【深度学习】超越ConvNeXt!Transformer 风格的卷积网络视觉基线模型Conv2Former
作者丨科技猛兽
编辑丨极市平台
导读
本文提出一种卷积调制模块,利用卷积来建立关系,这比注意力机制在处理高分辨率图像时更高效,称为 Conv2Former。作者在 ImageNet 分类、目标检测和语义分割方面的实验也表明,Conv2Former 比以前基于 CNN 的模型和大多数基于 Transformer 的模型表现得更好。
本文目录
1 Conv2Former:Transformer 风格的卷积网络视觉基线模型
(来自南开大学,字节跳动)
1.1 Conv2Former 论文解读
1.1.1 背景和动机
1.1.2 卷积调制模块
1.1.3 Conv2Former 整体架构
1.1.4 实验结果
1 Conv2Former:Transformer 风格的卷积网络视觉基线模型
论文名称:Conv2Former: A Simple Transformer-Style ConvNet for Visual Recognition
论文地址:https://arxiv.org/pdf/2211.11943.pdf
1.1.1 背景和动机
以 VGGNet、Inception 系列和 ResNet 系列为代表的 2010-2020 年代的卷积神经网络 (ConvNets) 在多种视觉任务中取得了巨大的进展,它们的共同特点是顺序堆叠多个基本模块 (Basic Building Block),并采用金字塔结构 (pyramid network architecture),但是却忽略了显式建模全局上下文信息的重要性。SENet 模块系列模型突破了传统的 CNN 设计思路,将注意力机制引入到 CNN 中以捕获远程依赖,获得了更好的性能。
自从 2020 年以来,视觉 Transformer (ViTs) 进一步促进了视觉识别模型的发展,在 ImageNet 图像分类和下游任务上表现出比最先进的 ConvNets 更好的结果。这是因为与只进行局部建模的卷积操作相比,Transformer 中的自注意力机制能够对全局的成对依赖进行建模,提供了一种更有效的空间信息编码方法。然而,在处理高分辨率图像时,自注意力机制导致的计算成本是相当大的。
为了解决这个问题,一些 2022 年经典的工作试图回答:如何借助卷积操作,打造具有 Transformer 风格的卷积网络视觉基线模型?
比如 ConvNeXt[1]:将标准 ResNet 架构现代化,并使用与 Transformer 相似的设计和训练策略,ConvNeXt 可以比一些 Transformer 表现得更好。
从原理和代码详解FAIR去年的惊艳之作:全新的纯卷积模型ConvNeXt
再比如 HorNet[2]:通过建模高阶的相互作用,使得纯卷积模型可以做到像 Transformer 一样的二阶甚至更高的相互作用。
精度超越ConvNeXt的新CNN!HorNet:通过递归门控卷积实现高效高阶的空间信息交互
再比如 RepLKNet[3],SLaK[4]:通过 31×31 或者 51×51 的超大 Kernel 的卷积,使得纯卷积模型可以建模更远的距离。
又对ConvNets下手了!详解SLaK:从稀疏性的角度将卷积核扩展到 51×51
到目前为止,如何更有效地利用卷积来构建强大的 ConvNet 体系结构仍然是一个热门的研究课题。
1.1.2 卷积调制模块
本文的关键就是本小节介绍的卷积调制模块。如下图1所示, 对于传统的 Self-attention, 给定一个序列长度为 的输入 , 自注意力模块首先通过线性层得到 key , query , 和 value , 其中 是通道数。 和 是输入的空间大小。输出是注意力矩阵 (本质是相似度得分矩阵) :

式中, 度量每一对输入令牌之间的关系,可以写成:

为了简单起见,这里省略了 scale factor,自注意模块的计算复杂度随着序列长度N的增加呈二次增长,带来了更高的计算代价。
在卷积调制模块中, 不通过2式计算相似度得分矩阵 。具体来说, 给定输入 , 作者使用一个大小为 的 Depth-wise 卷积 和 Hadamard 积计算输出:
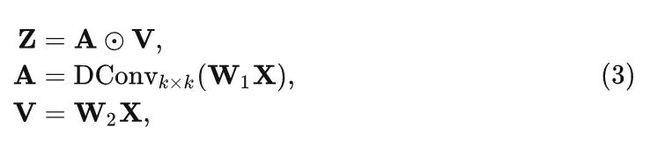
式中, 是 Hadamard 积, 是两个线性层的参数。上述卷积调制操作使每个空间位置 与以 为中心的 平方区域内的所有像素相关, 通道之间的信息交互可通过线性层实现。每个空间位置的输出是正方形区域内所有像素的加权和。
优势: 卷积调制模块利用卷积来建立关系,这比注意力机制在处理高分辨率图像时更高效。
 图1:卷积调制模块示意图
图1:卷积调制模块示意图
ConvNeXt 表明,将 ConvNets 的核大小从3扩大到7可以提高分类性能。然而,进一步增加 Kernel 的大小几乎不会带来性能上的提升,反而会在没有重新参数化的情况下增加计算负担。但作者认为,使 ConvNeXt 从大于 7×7的 Kernel Size 中获益很少的原因是使用空间卷积的方式。对于 Conv2Former,当 Kernel Size 从 5×5 增加到 21×21 时,可以观察到一致的性能提升。这种现象不仅发生在 Conv2Former-T (82.8→83.4) 上,也发生在参数为80M+ 的 Conv2Former-B (84.1→84.5) 上。考虑到模型效率,默认的 Kernel Size 大小可以设置为 11×11。
 图2:几种模块的空间编码过程比较
图2:几种模块的空间编码过程比较
权重策略的优化: 注意这里作者直接将深度卷积的输出作为权重,对线性投影后的特征进行调制。Hadamard 积之前既没有使用激活层,也没有使用归一化层 (例如 Sigmoid 或 LN 层),如果像 SE 模块那样加一个 Sigmoid 函数,会使性能降低 0.5% 以上。
1.1.3 Conv2Former 整体架构
如下图3所示,与ConvNeXt 和 Swin Transformer 相似,作者的 Conv2Former 也采用了金字塔架构。总共有4个 Stage,每个 Stage 的特征分辨率依次递减。根据模型大小尺寸,一共设计了5个变体:Conv2Former-N,Conv2Former-T, Conv2Former-S, Conv2Former-B,Conv2Former-L。
 图3:Conv2Former 整体架构
图3:Conv2Former 整体架构
当可学习参数数量固定时,如何安排网络的宽度和深度对模型性能有影响。原始的 ResNet-50 将每个 Stage 的块数设置为 (3,4,6,3)。ConvNeXt-T 按照 Swin-T 的模式将 Block 数之比更改为 (3,3,9,3),并对较大的模型将 Block 数之比更改为 (1,1,9,1)。Conv2Former 的设置如下图4所示。可以观察到,对于一个小模型 (参数小于30M),更深的网络表现更好。
 图4:Conv2Former 的架构配置
图4:Conv2Former 的架构配置
1.1.4 实验结果
ImageNet-1K 实验分为两种,一种是直接在 ImageNet-1K 上面训练和验证,另一种是先在 ImageNet-22K 上预训练,再在 ImageNet-1K 上微调和验证。
ImageNet-1K 实验设置
数据集:ImageNet-1K 训练 300 Epochs,ImageNet-1K 验证。
优化器: AdamW, lr batch_size :1024, , weight decay 为 , 数据增强: MixUp, CutMix, Stochastic Depth, Random Erasing, Label Smoothing, RandAug。
ImageNet-22K 实验设置
数据集:ImageNet-22K 预训练 90 Epochs,ImageNet-1K 微调 30 Epochs,ImageNet-1K 验证。
如下图5所示是 ImageNet-1K 实验结果。对于小型模型 (< 30M),与 ConvNeXt-T 和 Swin-T 相比,Conv2Former 分别有 1.1% 和 1.7% 的性能提升。即使 Conv2Former-N 只有 15M 参数和 2.2G FLOPs,其性能也与具有 28M 参数和 4.5G FLOPs 的 SwinT-T 相同。对于其他流行的模型,Conv2Former 也比类似模型尺寸的模型表现更好。Conv2Former-B 甚至比 EfficientNetB7 表现得更好 (84.4% vs . 84.3%),后者的计算量是 Conv2Former 的两倍 (37G vs. 15G)。
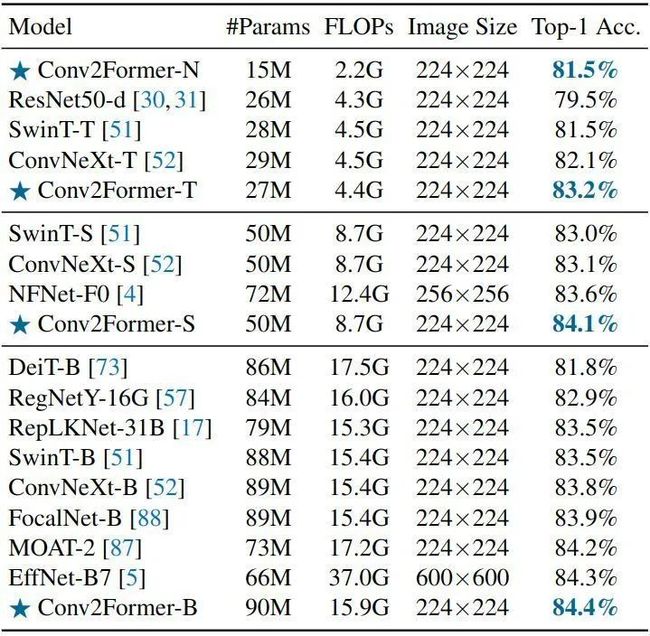 图5:ImageNet-1K 实验结果
图5:ImageNet-1K 实验结果
如下图6所示是 ImageNet-22K 的实验结果。作者遵循 ConvNeXt 中使用的设置来训练和微调模型。与 ConvNeXt 的不同变体相比,当模型尺寸相似时,Conv2Former 都表现得更好。此外,我们可以看到,当在更大的分辨率384×384 上进行微调时,Conv2Former-L 获得了比混合模型 (如 CoAtNet 和 MOAT) 更好的结果,Conv2Former-L 达到了 87.7% 的最佳结果。
 图6:ImageNet-22K 实验结果
图6:ImageNet-22K 实验结果
如下图8所示是关于卷积核大小的消融实验结果。在 大小增加到 21 × 21 之前,性能增益似乎已经饱和。这个结果与 ConvNeXt 得出的结论截然不同,ConvNeXt 得出的结论是,使用大于 7×7 的 Kernel 不会带来明显的性能提升。
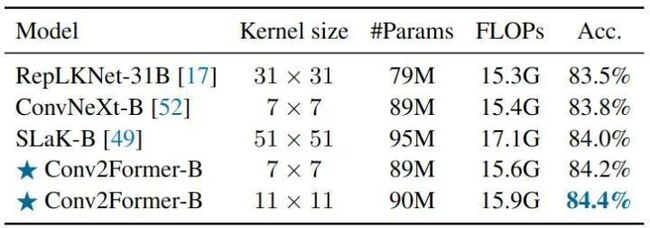 图7:onv2Former 对于大卷积核的泛化效果很好
图7:onv2Former 对于大卷积核的泛化效果很好
消融实验1:卷积核大小
如下图8所示是关于卷积核大小的消融实验结果。在 Kernel Size 增加到 21 × 21 之前,性能增益已经饱和。这个结果与 ConvNeXt 得出的结论截然不同,ConvNeXt 得出的结论是,使用大于 7×7 的 Kernel Size 不会带来明显的性能提升。这表明 Conv2Former 的做法能比传统方式更有效地利用大 Kernel 的优势。
 图8:卷积核大小,融合策略的消融实验结果
图8:卷积核大小,融合策略的消融实验结果
消融实验2:不同融合策略的影响
如下图8, 9所示是关于不同融合策略影响的消融实验结果。除了上述两种融合策略外, 作者还尝试使用其他方法来融合特征映射, 包括在 之后添加一个 Sigmoid 函数, 对 进行 归一化 处理, 将 的值线性归一化到(0,1]。可以看到, Hardmard 积比其他操作的结果更好。作者发现, 无论是通过 Sigmoid 函数, 还是通过线性的归一化操作, 将 线性化到 之间, 都会对性能有损害。
直筒架构实验结果
遵循 ConvNeXt 的做法,作者也训练了 Conv2Former 的直筒架构 (Isotropic Models) 版本,结果如下图9所示。作者将 Conv2Former-IS 和 Conv2Former-IB 的块数设置为18,并调整通道数以匹配模型大小。字母 "I" 表示直筒架构,可以看到,对于 22M 参数左右的小型模型,Conv2Former-IS 比 DeiT-S 的表现要好得多。当将模型尺寸放大到 80M+ 时,Conv2Former-IB 达到了 82.7% 的 Top-1 Accuracy,这也比 ConvNeXt-IB 高 0.7%,比 DeiT-B 高0.9%。
 图9:直筒架构实验结果
图9:直筒架构实验结果
目标检测实验结果
如下图10所示是不同骨干网络,以 Mask R-CNN 为检测头和 Cascade Mask R-CNN 为实例分割头在 COCO 数据集的实验结果。训练策略遵循 ConvNeXt。对于小模型,使用 Mask R-CNN 框架时,Conv2Former-T 比 SwinT-T 和 ConvNeXt-T 获得了约 2% AP 的改进。
 图10:目标检测实验结果
图10:目标检测实验结果
语义分割实验结果
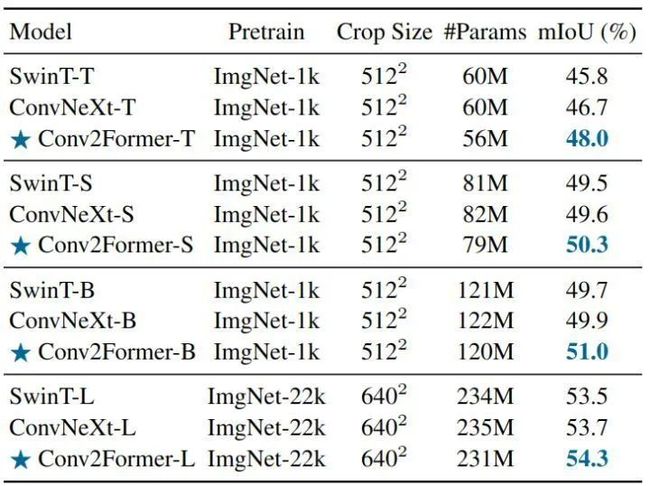
如下图11所示是不同骨干网络,以 UperNet 为分割头在 ADE20k 上的实验结果。对于不同尺度的模型,我们的Conv2Former可以优于Swin Transformer和ConvNeXt。
总结
本文试图回答:如何借助卷积操作,打造具有 Transformer 风格的卷积网络视觉基线模型。本文提出一种卷积调制模块,利用卷积来建立关系,这比注意力机制在处理高分辨率图像时更高效。最终的模型称为 Conv2Former,它通过只使用卷积和 Hadamard 积,简化了注意力机制。卷积调制操作是一种利用大核卷积的更有效的方法。作者在 ImageNet 分类、目标检测和语义分割方面的实验也表明,Conv2Former 比以前基于 CNN 的模型和大多数基于 Transformer 的模型表现得更好。
参考
^A ConvNet for the 2020s
^HorNet: Efficient High-Order Spatial Interactions with Recursive Gated Convolutions
^Scaling Up Your Kernels to 31x31: Revisiting Large Kernel Design in CNNs
^More ConvNets in the 2020s: Scaling up Kernels Beyond 51 × 51 using Sparsity

往期精彩回顾
适合初学者入门人工智能的路线及资料下载(图文+视频)机器学习入门系列下载机器学习及深度学习笔记等资料打印《统计学习方法》的代码复现专辑机器学习交流qq群955171419,加入微信群请扫码