知识蒸馏(Knowledge Distillation)
1、Distilling the Knowledge in a Neural Network
Hinton的文章"Distilling the Knowledge in a Neural Network"首次提出了知识蒸馏(暗知识提取)的概念,通过引入与教师网络(teacher network:复杂、但推理性能优越)相关的软目标(soft-target)作为total loss的一部分,以诱导学生网络(student network:精简、低复杂度)的训练,实现知识迁移(knowledge transfer)。
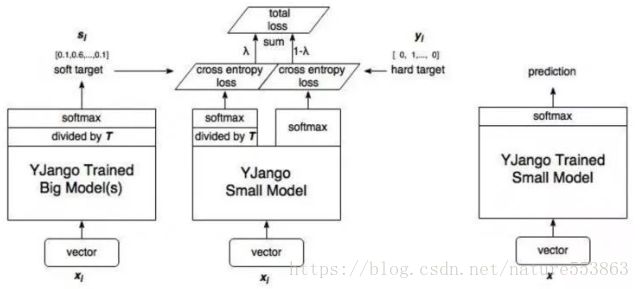
如上图所示,教师网络(左侧)的预测输出除以温度参数(Temperature)之后、再做softmax变换,可以获得软化的概率分布(软目标),数值介于0~1之间,取值分布较为缓和。Temperature数值越大,分布越缓和;而Temperature数值减小,容易放大错误分类的概率,引入不必要的噪声。针对较困难的分类或检测任务,Temperature通常取1,确保教师网络中正确预测的贡献。硬目标则是样本的真实标注,可以用one-hot矢量表示。total loss设计为软目标与硬目标所对应的交叉熵的加权平均(表示为KD loss与CE loss),其中软目标交叉熵的加权系数越大,表明迁移诱导越依赖教师网络的贡献,这对训练初期阶段是很有必要的,有助于让学生网络更轻松的鉴别简单样本,但训练后期需要适当减小软目标的比重,让真实标注帮助鉴别困难样本。另外,教师网络的推理性能通常要优于学生网络,而模型容量则无具体限制,且教师网络推理精度越高,越有利于学生网络的学习。
教师网络与学生网络也可以联合训练,此时教师网络的暗知识及学习方式都会影响学生网络的学习,具体如下(式中三项分别为教师网络softmax输出的交叉熵loss、学生网络softmax输出的交叉熵loss、以及教师网络数值输出与学生网络softmax输出的交叉熵loss):
联合训练的Paper地址:https://arxiv.org/abs/1711.05852


2、Exploring Knowledge Distillation of Deep Neural Networks for Efficient Hardware Solutions
这篇文章将total loss重新定义如下:
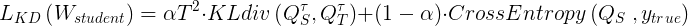
GitHub地址:https://github.com/peterliht/knowledge-distillation-pytorch
total loss的Pytorch代码如下,引入了精简网络输出与教师网络输出的KL散度,并在诱导训练期间,先将teacher network的预测输出缓存到CPU内存中,可以减轻GPU显存的overhead:
-
def loss_fn_kd(outputs, labels, teacher_outputs, params):
-
"""
-
Compute the knowledge-distillation (KD) loss given outputs, labels.
-
"Hyperparameters": temperature and alpha
-
NOTE: the KL Divergence for PyTorch comparing the softmaxs of teacher
-
and student expects the input tensor to be log probabilities! See Issue #2
-
"""
-
alpha = params.alpha
-
T = params.temperature
-
KD_loss = nn.KLDivLoss()(F.log_softmax(outputs/T, dim=
1),
-
F.softmax(teacher_outputs/T, dim=
1)) * (alpha * T * T) + \
-
F.cross_entropy(outputs, labels) * (
1. - alpha)
-
-
return KD_loss
3、Ensemble of Multiple Teachers
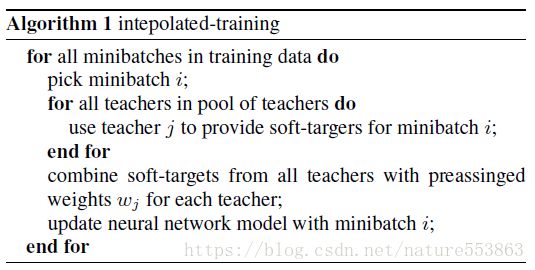
第一种算法:多个教师网络输出的soft label按加权组合,构成统一的soft label,然后指导学生网络的训练:
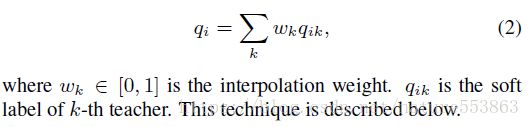
第二种算法:由于加权平均方式会弱化、平滑多个教师网络的预测结果,因此可以随机选择某个教师网络的soft label作为guidance:

第三种算法:同样地,为避免加权平均带来的平滑效果,首先采用教师网络输出的soft label重新标注样本、增广数据、再用于模型训练,该方法能够让模型学会从更多视角观察同一样本数据的不同功能:

Paper地址:
https://www.researchgate.net/publication/319185356_Efficient_Knowledge_Distillation_from_an_Ensemble_of_Teachers
4、Hint-based Knowledge Transfer
为了能够诱导训练更深、更纤细的学生网络(deeper and thinner FitNet),需要考虑教师网络中间层的Feature Maps(作为Hint),用来指导学生网络中相应的Guided layer。此时需要引入L2 loss指导训练过程,该loss计算为教师网络Hint layer与学生网络Guided layer输出Feature Maps之间的差别,若二者输出的Feature Maps形状不一致,Guided layer需要通过一个额外的回归层,具体如下:
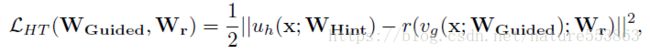
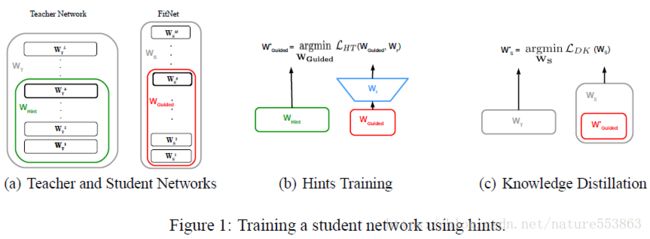
具体训练过程分两个阶段完成:第一个阶段利用Hint-based loss诱导学生网络达到一个合适的初始化状态(只更新W_Guided与W_r);第二个阶段利用教师网络的soft label指导整个学生网络的训练(即知识蒸馏),且total loss中soft target相关部分所占比重逐渐降低,从而让学生网络能够全面辨别简单样本与困难样本(教师网络能够有效辨别简单样本,而困难样本则需要借助真实标注,即hard target):

Paper地址:https://arxiv.org/abs/1412.6550
GitHub地址:https://github.com/adri-romsor/FitNets
5、Attention to Attention Transfer
通过网络中间层的attention map,完成teacher network与student network之间的知识迁移。考虑给定的tensor A,基于activation的attention map可以定义为如下三种之一:

随着网络层次的加深,关键区域的attention-level也随之提高。文章最后采用了第二种形式的attention map,取p=2,并且activation-based attention map的知识迁移效果优于gradient-based attention map,loss定义及迁移过程如下:
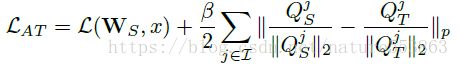
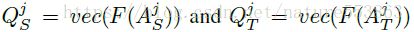
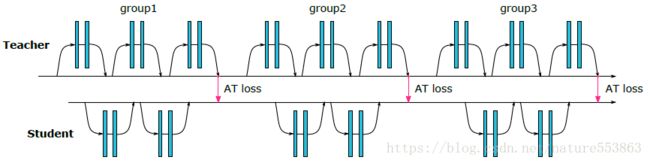
Paper地址:https://arxiv.org/abs/1612.03928
GitHub地址:https://github.com/szagoruyko/attention-transfer
6、Flow of the Solution Procedure
暗知识亦可表示为训练的求解过程(FSP: Flow of the Solution Procedure),教师网络或学生网络的FSP矩阵定义如下(Gram形式的矩阵):
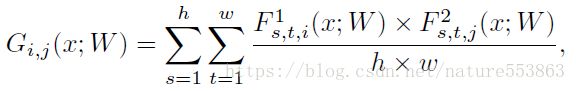
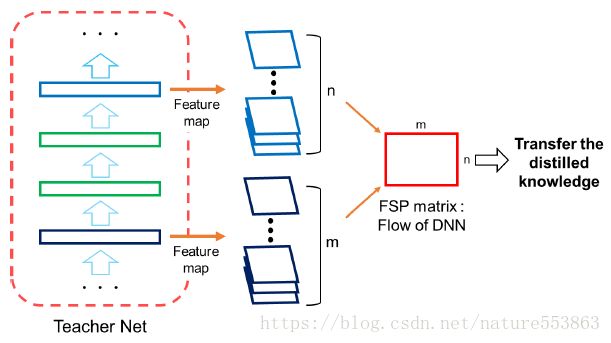
训练的第一阶段:最小化教师网络FSP矩阵与学生网络FSP矩阵之间的L2 Loss,初始化学生网络的可训练参数:

训练的第二阶段:在目标任务的数据集上fine-tune学生网络。从而达到知识迁移、快速收敛、以及迁移学习的目的。
Paper地址:
http://openaccess.thecvf.com/content_cvpr_2017/papers/Yim_A_Gift_From_CVPR_2017_paper.pdf
7、Knowledge Distillation with Adversarial Samples Supporting Decision Boundary
从分类的决策边界角度分析,知识迁移过程亦可理解为教师网络诱导学生网络有效鉴别决策边界的过程,鉴别能力越强意味着模型的泛化能力越好:
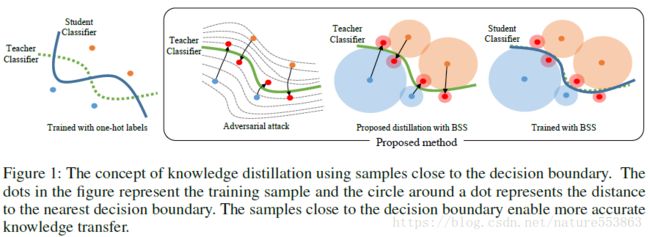
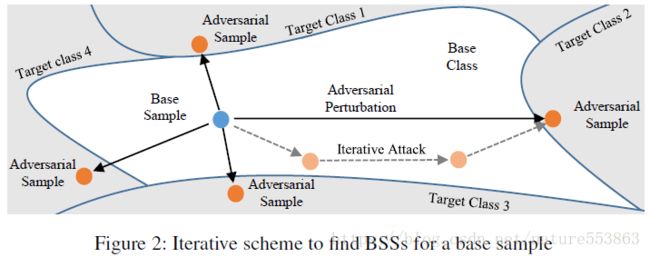
文章首先利用对抗攻击策略(adversarial attacking)将基准类样本(base class sample)转为目标类样本、且位于决策边界附近(BSS: boundary supporting sample),进而利用对抗生成的样本诱导学生网络的训练,可有效提升学生网络对决策边界的鉴别能力。文章采用迭代方式生成对抗样本,需要沿loss function(基准类得分与目标类得分之差)的梯度负方向调整样本,直到满足停止条件为止:
loss function:

沿loss function的梯度负方向调整样本:

停止条件(只要满足三者之一):

结合对抗生成的样本,利用教师网络训练学生网络所需的total loss包含CE loss、KD loss以及boundary supporting loss(BS loss):

Paper地址:https://arxiv.org/abs/1805.05532
8、Label Refinery:Improving ImageNet Classification through Label Progression
这篇文章通过迭代式的诱导训练,主要解决训练期间样本的crop与label不一致的问题,以增强label的质量,从而进一步增强模型的泛化能力:

诱导过程中,total loss表示为本次迭代(t>1)网络的预测输出(概率分布)与上一次迭代输出(Label Refinery:类似于教师网络的角色)的KL散度:

文章实验部分表明,不仅可以用训练网络作为Label Refinery Network,也可以用其他高质量网络(如Resnet50)作为Label Refinery Network。并在诱导过程中,能够对抗生成样本,实现数据增强。
GitHub地址:https://github.com/hessamb/label-refinery
9、Miscellaneous
-------- 知识蒸馏可以与量化结合使用,考虑了中间层Feature Maps之间的关系,可参考:
https://blog.csdn.net/nature553863/article/details/82147933
-------- 知识蒸馏与Hint Learning相结合,可以训练精简的Faster-RCNN,可参考:
https://blog.csdn.net/nature553863/article/details/82463249
-------- 模型压缩方面,更为详细的讨论,请参考:
https://blog.csdn.net/nature553863/article/details/81083955