13种主流机器学习的框架

1. Apache Spark MLlib
Apache Spark 最为人所知的是它是Hadoop家族的一员,但是这个内存数据处理框架却是脱胎于Hadoop之外,也正在Hadoop生态系统以外为自己获得了名声。Hadoop 已经成为可供使用的机器学习工具,这得益于其不断增长的算法库,这些算法可以高速度应用于内存中的数据。
早期版本的Spark 增强了对MLib的支持,MLib是主要面向数学和统计用户的平台,它允许 通过持久化管道特性将Spark机器学习工作挂起和恢复。2016年发布的Spark2.0,对Tungsten高速内存管理系统和新的DataFrames流媒体API 进行了改进,这两点都会提升机器学习应用的性能。

2. H2O
H2O,现在已经发展到第三版,可以提供通过普通开发环境(Python, Java, Scala, R)、大数据系统(Hadoop, Spark)以及数据源(HDFS, S3, SQL, NoSQL)访问机器学习算法的途径。H2O是用于数据收集、模型构建以及服务预测的端对端解决方案。例如,可以将模型导出为Java代码,这样就可以在很多平台和环境中进行预测。
H2O可以作为原生Python库,或者是通过Jupyter Notebook, 或者是 R Studio中的R 语言来工作。这个平台也包含一个开源的、基于web的、在H2O中称为Flow的环境,它支持在训练过程中与数据集进行交互,而不只是在训练前或者训练后。

3. Apache Singa
“深度学习”框架增强了重任务类型机器学习的功能,如自然语言处理和图像识别。Singa是一个Apache的孵化器项目,也是一个开源框架,作用是使在大规模数据集上训练深度学习模型变得更简单。
Singa提供了一个简单的编程模型,用于在机器群集上训练深度学习网络,它支持很多普通类型的训练工作:卷积神经网络,受限玻尔兹曼机 以及循环神经网络。 模型可以同步训练(一个接一个)或者也异步(一起)训练,也可以允许在在CPU和GPU群集上,很快也会支持FPGA。Singa也通过Apache Zookeeper简化了群集的设置。

3. Caffe2
深度学习框架Caffe开发时秉承的理念是“表达、速度和模块化”,最初是源于2013年的机器视觉项目,此后,Caffe还得到扩展吸收了其他的应用,如语音和多媒体。
因为速度放在优先位置 ,所以Caffe完全用C+ +实现,并且支持CUDA加速,而且根据需要可以在CPU和GPU处理间进行切换。分发内容包括免费的用于普通分类任务的开源参考模型,以及其他由Caffe用户社区创造和分享的模型。
一个新的由Facebook 支持的Caffe迭代版本称为Caffe2,现在正在开发过程中,即将进行1.0发布。其目标是为了简化分布式训练和移动部署,提供对于诸如FPGA等新类型硬件的支持,并且利用先进的如16位浮点数训练的特性。

4. Google的TensorFlow
与微软的DMTK很类似,Google TensorFlow 是一个机器学习框架,旨在跨多个节点进行扩展。 就像Google的 Kubernetes一样,它是是为了解决google内部的问题而设计的,google最终还是把它作为开源产品发布出来。
TensorFlow实现了所谓的数据流图,其中的批量数据(“tensors”)可以通过图描述的一系列算法进行处理。系统中数据的移动称为“流”-其名也因此得来。这些图可以通过C++或者Python实现并且可以在CPU和GPU上进行处理。
TensorFlow近来的升级提高了与Python的兼容性,改进了GPU操作,也为TensorFlow能够运行在更多种类的硬件上打开了方便之门,并且扩展了内置的分类和回归工具库。
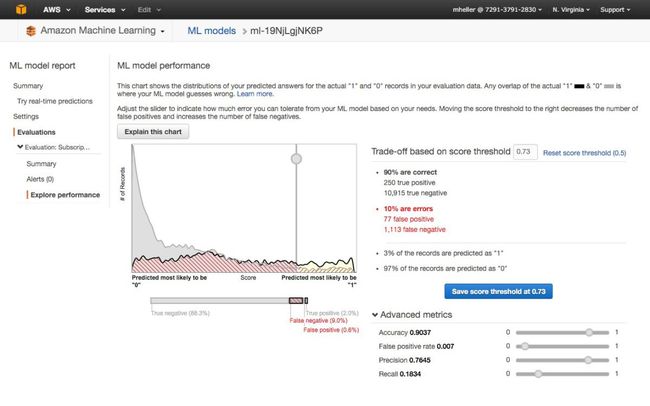
5. 亚马逊的机器学习
亚马逊对云服务的方法遵循一种模式:提供基本的内容,让核心受众关注,让他们在上面构建应用,找出他们真正需要的内容,然后交付给他们。
亚马逊在提供机器学习即服务-亚马逊机器学习方面也是如此。该服务可以连接到存储在亚马逊 S3、Redshift或RDS上的数据,并且在这些数据上运行二进制分类、多级分类或者回归以构建一个模型。但是,值得注意的是生成的模型不能导入或导出,而训练模型的数据集不能超过100GB。
但是,亚马逊机器学习展现了机器学习的实用性,而不只是奢侈品。对于那些想要更进一步,或者与亚马逊云保持不那么紧密联系的人来说,亚马逊的深度学习机器图景包含了许多主要的深度学习框架,包括 Caffe2、CNTK、MXNet和TensorFlow。
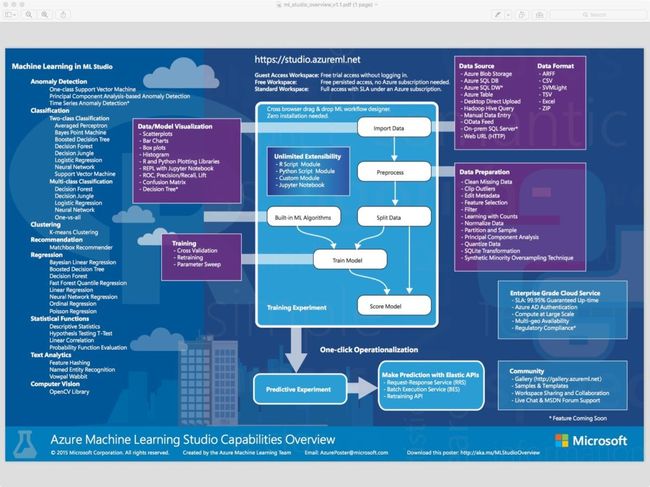
6. 微软的Azure ML Studio
考虑到执行机器学习所需的大量数据和计算能力,对于机器学习应用云是一种理想环境。微软已经为Azure配备了自己的即付即用的机器学习服务-Azure ML Studio,提供了按月、按小时和免费的版本。(该公司的HowOldRobot项目就是利用这个系统创立的。)你甚至不需要一个账户来就可以试用这项服务;你可以匿名登录,免费使用Azure ML Studio最多8小时。
Azure ML Studio允许用户创立和训练模型,然后把这些模型转成被其他服务所使用的API。免费用户的每个账号可以试用多达10GB的模型数据,你也可以连接自己的Azure存储以获得更大的模型。有大范围的算法可供使用,这要感谢微软和第三方。
近来的改进包括通过Azure批处理服务、更好的部署管理控制和详细的web服务使用统计,对训练任务进行了批量管理。

7. 微软的分布式机器学习工具集
在机器学习问题中投入更多的机器,会取得更好的效果-但是开发在大量计算机都能运行良好的机器学习应用却是挺伤脑筋的事。
微软的DMTK(分布式机器学习工具集)框架解决了在系统集群中分布多种机器学习任务的问题。
DMTK被认为是一个框架而不是一个完全成熟、随去随用的解决方案,因此包含算法的数量是很小的。然而,你还是会找到一些关键的机器学习库,例如梯度增强框架(LightGBM),以及对于一些像Torch和Theano这样深度学习框架的支持。
DMTK的设计使用户可以利用有限的资源构建最大的群集。例如,群集中的每个节点都会有本地缓存,从而减少了与中央服务器节点的通信流量,该节点为任务提供参数。
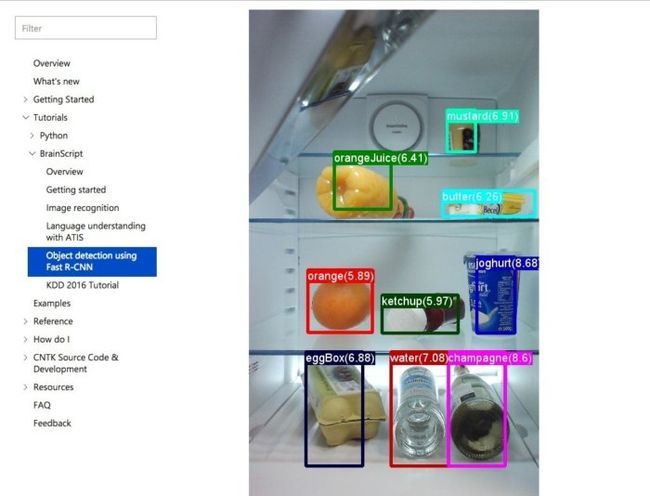
8. 微软的计算网络工具集
在发布DMTK之后,微软又推出了另一款机器学习工具集,即计算网络工具包,简称CNTK。
CNTK与Google TensorFlow类似,它允许用户通过一个有向图来创建神经网络。微软也认为CNTK可以与诸如Caffe、Theano和 Torch这样的项目相媲美,-此外CNTK还能通过利用多CPU和GPU进行并行处理而获得更快的速度。微软声称在Azure上的GPU群集上运行CNTK,可以将为Cortana的语音识别训练速度提高一个数量级。
最新版的CNTK 2.0通过提高精确性提高了TensorFlow的热度,添加了一个Java API,用于Spark兼容性,并支持kera框架(通常用于TensorFlow)的代码。

9. Apache Mahout
在Spark占据主流地位之前很久,Mahout就已经开发出来,用于在Hadoop上进行可扩展机器学习。但经过一段长时间的相对沉默之后,Mahout又重新焕发了活力,例如一个用于数学的新环境,称为Samsara,允许多种算法可以跨越分布式Spark群集上运行。并且支持CPU和GPU运行。
Mahout框架长期以来一直与Hadoop绑定,但它的许多算法也可以在Hadoop之外运行。这对于那些最终迁移到Hadoop的独立应用或者是从Hadoop中剥离出来成为单独的应用都很有用。
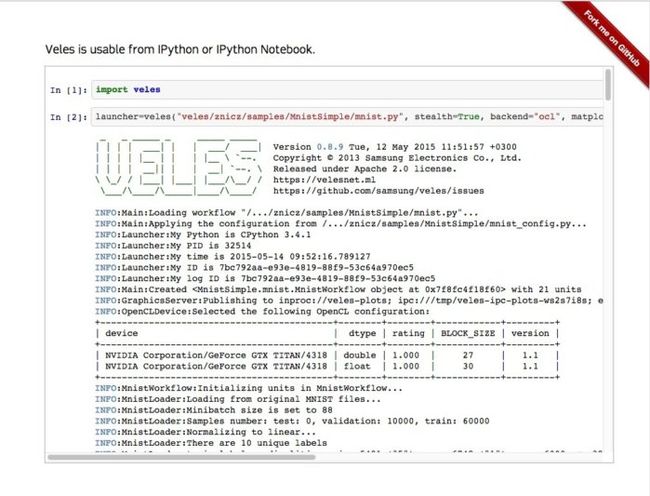
10. Veles (Samsung)
[Veles]https://velesnet.ml/)是一个用于深度学习应用的分布式平台,就像TensorFlow和DMTK一样,它是用C++编写的,尽管它使用Python来执行节点之间的自动化和协调。在被传输进群集之前,要对数据集分析并且进行自动的归一化,然后调用REST API来即刻使用已训练的模型(假定你的硬件满足这项任务的需要)
Veles不仅仅是使用Python作为粘合代码,因为基于Python的Jupyter Notebook 可以用来可视化和发布由一个Veles集群产生的结果。Samsung希望,通过将Veles 开源将会刺激进一步的开发,作为通往Windows和MacOS的途径。
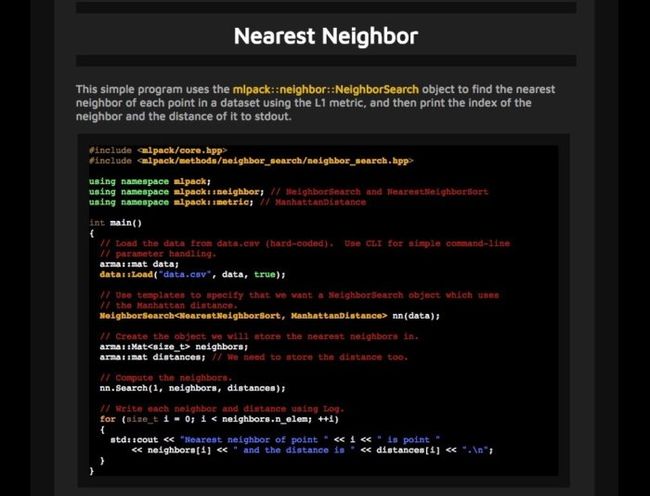
11. mlpack 2
作为一个基于C++的机器学习库,mlpack最初产生于2011年,按照库的创立者想法,设计mlpack是为了“可扩展性,速度和易于使用。”mlpack既可以通过由若干行命令行可执行程序组成的“黑盒”进行操作,也可以利用C++ API来完成复杂的工作。
mlpack的第二版包含了许多新的算法,以及现有算法的重构,以提高它们的速度或使它们瘦身。例如,它舍弃了Boost库的随机数生成器,转而采用C++ 11的原生随机数功能。
mlpack的一个痼疾是缺少对于C++以为语言的支持。这就意味着其他语言的用户需要第三方库的支持,如这样的一个Pyhton库。还有完成了一些工作来增加对MATLAB的支持,但是像mlpack这样的项目,在机器学习的主要环境中直接发挥作用时,往往会获得更大的应用。
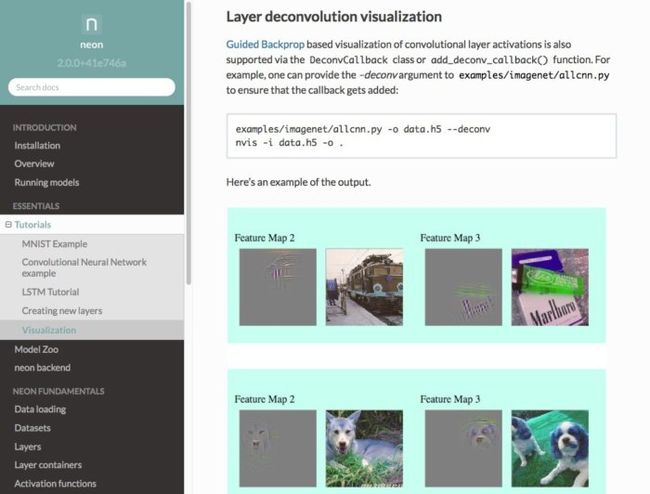
12. Neon
Nervana,一家建立自己的深度学习硬件和软件平台的公司(现在是英特尔的一部分),已经提供了一个名为“Neon”的深度学习的框架,它是一个开源项目。Neon使用可插拔的模块,以实现在CPU、GPU或者Nervana自己开发的芯片上完成繁重的任务。
Neon主要是用Python编写,也有一部分是用C++和汇编以提高速度。这使得该框架可以为使用Python或者其他任何与Python绑定框架进行数据科学工作的人所用。
许多标准的深度学习模型,如LSTM、AlexNet和GoogLeNet,都可以作为Neon的预训练模型。最新版本Neon 2.0,增加了英特尔数学内核库来提高CPU的性能。
13. Marvin
另一个相对近期的产品——Marvin神经网络框架,是普林斯顿视觉集团的产物。Marvin“生来就是被黑的”,正如其创建者在该项目文档中解释的那样,该项目只依赖于一些用C++编写的文件和CUDA GPU框架。虽然该项目的代码很少,但是还是提供了大量的预训练模型,这些模型可以像项目本身代码一样,能够在合适的场合复用或者根据用户的需要共享。