PaddleNLP开源UTC通用文本分类技术,斩获ZeroCLUE、FewCLUE双榜第一
飞桨PaddlePaddle 2023-01-12 20:02 发表于湖北
针对产业级分类场景中任务多样、数据稀缺、标签迁移难度大等挑战,百度提出了一个大一统的通用文本分类技术UTC(Universal Text Classfication)。
UTC在ZeroCLUE和FewCLUE两个榜单上均位居榜首,证明了其优异的零样本和小样本学习能力。飞桨PaddleNLP结合文心大模型中的知识增强NLP大模型文心ERNIE,开源了首个面向通用文本分类的产业级技术方案,仅三行代码即可快速体验多任务文本分类效果,同时提供了端到端的模型训练部署方案,支持复杂场景的产业落地。
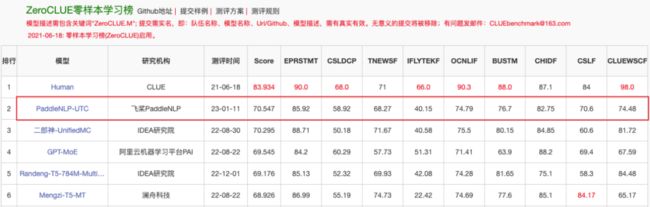
图:ZeroCLUE榜单(2023.01.12)
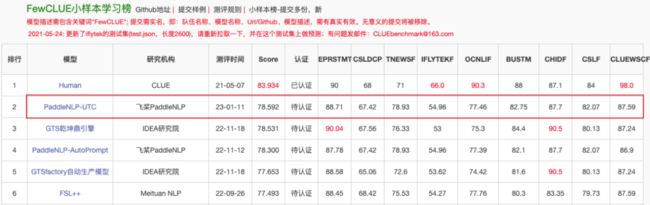
图:FewCLUE榜单(2023.01.12)
 榜单介绍
榜单介绍
CLUE(Chinese Language Understanding Evaluation)作为中文语言理解权威测评榜单,在学术界和工业界都有着广泛影响。ZeroCLUE和FewCLUE是其设立的中文零/小样本学习测评子榜,旨在探索低资源场景下的最佳模型与实践。自发布以来已经吸引了美团、IDEA研究院、澜舟科技、网易、腾讯微信、阿里云等多家企业和研究院的参与。
 通用文本分类技术UTC
通用文本分类技术UTC
随着企业智能化转型的加速,文本分类技术被广泛应用于各行各业的文本处理中,如对话意图识别、金融研报文档分类、票据归档、事件检测等。
分类任务看似简单,然而在产业级文本分类落地实践中,面临着诸多挑战:
- 任务多样:单标签、多标签、层次标签、大规模标签等不同的文本分类任务,需要开发不同的分类模型,模型架构往往特化于具体任务,难以使用统一形式建模;
- 数据稀缺:部分领域数据稀缺,难以获取,且领域专业性使得数据标注门槛高;
- 标签迁移:不同领域的标签多样,并且迁移难度大,尤其不同领域间的标签知识很难迁移。
针对以上难题,百度构建了“任务架构统一、通用能力共享”的通用文本分类技术UTC,其实现了良好的零/少样本迁移性能。UTC是一个大一统诸多任务的开放域分类技术方案,其总体框架如下图所示。
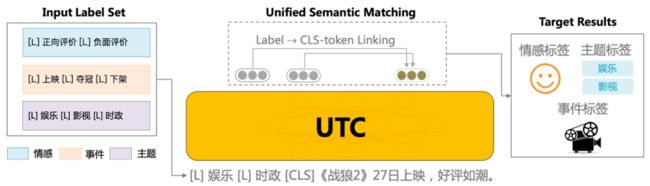
图:UTC总体框架
在详细分享其技术思路之前,先来看看UTC有哪些亮点。
 UTC亮点
UTC亮点
*亮点1:多任务统一建模*
在传统技术方案中,针对不同的分类任务需要构建多个分类模型,模型需单独训练且数据和知识不共享。而在UTC方案下,单个模型能解决所有分类需求,包括但不限于单标签分类、多标签分类、层次标签分类、大规模事件标签检测、蕴含推理、语义相似度计算等,降低了开发成本和机器成本。
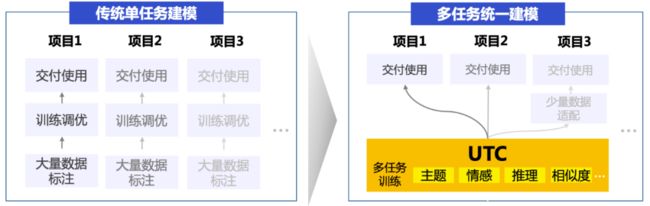
图:传统方案 vs UTC统一建模方案
*亮点2:零样本分类和小样本迁移能力强*
UTC通过大规模多任务预训练后,可以适配不同的行业领域,不同的分类标签。例如,在财务报销场景,无需训练数据,即可全部分类正确(图左)。针对稍复杂场景,标注少量数据微调即完成任务适配,例如金融文档分类(图中)和政务服务分类(图右)中,仅标注了几条样本,分类效果就取得大幅提升,大大降低标注门槛和成本。
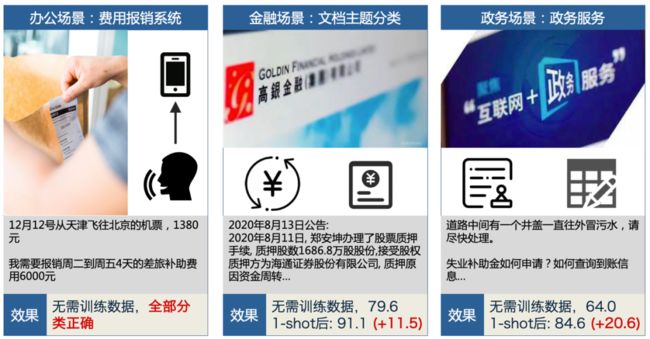
图:文本分类零样本和小样本效果展示
综合来看,在医疗、金融、法律等领域中,无需训练数据的零样本情况下UTC效果平均可达到70%+(如下表所示),标注少样本也可带来显著的效果提升:**每个标签仅仅标注1条样本后,平均提升了10个点!**也就是说,即使在某些场景下表现欠佳,人工标几个样本,丢给模型后就会有大幅的效果提升。
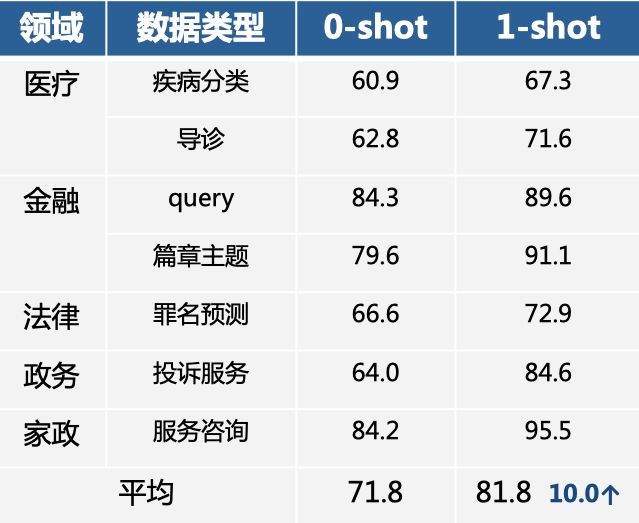
图:自建数据集上UTC效果
说明:0-shot表示无训练数据直接预测,1-shot表示每个标签基于1条标注数据进行模型微调。
 快速使用UTC
快速使用UTC
PaddleNLP结合文心ERNIE,基于UTC技术开源了首个面向通用文本分类的产业级技术方案。对于简单任务,通过调用 paddlenlp.Taskflow API ,仅用三行代码即可实现零样本(Zero-shot)通用文本分类,可支持情感分析、意图识别、语义匹配、蕴含推理等各种可转换为分类问题的NLU任务。仅使用一个模型即可同时支持多个任务,便捷高效!
from pprint import pprint
from paddlenlp import Taskflow
# 情感分析
cls = Taskflow("zero_shot_text_classification", schema=["这是一条好评", "这是一条差评"])
cls("房间干净明亮,非常不错")
>>>
[{'predictions': [{'label': '这是一条好评', 'score': 0.9695149765679986}],
'text_a': '房间干净明亮,非常不错'}]
# 意图识别
schema = ["病情诊断", "治疗方案", "病因分析", "指标解读", "就医建议", "疾病表述", "后果表述", "注意事项", "功效作用", "医疗费用", "其他"]
pprint(cls("先天性厚甲症去哪里治"))
>>>
[{'predictions': [{'label': '就医建议', 'score': 0.9628814210597645}],
'text_a': '先天性厚甲症去哪里治'}]
# 语义相似度
cls = Taskflow("zero_shot_text_classification", schema=["不同", "相同"])
pprint(cls([["怎么查看合同", "从哪里可以看到合同"], ["为什么一直没有电话来确认借款信息", "为何我还款了,今天却接到客服电话通知"]]))
>>>
[{'predictions': [{'label': '相同', 'score': 0.9775065319076257}],
'text_a': '怎么查看合同',
'text_b': '从哪里可以看到合同'},
{'predictions': [{'label': '不同', 'score': 0.9918983379165037}],
'text_a': '为什么一直没有电话来确认借款信息',
'text_b': '为何我还款了,今天却接到客服电话通知'}]
# 蕴含推理
cls = Taskflow("zero_shot_text_classification", schema=["中立", "蕴含", "矛盾"])
pprint(cls([["一个骑自行车的人正沿着一条城市街道朝一座有时钟的塔走去。", "骑自行车的人正朝钟楼走去。"],
["一个留着长发和胡须的怪人,在地铁里穿着一件颜色鲜艳的衬衫。", "这件衬衫是新的。"],
["一个穿着绿色衬衫的妈妈和一个穿全黑衣服的男人在跳舞。", "两人都穿着白色裤子。"]]))
>>>
[{'predictions': [{'label': '蕴含', 'score': 0.9944843058584897}],
'text_a': '一个骑自行车的人正沿着一条城市街道朝一座有时钟的塔走去。',
'text_b': '骑自行车的人正朝钟楼走去。'},
{'predictions': [{'label': '中立', 'score': 0.6659998351201399}],
'text_a': '一个留着长发和胡须的怪人,在地铁里穿着一件颜色鲜艳的衬衫。',
'text_b': '这件衬衫是新的。'},
{'predictions': [{'label': '矛盾', 'score': 0.9270557883904931}],
'text_a': '一个穿着绿色衬衫的妈妈和一个穿全黑衣服的男人在跳舞。',
'text_b': '两人都穿着白色裤子。'}]
对于复杂任务,可以标注少量数据(Few-shot)进行模型训练,以进一步提升模型分类效果。PaddleNLP打通了数据标注-模型训练-模型调优-预测部署全流程,多场景文本分类任务可用单一模型实现,进一步节省模型训练和部署资源,助力高效文本分类产业落地。
- 了解详情
https://github.com/PaddlePaddle/PaddleNLP/tree/develop/applications/zero_shot_text_classification
 UTC技术思路
UTC技术思路
UTC基于百度最新提出的统一语义匹配框架USM(Unified Semantic Matching)[1],将分类任务统一建模为标签与文本之间的匹配任务,对不同标签的分类任务进行统一建模。具体地说:
(1)为了实现任务架构统一,UTC设计了标签与文本之间的词对连接操作(Label–>CLS-Token Linking),这使得模型能够适应不同领域和任务的标签信息,并按需求进行分类,从而实现了开放域场景下的通用文本分类。
例如,对于事件检测任务,可将一系列事件标签拼接为[L]上映[L]夺冠[L]下架 ,然后与原文本一起作为整体输入到UTC中,UTC将不同标签标识符[L]与[CLS]进行匹配,可对不同标签类型的分类任务统一建模,直接上图:
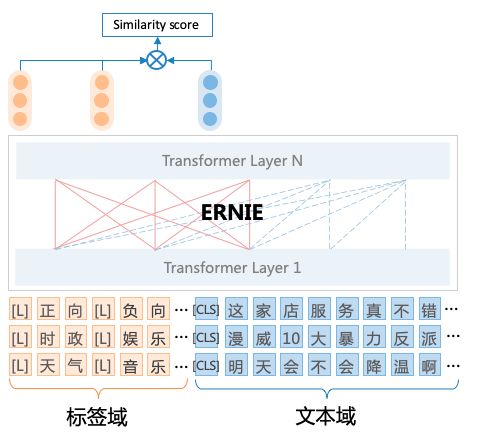
图:UTC模型架构图
(2)为了实现通用能力共享,让不同领域间的标签知识跨域迁移,UTC构建了统一的异质监督学习方法进行多任务预训练,使不同领域任务具备良好的零/少样本迁移性能。统一的异质监督学习方法主要包括三种不同的监督信号:
- 直接监督:分类任务直接相关的数据集,如情感分类、新闻分类、意图识别等。
- 间接监督:分类任务间接相关的数据集,如选项式阅读理解、问题-文章匹配等。
- 远程监督:标签知识库或层级标题与文本对齐后弱标注数据。
想详细了解UTC的强大能力,可访问:
https://github.com/PaddlePaddle/PaddleNLP/tree/develop/applications/zero_shot_text_classification
 商业合作
商业合作
在开源版本之外,商业版本融合了百度多年的业务落地经验,具有更好的效果和更完善的落地方案:
- 效果更好:同任务上零/少样本效果会更好,同时包含更多预定义能力。
- 支持大规模标签:支持千级别以上的大规模标签分类任务。
- 部署成本更低:单卡GPU可以支持上百个任务同时部署。
- 预置多种场景:减少产品探索,同时提供定制人力。
 未来展望
未来展望
通过这次ZeroCLUE和FewCLUE的实践,验证了UTC具备良好的零/少样本迁移性能。未来PaddleNLP将进一步提升UTC的零样本能力,做到更大规模场景下的“开箱即用”。
如果我们的开源工作对你有帮助,欢迎STAR支持。
相关地址
- GitHub地址
https://github.com/PaddlePaddle/PaddleNLP
- Gitee地址
https://gitee.com/paddlepaddle/PaddleNLP
参考
[1]Universal Information Extraction as Unified Semantic Matching:
https://arxiv.org/pdf/2301.03282.pdf