tensorflow使用显卡gpu进行训练详细教程
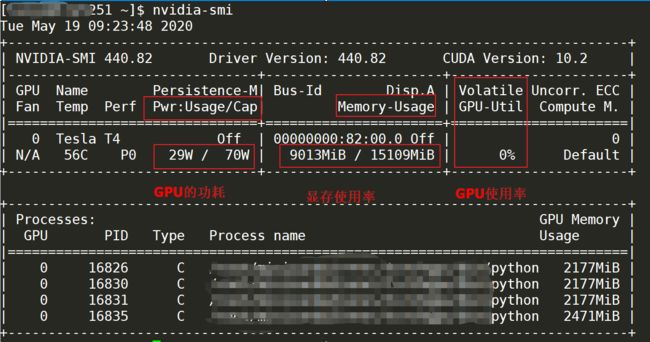
GPU之nvidia-smi命令详解查看显卡的信息:
cmd: nvidia-smi
GPU之nvidia-smi命令详解 - 简书
-
GPU:本机中的GPU编号(有多块显卡的时候,从0开始编号)图上GPU的编号是:0
-
Fan:风扇转速(0%-100%),N/A表示没有风扇
-
Name:GPU类型,图上GPU的类型是:Tesla T4
-
Temp:GPU的温度(GPU温度过高会导致GPU的频率下降)
-
Perf:GPU的性能状态,从P0(最大性能)到P12(最小性能),图上是:P0
-
Persistence-M:持续模式的状态,持续模式虽然耗能大,但是在新的GPU应用启动时花费的时间更少,图上显示的是:off
-
Pwr:Usager/Cap:能耗表示,Usage:用了多少,Cap总共多少
-
Bus-Id:GPU总线相关显示,domain:bus:device.function
-
Disp.A:Display Active ,表示GPU的显示是否初始化
-
Memory-Usage:显存使用率
-
Volatile GPU-Util:GPU使用率
-
Uncorr. ECC:关于ECC的东西,是否开启错误检查和纠正技术,0/disabled,1/enabled
-
Compute M:计算模式,0/DEFAULT,1/EXCLUSIVE_PROCESS,2/PROHIBITED
-
Processes:显示每个进程占用的显存使用率、进程号、占用的哪个GPU
隔几秒刷新一下显存状态:nvidia-smi -l 秒数
隔两秒刷新一下GPU的状态:nvidia-smi -l 2
tensorflow的显卡使用方式
1、直接使用
这种方式会把当前机器上所有的显卡的剩余显存基本都占用,注意是机器上所有显卡的剩余显存。因此程序可能只需要一块显卡,但是程序就是这么霸道,我不用其他的显卡,或者我用不了那么多显卡,但是我就是要占用。
with tf.compat.v1.Session() as sess:
# 输入图片为256x256,2个分类
shape, classes = (224, 224, 3), 20
# 调用keras的ResNet50模型
model = keras.applications.resnet50.ResNet50(input_shape = shape, weights=None, classes=classes)
model.compile(optimizer="adam", loss="sparse_categorical_crossentropy", metrics=["accuracy"])
# 训练模型 categorical_crossentropy sparse_categorical_crossentropy
# training = model.fit(train_x, train_y, epochs=50, batch_size=10)
model.fit(train_x,train_y,validation_data=(test_x, test_y), epochs=20, batch_size=6,verbose=2)
# # 把训练好的模型保存到文件
model.save('resnet_model_dog_n_face.h5')2、分配比例使用
其中这种方式跟上面直接使用方式的差异就是,我不占用所有的显存了,例如这样写,我就占有每块显卡的60%。
from tensorflow.compat.v1 import ConfigProto# tf 2.x的写法
config =ConfigProto()
config.gpu_options.per_process_gpu_memory_fraction=0.6
with tf.compat.v1.Session(config=config) as sess:
model = keras.applications.resnet50.ResNet50(input_shape = shape, weights=None, classes=classes)3. 动态申请使用
这种方式是动态申请显存的,只会申请内存,不会释放内存。而且如果别人的程序把剩余显卡全部占了,就会报错。
以上三种方式,应根据场景来选择。
第一种因为是全部占用内存,因此只要模型的大小不超过显存的大小,就不会产生显存碎片,影响计算性能。可以说合适部署应用的配置。
第二种和第三种适合多人使用一台服务器的情况,但第二种存在浪费显存的情况,第三种在一定程序上避免了显存的浪费,但极容易出现程序由于申请不到内存导致崩溃的情况。
config = tf.compat.v1.ConfigProto()
config.gpu_options.allow_growth = True
session = tf.compat.v1.InteractiveSession(config=config)
with tf.compat.v1.Session(config=config) as sess:
model4 指定GPU
在有多块GPU的服务器上运行tensorflow的时候,如果使用python编程,则可指定GPU,代码如下:
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "2"配上一个完整的示例:resnet50图片分类:
config = tf.compat.v1.ConfigProto()
config.gpu_options.allow_growth = True
session = tf.compat.v1.InteractiveSession(config=config)
with tf.compat.v1.Session(config=config) as sess:
# 输入图片为256x256,2个分类
shape, classes = (224, 224, 3), 20
# 调用keras的ResNet50模型
model = keras.applications.resnet50.ResNet50(input_shape = shape, weights=None, classes=classes)
model.compile(optimizer="adam", loss="sparse_categorical_crossentropy", metrics=["accuracy"])
# 训练模型 categorical_crossentropy sparse_categorical_crossentropy
# training = model.fit(train_x, train_y, epochs=50, batch_size=10)
model.fit(train_x,train_y,validation_data=(test_x, test_y), epochs=20, batch_size=6,verbose=2)
# # 把训练好的模型保存到文件
model.save('resnet_model_dog_n_face.h5')