A Novel Lip Descriptor for Audio-Visual Keyword Spotting Based on Adaptive Decision Fusion(2016)
摘要
当应用于噪声剧烈变化的现实环境时,关键词识别仍然是一个挑战。在最近的研究中,由于视觉语音不受噪声的影响,视听一体化方法已显示出优越性。
然而,在视觉语音识别中,个体的话语习惯会导致混淆和错误识别。为了解决这一问题,本文提出了一种新的唇部描述符,该描述符同时包含基于几何的特征和基于外观的特征。
基于几何的特征:一组基于几何图形的特征提出了一种基于先进的面部地标定位方法。
基于外观的特征:为了获得鲁棒性和区分性的表示,提出了一种考虑话语(文本)间相似性的时空嘴唇特征,并将该特征映射到类内子空间。
此外,为了充分利用视听语音,适应不同的噪声环境,提出了一种基于决策融合的并行两步关键词识别策略。使用神经网络生成的权重结合了声音和视觉。
在OuluVS数据集和PKU-AV数据集上的实验结果表明,与现有技术相比,所提出的唇形描述符具有竞争力的性能。此外,本文提出的基于决策级融合的视听关键词识别(AV-KWS)方法显著提高了噪声鲁棒性,具有优于特征级融合的性能,特征级融合也能够适应各种噪声条件。
研究内容
对于KWS,有三种典型的方法:基于HMM填充的KWS、基于音素格的KWS和基于LVCSR(大词汇量连续语音识别)的KWS[7]。最常见的KWS方法是基于LVCSR的KWS,它使用LVCSR系统生成单词格,然后在格中搜索关键字。
事实上,人类语言产生和感知的内在机制是双峰的[11]。当我们与他人交流时,我们不仅“听”,而且“看”。此外,视觉信息不受声环境的影响。
AV-ASR基本示意图
图1显示了AV-ASR的基本示意图,包括声学特征提取、视觉前端设计和视听融合。视觉前端设计包括人脸检测、嘴唇定位和视觉特征提取。 嘴唇区域定位->面部地标估计

Fig. 1. 一个AV-ASR系统的主要模块
AV-KWS基本示意图
图2显示了我们的AV-KWS系统的总体示意图。虽然对AV-ASR进行了广泛的研究,但很少有研究涉及视听关键词识别(AV-KWS)。本文提出了一种基于决策融合的AV-KWS策略,该策略使用了一种新的唇形描述符。

Fig. 2. AV-KWS系统显示平行定位策略
提出的方法&模型架构
视觉特征提取 (新的唇形描述符)
首先,基于几何的特征:采用一种先进的人脸标志点定位方法来促进视觉特征提取过程,这对于VSR(视觉语音识别)中的视觉特征提取至关重要。其次,提出了形状差异特征来表示唇形的几何信息。
最后,基于外观的特征:引入时空唇形特征来捕捉嘴唇运动的纹理和动态,在说话过程中涉及以下两个方面:
- 包含个人身份信息的个体变量导致较大的类内方差,这些变量与VSR无关,并且需要抑制;
2) 说话过程中包括嘴唇区域的纹理、形状和动态变化等话语(文本)变量,是区分不同话语的关键资源。
基于几何的特征
唇区裁剪
人脸标志点定位识别人脸图像上的基准点,这对于人脸识别和人脸动画等任务至关重要。
在AV-ASR中,主动外观模型(AAM)作为一种经典的人脸标志点定位方法,通常用于传统的视觉前端。
在此基础上,本文采用了一种人脸形状或语义人脸标志点的方法进行唇形区域裁剪,代替传统的AAM。
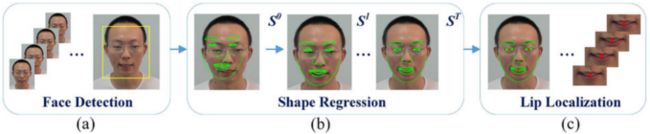
Fig. 3. 唇区裁剪流程。(a)输入话语视频,然后进行粗人脸检测。(b)以从粗到细的方式快速进行形状回归。(c)人脸对齐和裁剪的唇部区域。
假设一个人脸形状S = [ x1 , y1 , . . . , xN , yN ]T由N个人脸标志点组成。给定人脸图像,人脸标志点检测的目标是最小化 ||S− Sˆ||,真实形状:Sˆ。基本的形状回归框架如下。
首先,使用增强回归[32]以相加方式组合T个弱回归变量(R1 ,...,Rt ,...,RT )。给定人脸图像I和初始人脸形状S0,每个回归器根据图像特征计算形状增量ΔS,然后更新人脸形状,其公式如下:
![]()
给定N个训练样本![]() ,回归器按顺序学习,直到训练误差不再减小。每个回归器Rt学习如下:
,回归器按顺序学习,直到训练误差不再减小。每个回归器Rt学习如下:
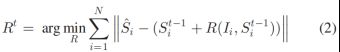
其中Sit−1是前一阶段的估计形状。在回归预处理中,检测到粗糙的人脸框,然后以从粗到细的方式估计标志点,如图3(b)所示。
接着,可以检测眼睛和嘴巴的几何中心。因此,在使用整个序列的预定义比率参数对面部进行归一化后,嘴唇区域根据嘴中心进行裁剪,如图3(c)所示。
形状差异特征(SDF)
由于形状回归模型的有效性,可以准确地检测到唇部标志点,因此需要基于几何的特征来精确地表示形状,例如唇部宽度、高度和轮廓。为了充分利用衍生出的标志点,提出了形状差异特征(SDF)。

Fig. 4. 四种形状表示:(a)嘴唇宽度和高度,(b)垂直方向上的形状信息,(c)外唇轮廓,和(d)内唇轮廓。
给定M个唇部标志点,通过计算两个标志点之间的欧氏距离,开发了四种类型的表示法来全面描述唇部形状,如图4所示:
- 唇部宽度和高度形成一个表示为d1的向量;
- 对应标志点之间的所有垂直距离形成向量d2;
- 外唇轮廓由向量d3表示,包括外圈标志点和嘴中心之间的距离;
- 内唇轮廓由向量d4表示,包括内环标志点和嘴中心之间的距离。
将dt=[d1T,d2T,d3T,d4T]T表示为第t帧的特征向量。考虑到个体嘴唇外观差异的干扰,最终形状差异特征向量d计算如下:
![]()
其中,T是话语视频的帧数,| · |表示取d t+1 − d t的每个元素的绝对值。
基于外观的特征
时空唇形特征(STLF)
不同的说话者说出同一词的嘴巴外观是不同的,这导致了很大的类内差异。
为了在检测到的唇形区域中获得纹理和动态变化的鲁棒表示,并缩小类内距离,提出了一种时空唇形特征(STLF),包括以下步骤:
- 在一段话语视频中,将每个裁剪的嘴唇区域分割成K个块,并把相应的块放在一起,形成K个体积;
- 从采样块中提取低层(low-level)特征;
- 采用局部约束线性编码(LLC)[33]将低层特征编码为高层特征,实现提出的混合池化;
- 采用白化主成分分析(WPCA)缩小类内差异。
整个过程如图5所示。
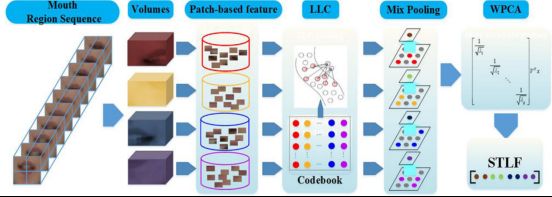
Fig. 5. 获得时空唇部特征的过程。
基于决策融合的并行两步kws策略
自适应视听集成
对于AV-KWS,在各种噪声条件下,声音和视觉信息的贡献不同。因此,如何融合声音和视觉信息的决定对最终的性能有很大的影响。
一般来说,有两大类融合:特征级融合和决策级融合[14]。
特征级融合直接以一种简单的方式将两种模式的特征直接连接到一个更大的特征向量中,或者采用一些适当的变换。然后使用基于级联特征向量的单个分类器进行识别,如图6(a)所示。
决策级融合,音频和视频模式在分类器输出后集成,如图6(b)所示。具体来说,决策融合可分为三类,即“早期”集成(多流HMM)、“中间”集成和“后期”集成。这三个类别分别对应于国家级、词汇级和话语级的分类。
与特征级融合相比,决策级融合方法在处理不同噪声条件方面具有重要优势[11],[14]。特征级融合将声学特征和视觉特征连接成更大的特征向量,具有更高的维数,因此需要更多的训练数据来确保足够的概率建模。与特征级融合相比,决策级融合可以明确地对两种模式的可靠性进行建模,这一点非常重要,因为两种模式的识别能力可能存在很大差异。
根据不同的噪声条件,积分权重相对容易生成。这有助于使用决策级融合控制两种模式的贡献,独立处理这两种模式。
Fig. 6.特征级融合和决策级融合的框架。(a)特征级融合。(b)决策级融合。

Fig. 7. Log-likelihoods of HMMs under different noisy conditions.
本文采用了决策融合的后期集成,以应对不同的噪声条件,并开发出具有噪声鲁棒性的AV-KWS系统。
此外,还使用了基于HMM的传统AV-KWS,其中分别训练声学HMM和视觉HMM,以提供给定多媒体源的相应模态似然度。
本文采用与最大对数似然[42]的最佳假设的平均差作为可靠性度量:
![]()
从整体角度来看,(16)中与最大对数似然(Diffmax)的平均差异在不同噪声条件下具有最佳识别性能[14]。刘易斯和鲍尔斯指出,在测量可靠性时,其他分散形式的固有误差导致其低于Diffmax[44] 。因此,本文采用了平均差对最大对数似然的可靠性度量。
然后利用神经网络将两个输入可靠性映射到最佳权重。对于具有开始和结束时间的关键词候选,可以有效地获得每个模态(DA和DV)的相应可靠性。对于给定的一对声学、视觉可靠性(DA,DV),积分权重γ可通过神经网络建模的函数f计算,如下所示:
![]()
为了获得不同条件下的自适应权值,利用不同SNR的声学语音和不同图像分辨率的视觉语音训练神经网络。经过训练的神经网络可以针对不同的条件(不限于用于训练的条件)生成关键字候选的最佳权重。
精确的训练过程如下。1) 计算给定标记关键字的DA和DV(话语中的关键字是人工标记的)。2) 在[0,1]的空间内以0.01的步长彻底搜索最佳权重,并检查使用特定权重值的识别结果是否正确。3) 使用输入可靠性和相应的最优权重训练神经网络。
两步关键词识别策略
为了使用自适应权重确定视觉模态对KWS的益处,采用了传统的基于HMM填充的KWS。该方法主要用于对话系统、指挥控制和信息咨询等应用领域。更具体地说,我们的KWS系统采用了传统的两阶段策略:在第一阶段选择可能的关键字候选,以包括嵌入在无约束语音中的真实关键字,并在第二阶段拒绝假警报。由于声学识别性能在噪声条件下显著下降,因此放弃了仅对声学候选对象执行视觉重新评分的策略。或者,引入并行两步识别,以互补地充分利用两种模式,如图2所示。
第一步:利用经过训练的声学和视觉关键词HMMs以及填充模型,首先对测试语音并行进行声学和视觉关键词搜索,生成若干声学关键词候选和视觉关键词候选,并具有相应的日志概率。
步骤2:对于由任一模态获得的具有开始和结束时间的关键词候选,然后基于该关键词的另一模态执行重新评分,因为声学关键词候选可能与视觉关键词不相同,尤其是当声学环境太嘈杂时。因此,每个候选人都会收到一个声学和视觉日志。
训练后的神经网络以声可靠度DA和视觉可靠度DV为输入因子,计算出相应的声可靠度DA和视觉可靠度DV,并输出最优权重。接下来,使用(15)中的估计权重,通过线性组合声学和视觉日志可能性,可以获得关键词候选的综合得分。最后,根据每个关键词候选词的综合得分实现拒绝,以消除假警报。考虑到背景噪声,使用基于似然比[45](或对数似然差)的抑制,表示为Lr,因为其对噪声的鲁棒性,如下所示:
![]()
其中logp(OAV |λi)是关键字模型λi的综合对数似然,logp(OAV | Filler)是填充模型的综合对数似然。类似地,对数p(OAV | Filler)可以基于Filler模型通过线性组合相应的声学和视觉对数可能性来计算。当候选词的对数似然比大于阈值时,该候选词被视为真关键字,否则将被视为假警报并被拒绝。
通常,识别结果分析是通过在关键字验证后将其与人工标记的参考进行比较来执行的。如图8所示,在拒绝步骤(图8中的情况(2))中,一些声学和视觉关键词候选被作为假警报直接移除。对于拒绝后剩余的候选词,应采取额外的步骤,因为声学和视觉关键词候选词可能会在时间上重叠。因此,需要一个标准来处理这种情况。对于每个具有相应时间区域和综合对数似然性的声学和视觉关键词候选,如果一个模态关键词候选的中间时间点落在另一个模态关键词候选的时间区域内,则将其视为重叠实例。因此,具有更大综合对数似然性的候选被确定为真关键字,而另一个被视为假警报(图8中的情况(1))。对于其他情况(声音和视觉关键词候选词在时间上不重叠),直接确定候选词为真实关键词(图中的情况(3)、(4))。8).
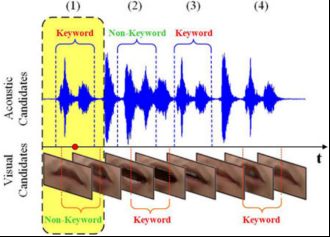
Fig. 8. Additional step to deal with the overlapping acoustic and visual candidates.

文章贡献
- 在视觉语音识别中,提出了一种新的唇形描述符,该描述符表示鲁棒且有区别的形状和纹理信息,旨在抑制较大的类内方差。
基于几何的特征:最先进的人脸标志点定位方法,并基于识别的标志点提出了一组基于几何的特征。
基于外观的特征:提出了一种时空唇部特征,该特征表示与唇部相似性有关的纹理变化。
2) 为了自适应地处理不同的噪声条件,并将音频语音和视频语音互补地结合起来,提出了一种基于决策融合的并行两步KWS策略。此外,使用神经网络生成的权重结合了声音和视觉贡献。
数据集
结果
- 视觉语音识别
实验1:为了评估STLF。
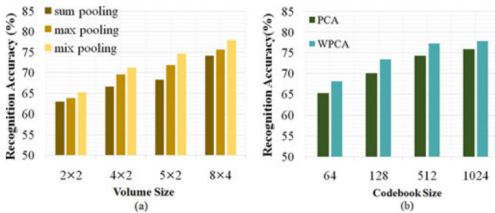
Fig. 9. (a) Comparisons of STLF on OuluVS with different segmentations and pooling strategies with codebook size M = 512 using WPCA. (b) Comparisons of STLF with different codebook sizes and dimension reduction methods in segmentation 8 × 4 using mixpooling.
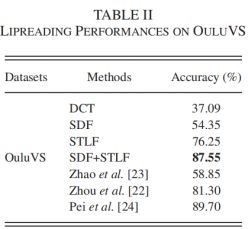
实验2:为了探索SDF、STLF及其组合的性能,将它们与[22]–[24]中提出的最先进的唇读方法进行了比较。
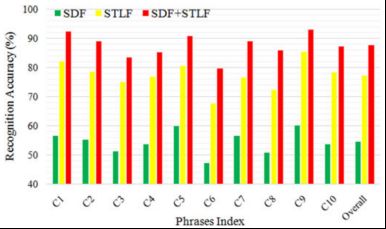
Fig. 10. Phrases recognition comparison of different features in the speaker-independent way on the OuluVS database.
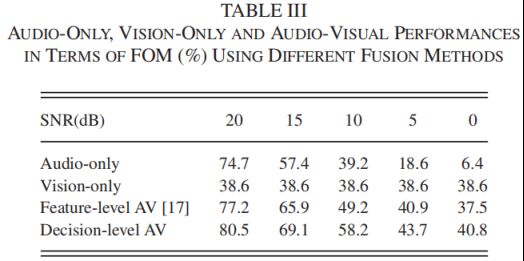
- PKU-AV上的视听关键字识别
实验3:通过HMM对SDF、STLF及其组合在PKU-AV上的性能进行了测试,对DCT、STLF及其与SDF的组合,参数设置与实验2相同。
实验4:在本实验中,视觉部分和音频部分根据决策水平进行整合。

Fig. 11. Exemplar video frames in PKU-AV.

Fig. 12. FOM performances of different visual features for keyword spotting.
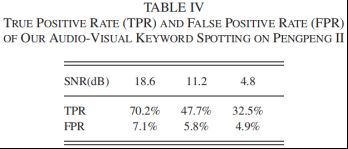
实验5:接下来,在数据库(白噪声破坏的声学语音和原始视觉语音)上,比较了基于自适应权重(使用“SDF+STLF”作为视觉特征)的决策级融合AV-KWS性能和[17]中提出的基于特征的视听关键词发现器的性能。
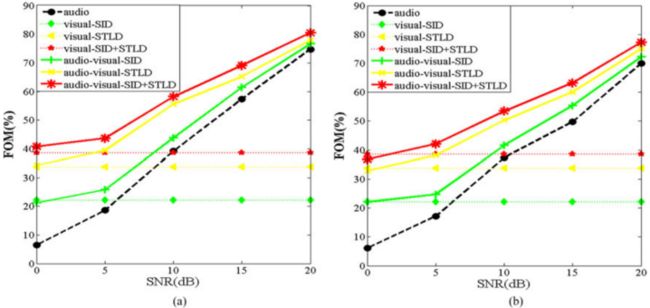
Fig. 13. Recognition performances of the audio-only, vision-only, and audio-visual KWS system under white noise and babble noise conditions. (a) Performance of white noise condition using SDF, STLF, and their combination. (b) Performance of babble noise condition using SDF and STLF their combination. (a) White–noise. (b) Babble noise.
实验6:在友好的面对面HRI中,应该允许相对自由的运动,这可能会导致AV-KWS的不同脸型。

Fig. 14. FOM performances of different image resolutions.
- 真实环境中的HRI
-

Fig. 15. HRI-oriented mobile robot Pengpeng II.
总结
为了在各种噪声条件下获得更鲁棒的HRI,本文利用新的视觉特征开发了一种视听关键词检测器。
最先进的人脸标志点定位方法用于精确裁剪和对齐唇形区域。为了充分利用检测到的标志点,设计了一个几何特征SDF作为补充特征。
提出的STLF考虑了唇话语(文本)的相似性,并致力于减少类内差异。
为了在各种条件下充分利用这两种模式,还进行了基于声学和视觉模式的并行两步识别。
实验结果验证了所提特征及其组合的有效性。此外,这种基于决策层的音频-视频融合提高了关键字检测器的噪声鲁棒性。这名视听关键词观察员处理未经训练的噪声条件的能力,包括不同的噪声水平和噪声类型,得到了有力的证实。