这个深度学习库能执行10多种图像文本任务,有20多个数据集,还统一接口|已开源...
Pine 发自 凹非寺
量子位 | 公众号 QbitAI
支持10余种图像文本任务,囊括20多种数据集,还提供SOTA模型性能和可复现预训练及微调实验配置。
没错,这是一个视觉语言深度学习框架就可以拥有的。
这个库的庐山真面目是:Salesforce亚洲研究院推出的LAVIS。

并且,它还统一了接口,降低开发成本和入门门槛。
最重要的是:已开源!
LAVIS全⽅位⽀持视觉语⾔任务、数据集、模型。
如果还不能看不出它的优势,那话不多说,直接看LAVIS与现有多模态库的对比图。

相较之下,现存的视觉语⾔框架只⽀持较少⼀部分任务和数据集,逊色了不少。
除此之外,LAVIS还附带了丰富的开源资源和⼯具,就比如说它提供了一个图形化的工具,可以可视化数据集的样本,以便于能更好的预览、理解数据。
并且随着LAVIS一起开源的还有GUI demo,它的功能就有这么多。(看图)

具体LAVIS有何过人之处?一起来看看吧~
⼀站式视觉语⾔框架
LAVIS概括下来,可以用三个数字来表示:四、十、二十。
先来说说四,它表示LAVIS支持四种领先的基础视觉语⾔模型架构,包括ALBEF、BLIP、CLIP和ALPRO。
其中ALBEF和CLIP主要支持图像文本任务,ALPRO⽀持视频⽂本任务,BLIP对这两项任务都能够提供⽀持。
也正是有了这些视觉语言模型做基础,LAVIS才能够运行这十余种视觉语言任务。
具体来讲,它可以进行图⽚描述⽣成、图像⽂本检索、视频⽂本检索、图像问答、视频问答、多模态分 类、多模态图像、视频对话、视觉语⾔推理、多模态预训练等实⽤任务。
除此之外,LAVIS还具备多模态特征提取等功能。
讲完模型架构和任务,就还差数据集了,不过这就不必担心,因为LAVIS能够支持二十多种数据集。
想实现各项任务都能够找到合适的数据集进行训练。

不过,这些都还只是LAVIS的开碟小菜,它还“憋了个大招”:
统一接口。
这对初学者和跨领域研究者来说是相当友好了,许多深度学习库的模型、数据集一集任务评估接口都不一致,这就导致学习成本大大提高。
而统一接口之后,就会极⼤简化模型训练评测,并且能够最⼩化重复开发成本。
话说回来,这里的统一接口具体方便了什么呢?
主要分为两部分。
第一部分是用于加载数据集和模型的统一接口,模型及其相关的预处理器也可以通过一个统一的接口来加载,从而便于对自定义数据进行分析和推断。
第二部分是实现多模态特征提取的统一接口,这些特性对于端到端微调的离线应用程序尤其有用。通过更改名称和模式,用户可以选择使用不同的模型架构和预先训练的权重。
这样一来,⽤户便可以利⽤LAVIS提供的load_model(), load_dataset() ,⼀键加载所需模型和数据集。
比如说,加载COCO captioning数据集,只需要输入load_dataset(“coco_caption”);加载BLIP captioning模型只需要输入model=load_model(name=“blip_caption”)。
此外,LAVIS还能实现数据到训练⾼定制化,给予开发者充分空间研究新模型、新多模态能⼒、新引⽤场景。
不过,实现LAVIS这样一站式的视觉语言框架,是怎样做到的呢?
模块化的结构
其实从LAVIS的构造就能够看出,LAVIS深度学习库的整个构造很简洁,用三个字就可以概括:模块化。
在整个库中,将关键组件模块化后再进行组织。
这样一来,就可以对单个组件的现成访问、快速开发以及新组件或外部组件的轻松集成,还能够模型推断,例如多模态特征提取。
具体是怎样的?可以一起看看。
LAVIS共分为六个关键模块(详见下图)。
其中比较核心的就是runners模块,它负责管理整个训练的评估的过程,RunnerBase和RunnerIters也各司其职,一个负责基于epoch的训练,一个负责基于迭代的训练。
tasks模块会对每个任务执行具体的训练和评估逻辑,以适应特定的任务。
datasets顾名思义就是负责创建数据集。
在models模块中,它保存了其支持的四个模型以及共享模型层的定义。
processors模块用来处理多模态输入的预处理,处理器将输入的图像、视频和文本转换为模型可以使用的形式。
common则是LAVIS提供的工具包和一些应用程序。
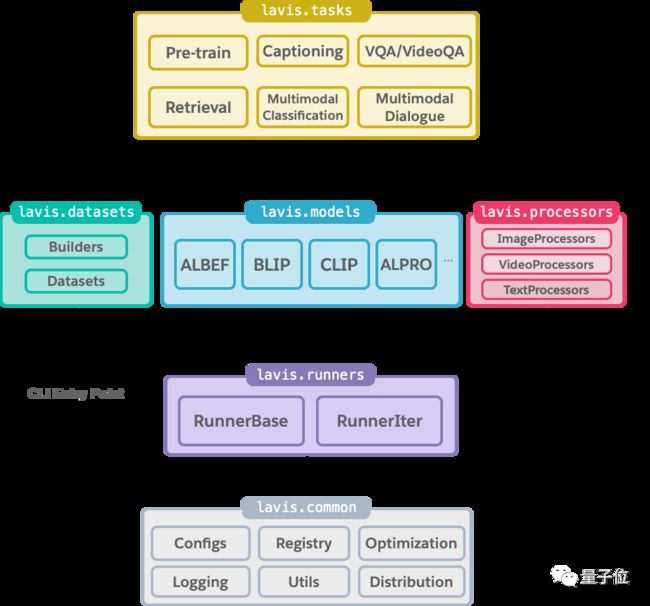
这些模块之间相互依赖,由此便形成了一个简单而统一的库,进而可以更方便地训练和评估模型;访问所支持的模型和数据集以及扩展新模型、任务和数据集。
目前,开发人员表示将持续更新维护LAVIS,在未来它将会支持更多更强大的视觉语言预训练模型,和更多的视觉语言任务,比如文本图像生成。
听完是不是心痒痒了?
下方就有开源链接以及详细文档,感兴趣的朋友可以试试~
Github:https://github.com/salesforce/LAVIS
技术报告:https://arxiv.org/abs/2209.09019
⽀持⽂档:https://opensource.salesforce.com/LAVIS//latest/index.html
官⽅博客:https://blog.salesforceairesearch.com/lavis-language-vision-library/