾难性遗忘?
是因为机器学会新任务得到的参数在过去的任务上,可能会导致机器在新任务上表现的不好
一种解决方式就是控制参数更新,让参数在所有任务上表现都好。

下面我们来说一下 Selective Synaptic Plasticity。它的基本思想:模型中的某些参数对前面的任务很重要,仅更改不重要的参数。我们原来的loss function仅仅是对参数θ进行更新,但是没有考虑这个参数是否是重要的。我们新的loss function就考虑了这一点,在之前的条件下,我们加入了新的一项。引入了一个参数叫做bi来衡量参数θi的重要性,重要的参数,如果改变很大,Loss值也会变大。

右边上图:如果二次微分比较小的话,就意味着在θ1方向(x轴)的重要性是很低的,意味着在x轴方向可以进行大的移动。
右边下图:如果二次微分比较大,就意味着在θ2(y轴)方向的重要性是比较高的,所以就不能在y轴方向进行太大的移动。

还有一种叫做GEM的方法。通过原先任务的梯度,来限制当前任务的参数更新,不过要获得原先任务的梯度,还是需要少部分原先任务的训练资料。

2.Additional Neural Resource Allocation
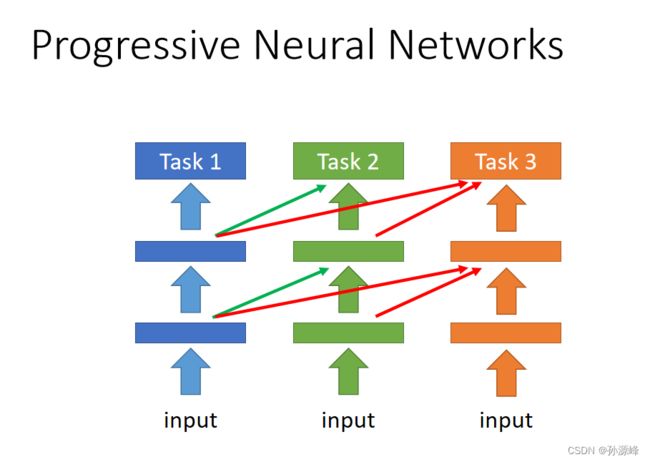
一种做法就是Pregressive Neural Network,它每训练一个新任务就会增加一个新网络,然后将原先任务的隐藏层输出作为输入,这样就可以考虑前面的任务,不会遗忘,但是随着会的任务越来越多,网络也会越来越大,这会导致memory总有一天会耗尽。
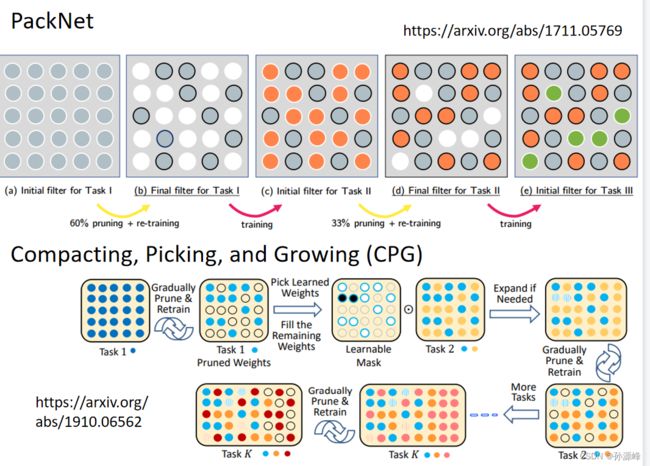
另一种做法是PackNet,就是先定义一个大网络,每学一个任务只用其中的一部分neuron进行训练,这与上面的想法差不多,还是会有问题。
3.Memory Reply
下面我们介绍另一种方法,我们可以不存储之前task的数据,而是通过generater(生成器)去生成之前task的数据集。通过一个额外的生成器,生成原先任务的数据,之后就可以进行Multi-task Learning,这种方式只要生成器比原先任务的数据占用的memory小,就有优势,另外通过实验表明,这种方式是很有效的,很接近上界。