CVPR 2021 | GFLV2:目标检测良心技术,无Cost涨点!
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
本文作者:李翔 | 来源:知乎(已授权)
https://zhuanlan.zhihu.com/p/313684358

论文:https://arxiv.org/abs/2011.12885
源码和预训练模型地址:
https://github.com/implus/GFocalV2
老规矩,还是一句话总结:
本文应该是检测领域首次引入用边界框的不确定性的统计量来高效地指导定位质量估计,从而基本无cost(包括在训练和测试阶段)地提升one-stage的检测器性能,涨幅在1~2个点AP。又是一个超超超良心技术,欢迎各位看官试用~
-------------------------------------------------------------------------------
先从文章立意出发,这篇文章完成了两个小小的心愿:
1) GFLV1的遗留问题。
大家都知道,在GFLV1中(还不知道的可以移一小步到:NeurIPS 2020 | Focal Loss改进版来了!GFocal Loss:良心技术,无Cost涨点!),我们提出了对边界框进行一个一般化的分布表示建模,如下图所示:

有了这个可以学习的表示之后,可视化是非常香的:
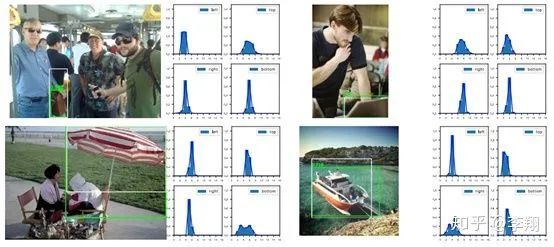
大家可以看到,基本上那些非常清晰明确的边界,它的分布都很尖锐;而模糊定义不清的边界(如背包的上沿和伞的下沿到底在哪里傻傻分不清)它们学习到的分布基本上会平下来,而且有的时候还经常出现双峰的情况。
但是,问题来了,除了可视化,好像这个学到的分布也不能干啥了啊?可视化也不能当饭吃啊。。。另外,在GFLV1整体性能的提升中,相比较于分类-质量联合表示,这个一般化的分布贡献的提点也非常的有限(仅占据了30%),所以这就是GFLV1中遗漏的一个重要问题,如何让这个一般化的分布充分发挥出它的作用?
这也是GFLV2的一大出发点,在GFLV2中,我们正是利用了刚才可视化观察到的这个普适的规律:既然分布的形状和真实的定位质量非常相关,那么我们为什么不好好利用一下,用能够表达分布形状的统计量去指导最终定位质量的估计啊~当时想到这一点的时候不禁拍案叫妙,妙不可言,言不胜code,随即立马开码,没想到竟然一跑就见效了~
2) 提出自己算法的下一代版本。
最近看到大家都纷纷用写软件的方式继承着自己的算法,如YOLOV1-5(竟然已经干到第5代了),DCNV1-2, ReppointsV1-2,当然还要有各种++,如RelationNet和RelationNet++,PAN和PAN++,C和C++,着实有一种长江后浪推前浪,一浪更比一浪强的气势。于是我暗暗立下誓言,在我漫长的科研职业生涯里面,终有一天,我也要用我自己的后浪V2,拍打自己的前浪V1。好嘛,正好得着这个机会,于是乎GFocalV2来啦~
好我们言归正传,接着GFLV1遗留问题的话茬,我们对GFLV1做了一些统计分析,具体把预测框的分布的top-1值和其真实的IoU定位质量做了一个散点图(右上角):
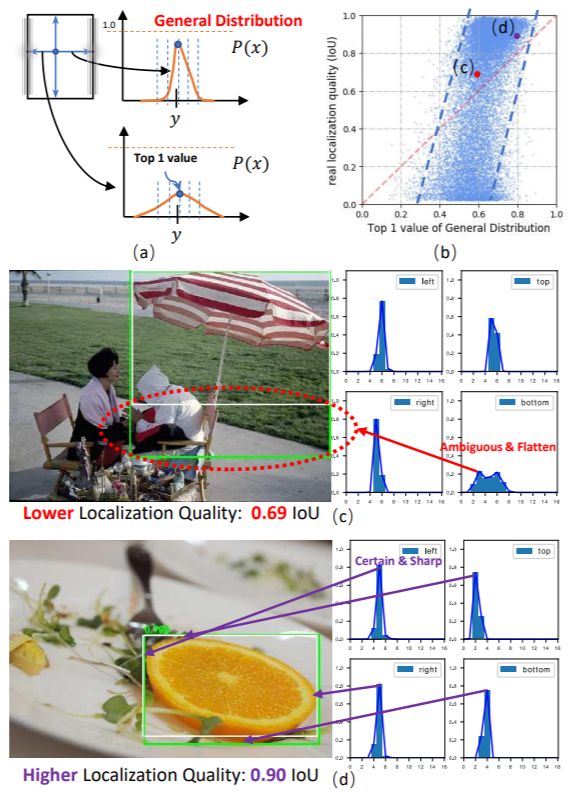
可以看出,整个散点图还是有一个明显地倾向于y=x的趋势的,也就是说,在统计意义上,我们此前观察得出的“分布的形状与真实的定位质量具有较强的相关性”这个假设是基本成立的。当然,为了更好地理解,我们在(b)图中给出了两个具体的散点(c)(d)的case,方便大家观察理解。基于这个分析,我们即决定采用学习到的分布的形状来帮助(协助指导)定位质量估计,从而提升检测的整体性能。
那么如何来刻画分布的形状呢?我们采用了一个非常简单的做法,就是直接取我们学习到的分布(分布是用离散化的多个和为1的回归数值表示的,详情参考GFLV1)的Topk数值。其实理解起来也不难,因为所有数值和为1,如果分布非常尖锐的话,Topk这几个数通常就会很大;反之Topk就会比较小。选择Topk还有一个重要的原因就是它可以使得我们的特征与对象的scale尽可能无关,如下图所示:
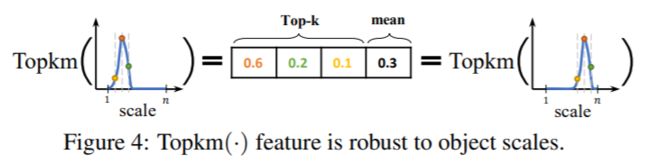
简单来说就是长得差不多形状的分布要出差不多结果的数值,不管它峰值时落在小scale还是大scale。我们把4条边的分布的Topk concat在一起形成一个维度非常低的输入特征向量(可能只有10+或20+),用这个向量再接一个非常小的fc层(通常维度为32、64),最后再变成一个Sigmoid之后的scalar乘到原来的分类表征中,就完事啦~具体model参考下图,其中红色框就是比GFLV1多出来的Distribution-Guided Quality Predictor部分,也就是本文的核心,看上去是不是非常的轻?

得益于输入(分布的统计量)和输出(定位质量)是非常相关的,所以我们这里的网络设计也只需要非常的轻量就能够达到很不错的效果。所以一个巨大的好处是,这个模块的引入并不会对训练和测试带来额外的负担,几乎保持了网络训练和测试的效率,同时还能提1~2个AP点,性价比是真的香。
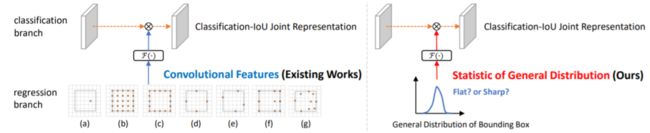
要说GFLV2最大的亮点其实是从思考角度上的。如下图所示,此前有很多工作都在尝试用不同空间维度的卷积特征去增强分类表示(或者是分类-质量联合表示),但鲜有工作落脚于找到一个更加相关的、复杂度非常低的统计特征来指导质量的估计。用一张图可以体现出GFLV2和现有工作的最大区别(同时,如果我没有miss掉一些工作的话,GFLV2也是检测历史上第一个用学习到的分布的统计特征去指导质量估计的):
最后看一下overall的性能:
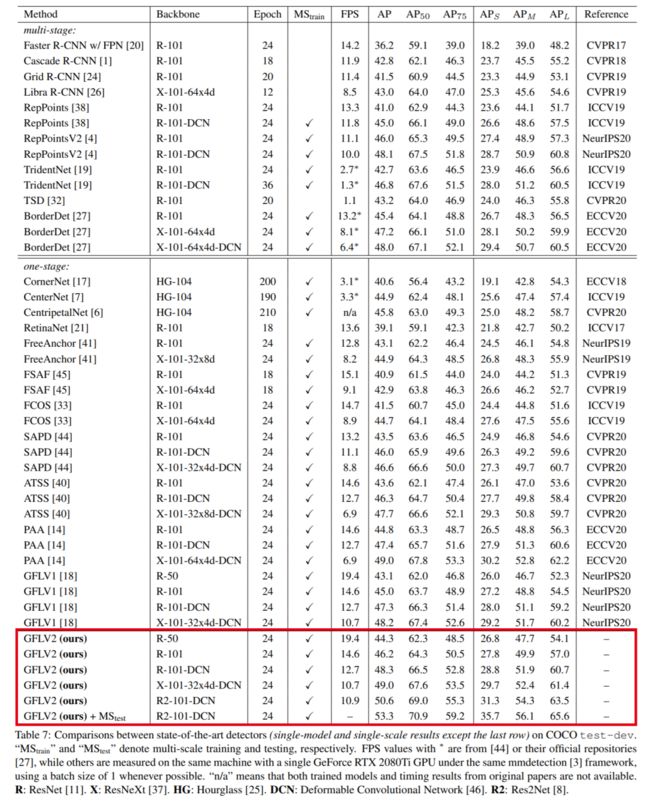
PS:检测发展太快了,一页要放不下了。。。另外Res2Net Backbone是真的牛,相比ResNeXt是又快又好~
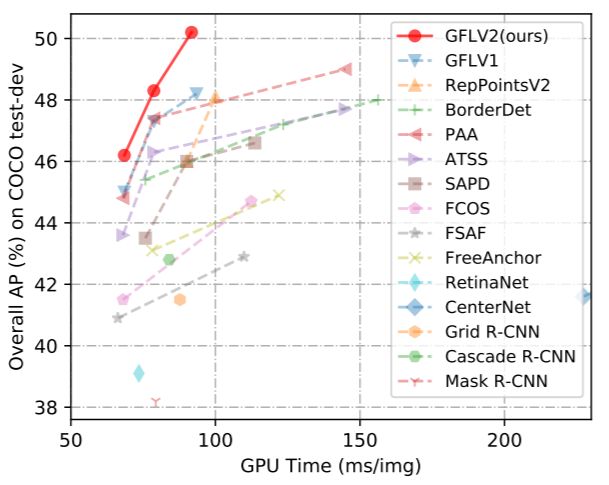
速度性能的trade-off:
最后,我们还可视化了一下GFLV2是如何利用好更好的定位质量估计来保障更精准的结果的(我们给出了NMS前后的所有框,并列出了NMS score排前4的框和它们的分数):
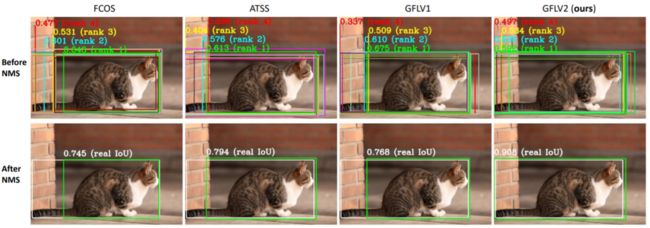
大家可以看到,其他算法里面也有非常准的预测框,但是它们的score通常都排到了第3第4的位置,而score排第一的框质量都比较欠佳。相反,GFLV2也有预测不太好的框,但是质量较高的框都排的非常靠前,性能就是这么的给提上来啦~
最后,这两天NanoDet突然爆火,4天1.2k star,里面分类和回归分支的核心技术即采用了GFLV1的方案,在性能一致的情况下速度是最新的ScaledYOLOv4中的YOLOV4-tiny的2倍,欢迎大家协同关注哟!
也比较期待GFLV2是否也能够在NanoDet上继续无cost提升~~
上述论文和代码下载
后台回复:GFLV2,即可下载上述论文PDF和项目源代码
后台回复:CVPR2021,即可下载CVPR 2021论文和开源代码合集
点击下方卡片并关注,了解CV最新动态
重磅!CVer-论文写作与投稿交流群成立
扫码添加CVer助手,可申请加入CVer-论文写作与投稿 微信交流群,目前已满2400+人,旨在交流顶会(CVPR/ICCV/ECCV/NIPS/ICML/ICLR/AAAI等)、顶刊(IJCV/TPAMI/TIP等)、SCI、EI、中文核心等写作与投稿事宜。
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如论文写作+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加小助手微信,进交流群
▲点击上方卡片,关注CVer公众号
整理不易,请给CVer点赞和在看!