【Pytorch】残差神经网络(Residual Networks)
一、背景
传统的神经网络,由于网络层数增加,会导致梯度越来越小,这样会导致后面无法有效的训练模型,这样的问题成为梯度消弭。为了解决这样的问题,引入残差神经网络(Residual Networks),残差神经网络的核心是”跳跃”+“残差块”。通过引入RN网络,可以有效缓解梯度消失的问题,可以训练更深的网络。
二、残差网络的基本模型
下图是一个基本残差块。它的操作是把某层输入跳跃连接到下一层乃至更深层的激活层之前,同本层输出一起经过激活函数输出。
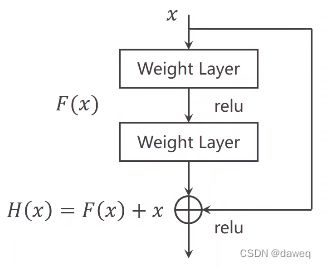
当对H(x)进行求导时,x求导为1,这样就避免了F(X)导数过小,进而使梯度消失的问题。
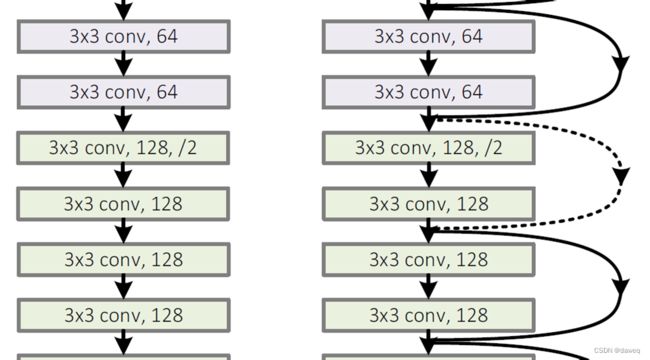
有图就是将几个残差块连接在一起。
三、简单残差神经网络的实现
用Pytorch实现以下残差神经网络模型。
(1)导入包
import torch
from torch import nn
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
import matplotlib.pyplot as plt
(2)数据准备
batch_size = 64
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307, ), (0.3081, ))
])
train_dataset = datasets.MNIST(root='dataset/mnist',
train=True,
download=True,
transform=transform)
train_loader = DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=True)
test_dataset = datasets.MNIST(root='dataset/mnist',
train=False,
download=True,
transform=transform)
test_loader = DataLoader(dataset=test_dataset,
batch_size=batch_size,
shuffle=False)
(3)残差模型
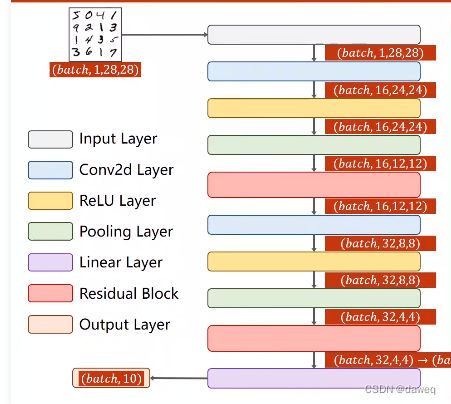
定义残差模型,根据最基本的残差块,残差中间需要经过卷积->激活->卷积这样的操作,为了保证输入输出大小一致,故中间两个卷积层的输入输出大小都和模型最初输入大小保持一致。在前馈中可以看到是卷积->激活->卷积->与输入相加这样的过程。
class ResidualBlock(nn.Module):
def __init__(self, channels):
super(ResidualBlock, self).__init__()
self.channels = channels
self.conv1 = nn.Conv2d(channels, channels, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(channels, channels, kernel_size=3, padding=1)
def forward(self, x):
y = F.relu(self.conv1(x))
y = self.conv2(y)
return F.relu(x + y)
(4)神经网络模型
这一步就是对整个神经网络流程的复刻,注意每一层输入输出数据的大小,保证层与层之间能相连就可以了。
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1,16, kernel_size=5)
self.conv2 = nn.Conv2d(16, 32, kernel_size=5)
self.mp = nn.MaxPool2d(2)
self.rblock1 = ResidualBlock(16)
self.rblock2 = ResidualBlock(32)
self.fc = nn.Linear(512, 10)
def forward(self, x):
in_size = x.size(0)
x = self.mp(F.relu(self.conv1(x)))
x = self.rblock1(x)
x = self.mp(F.relu(self.conv2(x)))
x = self.rblock2(x)
x = x.view(in_size, -1)
x = self.fc(x)
return x
(5)训练
def train(epoch):
running_loss = 0
for batch_idx, data in enumerate(train_loader, 0):
inputs, target = data
inputs, target = inputs.to(device), target.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d, %5d] loss: %.3f' % (epoch + 1, batch_idx + 1, running_loss / 300))
running_loss = 0
(6)测试
accuracy = []
def min_test():
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, dim=1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy on test set: %d %%' % (100 * correct / total))
accuracy.append(100 * correct / total)
(7)主函数
model = Net()
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device)
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
if __name__ == '__main__':
for epoch in range(20):
train(epoch)
min_test()
print(accuracy)
plt.plot(range(20), accuracy)
plt.xlabel("epoch")
plt.ylabel("Accuracy")
plt.show()
四、实验结果
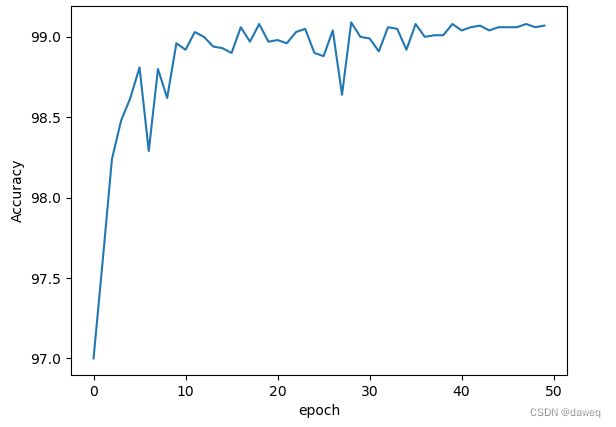
实现效果还可以,经过20个周期训练正确率最高能有99.25%。

**训练50次的效果,很神秘,感觉数据之神需要我献祭点什么 **

五、后续工作
1.阅读文献:
Identity Mappings in Deep Residual Networks
2.选取其中提供的一些残差快对神经网络进行测试,比较几个模型的差别。
3.学习《动手学习深度学习》。
4.学习Pytorch文档。
5.阅读经典论文,复现经典场景。